







摘要
- CNN和Transformer存在固有缺点,基于空间状态模型的Mamba可以弥补两种体系结构的不足。
- 本文定制了三个框架:MambaBCD、MambaSCD和MambaBDA,分别用于二进制变化检测(BCD)、语义变化检测(BCD)和构建损伤评估(BDA)。
- 三个都采用了视觉Mamba作为编码器,允许从输入图像种学习全局空间上下文信息。对于解码器,提出三种时空关系建模机制,可以自然的和Mamba结构结合,充分利用其属性,实现多时特征的时空交互,获得准确的变化信息。
- 论文链接:https://arxiv.org/abs/2404.03425
- 代码链接:https://github.com/ChenHongruixuan/MambaCD
方法
ChangeMamba总体结构如下:
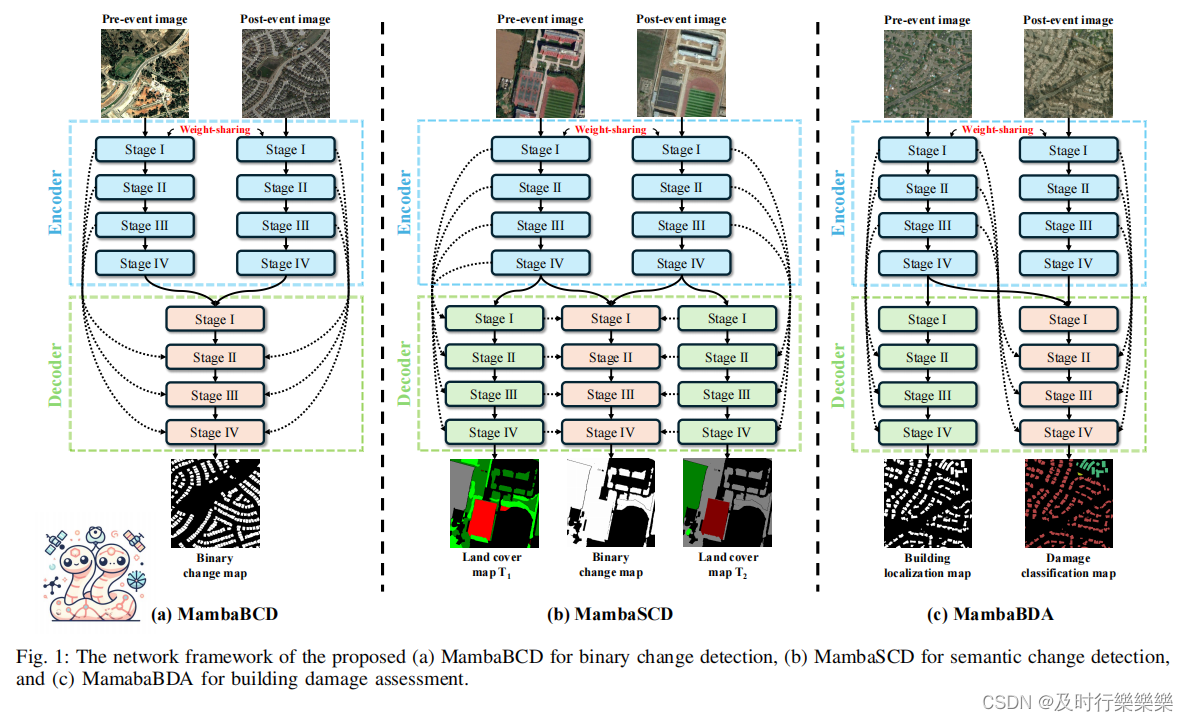
三个CD子任务,基于Mamba架构设计了相应的架构(MambaBCD、MambaSCD和MamabBDA)。
- 编码器均是VMamba架构的权重共享孪生网络。可以充分提取输入图像的鲁棒性和代表性特征。VMamba可以充分地利用Mamba体系结构和高效的二维交叉扫描机制,提取输入图像的鲁棒性和代表性特征(如图3所示)。
- MambaBCD:孪生编码器网络从输入图像中提取多层特征,多级特性被输入到一个定制的变化解码器中。基于Mamba架构,变化解码器可以通过三种不同的机制从多层次特征中充分学习时空关系,并逐步获得准确的BCD结果。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









