









目录
SBO 算法[1](School Based Optimization Algorithm, SBO)是Farshchin等 于 2018 年提出的一种新型基于人类群体智能行为开发的元启发式算法。该算法受学校内多班级教学模式的启发,拓展了教与学优化算法中的单一课堂教学模式,提出多班级协作教学的优化模式。SBO 算法针对这一问题引入多班级协作框架,解决了终止准则中参数复杂性的问题,具有参数少、搜索能力强等优势。
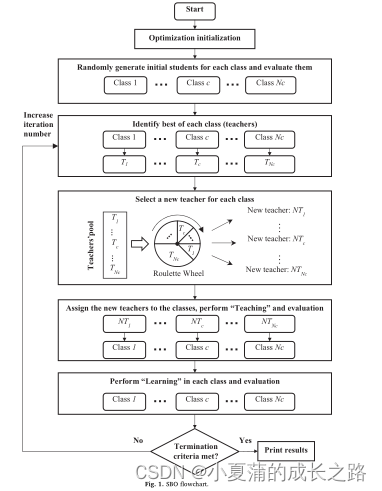
算法原理
常见的元启发式算法通过随机生成一个潜在解的初始群体,然后在一个系统的优化过程中逐步提高群体的整体适应度,这种方式只允许群体内部协作。更复杂的方法是利用一系列独立的并行群体进行协作,从而扩展算法的探索能力并提高算法的整体效率。这种多种群协作的方法包含两个阶段,第一阶段采用独立的元启发式方法探索不同群体区域的搜索空间,第二阶段探索子区域内最有前途的解方案。
SBO具有一名教师的单课堂教学环境(TLBO)扩展到具有多个教室和多个教师的学校。在SBO算法中,独立教室同时探索搜索空间,每个教室使用TLBO;然后,在每次迭代结束时,集合一组教师(每个教室一名教师)。在下一次迭代之前,根据教师的适应值,使用轮盘赌机制将教师分配到教室。此外,每一个新分配给每个教室的老师都应该比现在的老师有更好的适应能力。
在 SBO 算法中,每个候选解表示各班级中的学生个体,解分量分别表示各个科目,一轮迭代表示一次教与学的过程。SBO算法的搜索过程包括教师分配、教阶段和学阶段,算法通过三个过程的联合作用,逐步实现班级水平的提高。
教师分配
首先比较各个班级内学生个体的适应度值,分别选出班级最优生,构成一支优秀教师团队;其次通过轮盘赌选择机制依次从这批教师中随机选择一名教师分配到各班级中,执行教学任务。后面每个班级中都进行教与学算法TLBO的更新。对于TLBO本栏目也有专门的详细介绍,可以翻看记录查找学习。
教阶段
学生尽量向教师水平靠拢。学习后的更新方程式表示如下:
其中其中,
分别表示教学前后学生 i 在科目 D 的水平,Δi 表示学生 i 通过课堂教学所汲取的知识,使用教师
与班级平均值 M 的差值表示,TF 为教学因子,用于描述学生从课堂教学中获取知识的程度,取值为 1 或 2。r是随机数(0,1)。这里使用的平均数不是传统的平均值的算法,而是使用学生个体的适应度值 Fi 来描述班级平均水平 M,这种方式的搜索效率较优。公式如下所示:
学阶段
学生 i 随机选择班级内另外一位学生 j 进行学习和交流,同时,综合自身已掌握的知识情况,进行学习更新,更新方程如式:
流程图
- 初始化随机创建Nc个班级
- 在每个班级中挑选出最优秀的一个学生粒子作为老师,将这些老师作为一个老师库T1-Tnc
- 使用轮盘赌的方法,将老师库中的老师顺序打乱,在重新分配到教室中
- 对每个教室使用TLBO算法训练学生粒子
- 判断条件,直到输出最优值
主要代码
function SBO
global D
% Specity SBO parameters
Itmax=300; % Maximum number of iterations
NClass=5; % Number of classes in the school
PopSize=15; % Population size of each class
% Optimization problem parameters
D=Data10; % For truss function evaluate the functio to get the initial parameters
LB=D.LB; % Lowerbound
UB=D.UB; % Upperbound
FN='ST10'; % Name of analyzer function
%% Randomely generate initial designs between LB and UB
Cycle=1;
for I=1:PopSize
for NC=1:NClass
Designs{NC}(I,:)=LB+rand(1,size(LB,2)).*(UB-LB); % Row vector
end
end
% Analysis the designs
for NC=1:NClass
[PObj{NC},Obj{NC}]=Analyser(Designs{NC},FN);
Best{NC}=[];
end
%% SBO loop
for Cycle=2:Itmax
for NC=1:NClass
% Identify best designs and keep them
[Best{NC},Designs{NC},PObj{NC},Obj{NC},WMeanPos{NC}]=Specifier(PObj{NC},Obj{NC},Designs{NC},Best{NC});
TeachersPObj(NC,1)=Best{NC}.GBest.PObj;
TeachersDes(NC,:)=Best{NC}.GBest.Design;
end
for NC=1:NClass
% Select a teacher
SelectedTeacher=TeacherSelector(Best,NC,TeachersPObj);
% Apply Teaching
[Designs{NC},PObj{NC},Obj{NC}]=Teaching(LB,UB,Designs{NC},PObj{NC},Obj{NC},TeachersDes(SelectedTeacher,:),WMeanPos{NC},FN);
[Best{NC},Designs{NC},PObj{NC},Obj{NC},WMeanPos{NC}]=Specifier(PObj{NC},Obj{NC},Designs{NC},Best{NC});
% Apply Learning
[Designs{NC},PObj{NC},Obj{NC}]=Learning(LB,UB,Designs{NC},Obj{NC},PObj{NC},FN);
[Best{NC},Designs{NC},PObj{NC},Obj{NC},WMeanPos{NC}]=Specifier(PObj{NC},Obj{NC},Designs{NC},Best{NC});
end
% Find best so far solution and Mean
CumPObj=[];
for NC=1:NClass
ClassBestPObj(NC,1)=Best{NC}.GBest.PObj;
ClassMean(NC,1)=mean(PObj{NC});
CumPObj=[CumPObj;PObj{NC}];
end
[~,b]=min(ClassBestPObj);
OveralBestPObj=Best{b}.GBest.PObj;
OveralBestObj=Best{b}.GBest.Obj;
OveralBestDes=Best{b}.GBest.Design;
% Plot time history of the best solution vs. iteration and print the
% results
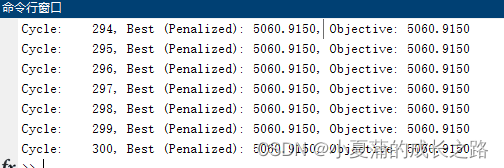
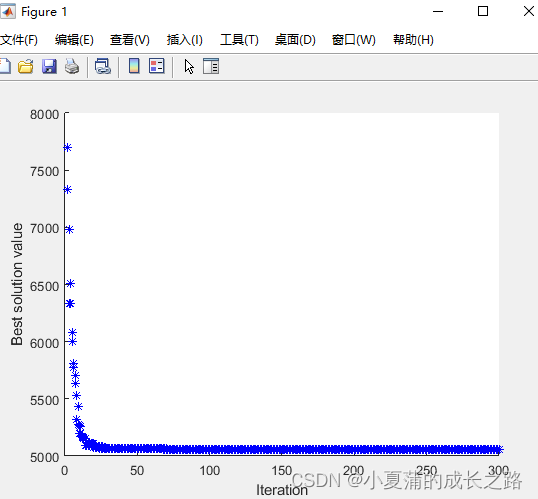
hold on;plot(Cycle,Best{b}.GBest.PObj,'b*');xlabel('Iteration');ylabel('Best solution value');pause(0.0001)
fprintf('Cycle: %6d, Best (Penalized): %6.4f, Objective: %6.4f\n',Cycle,OveralBestPObj,OveralBestObj);
end
Solution.PObj=OveralBestPObj;% Objective value for best non-penalized solution
Solution.Design=OveralBestDes;% Design for best non-penalized solution
%% Save the results
save('SBO_Results.mat','Solution')
仿真结果
参考文献
[1]Farshchin M, Maniat M, Camp C V, et al. School based optimization algorithm for design of steel frames[J]. Engineering Structures, 2018, 171: 326-335.















 1412
1412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









