







6. SparkCore项目实战
6.1 数据准备
本项目的数据是采集电商网站的用户行为数据,主要包含用户的4种行为:搜索、点击、下单和支付。
1)数据格式
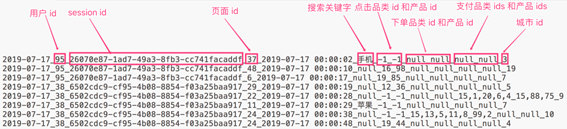
(1)数据采用_分割字段
(2)每一行表示用户的一个行为,所以每一行只能是四种行为中的一种。
(3)如果搜索关键字是null,表示这次不是搜索
(4)如果点击的品类id和产品id是-1表示这次不是点击
(5)下单行为来说一次可以下单多个产品,所以品类id和产品id都是多个,id之间使用逗号,分割。如果本次不是下单行为,则他们相关数据用null来表示
(6)支付行为和下单行为类似
2)数据字段详细说明
| 编号 | 字段名称 | 字段类型 | 字段含义 |
|---|---|---|---|
| 1 | date | String | 用户点击行为的日期 |
| 2 | user_id | Long | 用户的ID |
| 3 | session_id | String | Session的ID |
| 4 | page_id | Long | 某个页面的ID |
| 5 | action_time | String | 动作的时间点 |
| 6 | search_keyword | String | 用户搜索的关键词 |
| 7 | click_category_id | Long | 某一个商品品类的ID |
| 8 | click_product_id | Long | 某一个商品的ID |
| 9 | order_category_ids | String | 一次订单中所有品类的ID集合 |
| 10 | order_product_ids | String | 一次订单中所有商品的ID集合 |
| 11 | pay_category_ids | String | 一次支付中所有品类的ID集合 |
| 12 | pay_product_ids | String | 一次支付中所有商品的ID集合 |
| 13 | city_id | Long | 城市id |
6.2 需求1:Top10热门品类
需求说明:品类是指产品的分类,大型电商网站品类分多级,咱们的项目中品类只有一级,不同的公司可能对热门的定义不一样。我们按照每个品类的点击、下单、支付的量来统计热门品类。
6.2.1 需求分析一:

分别统计每个产品点击的次数,下单的次数,支付的次数
6.2.2 代码实现一:
package com.atguigu.spark.day07
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import scala.collection.mutable.ListBuffer
object Spark01_TopN_req1 {
def main(args: Array[String]): Unit = {
//创建Spark配置文件对象
val conf: SparkConf = new SparkConf().setAppName("Spark01_TopN_req1 ").setMaster("local[*]")
//创建SparkContext
val sc: SparkContext = new SparkContext(conf)
//1.读取数据,创建rdd
val dataRDD: RDD[String] = sc.textFile("E:\\spark-0701\\input\\user_visit_action.txt")
//2.将读到的数据进行切分,并且将切分的内容封装为UserVisitAction对象
val actionRDD: RDD[UserVisitAction] = dataRDD.map {
line => {
val fields: Array[String] = line.split("_")
UserVisitAction(
fields(0),
fields(1).toLong,
fields(2),
fields(3).toLong,
fields(4),
fields(5),
fields(6).toLong,
fields(7).toLong,
fields(8),
fields(9),
fields(10),
fields(11),
fields(12).toLong
)
}
}
//3.判断当前这条日志记录的是什么行为,并封装为结果对象(品类,点击数,下单数,支付数)
val infoRDD: RDD[CategoryCountInfo] = actionRDD.flatMap {
userAction => {
//判断是否为点击行为
if (userAction.click_category_id != -1) {
//封装输出结果对象
List(CategoryCountInfo(userAction.click_category_id.toString, 1, 0, 0))
} else if (userAction.order_category_ids != "null") {
//判断是否为下单行为,如果是下单行为,需要对当前订单中所有品类的id进行切分
val ids: Array[String] = userAction.order_category_ids.split(",")
//定义一个集合,用于存放多个品类id封装的输出结果对象
val categoryCountInfoList: ListBuffer[CategoryCountInfo] = ListBuffer[CategoryCountInfo]()
//对所有品类的id进行遍历
for (id <- ids) {
categoryCountInfoList.append(CategoryCountInfo(id, 0, 1, 0))
}
categoryCountInfoList
} else if (userAction.pay_category_ids != "null") {
//支付行为
val ids: Array[String] = userAction.pay_category_ids.split(",")
val categoryCountInfoList: ListBuffer[CategoryCountInfo] = ListBuffer[CategoryCountInfo]()
for (id <- ids) {
categoryCountInfoList.append(CategoryCountInfo(id, 0, 0, 1))
}
categoryCountInfoList
} else {
Nil
}
}
}
//4.将相同品类的放到一组
val groupRDD: RDD[(String, Iterable[CategoryCountInfo])] = infoRDD.groupBy(_.categoryId)
//将分组之后的数据进行聚合处理
val reduceRDD: RDD[(String, CategoryCountInfo)] = groupRDD.mapValues {
datas => {
datas.reduce {
(info1, info2) => {
info1.clickCount = info1.clickCount + info2.clickCount
info1.orderCount = info2.clickCount + info2.clickCount
info1.payCount = info1.payCount + info2.payCount
info1
}
}
}
}
//5.对上述RDD的结构进行转换,只保留value部分
val mapRDD: RDD[CategoryCountInfo] = reduceRDD.map(_._2)
//6.对RDD中的数据进行排序,取Top10
val res: Array[CategoryCountInfo] = mapRDD.sortBy(info => (info.clickCount, info.orderCount, info.payCount), false).take(10)
//7.打印输出
res.foreach(println)
//关闭连接
sc.stop()
}
}
//用户访问动作表
case class UserVisitAction(date: String, //用户点击行为的日期
user_id: Long, //用户的ID
session_id: String, //Session的ID
page_id: Long, //某个页面的ID
action_time: String, //动作的时间点
search_keyword: String, //用户搜索的关键词
click_category_id: Long, //某一个商品品类的ID
click_product_id: Long, //某一个商品的ID
order_category_ids: String, //一次订单中所有品类的ID集合
order_product_ids: String, //一次订单中所有商品的ID集合
pay_category_ids: String, //一次支付中所有品类的ID集合
pay_product_ids: String, //一次支付中所有商品的ID集合
city_id: Long) //城市 id
// 输出结果表
case class CategoryCountInfo(categoryId: String, //品类id
var clickCount: Long, //点击次数
var orderCount: Long, //订单次数
var payCount: Long) //支付次数
输出:
CategoryCountInfo(15,6120,0,1259)
CategoryCountInfo(2,6119,2,1196)
CategoryCountInfo(20,6098,0,1244)
CategoryCountInfo(12,6095,2,1218)
CategoryCountInfo(11,6093,0,1202)
CategoryCountInfo(17,6079,2,1231)
CategoryCountInfo(7,6074,2,1252)
CategoryCountInfo(9,6045,2,1230)
CategoryCountInfo(19,6044,2,1158)
CategoryCountInfo(13,6036,2,1161)
6.2.3 需求分析二
采用累加器,避免shuffle过程。
最好的办法应该是遍历一次能够计算出来上述的3个指标。使用累加器可以达成我们的需求。
(1)遍历全部日志数据,根据品类id和操作类型分别累加,需要用到累加器
定义累加器,当碰到订单和支付业务的时候注意拆分字段才能得到品类 id
(2)遍历完成之后就得到每个品类 id 和操作类型的数量.
(3)按照点击下单支付的顺序来排序
(4)取出 Top10

6.3 需求2:Top10热门品类中每个品类的Top10活跃Session统计
6.3.1 需求分析
- 需求描述
对于排名前10的品类,分别获取每个品类点击次数排名前10的sessionId。(注意: 这里我们只关注点击次数,不关心下单和支付次数)
这个就是说,对于top10的品类,每一个都要获取对它点击次数排名前10的sessionId。这个功能,可以让我们看到,对某个用户群体最感兴趣的品类,各个品类最感兴趣最典型的用户的session的行为。 - 分析思路
通过需求1,获取TopN热门品类的id
将原始数据进行过滤(1.保留热门品类 2.只保留点击操作)
对session的点击数进行转换 (category-session,1)
对session的点击数进行统计 (category-session,sum)
将统计聚合的结果进行转换 (category,(session,sum))
将转换后的结构按照品类进行分组 (category,Iterator[(session,sum)])
对分组后的数据降序 取前10
6.3.2 代码实现
//需求2
//1.获取热门品类top10的品类id 来自需求1的结果
val ids: Array[String] = res.map(_.categoryId)
//ids可以进行优化,因为发送给Excutor中的Task使用,每一个Task都会创建一个副本,所以可以使用广播变量
val broadcastIds: Broadcast[Array[String]] = sc.broadcast(ids)
//2.将原始数据进行过滤(1.保留热门品类 2.只保留点击操作)
val filterRDD: RDD[UserVisitAction] = actionRDD.filter {
action => {
//只保留点击行为
if (action.click_product_id != -1) {
//同时确定是热门品类的点击
//集合数据为字符串类型,id是Long类型,需要进行转换
broadcastIds.value.contains(action.click_category_id.toString)
} else {
false
}
}
}
//3.对session的点击数进行转换(category_session,1)
val mapRDD1: RDD[(String, Int)] = filterRDD.map {
action => {
(action.click_category_id + "_" + action.session_id, 1)
}
}
//4.对session的点击数进行统计(category_session,sum)
val reduceRDD1: RDD[(String, Int)] = mapRDD1.reduceByKey(_ + _)
//5.将聚合的结果进行转换(category,(session,sum))
val mapRDD2: RDD[(String, (String, Int))] = reduceRDD1.map {
case (categoryAndSession, sum) =>
(categoryAndSession.split("_")(0), (categoryAndSession.split("_")(1), sum))
}
//6.将转换后的结构按照品类分组(category,Iterator[(session,sum)])
val groupRDD2: RDD[(String, Iterable[(String, Int)])] = mapRDD2.groupByKey()
//7.对分组之后的数据降序,取前十
val resRDD2: RDD[(String, List[(String, Int)])] = groupRDD2.mapValues {
datas => {
datas.toList.sortWith {
case (left, right) => {
left._2 > right._2
}
}.take(10)
}
}
//8.打印输出
resRDD2.foreach(println)
输出:
(7,List((a41bc6ea-b3e3-47ce-98af-48169da7c91b,9), (9fa653ec-5a22-4938-83c5-21521d083cd0,7), (f34878b8-1784-4d81-a4d1-0c93ce53e942,7), (2d4b9c3e-2a9e-41b6-9573-9fde3533ed89,7), (95cb71b8-7033-448f-a4db-ae9861dd996b,7), (4dbd319c-3f44-48c9-9a71-a917f1d922c1,7), (aef6615d-4c71-4d39-8062-9d5d778e55f1,7), (a96c0b6b-f0e3-4bc5-9780-6c1046c335af,6), (22421bea-8f9b-4d76-b10d-9ca91f1d9403,6), (f666d6ba-b3e8-45b1-a269-c5d6c08413c3,6)))
(9,List((199f8e1d-db1a-4174-b0c2-ef095aaef3ee,9), (329b966c-d61b-46ad-949a-7e37142d384a,8), (5e3545a0-1521-4ad6-91fe-e792c20c46da,8), (bed60a57-3f81-4616-9e8b-067445695a77,7), (8f9723a3-833d-4103-a7ff-352cd17de067,7), (cbdbd1a4-7760-4195-bfba-fa44492bf906,7), (f205fd4f-f312-46d2-a850-26a16ac2734c,7), (8a0f8fe1-d0f4-4687-aff3-7ce37c52ab71,7), (e306c00b-a6c5-44c2-9c77-15e919340324,7), (4f0261cc-2cb1-40e0-9ffb-5587920c1084,7)))
(12,List((22a687a0-07c9-4e84-adff-49dfc4fe96df,8), (73203aee-de2e-443e-93cb-014e38c0d30c,8), (a4b05ea2-2869-4f20-a82a-86352aa60e9f,8), (b4589b16-fb45-4241-a576-28f77c6e4b96,8), (a735881e-4c30-4ddc-a1d9-ef2069d5fb5b,7), (c32dc073-4454-4fcd-bf55-fbfcc8e650f3,7), (64285623-54ad-4a1f-ae84-d8f85ebf94c6,7), (89278c1a-1e33-45aa-a4b7-33223e37e9df,7), (4c90a8a8-91d0-4888-908c-95dad1c5194e,7), (ab16e1e4-b3fc-4d43-9c95-3d49ec26d59c,7)))
(20,List((199f8e1d-db1a-4174-b0c2-ef095aaef3ee,8), (7eacf77a-c019-4072-8e09-840e5cca6569,8), (85157915-aa25-4a8d-8ca0-9da1ee67fa70,7), (07b5fb82-da25-4968-9fd8-47485f4cf61e,7), (ab27e376-3405-46e2-82cb-e247bf2a16fb,7), (cde33446-095b-433c-927b-263ba7cd102a,7), (5e3545a0-1521-4ad6-91fe-e792c20c46da,7), (22e78a14-c5eb-45fe-a67d-2ce538814d98,7), (d500c602-55db-4eb7-a343-3540c3ec7a36,7), (215bdee7-db27-458d-80f4-9088d2361a2e,7)))
(19,List((fde62452-7c09-4733-9655-5bd3fb705813,9), (85157915-aa25-4a8d-8ca0-9da1ee67fa70,9), (d4c2b45d-7fa1-4eff-8473-42cecdaffd62,9), (329b966c-d61b-46ad-949a-7e37142d384a,8), (1b5e5ce7-cd04-4e78-9a6f-1c3dbb29ce39,8), (4d93913f-a892-490d-aa58-3a74b9099e29,7), (5e3545a0-1521-4ad6-91fe-e792c20c46da,7), (22e78a14-c5eb-45fe-a67d-2ce538814d98,7), (b61734fd-b10d-456d-b189-2e3fe0adf31d,7), (46e6b58a-ad5b-4330-9e67-bc2651f9c5e2,7)))
(15,List((632972a4-f811-4000-b920-dc12ea803a41,10), (5e3545a0-1521-4ad6-91fe-e792c20c46da,8), (66a421b0-839d-49ae-a386-5fa3ed75226f,8), (f34878b8-1784-4d81-a4d1-0c93ce53e942,8), (9fa653ec-5a22-4938-83c5-21521d083cd0,8), (e306c00b-a6c5-44c2-9c77-15e919340324,7), (524378b7-e676-43e6-a566-a5493a9058d4,7), (a9b9806c-90fb-4df1-94c6-d0fb12425fa3,7), (6bc240fb-ba5a-4661-b757-ab7d193055b3,7), (213bc2d5-be6b-49a3-9cb6-f9afc5b69b3d,7)))
(2,List((b4589b16-fb45-4241-a576-28f77c6e4b96,11), (66c96daa-0525-4e1b-ba55-d38a4b462b97,11), (f34878b8-1784-4d81-a4d1-0c93ce53e942,10), (25fdfa71-c85d-4c28-a889-6df726f08ffb,9), (ab27e376-3405-46e2-82cb-e247bf2a16fb,8), (0b17692b-d603-479e-a031-c5001ab9009e,8), (213bc2d5-be6b-49a3-9cb6-f9afc5b69b3d,8), (39cd210e-9d54-4315-80bf-bed004996861,8), (f666d6ba-b3e8-45b1-a269-c5d6c08413c3,8), (263af32c-a0f4-429d-9410-cc4cf15f16cf,7)))
(17,List((4509c42c-3aa3-4d28-84c6-5ed27bbf2444,12), (9bdc044f-8593-49fc-bbf0-14c28f901d42,8), (1b5ac69b-5e00-4ff3-8a5c-6822e92ecc0c,8), (dd3704d5-a2f9-40c1-b491-87d24bbddbdb,8), (bf390289-5c9d-4037-88b3-fdf386b3acd5,8), (0416a1f7-350f-4ea9-9603-a05f8cfa0838,8), (fde62452-7c09-4733-9655-5bd3fb705813,7), (b056f9a0-8010-415c-90f8-bab078ef322e,7), (abbf9c96-eca3-4ecf-9c44-04193eb4b562,7), (ab16e1e4-b3fc-4d43-9c95-3d49ec26d59c,7)))
(13,List((f736ee4a-cc14-4aa9-9a96-a98b0ad7cc3d,8), (329b966c-d61b-46ad-949a-7e37142d384a,8), (0f227059-7006-419c-87b0-b2057b94505b,7), (1fb79ba2-4780-4652-9574-b1577c7112db,7), (1b5e5ce7-cd04-4e78-9a6f-1c3dbb29ce39,7), (632972a4-f811-4000-b920-dc12ea803a41,7), (c0f70b31-fc3b-4908-af97-9b4936340367,7), (7eacce38-ffbc-4f9c-a3ee-b1711f8927b0,7), (5d2f3efb-be1c-4ee2-8fd5-545fd049e70c,6), (5e3545a0-1521-4ad6-91fe-e792c20c46da,6)))
(11,List((329b966c-d61b-46ad-949a-7e37142d384a,12), (99f48b83-8f85-4bea-8506-c78cfe5a2136,7), (2cd89b09-bae3-49b5-a422-9f9e0c12a040,7), (dc226249-ce13-442c-b6e4-bfc84649fff6,7), (4509c42c-3aa3-4d28-84c6-5ed27bbf2444,7), (e7f9a91d-ff65-4b5f-9488-2a3195e1d0c6,6), (5d2f3efb-be1c-4ee2-8fd5-545fd049e70c,6), (8fb4a0a9-e128-4d9a-8e11-fd4a9fd22474,6), (45e35ffa-f0e0-400e-a252-5605b4089625,6), (72564b51-db5d-4ea1-8085-81172be1bf09,6)))
6.4 需求3:页面单跳转化率统计
6.4.1 需求分析
- 需求描述
计算页面单跳转化率,什么是页面单跳转换率,比如一个用户在一次 Session 过程中访问的页面路径 3,5,7,9,10,21,那么页面 3 跳到页面 5 叫一次单跳,7-9 也叫一次单跳,那么单跳转化率就是要统计页面点击的概率
比如:计算 3-5 的单跳转化率,先获取符合条件的 Session 对于页面 3 的访问次数(PV)为 A,然后获取符合条件的 Session 中访问了页面 3 又紧接着访问了页面 5 的次数为 B,那么 B/A 就是 3-5 的页面单跳转化率.

产品经理和运营总监,可以根据这个指标,去尝试分析,整个网站,产品,各个页面的表现怎么样,是不是需要去优化产品的布局;吸引用户最终可以进入最后的支付页面。
数据分析师,可以此数据做更深一步的计算和分析。
企业管理层,可以看到整个公司的网站,各个页面的之间的跳转的表现如何,可以适当调整公司的经营战略或策略。
在该模块中,需要根据查询对象中设置的 Session 过滤条件,先将对应得 Session 过滤出来,然后根据查询对象中设置的页面路径,计算页面单跳转化率,比如查询的页面路径为:3、5、7、8,那么就要计算 3-5、5-7、7-8 的页面单跳转化率。
2)思路分析
读取原始数据
将原始数据映射为样例类
将原始数据根据session进行分组
将分组后的数据根据时间进行排序(升序)
将排序后的数据进行结构的转换(pageId,1)
计算分母-将相同的页面id进行聚合统计(pageId,sum)
计算分子-将页面id进行拉链,形成连续的拉链效果,转换结构(pageId-pageId2,1)
将转换结构后的数据进行聚合统计(pageId-pageId2,sum)
计算页面单跳转换率

6.4.2 代码实现
object Spark03_TopN_req3 {
def main(args: Array[String]): Unit = {
//创建Spark配置文件对象
val conf: SparkConf = new SparkConf().setAppName("Spark03_TopN_req3 ").setMaster("local[*]")
//创建SparkContext
val sc: SparkContext = new SparkContext(conf)
//需求1
//1.读取数据,创建rdd
val dataRDD: RDD[String] = sc.textFile("E:\\spark-0701\\input\\user_visit_action.txt")
//2.将读到的数据进行切分,并且将切分的内容封装为UserVisitAction对象
val actionRDD: RDD[UserVisitAction] = dataRDD.map {
line => {
val fields: Array[String] = line.split("_")
UserVisitAction(
fields(0),
fields(1).toLong,
fields(2),
fields(3).toLong,
fields(4),
fields(5),
fields(6).toLong,
fields(7).toLong,
fields(8),
fields(9),
fields(10),
fields(11),
fields(12).toLong
)
}
}
//需求3
//1.对当前日志中记录的访问页面进行计数
val pageIdRDD: RDD[(Long, Long)] = actionRDD.map {
action => {
(action.page_id, 1L)
}
}
//2.通过页面的计数,计算每一个页面出现的总次数,作为求单跳转换率的分母
val fmIdsMap: Map[Long, Long] = pageIdRDD.reduceByKey(_ + _).collect().toMap
//3.计算分子
//3.1 将原始数据按照sessionId进行分组
val sessionRDD: RDD[(String, Iterable[UserVisitAction])] = actionRDD.groupBy(_.session_id)
//3.2将分组后的数据按照时间升序排序
val pageFlowRDD: RDD[(String, List[(String, Int)])] = sessionRDD.mapValues {
datas => {
//得到排序后的同一个session的用户访问行为
val userActions: List[UserVisitAction] = datas.toList.sortWith {
(left, right) => {
left.action_time > right.action_time
}
}
//3.3 对排序后的用户访问行为进行结构转换,只保留页面就可以
val pageIdList: List[Long] = userActions.map(_.page_id)
//3.4 对当前会话用户访问页面,进行拉链,得到页面的流转情况
//A->B->C->D->E->F
//B->C->D->E->F
val pageFlows: List[(Long, Long)] = pageIdList.zip(pageIdList.tail)
//3.5 对拉链后的数据,进行结构的转换(页面A-页面B,1)
pageFlows.map {
case (pageId1, pageId2) => {
(pageId1 + "-" + pageId2, 1)
}
}
}
}
//3.6 将每一个会话的页面跳转统计完毕之后,就没有必要保留会话信息了,所以对上述RDD进行结构转换
//只保留页面跳转以及计数
val pageFlowMapRDD: RDD[(String, Int)] = pageFlowRDD.map(_._2).flatMap(list => list)
//3.7 对页面跳转情况进行聚合操作
val pageAToPageBSumRDD: RDD[(String, Int)] = pageFlowMapRDD.reduceByKey(_ + _)
//4.页面单跳转换率
pageAToPageBSumRDD.foreach {
//(pageA-pageB,sum)
case (pageFlow, fz) => {
val pageIds: Array[String] = pageFlow.split("-")
//获取分母页面id
val fmPageId: Long = pageIds(0).toLong
//获取分母页面总访问数
val fmSum: Long = fmIdsMap.getOrElse(fmPageId, 1L)
//转换率
println(pageFlow + "---->" + fz.toDouble / fmSum)
}
}
//关闭连接
sc.stop()
}
}
输出(部分):
44-33---->0.012592389816589104
8-14---->0.02157880360557225
13-5---->0.018207282913165267
11-17---->0.022417707150964812
18-42---->0.017152191668935474
9-45---->0.016699137211244084
14-48---->0.021462863597853713
42-42---->0.016549104720564298
27-26---->0.019912711402073104
7-30---->0.01918194640338505
1-17---->0.01868131868131868
...














 208
208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









