









一.概念
线性判别分析是对费舍尔的线性鉴别方法的归纳,这种方法使用统计学、模式识别和机器学习方法,试图找到两类物体或事件的特征的一个线性组合,以能够特征化或区分它们。所得的组合可用来作为一个线性分类器,或者,更常见的是,为后续的分类做降维处理。
1.1简介
线性判别思想:给定训练样例集,设法将样例投影到一条直线上,使得同样样例的投影点尽可能接近,异样样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的直线上,再根据投影点的位置来确定新样本的类别。
LDA与方差分析(ANOVA)和回归分析紧密相关
方差分析→类别自变量和连续数因变量,判别分析→连续自变量和类别因变量
LDA与主成分分析(PCA)和因子分析紧密相关
1.2 优点
①可以直接求得基于广义特征值问题的解析解;
②不需要调整参数,不存在学习参数和优化权重以及神经元激活函数的选择等问题;
③对模式的归一化或随机化不敏感。
1.3 应用领域
(1)破产预测:LDA是第一个用来系统解释公司进入破产或存活的统计学工具。
(2)脸部识别:LDA把特征的数量降到可管理的数量后再进行分类。
(3)市场营销:LDA用于通过市场调查或其他数据收集手段,找出那些能区分不同客户或产品类型的多个因素。
(4)生物医学研究:评估患者的严重程度和对疾病结果的预后判断。
(5)地球科学:可用于区分蚀变带。
当很多带的不同数据都现成时,判别分析可以从数据中找到模式并有效的对它分类。
二.原理
关于线性判别分析相关数学原理,可以看下面这篇博客,博主描写的非常详细。
线性判别分析数学原理以及二分类具体实现
三.python实现
import pandas as pd
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split,KFold,cross_val_score
from sklearn.metrics import classification_report,confusion_matrix,accuracy_score
# 数据集
raw_data = pd.read_csv('1_raw_data_13-12_22.03.16.txt', sep='\t', header=0) # 读取csv数据,并将第一行视为表头,返回DataFrame类型
data = raw_data.values
times = data[::, 0]
features_data = raw_data[['channel1','channel5']]
features = features_data.values
labels = data[::,-1] # 最后一列为特征值
# 70%作为训练集,30%为测试集
validation_data = 0.3
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=validation_data, random_state=0)
print(train_features.shape)
lda = LinearDiscriminantAnalysis()
# lda.fit(train_features,train_labels)
# pred_test = lda.predict(test_features)
# accuracy_score = accuracy_score(test_labels,pred_test)
# print(accuracy_score)
models = {}
models['LDA'] = lda
# 评估算法(交叉验证)
results = []
for key in models:
kfold = KFold(n_splits=10,shuffle=True)
cv_results = cross_val_score(models[key],train_features,train_labels,cv=kfold,scoring='accuracy')
results.append(cv_results)
print(results)
# 箱线图显示算法
fig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(models.keys())
plt.show()
运行结果:
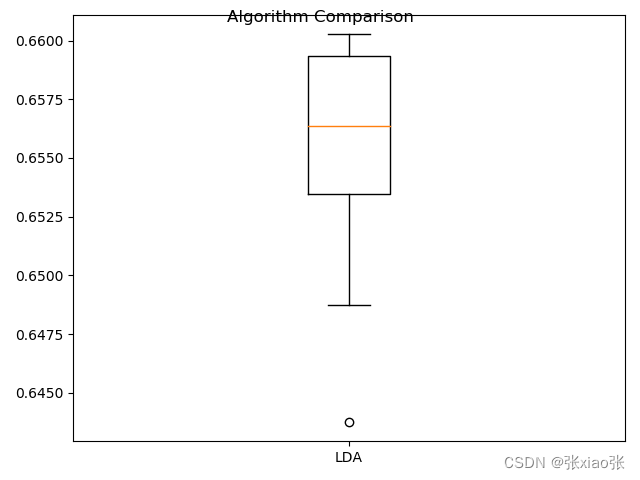
四.小结
算法使用了线性判别分析,是python自带库里面的 from sklearn.discriminant_analysis import LinearDiscriminantAnalysis的 LinearDiscriminantAnalysis(),后面可以自己写线性判别分析的实现。
箱线图介绍:
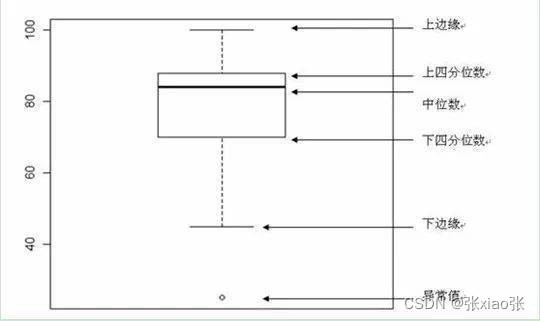
















 782
782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









