







使用SparkPi提交任务
先开启spark集群
[root@hadoop01 bin]# ./spark-submit --class org.apache.spark.examples.SparkPi /
--master spark://hadoop01:7077 /
--executor-memory 1G /
--total-executor-cores 1 examples/jars/spark-examples_2.12-3.2.0.jar 10
进入hadoop01:8080网址可以显示出


高可用时需要指向一个Master列表:
[root@hadoop01 bin]# ./spark-submit --class org.apache.spark.examples.SparkPi /
--master spark://hadoop01:7077,hadoop02:7077,hadoop03:7077 /
--executor-memory 1G /
--total-executor-cores 1 examples/jars/spark-examples_2.12-3.2.0.jar 10
bug(待解决):
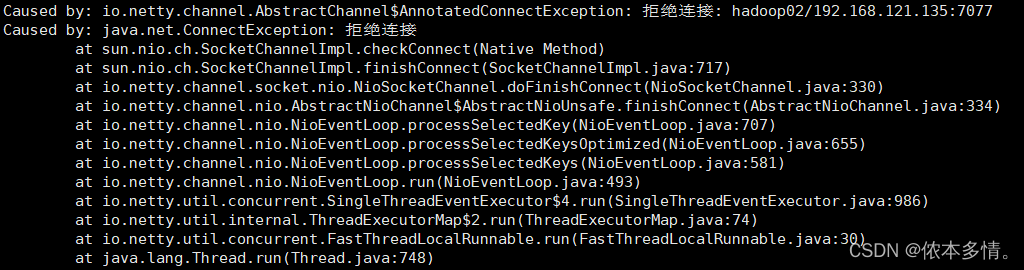
spark-shell进行词频统计
在spark-env.sh配置文件中添加:
#指定HDFS配置文件目录
export HADOOP_CONF_DIR=/export/servers/hadoop-2.7.4/etc/hadoop
然后先启动zookeeper,再启动hadoop,最后启动spark。
创建需要统计的文件,并传入hdfs中。
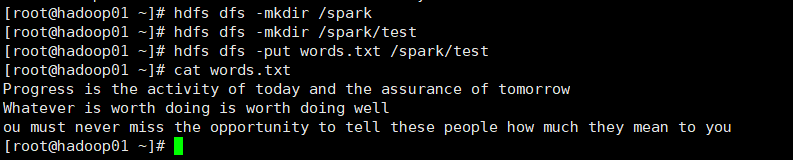
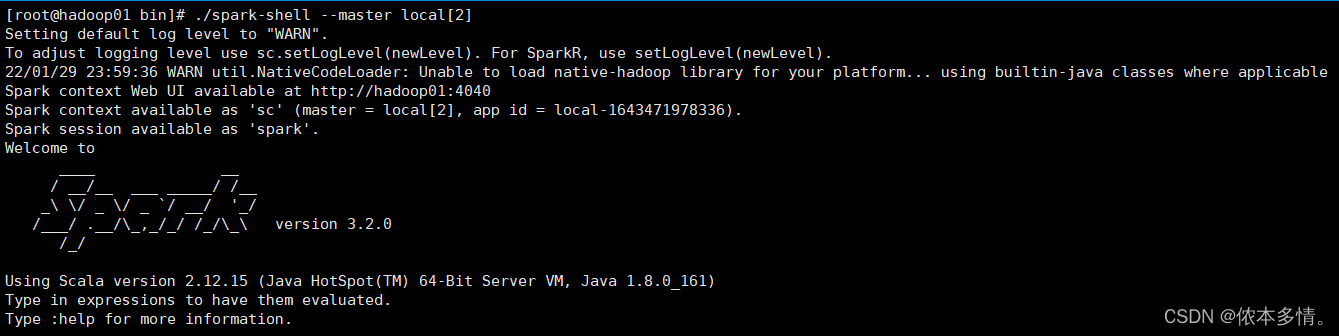
启动spark-shell
[root@hadoop01 bin]# ./spark-shell --master local[2]
词频统计结果:
sc.textFile("/spark/test/words.txt").flatMap(_.split("")).map((_,1)).reduceByKey(_+_).collect















 6545
6545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











