









摘要
- 现有的CNN和基于Transformer的框架往往难以准确的分割语义变化区域。且,基于标准自注意力的Transformer方法对图像分辨率存在二次计算复杂度,使得在训练数据有限的CD任务种不太实用。
- 为此,提出孪生的高效变化检测框架ELGC-Net,利用丰富的上下文信息来精确分割变化区域,同时减少模型的大小。ELGC-Net包含一个孪生编码器、融合模块和一个解码器。
- 编码器:引入一个Efficient Local-Global Con-text Aggregator(ELGCA)模块,增强全局上下文和局部空间信息,同时解决标准自注意力的局限性。
- PT捕获全局上下文信息。
- 采用池化操作进行特征提取,并通过transpose注意力最小化计算成本。
- 深度卷积对局部上下文进行编码。
- PT捕获全局上下文信息。
- 编码器:引入一个Efficient Local-Global Con-text Aggregator(ELGCA)模块,增强全局上下文和局部空间信息,同时解决标准自注意力的局限性。
- 大量实验表明,ELGC-Net优于现有方法,在提高精度的同时显著减少了训练参数。
- 还介绍了ELGC-Net-LW,是一种更轻量化的变体,显著降低了计算复杂度,在不影响CD精度的情况下,满足计算资源有限的场景。
- 论文链接:https://arxiv.org/abs/2403.17909
- 代码链接:GitHub - techmn/elgcnet: ELGC-Net: Efficient Local-Global Context Aggregation for Remote Sensing Change Detection
动机
以往的一些方法依赖于标准的自注意力,与编码器中tokens的数量呈二次复杂度。大量的参数、高内存占用和高FLOPs使得这些方法不太适合用于实际的遥感变化检测应用。因此,希望同时捕获局部-全局上下文信息,有效地检测图像对之间的细微和显著的结构变化。
方法
总体架构如图3所示:
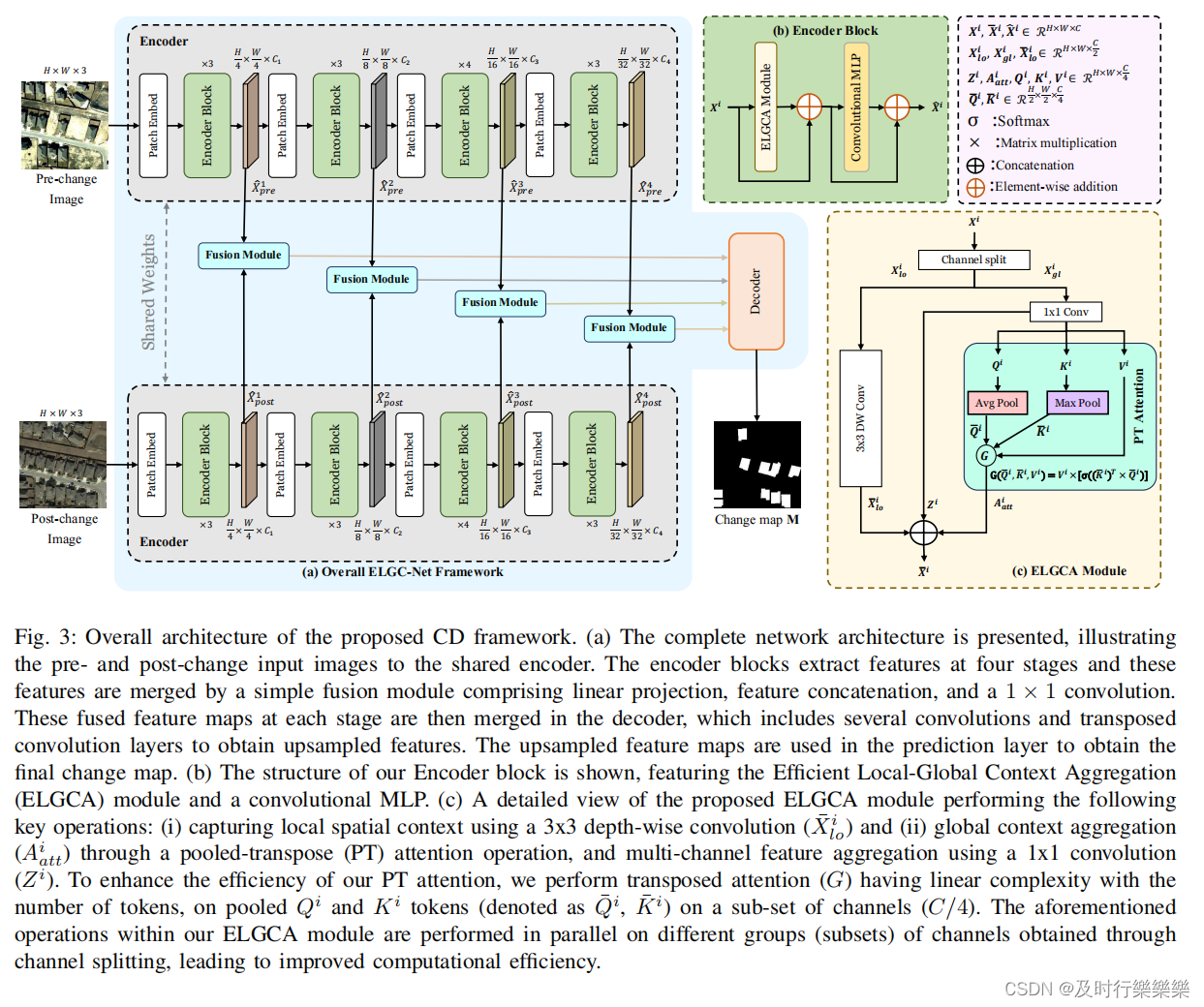
ELGC-Net:孪生编码器分为四个阶段,在每个阶段,特征图首先通过一个patch嵌入层进行降采样。然后进入编码块,编码块由ELGCA和一个卷积MLP层组成。对每个阶段得到的双时态特征通过融合模块进行融合,将融合的特征送入解码器进行变化图预测。
- 孪生编码器
- ELGCA:聚合局部和全局上下文信息,提高预测变化图的准确性,同时减少参数和FLOPs。
- 将通道分为不同的组,将它们输入两个独立的上下文聚合器中,以获得局部和全局上下文信息。设第i阶段ELGCA模块的输入特征为
,首先对输入特征进行通道分割,得到
,从中得到PT注意力和局部上下文聚合器的输入。
- PT注意力:该注意力具有线性复杂度,对
进行1x1卷积,并将其分别分解为
特征(后三个分别作为PT捕获全局上下文信息的query,key,value)。分别对
进行3x3平均池化和2x2最大池化操作,获得
,对轻微变化具有鲁棒性。然后在
嵌入之间采用转置注意力G。最后获得的特征表示
。
- 局部上下文聚合器:对
执行3x3卷积操作,得到特征表示
。这种基于深度卷积的局部上下文聚合器以最小的模型参数和FLOPs有效的捕获了局部上下文信息,并减轻了对位置嵌入的要求。
- 最终,使用concatenation操作将具有不同感受野的局部和全局上下文聚合特征进行合并,以获得丰富的局部-全局上下文聚合特征
。ELGCA模块不同于上下文聚合器顺序使用,它以并行的方式利用通道的不同子集分别使用上下文聚合器,降低了计算复杂度。
- 将通道分为不同的组,将它们输入两个独立的上下文聚合器中,以获得局部和全局上下文信息。设第i阶段ELGCA模块的输入特征为
- 卷积MLP层
- ELGCA:聚合局部和全局上下文信息,提高预测变化图的准确性,同时减少参数和FLOPs。
- 融合模块
- 包括linear projection,feature concatenation, 1 × 1 convolution operation,减少通道数量。
- 解码器
- 包括卷积层、转置卷积层,如图4。
- 四个阶段的多尺度融合特征,沿通道维度链接并输入1x1卷积层。
- 然后,应用转置卷积来提高特征映射的空间分辨率。用两个3x3卷积层组成残差块来增强特征映射。再用和残差块组合的转置卷积获得与输入相同空间维数的特征映射。
- 最后应用3x3卷积获得两通道的预测分数(第一个通道是无变化类分数,第二个是变化类分数),利用argmax得到二进制变化映射。

实验
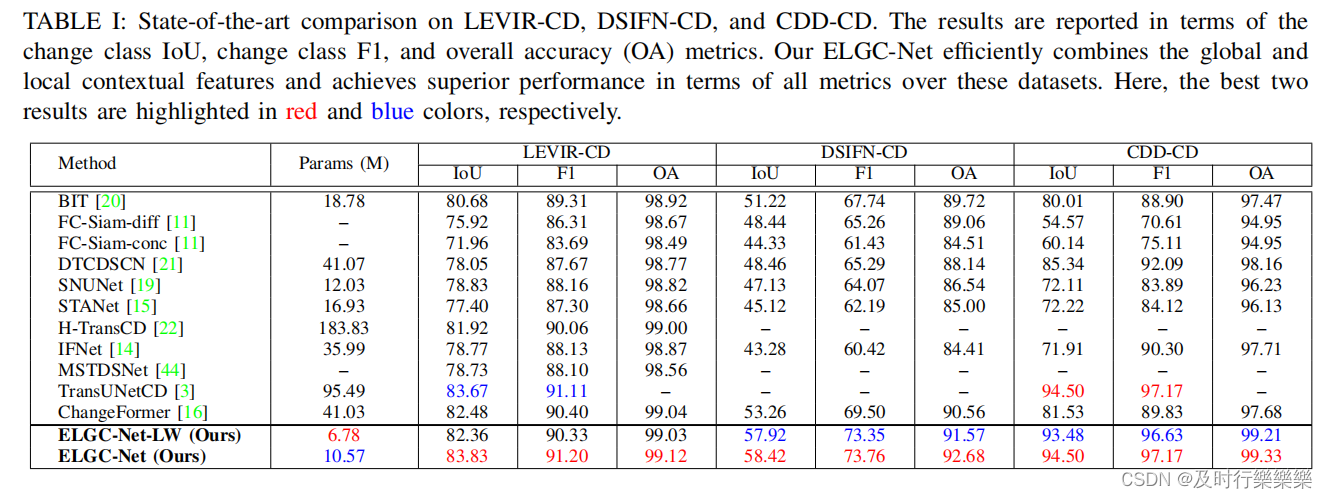
State-of-the-art Quantitative Comparison
Qualitative Comparison



Ablation of contextual features in ELGCA module:
Ablation Study

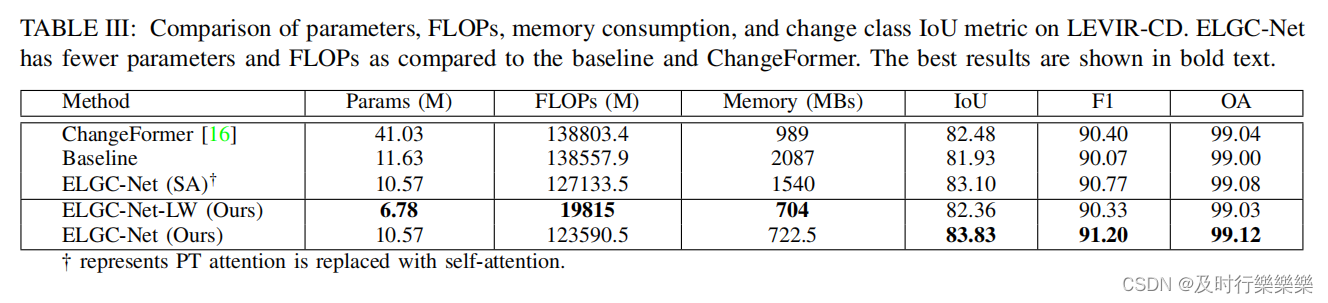
Comparison of Parameters and FLOPs:
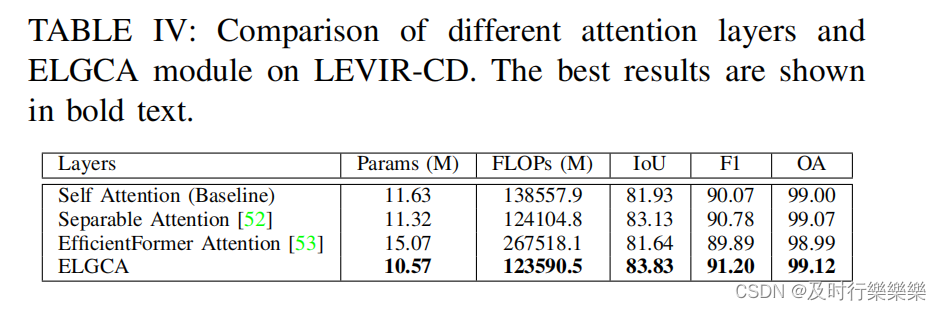
Comparison between other context aggregators and
Our’s ELGCA :
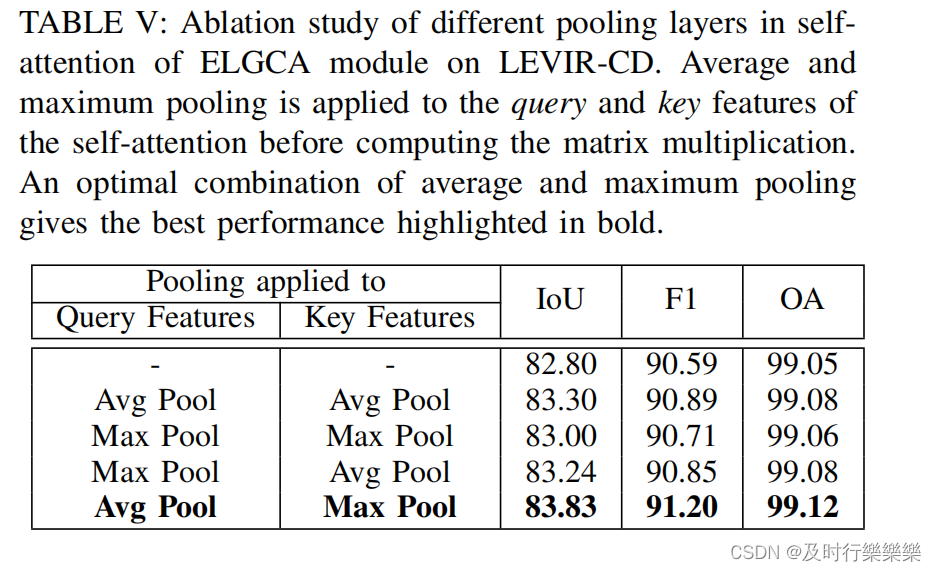
Ablation of pooling layers in ELGCA:
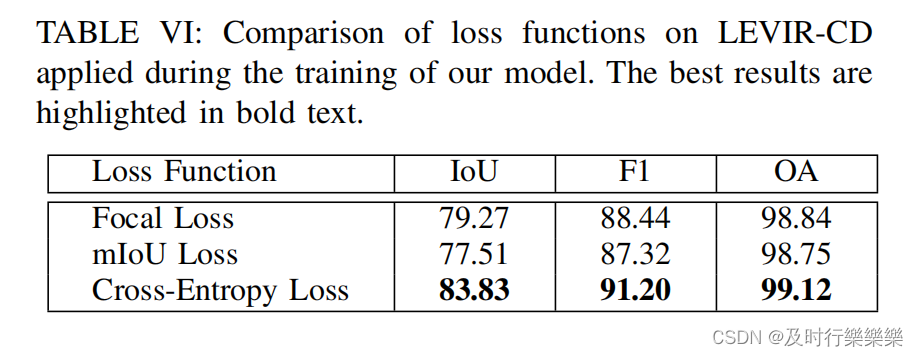
Ablation of losses applied during training of ELGCA:















 1658
1658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









