










1.哈夫曼编码原理
根据字符出现的概率大小进行编码,出现概率高的字符使用较短的编码,出现概率低的字符使用较长的编码,从而使平均码长尽可能短。是数据压缩技术的一种体现。
可以这么理解,出现概率高的字符则说明使用到这个字符的次数多,那么为了方便使用就要把这种常用的字符设置的简短方便一些,编码越短越好。例如A的编码有1和11111111两种选择,而且经常使用到A,那么肯定是选择编码为1更方便,每次只需要输入一个1就可以了,而不用输入那么长的一串。
2.哈夫曼树
要实现哈夫曼编码,首先需要构造一棵哈夫曼树。
哈夫曼树是根据各个字符的概率大小(也可理解为重要程度,以下用重要程度来说能更好理解)来构造的,构造的顺序是从叶子结点开始往上新构造,直到构造出根结点为止。
2.1构造规则
- 从现有的所有结点中选择重要程度最小的两个组合构造出它们的父结点,父结点的重要程度为两个子结点的重要程度之和
- 生成父结点后,已经用过的两个结点就不再之后的考虑范围内了,但要把新生成的父结点加入到现有的尚未使用过的结点集合中
- 重复1、2步骤,直到所有的结点都使用过
假设有一下字符:
| 字符 | 概率(重要程度) |
|---|---|
| A | 8 |
| B | 10 |
| C | 3 |
| D | 4 |
| E | 5 |
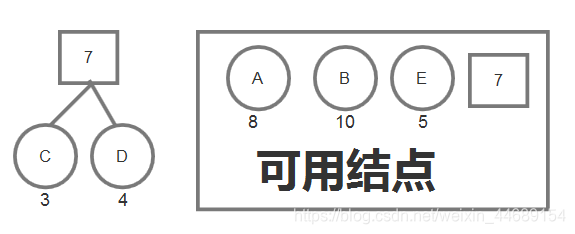
初始的结点就是这五个,在其中选出重要程度最小的两个,分别是C、D,然后用这两个结点构造一个父结点出来
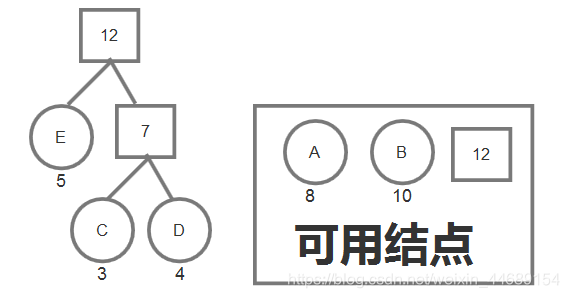
C、D已经使用过了,就不再考虑。将新生成的父结点加入到可用结点中,然后再从这些结点里选重要程度最低的两个结点,重复之前的操作。
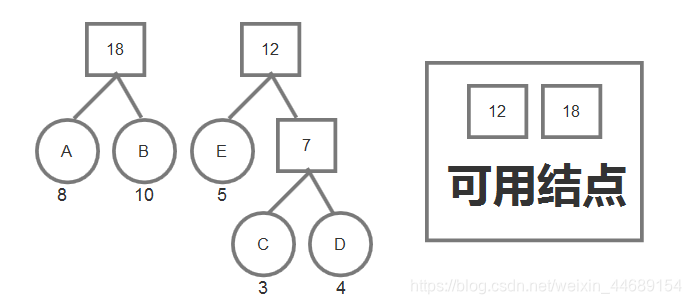 可以看到,每次重复这样的操作之后可用的结点是越来越少的,而且每生成一个新的父结点,可用的结点就会减一。
可以看到,每次重复这样的操作之后可用的结点是越来越少的,而且每生成一个新的父结点,可用的结点就会减一。
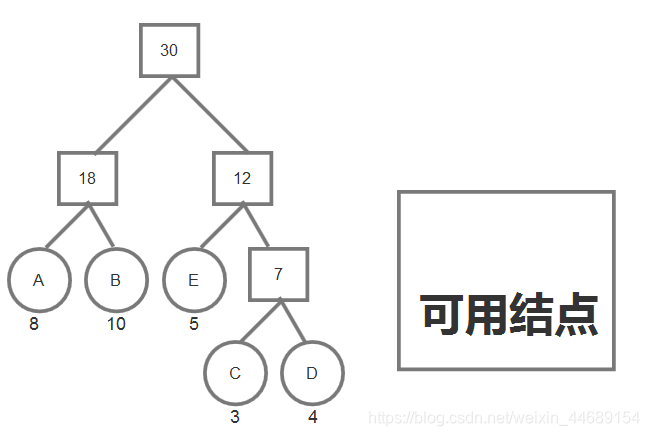
当可用结点没有了,也就是根结点构造出来的时候。此时哈夫曼树就构造好了
2.2构造时要注意的内容
- 一般两个最小的数中,较小的那个作为生成的父结点的左子结点,较大的那个作为生成的父结点的右子结点(其实是不固定的,所以哈夫曼树不唯一)
- 最终哈夫曼树的结点总数为 2n-1 (n为原始结点数)
- 原始的需要进行编码的结点都作为叶子节点
3编码
编码的过程是通过从哈夫曼树的根结点开始,到对应的叶子结点的路径进行编码的。
3.1编码规则
- 往左子结点走记为 0
- 往右子结点走记为 1
- 编码顺序是从根结点到叶子节点
把上面的例子按照这个编码规则处理后如下图
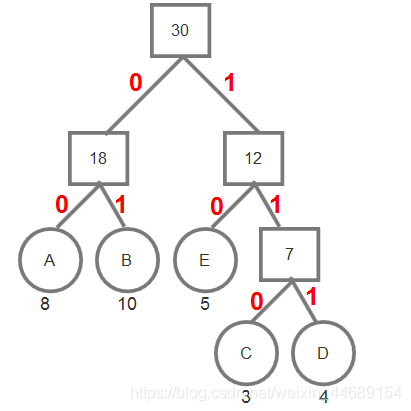
按照从根节点到叶子结点的顺序进行编码得到
| 字符 | 哈夫曼编码 |
|---|---|
| A | 00 |
| B | 01 |
| C | 110 |
| D | 111 |
| E | 10 |
4解码
解码就是输入一串哈夫曼编码,然后将其翻译成字符的形式
4.1解码规则
- 从根结点开始,按照编码,若是0则看左子结点,若是1则看右子结点,直到走到叶子节点,叶子节点代表的字符是什么则解码的结果就是什么
- 当解码出一个字符后便回到根结点,从下一个字符开始,继续重复上一点的方法,直到所有的编码都结束为止
4.2解码要注意的内容
- 每个编码都从哈夫曼树的根结点开始找
- 任意的编码都不可能是其他编码的前缀或者后缀,所以只需要将所有的编码按顺序直接处理就可以了不用考虑出现歧义的情况。
5.实例代码
#include<stdio.h>
#include<string.h>
#define MAXBIT 100
#define MAXVALUE 10000
#define MAXLEAF 30
#define MAXNODE MAXLEAF*2 -1
typedef struct { //编码结构体
int bit[MAXBIT]; //码
int start;
} HCodeType;
typedef struct { //结点结构体
int weight; //权值
int parent; //父亲结点
int lchild; //左子结点
int rchild; //右子结点
char value; //结点的实际值
} HNodeType;
void init (HNodeType HuffNode[MAXNODE], int n) { //初始化
for (int i=0; i<2*n-1; i++) { //初始化所有结点
HuffNode[i].weight = 0;
HuffNode[i].parent = -1; //-1代表不存在
HuffNode[i].lchild = -1;
HuffNode[i].rchild = -1;
HuffNode[i].value=' ';
}
for (int i=0; i<n; i++) { //输入n个结点的实际值
getchar(); //防止在输入字符的时候误把换行当作输入的值
printf ("输入实际值: ");
scanf ("%c",&HuffNode[i].value);
}
printf("\n") ;
for (int i=0; i<n; i++) { //输入n个结点的权值
printf ("输入权值: ");
scanf ("%d",&HuffNode[i].weight);
}
}
void HuffmanTree (HNodeType HuffNode[MAXNODE], int n) {//构造霍夫曼树
int m1, m2, x1, x2;
/*m1、m2:构造哈夫曼树不同过程中两个没有父结点且最小权值结点的权值,
x1、x2:构造哈夫曼树不同过程中两个最小权值结点在数组中的序号。*/
for (int i=0; i<n-1; i++) { //处理输入的n个结点
m1 = m2 = MAXVALUE; //每次处理时都要从初始化
x1 = x2 = 0; //初始化
//寻找所有结点中权值最小、无父结点的两个结点
for (int j=0; j<n+i; j++) { //每次处理完两个点后都会有新结点产生,则查找的要更多
if (HuffNode[j].weight < m1 && HuffNode[j].parent==-1) {
m2=m1; //m2放第二小的
x2=x1;
m1=HuffNode[j].weight; //m1放最小的
x1=j;
}
else if (HuffNode[j].weight < m2 && HuffNode[j].parent==-1)
{
m2=HuffNode[j].weight;
x2=j;
}
}
//设置找到的两个结点 x1、x2 的父结点信息
HuffNode[x1].parent = n+i; //两结点的父结点相同
HuffNode[x2].parent = n+i;
HuffNode[n+i].weight = HuffNode[x1].weight + HuffNode[x2].weight;//父结点的权值是两个子结点权值之和
HuffNode[n+i].lchild = x1; //左子结点是最小的
HuffNode[n+i].rchild = x2; //右子结点是第二小的
}
}
//编码
void coding (HNodeType HuffNode[MAXNODE], HCodeType HuffCode[MAXLEAF], int n) {
int c, p ;
HCodeType cd; //临时变量来存放求解编码时的信息
for (int i=0; i < n; i++) { //n个结点都要编码
cd.start = n-1;
c = i; //当前结点的位置
p = HuffNode[i].parent; //当前结点的父结点位置
while (p != -1) { //父结点存在才能往上找
if (HuffNode[p].lchild == c) //左子结点为0
cd.bit[cd.start] = 0;
else //右子结点为1
cd.bit[cd.start] = 1;
cd.start--; //求编码的低一位
c=p; //更新当前结点位置
p=HuffNode[c].parent; //更新当前结点的父结点位置
}
for (int j=cd.start+1; j<n; j++) //保存求出的结点的霍夫曼编码
HuffCode[i].bit[j] = cd.bit[j];
HuffCode[i].start = cd.start+1; //保存编码的起始位
}
for (int i=0; i<n; i++) { //输出所有霍夫曼编码
printf ("%c的霍夫曼编码: ", HuffNode[i].value);
for (int j=HuffCode[i].start; j < n; j++)
printf ("%d", HuffCode[i].bit[j]);
printf ("\n");
}
printf("\n") ;
}
void decoding(char string[],HNodeType HuffNode[],int n) { //解码
int m = 2*n-1; //结点总数
int current = m-1; //记录当前结点位置
for(int i=0; i<strlen(string); i++) {
if(string[i] == '0')
current = HuffNode[current].lchild; //走向左子结点
else
current = HuffNode[current].rchild; //走向右子结点
if(HuffNode[current].lchild == -1) { //叶结点
printf("%c", HuffNode[current].value);
current = m-1; //回到根结点进行新的解码
}
}
printf("\n");
}
int main() {
int n ;
HNodeType HuffNode[MAXNODE]; //存放每一个结点
HCodeType HuffCode[MAXLEAF]; //存放编码结构体数组
char pp[100]; //解码时输入的数据
printf ("输入结点数:\n");
scanf ("%d", &n);
printf("\n") ; //只是将输出的内容隔开起到美观作用
init (HuffNode, n) ; //初始化
HuffmanTree (HuffNode, n); //生成霍夫曼树
coding(HuffNode, HuffCode, n) ; //编码
printf("输入要解码的编码:\n");
scanf("%s",pp);
decoding(pp,HuffNode,n); //解码
return 0;
}
6.贪心思想
贪心是一种特殊的动态规划,最简单的动态规划。它的思想就是只看当前的最优解,局部最优就是全局最优。只有局部最优策略能产生最优解时才使用
实现哈夫曼编码的过程就是一个贪心的过程。因为很贪心,所以才要选择重要程度大的字符使用较短的编码。同理类似的还有,构建最小生成树的过程,也用到了贪心的思想,每次都选择符合条件的路径长度最小的边加入到最小生成树中。
考虑怎么贪心一般就是考虑从大到小选择、从小到大选择、从比重最大的开始选择等等。我做了几道贪心的题后,我认为在考虑这样的题时:
- 更多的应该往日常生活去考虑,多想想在真实情况下,我会怎么做让效率最高,往往我们生活中的经验也能够给我们一些正确的思路
- 除了通过经验来判断,最稳的还是通过数学的方式来证明,一般就是会形成一个公式,然后看哪个变量越大越好或者越小越好就得到了贪心的思路,或者一大一小的两个值通过公式进行比较,发现其中的规律。
这类题太多的套路也没有,但题型就那几样,多做题熟练了就好了。
7.总结
之前看了一个麻省理工数据结构的课,听了讲贪心的一节课,就很厉害,最开始讲怎么构造最小生成树,然后根据它的原理推导出了动态规划的方法,然后又从动态规划中找出了贪心的思想。瞬间就把我一直有疑惑的地方点通了。而且这样的推导过程也很厉害。所以,很多东西还是有很多关联的,要有刨根问底的精神,追究到根源或许就能豁然开朗了。

















 6096
6096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









