







分享一下最近阅读yolov1的这篇论文理解,有不对请各位大佬指点。
论文地址:链接: https://pan.baidu.com/s/1EyXhYMdZutK5WsyowHZ7xw 提取码: 6666
目录
本人初入目标检测的大坑,前段时间学了R-CNN系列网络CV目标检测面试必备RCNN系列1_crlearning的博客-CSDN博客
CV目标检测面试必备Faster-RCNN源码讲解_crlearning的博客-CSDN博客
最近准备学习YOLO,目前YOLO的发展迅速,YOLOV6、v7都很强,但是我认为YOLOv1的一些基本思想还是需要了解一下,所以就阅读了YOLO的第一篇论文。接下来就是我对这篇论文简单的提炼,yolov3才是YOLO系列正式被广泛应用的开始,简单了解历史。
1、摘要
yolov1在2016年提出,它是一种one-stage算法。作者提出yolo的特点就是快,并且将bounding boxs和类别预测归为回归问题。
2、引言(YOLO的优点)
在R-CNN中,使用的是region proposal的方法生成预选框,然后在进行调整为建议框输入到网络中,而YOLO直接将图片作为输入,最后直接返回类别概率以及边框值。这就让YOLO有三个优点:
第一,YOLO速度极快。由于将检测映射到回归问题,不需要复杂的管道,只需在测试时对图像运行在网络模型中来预测结果。
第二,YOLO对图像进行全局处理。它并不像R-CNN那样需要生成预选框,这就使得YOLO对图像处理的时候看得的是整个图像。
第三,YOLO可泛化性强。由于读取的信息是整张图片,那么当接收到新的领域,模型也不会那么容易奔溃。
3、YOLO模型
3.1、主要思想
对每个输入的图片划分为S x S的单元格(grid cell),如果有一个目标的中心点落在某个单元格,则该单元格负责检测该物体。每个单元格预测B个bbox(边界框)和每个bbox的置信度(框中有目标的概率),置信度公式如下:
![]()
其中如果box中框住了目标,那么pr=1,否则就是背景pr=0。这样就可以使得当box中有物体时,置信度为IOU,预测框和真实框的交并比。此外每个box还有x,y,w,h四个值来预测box的位置。
同时,每个单元格还需预测类别概率Pr(Classi|Object),当单元格中的box存在目标的中心时,则预测该类别。
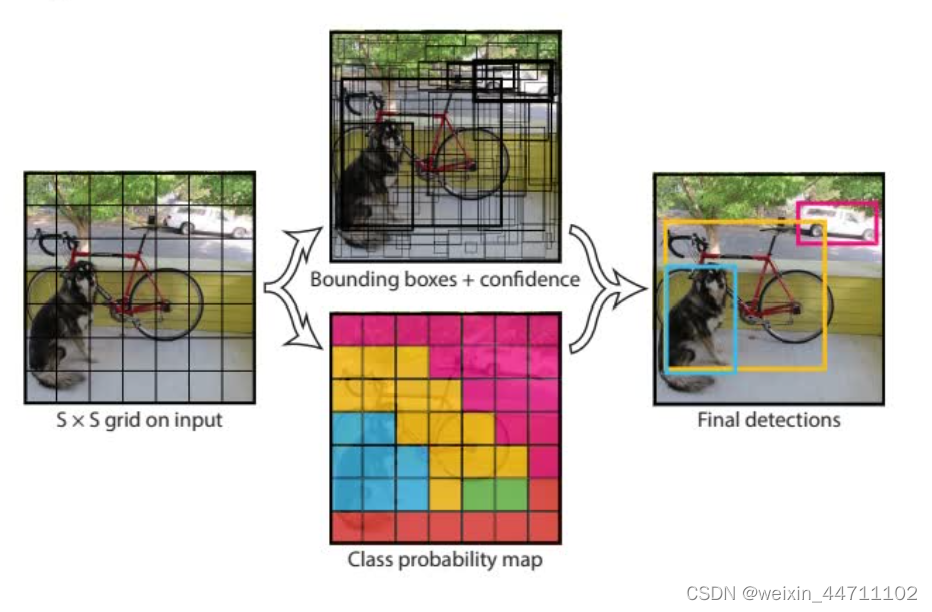
上图为原论文中给出的,一部分时预测bbox的位置以及置信度,另外一部分用来预测类别,最后结合输出。
3.2、网络模型设计
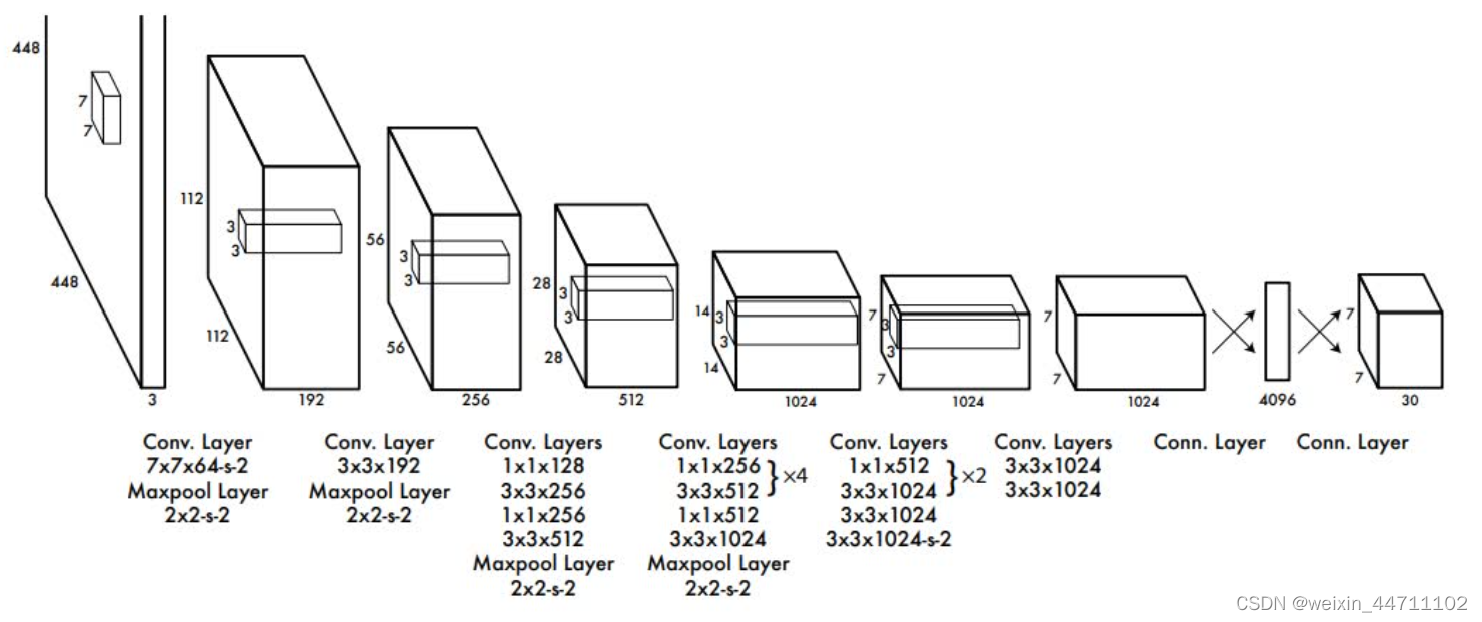
上图是论文中给的网络模型图包括24层卷积层和2个全连接层,其中全连接使用1 x 1的卷积保证空间信息不丢失,作者根据GoogleNet的启发而构建的,前面的6块卷积是为了提取出图像特征,然后后面的全连接预测bbox的坐标和类别概率。
输入为448 x 448 x 3,输出为7 x 7 x 30的tensor,其中7 x 7为上诉的网格数,s = 7,其中30的通道数为(4 + 1)x 2 + 20,其中4+1表示每个box的4个坐标信息(x,y,w,h)和一个置信度值,每个单元格中包括2个box所以需要 x 2,最后的20表示单元格对20个种类的分类概率。
3.3、损失函数

图中为论文中提出的loss函数公式,可以把他分为三类,分别是bbox的边框误差,bbox的置信度误差,单元格的分类误差。其中i表示单元格,j表示每个单元格对应的box,obj表示存在目标物体(前景),入表示权重。其中第二行的宽高损失使用根号为了确保大边框和小边框的宽高差损失差距不大。
其中使用非极大值抑制的方法过滤掉重复的边框,减少不必要的计算。
4、结果对比
在原论文中,作者提出yolov1对密集小目标的预测准确度不够,并且由于下采样的层数较多,对一些未知的图像信息准度不够。最后就是yolov1在loss中对小预测框的误差和大预测框的误差权重一样,比如相同的误差,在大框中可能只是微小的偏移,但是在小框中可能是致命的。但这些缺陷在后面的v2v3中解决了。
下面看看yolov1在数据集上的效果:

上面图表可以看出yolo的速度有一个显著的提升,map值也不低

这张图表展示了 两个模型对预测的误差,其中yolo对背景的误差降低了许多,主要原因是将整张图片输入网络中,信息齐全,容易分辨。















 3410
3410











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











