









目录
一、学习目标
- 根据卷积的输出结果,理解卷积运算的过程。
- 掌握模型可视化的方法。
二、学习内容
把模型变为用imagenet数据预训练好ResNet50,对dog.1.jpg图像数据,输出Resnet50前8层的某个通道的图像,分析相应的结果。
三、学习过程
用imagenet预训练好残差网络,对dog.1.jpg图像数据,使用Adam优化器,学习率设置为0.0001,图片大小为150*150,batch_size为16,训练15代的结果:
模型各层的输出大小:
|
|
|

训练15代的效果:

训练过程的分类精度和损失函数的变化图:
|
|
|
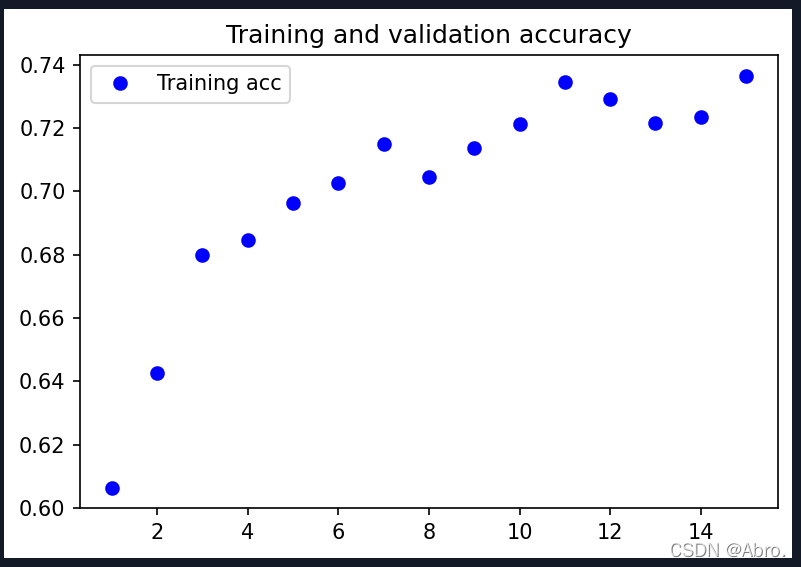
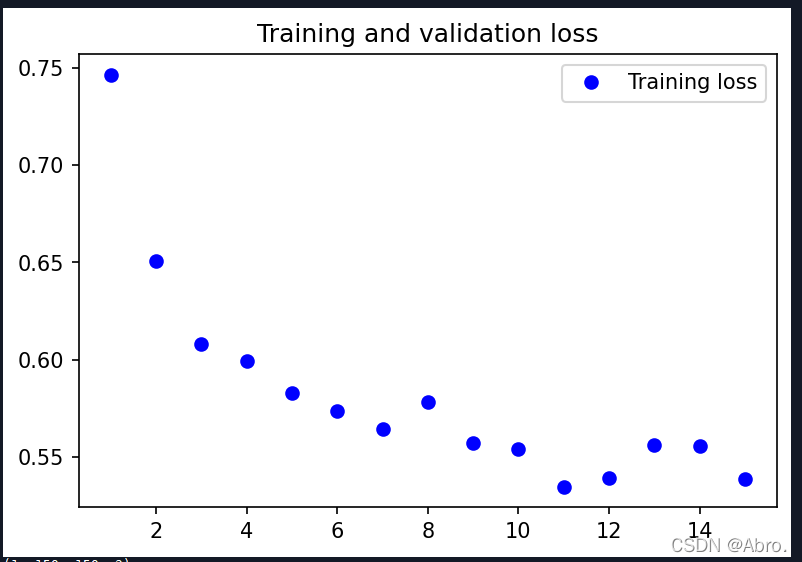
测试集的准确率最终能达到0.7257。
原图像和第1个通道可视化后的图像:
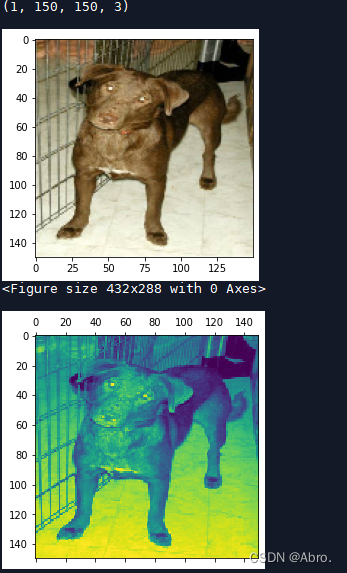
| 可视化第1个通道的图像 |
|
| 可视化第2个通道的图像 |
|
| 可视化第3个通道的图像 |
|
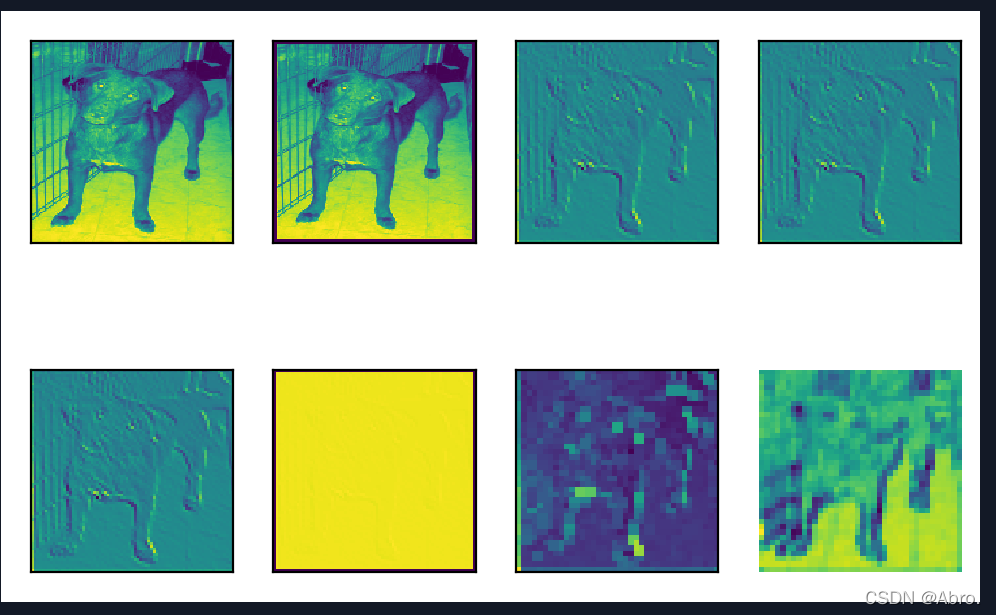
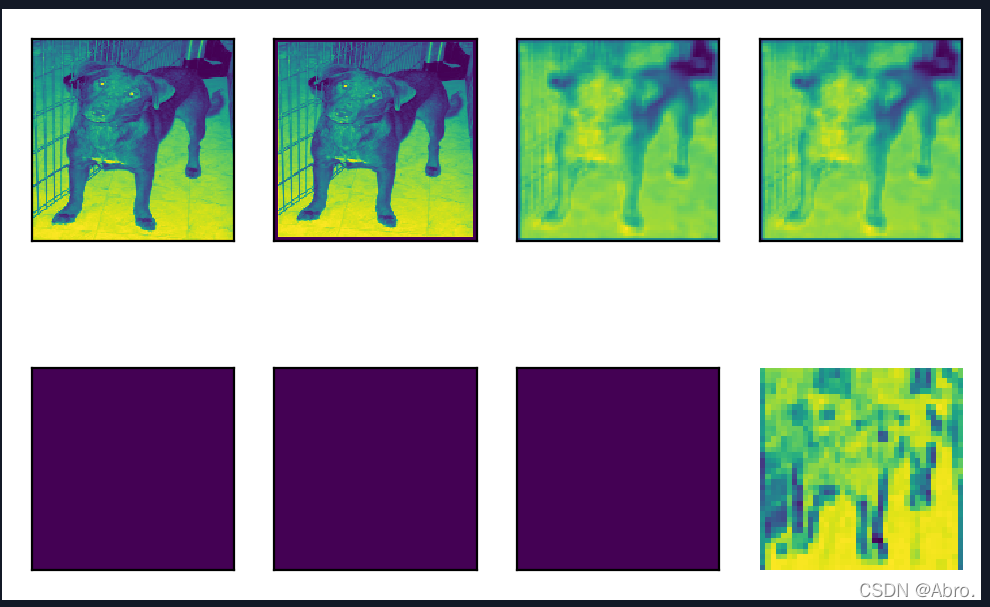
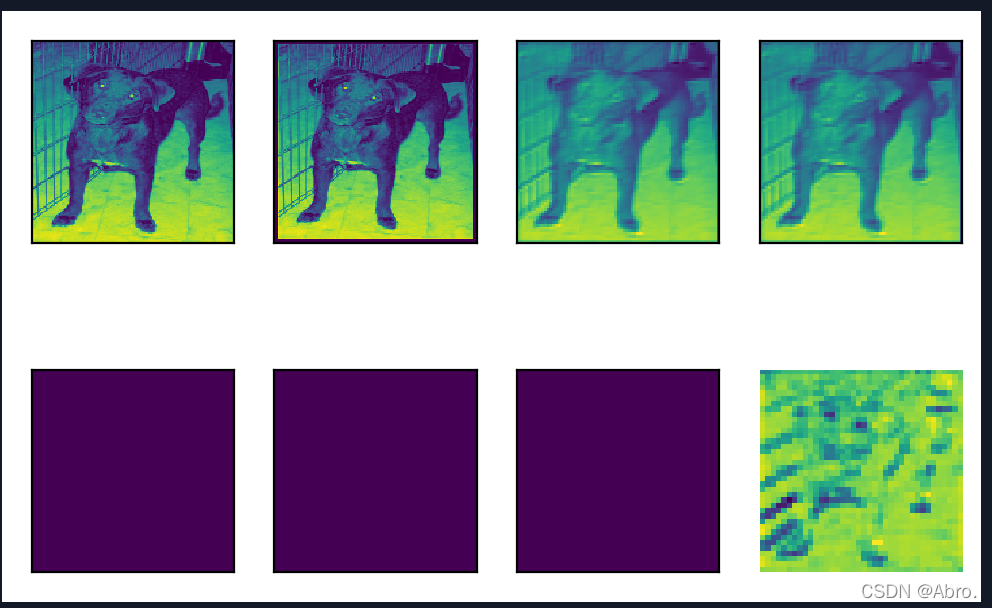
从上图可以看出,第3个通道的狗的图像逐渐清晰,比第1个和第2个通道可视化的结果要好辨认。
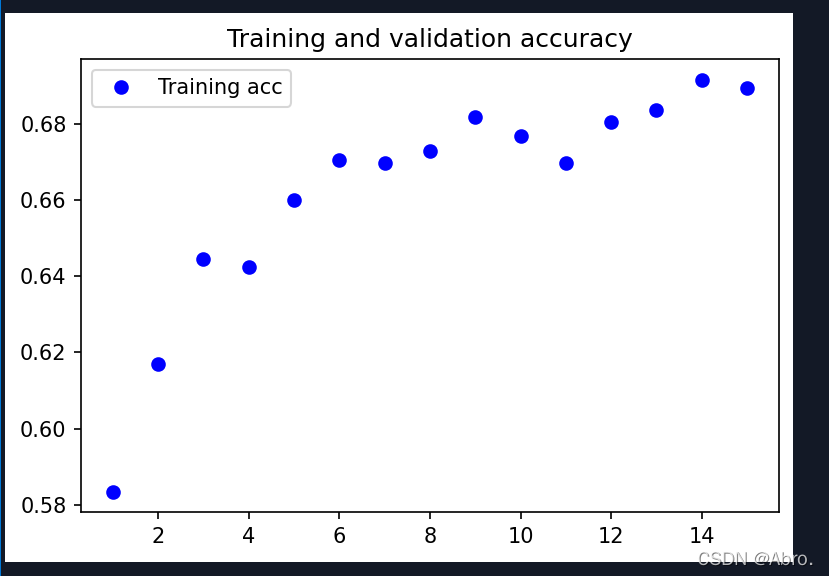
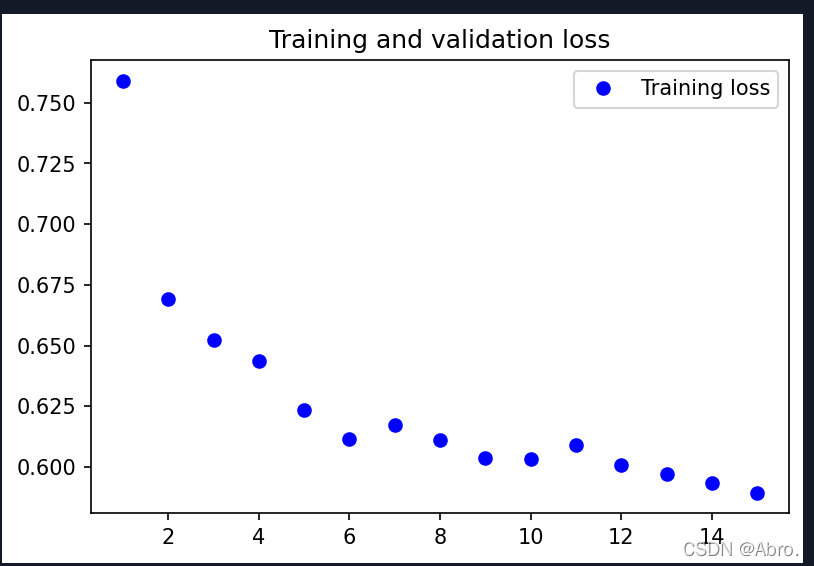
用imagenet预训练好残差网络,使用Adam优化器,学习率设置为0.0001,图片大小为150*150,batch_size为16,进行数据增强之后,训练15代的效果:
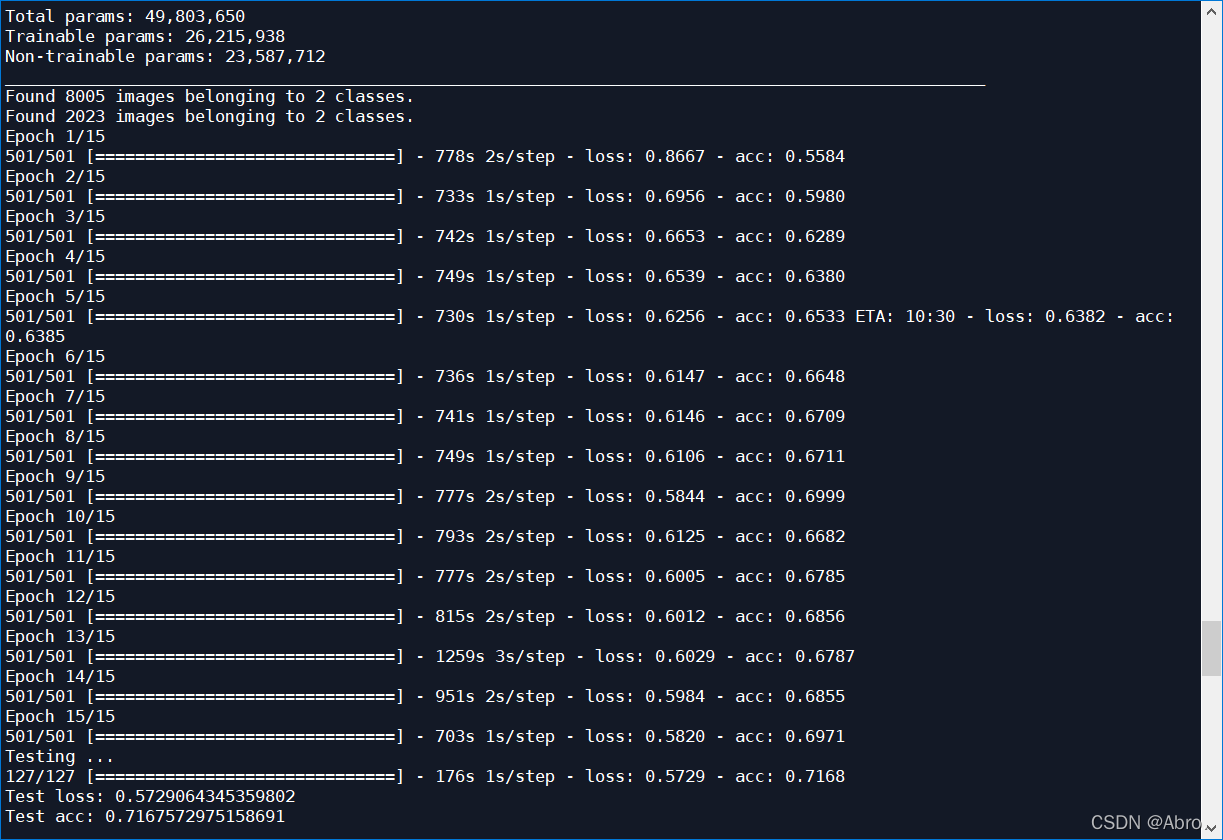
最终测试集的识别率能达到0.7168。
训练过程的分类精度和损失函数的变化图:
|
|
|
四、源码
# In[1]: 导入相应的包
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.models import Model
from tensorflow.keras.regularizers import l2
from tensorflow.keras import Sequential,optimizers
# In[2]: ResNet50模型,加载预训练权重
# 若没有模型文件,则自动下载(由于下载速度很慢,所以建议先把文件放进相应的目录)
# C:\Users\Administrator\.keras\models\resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5
base_model = ResNet50(input_shape=(150, 150, 3), #图片大小:150*150
include_top=False,
weights='imagenet')#用ImageNet预训练权重
base_model.trainable=False
x = base_model.output
x = Flatten()(x)
x = Dense(512,activation='relu',kernel_regularizer=l2(0.0003))(x)
predictions = Dense(2, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
#自定义优化器
optimizer = optimizers.Adam(lr=0.0001) #设置学习率
model.compile(optimizer, loss='categorical_crossentropy',metrics=['acc'])
model.summary() # 打印模型各层的输出大小
# In[3]:数据增强
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen_train = ImageDataGenerator(rescale = 1. / 255, # 像素转换为0到1,对识别率影响比较大
rotation_range=10, # 每张图片随机旋转10度以内进行增强
width_shift_range=0.1, # 左右随机平移10%以内
height_shift_range=0.1) # 上下随机平移10%以内
generator_train = datagen_train.flow_from_directory(
r'D:\Cadabra_tools002\course_data\cat-and-dog\training_set', # 训练集所在路径,子目录为类别
target_size=(150, 150), # 统一resize所有图片的大小为 (28,28)
batch_size=16, # 输入到fit函数中的批的大小
)
datagen_validation = ImageDataGenerator(rescale = 1. / 255)
generator_validation = datagen_validation.flow_from_directory(
r'D:\Cadabra_tools002\course_data\cat-and-dog\test_set',
target_size=(150, 150),
batch_size=16,
)
# In[3]:训练
# 直接加载预训练好的模型
model.load_weights('ch4_CatDog_CNN.h5')
#训练好后不需要再训练,直接加载
#history = model.fit(generator_train, epochs = 15)
#model.save_weights('ch4_CatDog_CNN.h5')
print('Testing ... ')
loss, acc = model.evaluate(generator_validation)
# 输出损失函数和识别率
print('Test loss:', loss)
print('Test acc:', acc)
# In[4]: 训练过程的分类精度和损失函数的变化图,每代一个点
import matplotlib.pyplot as plt
#
acc = history.history['acc']
#val_acc = history.history['val_acc']
loss = history.history['loss']
#val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.figure(dpi=150)
plt.plot(epochs, acc, 'bo', label='Training acc')
#plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure(dpi=150)
plt.plot(epochs, loss, 'bo', label='Training loss')
#plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
# In[5]: 读取一张测试图片,并且转换格式,以便作为神经网络的输入
import os, numpy as np
from tensorflow.keras.preprocessing import image
img_path = os.path.join(r'D:\Cadabra_tools002\course_data\cat-and-dog\dog.1.jpg')
img = image.load_img(img_path, target_size=(150,150))
plt.imshow(img)
img_tensor = image.img_to_array(img)
img_tensor = np.expand_dims(img_tensor, axis=0)
img_tensor /= 255.
print(img_tensor.shape)
# In[6]: 构造新的网络,获得前面训练好的基本模型的前面8层的输出
from tensorflow.keras.models import Model
layer_outputs = [layer.output for layer in model.layers[:8]]
# 函数式构造模型
activation_model = Model(inputs=model.input, outputs=layer_outputs)
activations = activation_model.predict(img_tensor)
layer_show = 0
channel = 0 #通道数
layer_activation = activations[layer_show]
plt.figure()
plt.matshow(layer_activation[0,:,:,channel], cmap='viridis')
# In[7]: 可视化
# activations[0]就是第一个卷积层Conv2D(32, (3,3))的输出
# activations[1]就是MaxPooling2D((2,2)))的输出
fig, ax = plt.subplots(2, 4,dpi=200)
plt.axis('off')
for i in range(0, 2):
for j in range(0, 4):
layer_activation = activations[i*4 + j]
ax[i, j].matshow(layer_activation[0,:,:,0], cmap='viridis')#可改变通道
ax[i, j].set_xticks([])
ax[i, j].set_yticks([])
五、学习产出
1.进行数据增强后,训练集的识别率降低了,但测试集的识别率和未进行数据增强时的识别率相差无几。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









