






Self attention
基本流程:self-attention的输入是众多的vector,输出也是众多的vector,新的vector是考虑过全部的信息的数据,然后再通过FC。
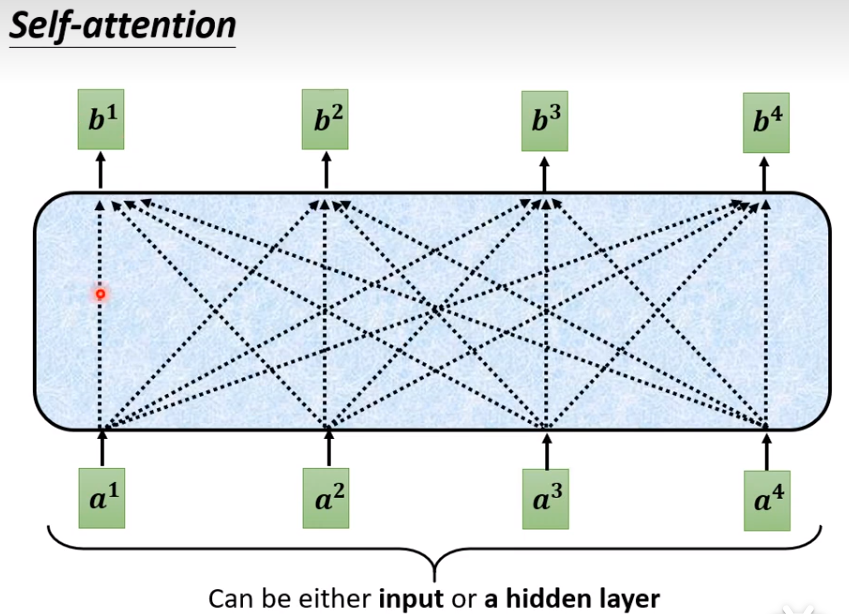
举例:如何产生b1
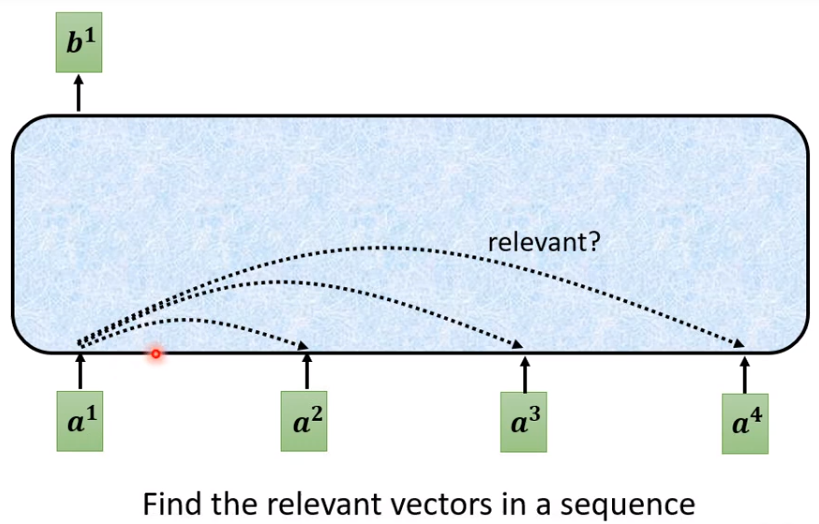
1、计算a1和其他的所有向量的关联程度
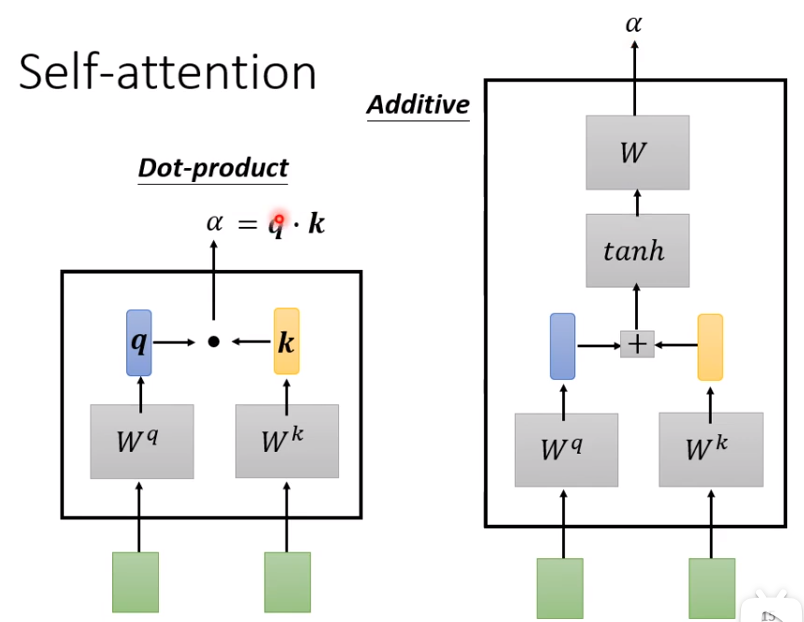
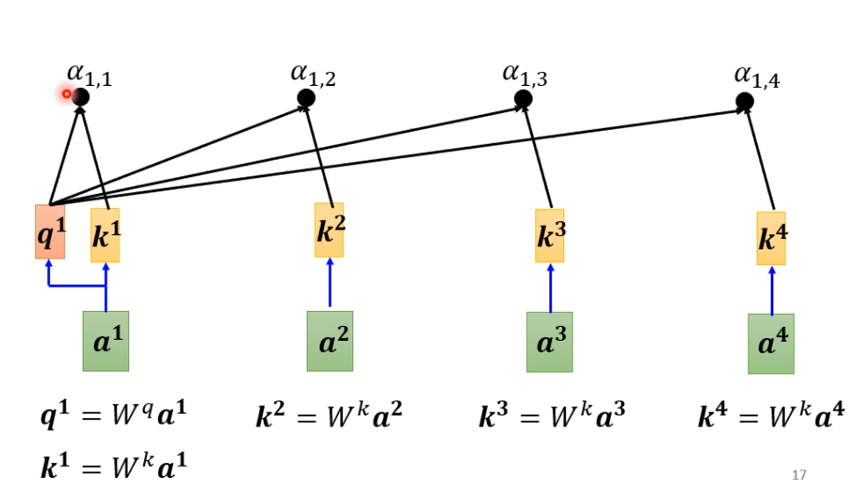
(1)提供一种思路:假设a1与a1计算关联度,a1(100×100)与a2(100×100),a1通过一个权重参数W_q矩阵(100×1),a2通过一个权重参数W_k矩阵(100×1),就可以的新的vector,q=(100×1),k=(100×1);再通过一个转置和dot就一个得到一个数字
(2)记得自己也要进行一个关联度计算
2、将所有计算得到的关联度进行一个softmax(relu,sigmoid都可以)
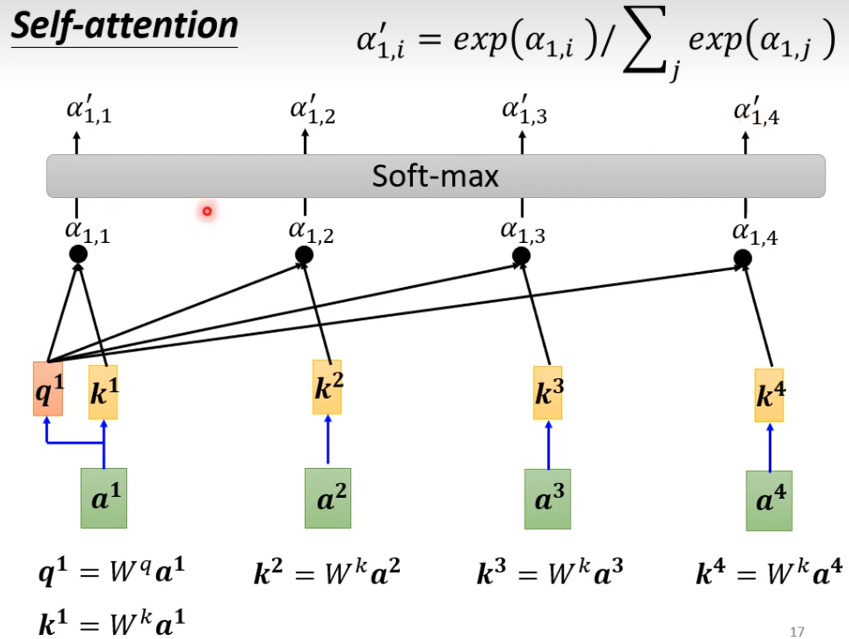
3、利用关联程度来抽取信息
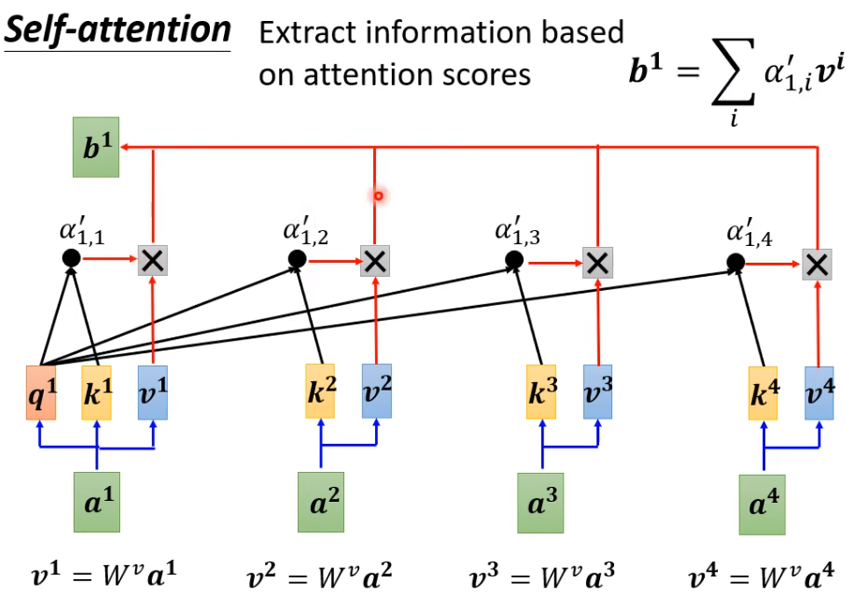
(1)所有向量a_i通过W_v(可以保持原有维度不改变)得到v_i,
(2)将每一个向量乘上当前关联程度,再进行一个sum就可以得到b1,
(3)值得注意的是如何关联程度越大,那么其对原来有的向量影响程度越大。
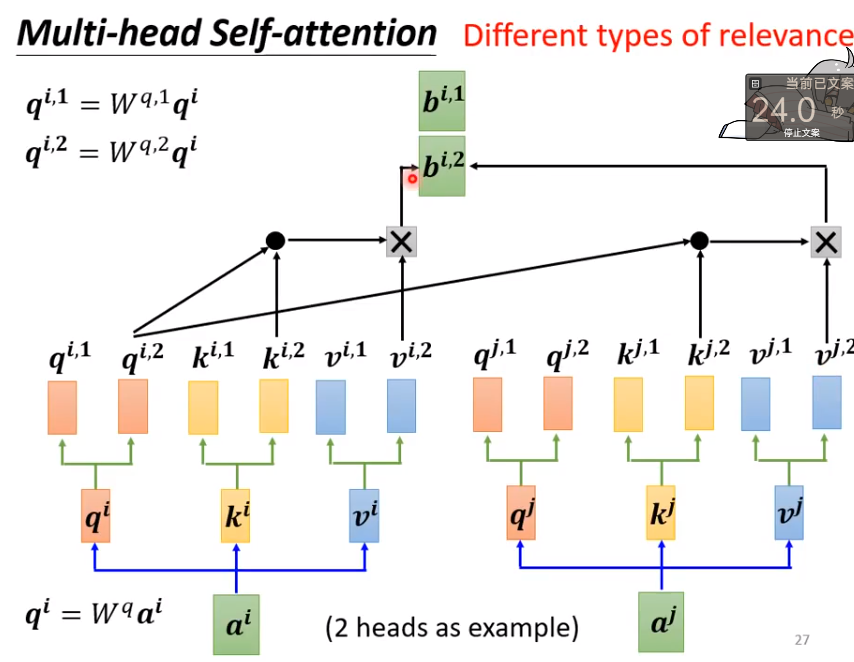
Multi-head Self-attention
当我们希望q,k,v向量可以存在多种的联系的时候,那么我们则需要使用多组参数来传播这些数据,通过排列组合不同q,不同k,不同的v,就可以得到多组的b,在通过一些变化就可以,合并到一个b上

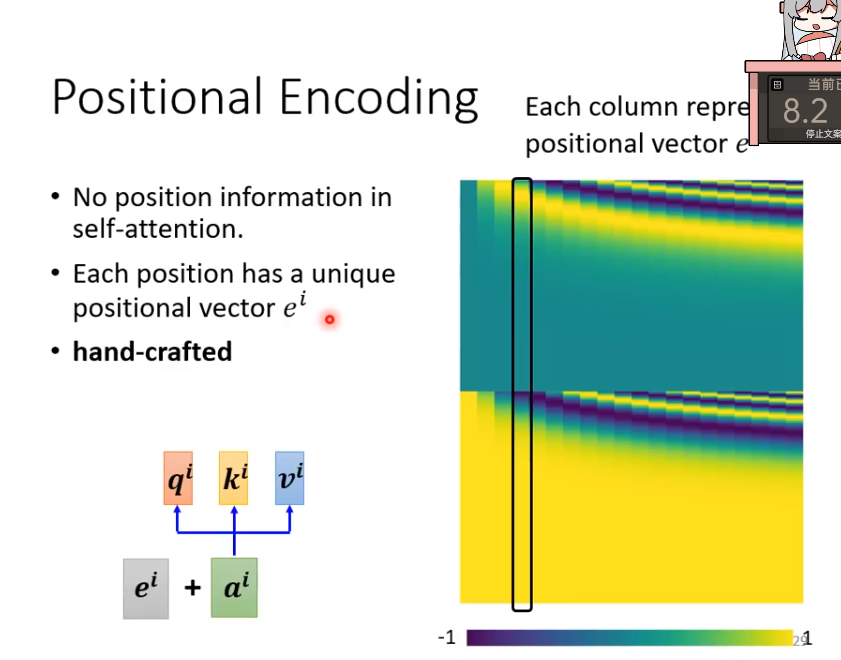
Positional Encoding
假设我们在进行NLP任务,那么输入的每一个词的顺序必然是有意义的,那么这里提供一种思路:就是将位置的信息进行编码,得到一个embedding加入在输入特征中,就可以得到一个新的带有位置信息的特征vector了。















 1443
1443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









