







8 实例
8.1 需求:
统计视频网站的常规指标
–统计视频观看数Top10
–统计视频类别热度Top10
–统计视频观看数Top20所属类别
–统计视频观看数Top50所关联视频的所属类别Rank
–统计每个类别中的视频热度Top10
–统计每个类别视频观看数Top10
8.2 数据结构
视频表:
| 字段 | 备注 | 详细描述 |
|---|---|---|
| video id | 视频唯一id(String) | 11位字符串 |
| uploader | 视频上传者(String) | 上传视频的用户名String |
| age | 视频年龄(int) | 视频在平台上的整数天 |
| category | 视频类别(Array) | 上传视频指定的视频分类 |
| length | 视频长度(Int) | 整形数字标识的视频长度 |
| views | 观看次数(Int) | 视频被浏览的次数 |
| rate | 视频评分(Double) | 满分5分 |
| Ratings | 流量(Int) | 视频的流量,整型数字 |
| conments | 评论数(Int) | 一个视频的整数评论数 |
| related ids | 相关视频id(Array) | 相关视频的id,最多20个 |
用户表:
| 字段 | 备注 | 字段类型 |
|---|---|---|
| uploader | 上传者用户名 | string |
| videos | 上传视频数 | int |
| friends | 朋友数量 | int |
8.3 ETL原始数据
通过观察原始数据形式,可以发现,视频可以有多个所属分类,每个所属分类用&符号分割,且分割的两边有空格字符,同时相关视频也是可以有多个元素,多个相关视频又用“\t”进行分割。为了分析数据时方便对存在多个子元素的数据进行操作,我们首先进行数据重组清洗操作。即:将所有的类别用“&”分割,同时去掉两边空格,多个相关视频id也使用“&”进行分割。
如
RX24KLBhwMI lemonette 697 People & Blogs 512 24149 4.22 315 474 t60tW0WevkE WZgoejVDZlo Xa_op4MhSkg MwynZ8qTwXA sfG2rtAkAcg j72VLPwzd_c 24Qfs69Al3U EGWutOjVx4M KVkseZR5coU R6OaRcsfnY4 dGM3k_4cNhE ai-cSq6APLQ 73M0y-iD9WE 3uKOSjE79YA 9BBu5N0iFBg 7f9zwx52xgA ncEV0tSC7xM H-J8Kbx9o68 s8xf4QX1UvA 2cKd9ERh5-8
编写map-reduce程序进行预处理
ETLMapper.java
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ETLMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
private Counter pass;
private Counter fail;
private StringBuilder sb = new StringBuilder();
private Text result = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
pass = context.getCounter("ETL", "Pass");
fail = context.getCounter("ETL", "Fail");
}
/**
* 将一行日志进行处理,第四个字段中的空格取去掉,将最后视频的分隔符改为"&"
*
* @param key 行号
* @param value 一行日志
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//一行数据
String line = value.toString();
//字段切分
String[] fields = line.split("\t");
//判断字段数量够不够
if (fields.length >= 9) {
//处理数据并输出
//去掉第四个字段的空格
fields[3] = fields[3].replace(" ", "");
//拼接字段成一行,注意最后几个字段分隔符
//拼接之前,清零旧的字符串
sb.setLength(0);
for (int i = 0; i < fields.length; i++) {
//如果当前正在拼接的字段是我们这一行的最后一个字段
if (i == fields.length - 1) {
sb.append(fields[i]);
} else if (i <= 8) {
//如果拼接的是前9个字段
sb.append(fields[i]).append("\t");
} else {
//剩下分隔符为&
sb.append(fields[i]).append("&");
}
}
result.set(sb.toString());
context.write(result, NullWritable.get());
pass.increment(1);
} else {
//丢弃数据
fail.increment(1);
}
}
}
ETLDriver.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import javax.xml.soap.Text;
import java.io.IOException;
public class ETLDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(ETLDriver.class);
job.setMapperClass(ETLMapper.class);
job.setNumReduceTasks(0);
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
打包提交集群运行
处理结果:
1xbSFrHzFQ0 Ireton06 482 Film&Animation 245 9780 4 9 6 7vNsnB_qFGA&ndnlUZxB1pg&y8AkKnLMELo&aLAIaFdDHUQ&tY7XxpwDd_8&Yl_A7r1D_OE&YBSoLnN9AiM&wKecR3arrnQ&MG6NYhMRCgs&VvnSYenJRVQ&krtueF7CnCs&hZ0-
8.4 在Hive中建立外部表映射数据
--video表
create external table video_ori(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited fields terminated by "\t"
collection items terminated by "&"
location '/gulivideo/video_etl';
--user表
create external table user_ori(
uploader string,
videos int,
friends int)
row format delimited fields terminated by "\t"
location '/gulivideo/user';
--video_orc表
create table video_orc(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
stored as orc
tblproperties("orc.compress"="SNAPPY");
--user_orc表
create table user_orc(
uploader string,
videos int,
friends int)
stored as orc
tblproperties("orc.compress"="SNAPPY");
--从外部表中插入数据
insert into table video_orc select * from video_ori;
insert into table user_orc select * from user_ori;
8.5 需求实现
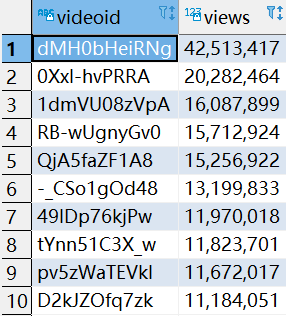
8.5.1 统计视频观看数top10
SELECT
videoid,
views
FROM
video_orc
ORDER BY
views DESC
LIMIT 10;
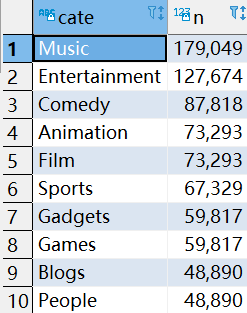
8.5.2 统计视频类别热度Top10
1 定义视频类别热度(假设按照类别下视频的个数来决定)
2 炸开类别
SELECT
videoid,
cate
FROM
video_orc LATERAL VIEW explode(category) tbl as cate;
3 在上表基础上,统计各个类别有多少视频,并排序取前十
SELECT
cate,
COUNT(videoid) n
FROM
t1
GROUP BY
cate
ORDER BY
n desc limit 10;
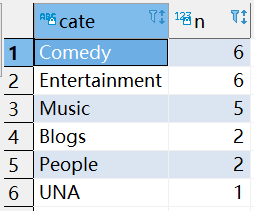
8.5.3 统计出视频观看数最高的20个视频的所属类别以及类别包含Top20视频的个数
1 统计前20视频和其类别
SELECT
videoid,
views,
category
FROM
video_orc
ORDER BY
views DESC
LIMIT 20;
2 打散类别
SELECT
videoid,
cate
FROM
t1 LATERAL VIEW explode(category) tbl as cate;
3 按照类别统计个数
SELECT
cate,
COUNT(videoid) n
FROM
t2
GROUP BY
cate
ORDER BY
n DESC;
完整sql:
SELECT
cate,
COUNT(videoid) n
FROM
(
SELECT
videoid,
cate
FROM
(
SELECT
videoid,
views,
category
FROM
video_orc
ORDER BY
views DESC LIMIT 20 )t1 LATERAL VIEW explode(category) tbl as cate )t2
GROUP BY
cate
ORDER BY
n DESC;
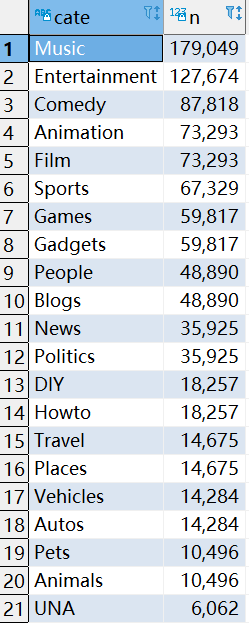
8.5.4 统计视频观看数Top50所关联视频的所属类别排序
1 统计观看数前50的视频的关联视频
SELECT
videoid,
views,
relatedid
FROM
video_orc
ORDER BY
views DESC
LIMIT 50;
2 炸开关联视频
SELECT
explode(relatedid) videoid
FROM
t1;
3 和原表Join获取关联视频的类别
SELECT
DISTINCT t2.videoid,
v.category
FROM
t2
JOIN video_orc v on
t2.videoid = v.videoid;
4 炸开类别
SELECT
explode(category) cate
FROM
t3;
5 和类别热度表(t5)Join 排序
SELECT
DISTINCT t4.cate,
t5.n
FROM
(
SELECT
explode(category) cate
FROM
(
SELECT
DISTINCT t2.videoid,
v.category
FROM
(
SELECT
explode(relatedid) videoid
FROM
(
SELECT
videoid,
views,
relatedid
FROM
video_orc
ORDER BY
views DESC LIMIT 50 ) t1 ) t2
JOIN video_orc v on
t2.videoid = v.videoid ) t3 ) t4
JOIN (
SELECT
cate,
COUNT(videoid) n
FROM
(
SELECT
videoid,
cate
FROM
video_orc LATERAL VIEW explode(category) tbl as cate) g1
GROUP BY
cate ) t5 ON
t4.cate = t5.cate
ORDER BY
t5.n DESC;
8.5.5 统计每个类别中的视频热度Top10,以Music为例
1.把视频表的类别炸开,生成中间表格video_category
CREATE TABLE video_category STORED AS orc TBLPROPERTIES("orc.compress"="SNAPPY") AS SELECT
videoid,
uploader,
age,
cate,
length,
views,
rate,
ratings,
comments,
relatedid
FROM
video_orc LATERAL VIEW explode(category) tbl as cate;
2.从video_category直接查询Music类的前10的视频
SELECT
videoid,
views
FROM
video_category
WHERE
cate ="Music"
ORDER BY
views DESC
LIMIT 10;
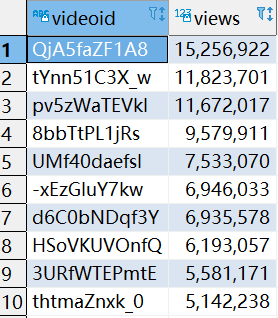
8.5.6 统计每个类别中视频流量Top10,以Music为例
1.从video_category直接查询Music类的流量前10视频
SELECT
videoid,
ratings
FROM
video_category
WHERE
cate ="Music"
ORDER BY
ratings DESC
LIMIT 10;
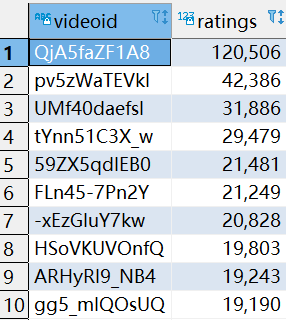
8.5.7 统计上传视频最多的用户Top10以及他们上传的观看次数在前20的视频
理解一:前十用户每人前20
1 统计视频上传最多的用户Top10
SELECT
uploader,
videos
FROM
user_orc
ORDER BY
videos DESC
LIMIT 10;
2 和video_orc联立,找出这些用户上传的视频,并按照热度排名
SELECT
t1.uploader,
v.videoid,
RANK() OVER(PARTITION BY t1.uploader ORDER BY v.views DESC) hot
FROM
t1
LEFT JOIN video_orc v ON
t1.uploader = v.uploader;
3.求每个人前20
SELECT
t2.uploader,
t2.videoid,
t2.hot
FROM
t2
WHERE hot<=20
完整sql:
SELECT
t2.uploader,
t2.videoid,
t2.hot
FROM
(
SELECT
t1.uploader,
v.videoid,
RANK() OVER(PARTITION BY t1.uploader
ORDER BY
v.views DESC) hot
FROM
(
SELECT
uploader,
videos
FROM
user_orc
ORDER BY
videos DESC LIMIT 10 )t1
LEFT JOIN video_orc v ON
t1.uploader = v.uploader )t2
WHERE
hot <= 20;

理解2:前十用户总榜前20
1 统计视频上传最多的用户Top10
SELECT
uploader,
videos
FROM
user_orc
ORDER BY
videos DESC
LIMIT 10;
2 观看数前20的视频
SELECT
videoid,
uploader,
views
FROM
video_orc
ORDER BY
views DESC
LIMIT 20;
3 联立两表 看看有没有他们上传的
SELECT
t1.uploader,
t2.videoid
FROM
t1
LEFT JOIN t2 ON
t1.uploader = t2.uploader;
8.5.8 统计每个类别视频观看数Top10
1 从video_category表查出每个类别视频观看数排名
SELECT
cate,
videoid,
views,
RANK() OVER(PARTITION BY cate ORDER BY views DESC) hot
FROM
video_category;
2 取每个类别的Top10
SELECT
cate,
videoid,
views
FROM
t1
WHERE
hot <= 10;
完整sql:
SELECT
cate,
videoid,
views
FROM
(
SELECT
cate,
videoid,
views,
RANK() OVER(PARTITION BY cate
ORDER BY
views DESC) hot
FROM
video_category )t1
WHERE
hot <= 10;
















 929
929











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









