







 本文介绍了在电商数据分析中如何处理商品数据,包括数据导入、类型检查、log变换、商品类别划分、运费分析、描述长度影响、词云和关键词提取、TF-IDF与降维技术(SVD和t-SNE)、K-Means聚类以及LDA主题建模的实践过程,利用Bokeh进行可视化展示。
本文介绍了在电商数据分析中如何处理商品数据,包括数据导入、类型检查、log变换、商品类别划分、运费分析、描述长度影响、词云和关键词提取、TF-IDF与降维技术(SVD和t-SNE)、K-Means聚类以及LDA主题建模的实践过程,利用Bokeh进行可视化展示。
1.在线商城商品数据信息概述
启动方式
以管理员身份运行Anaconda Prompt,进入Anaconda3的目录下,输入:
jupyter notebook --NotebookApp.iopub_data_rate_limit=1.0e10 "E:\学习资料\...(你的项目地址)"以NotebookApp.iopub_data_rate_limit=1.0e10方式启动,是为了画交互图形。
数据包导入
import nltk
import string
import re
import numpy as np
import pandas as pd
import pickle
#import lda
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="white")
from nltk.stem.porter import *
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.corpus import stopwords
#from sklearn.feature_extraction import stop_words
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
from collections import Counter
from wordcloud import WordCloud
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import plotly.offline as py
py.init_notebook_mode(connected=True)
import plotly.graph_objs as go
import plotly.tools as tls
%matplotlib inline
import bokeh.plotting as bp
from bokeh.models import HoverTool, BoxSelectTool
from bokeh.models import ColumnDataSource
from bokeh.plotting import figure, show, output_notebook
#from bokeh.transform import factor_cmap
import warnings
warnings.filterwarnings('ignore')
import logging
logging.getLogger("lda").setLevel(logging.WARNING)查看数据类型与结构
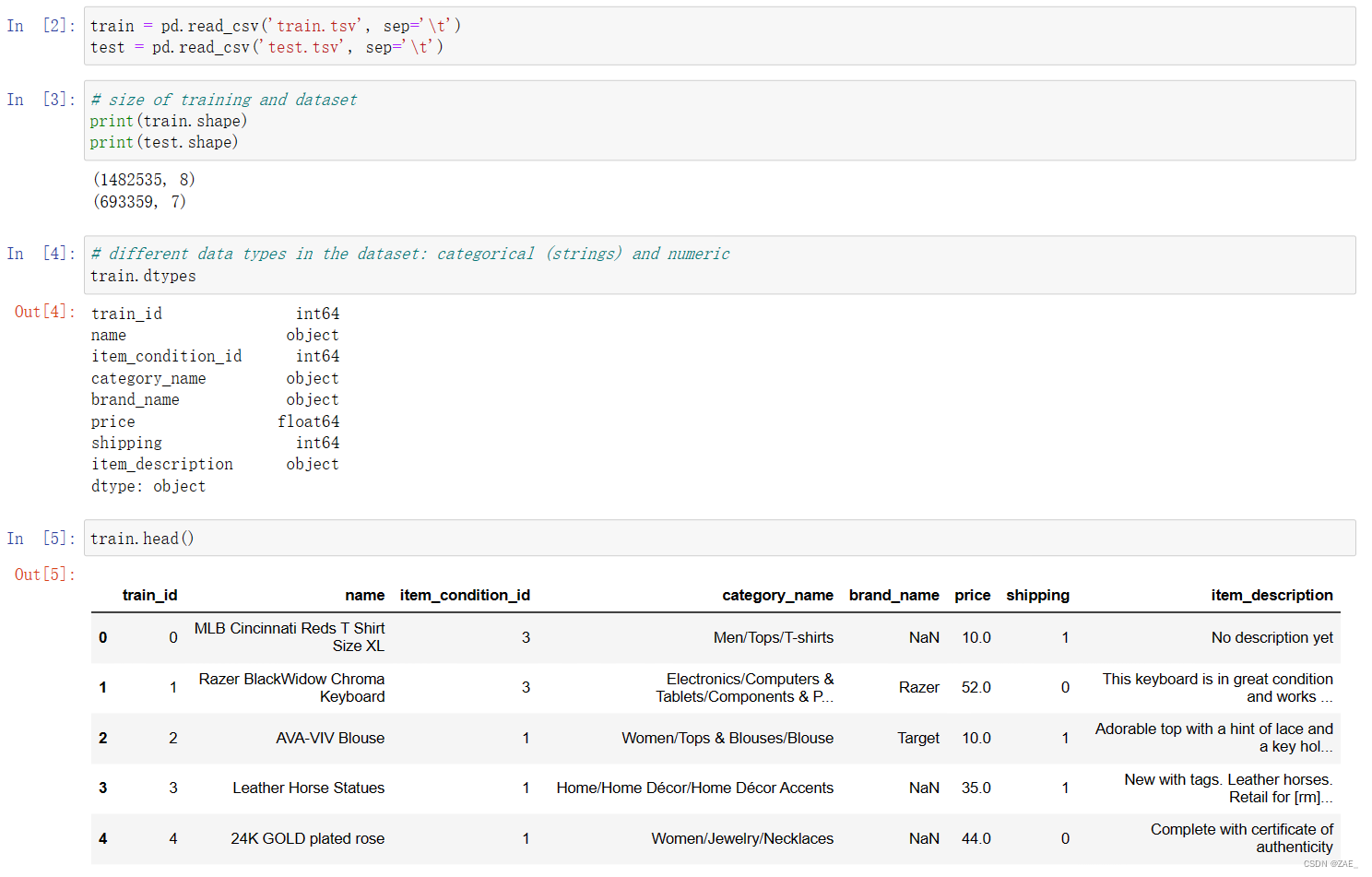
.head() 是 Pandas 中的一个函数,它用于显示数据表的前几行,默认是前 5 行。所以 train.head() 就是显示 DataFrame(数据表) train 的前 5 行数据。这对于快速查看数据的开头部分是很有帮助的,以便了解数据的结构和内容。
log变换

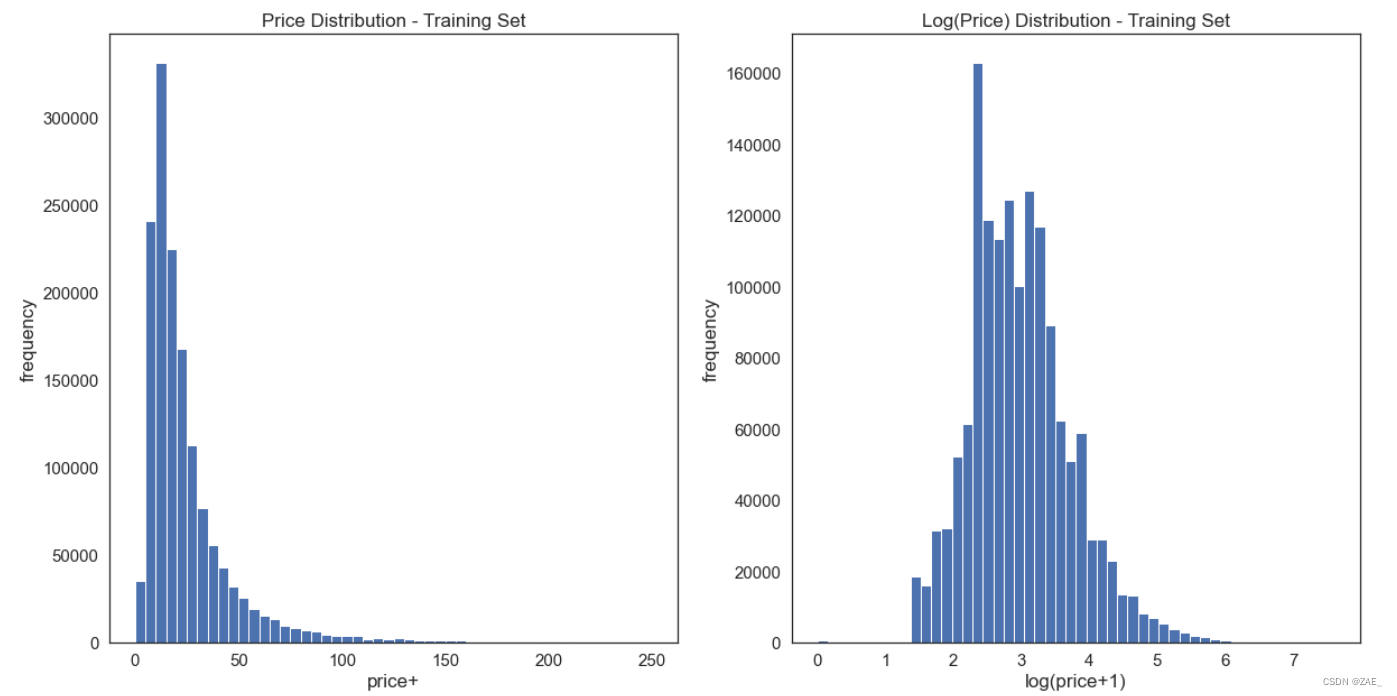
-
对数变换的用法: 对数变换是一种常见的数据变换方法,特别适用于偏态分布的数据。在这里,
np.log(train['price']+1)将价格取对数,+1是为了避免对数中的零值。 -
意义: 对数变换有助于减小数据的偏斜度(skewness)。当数据呈现右偏(正偏)分布时,取对数可以拉伸较小值之间的差异,同时压缩较大值之间的差异。这对于某些机器学习算法,尤其是线性模型,可能有助于提高性能。对价格取对数通常能够使价格分布更加接近正态分布,这有助于一些模型的表现。
2.商品类别划分方式
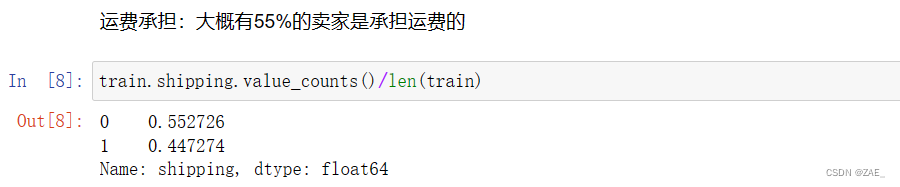
运费承担占比
运费价格变化
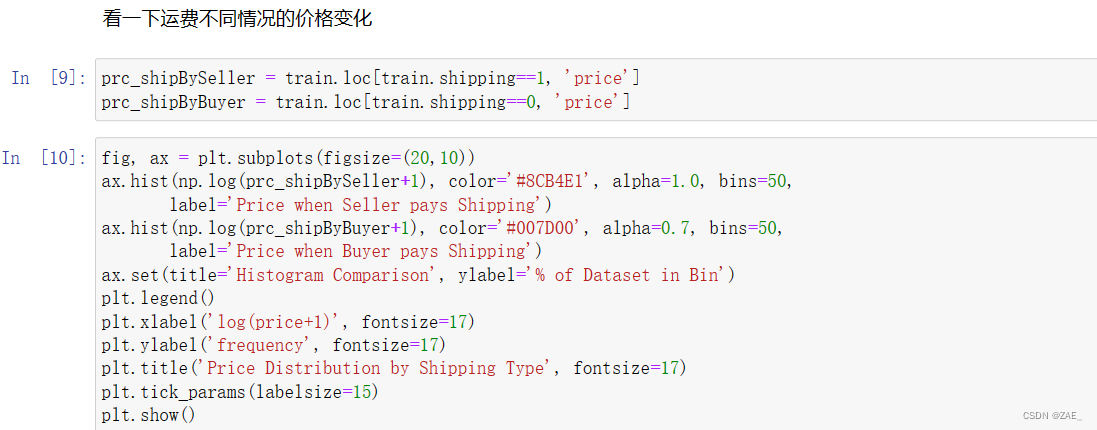
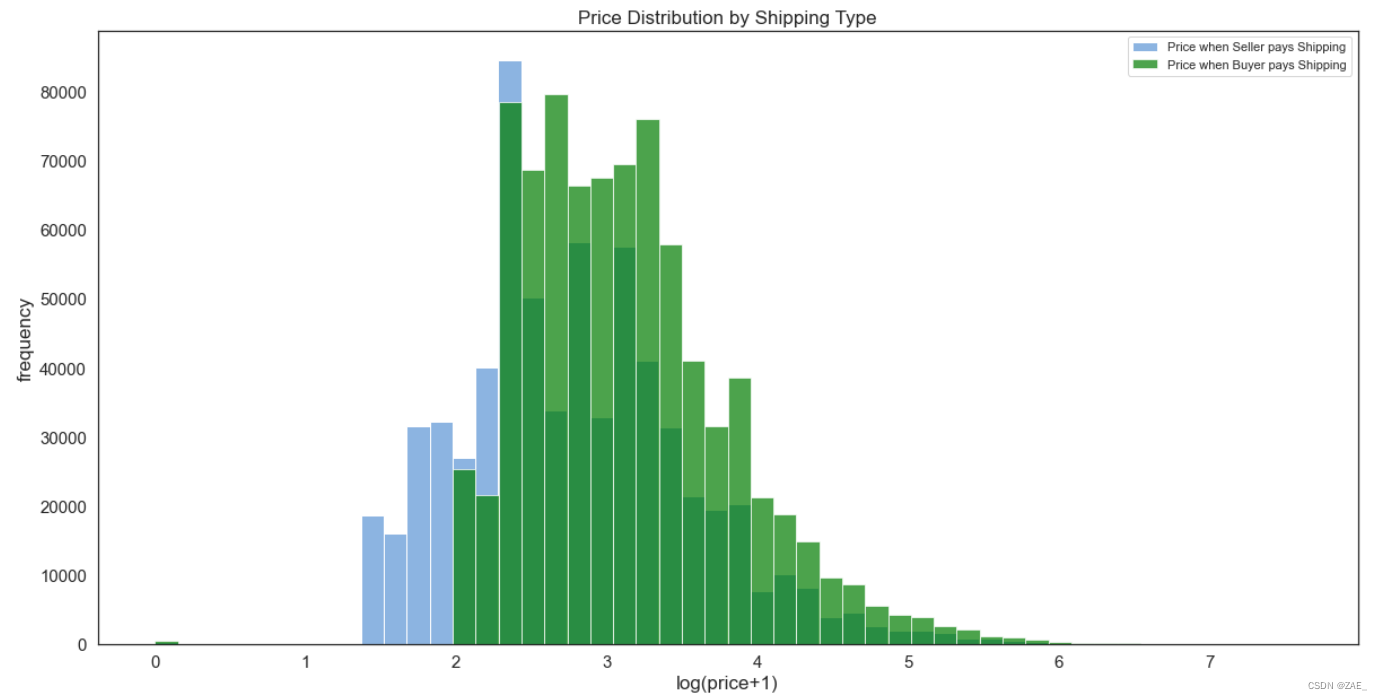
* 当在 ax.hist() 函数中使用 density=True 参数时,直方图的纵轴被标准化为密度,而不是计数。这意味着每个直方图条的高度不再表示该区间内的数据点数量,而是表示该区间内的数据点相对于总数据点数量的比例。
商品类别
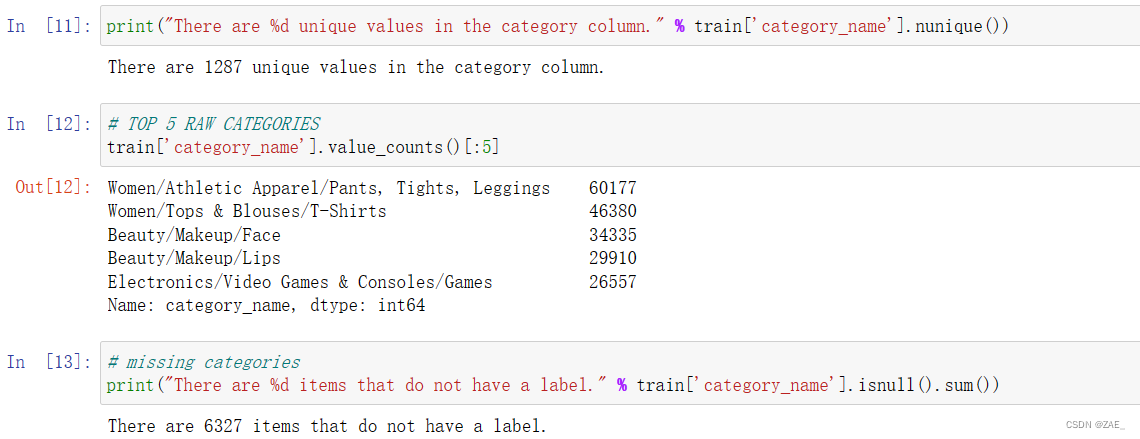
类别细分
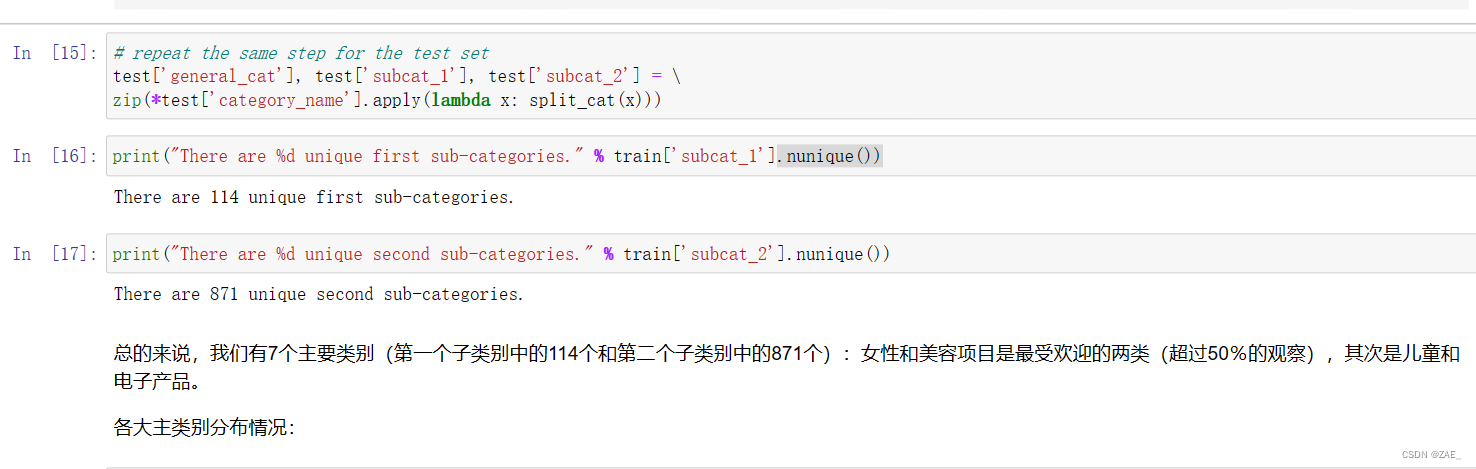
-
test['category_name'].apply(lambda x: split_cat(x)):对测试集中的category_name列应用一个函数,该函数被称为split_cat(x)。这个函数的作用是将category_name中的文本信息进行拆分,并返回一个包含三个元素的元组,分别是大类(general_cat)、子类1(subcat_1)和子类2(subcat_2)。 -
zip(*...):通过zip函数和*操作符将返回的元组解压,得到三个单独的列表,分别对应于拆分后的大类、子类1和子类2。 -
test['general_cat'], test['subcat_1'], test['subcat_2'] = ...:将上一步得到的三个列表分别赋值给测试集的三个新列general_cat、subcat_1和subcat_2。
* .nunique() 是 Pandas DataFrame 或 Series 的一个方法,用于返回唯一值的数量,用于查看数据中有多少个不同的元素,即有多少个类别。
3.商品类别可视化展示
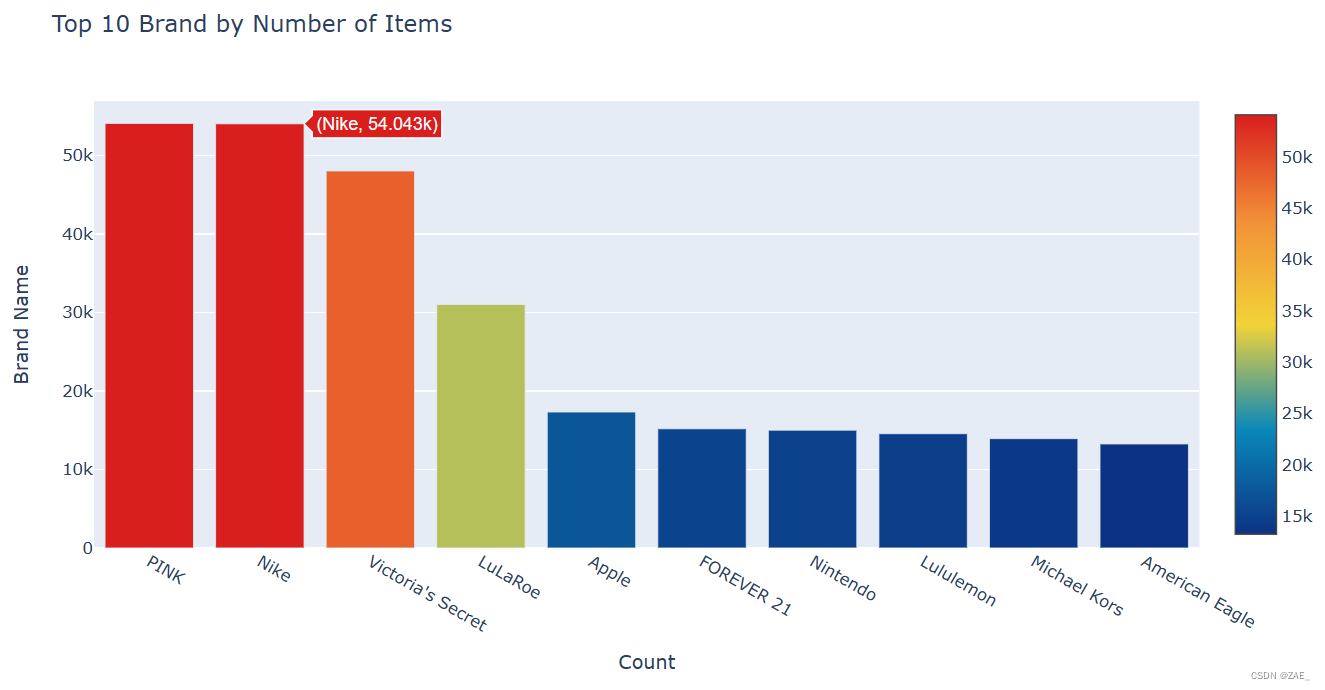
主类分布情况:
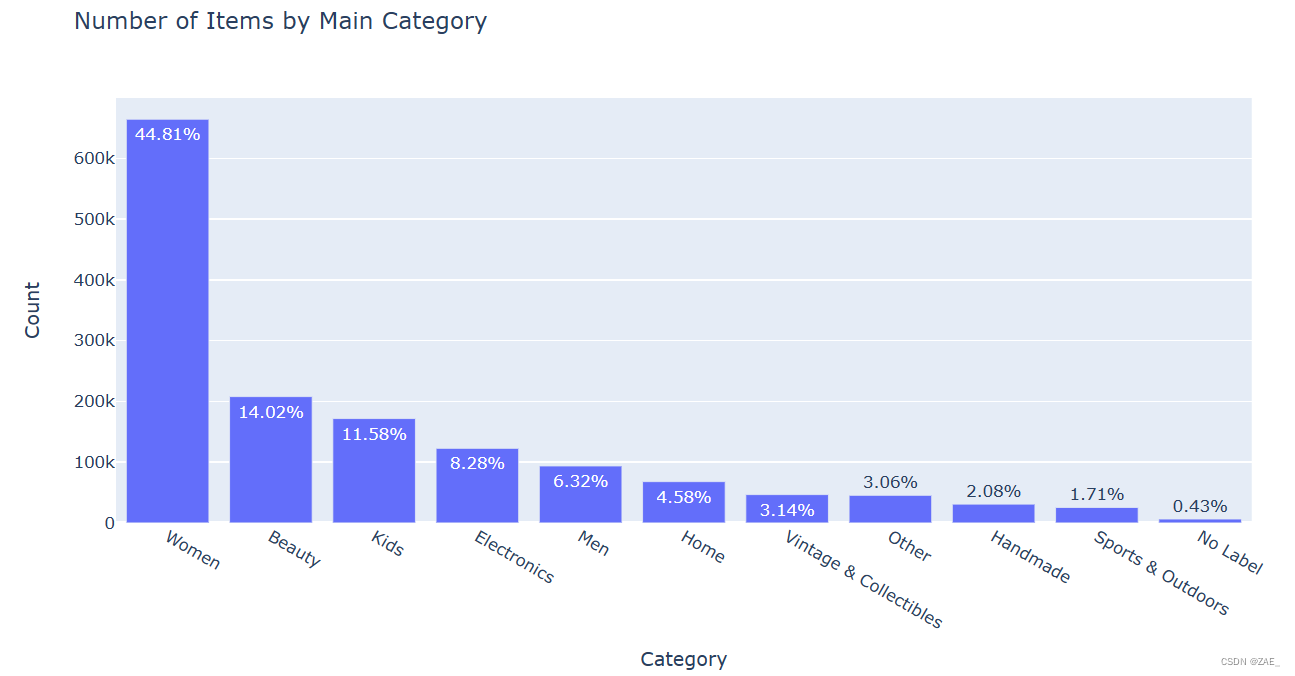
-
x = train['general_cat'].value_counts().index.values.astype('str'): 通过value_counts()统计每个主要类别的数量,并将索引(即类别的名称)提取为字符串数组,赋值给x。 -
y = train['general_cat'].value_counts().values: 获取每个主要类别的数量,赋值给y。 -
pct = [("%.2f"%(v*100))+"%" for v in (y/len(train))]: 计算每个主要类别数量在总数中的百分比,并格式化成字符串,赋值给pct。 -
使用
go.Bar创建一个水平柱形图的 trace (trace1),其中x是类别名称,y是数量,text是百分比文本。
subcat_1类别分布情况
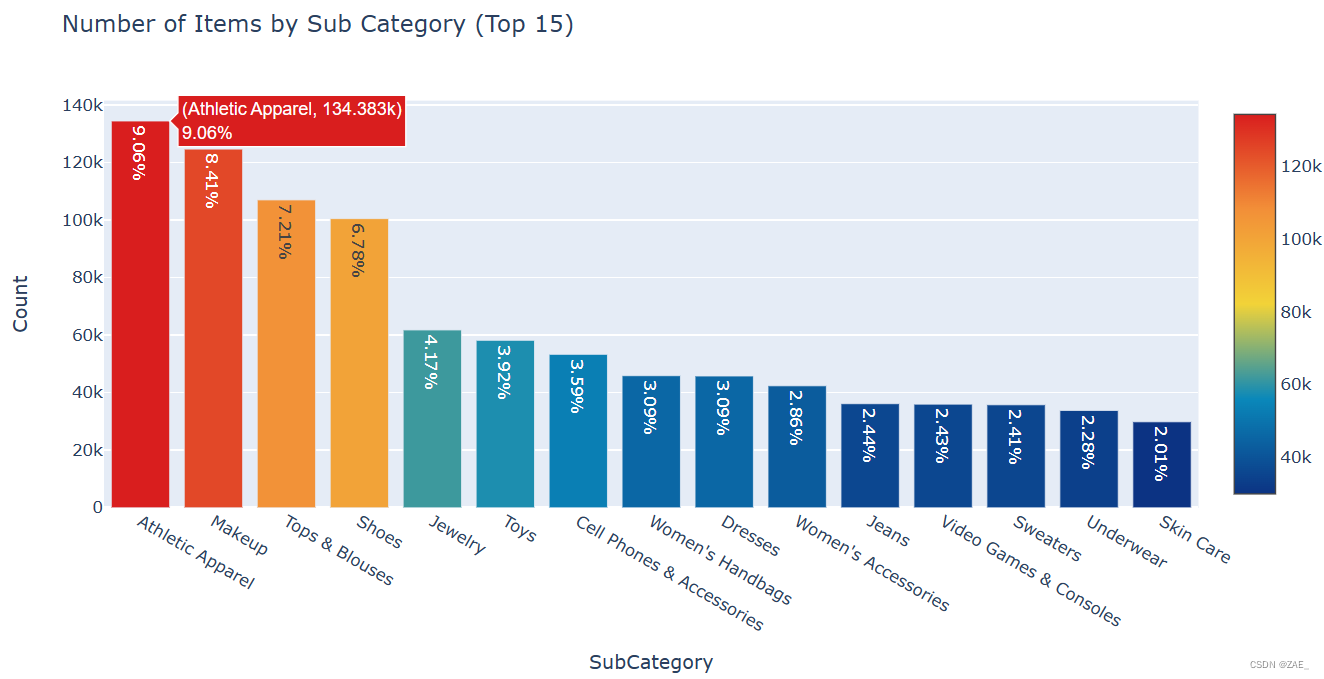
箱型图展示
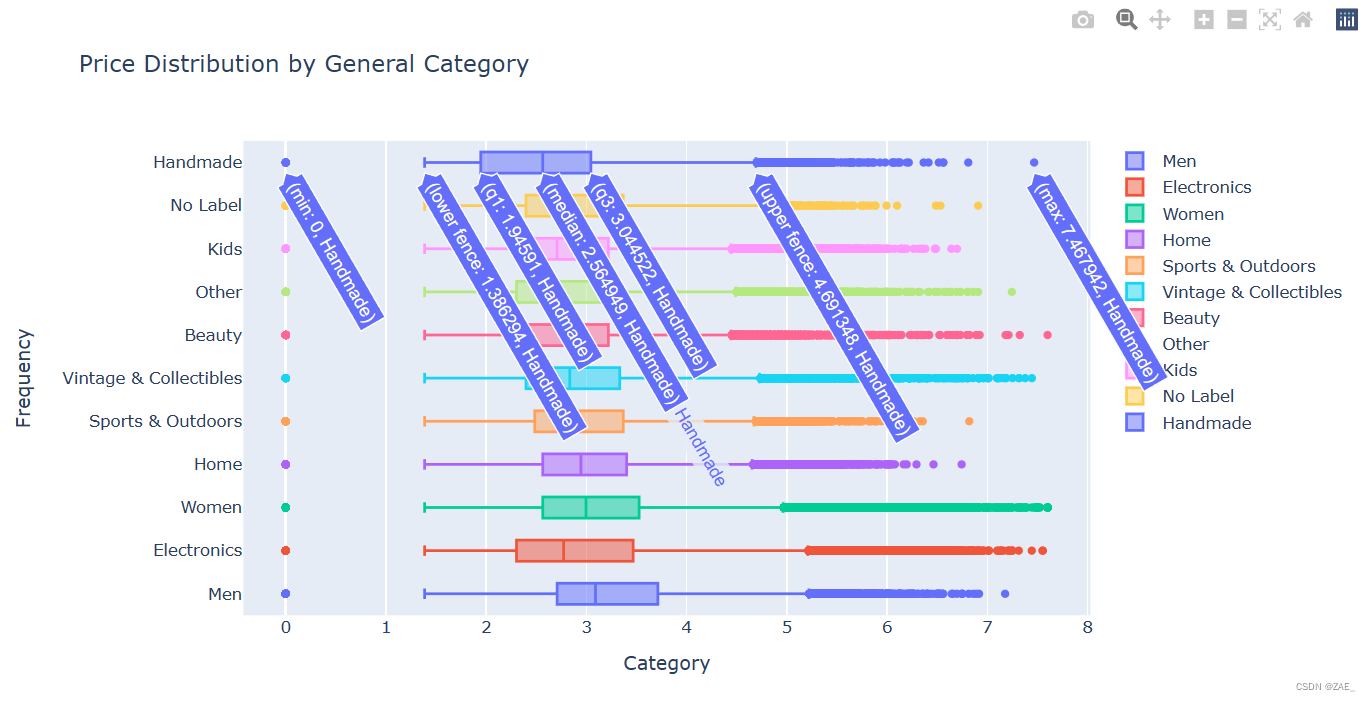
-
general_cats = train['general_cat'].unique(): 获取训练集中所有唯一的大类。 -
x = [train.loc[train['general_cat']==cat, 'price'] for cat in general_cats]: 通过列表推导式,创建了一个列表x,其中包含每个大类下商品的价格数据。对于每个大类,通过train.loc[train['general_cat']==cat, 'price']获取相应的价格数据。 -
data = [go.Box(x=np.log(x[i]+1), name=general_cats[i]) for i in range(len(general_cats))]: 创建箱线图的数据部分。对于每个大类,使用go.Box创建一个箱线图,其中x是对数变换后的价格数据,name是大类的名称。 -
创建布局 (
layout) 包括标题、y 轴标题和 x 轴标题。 -
最后,使用
py.iplot(fig)显示图形。
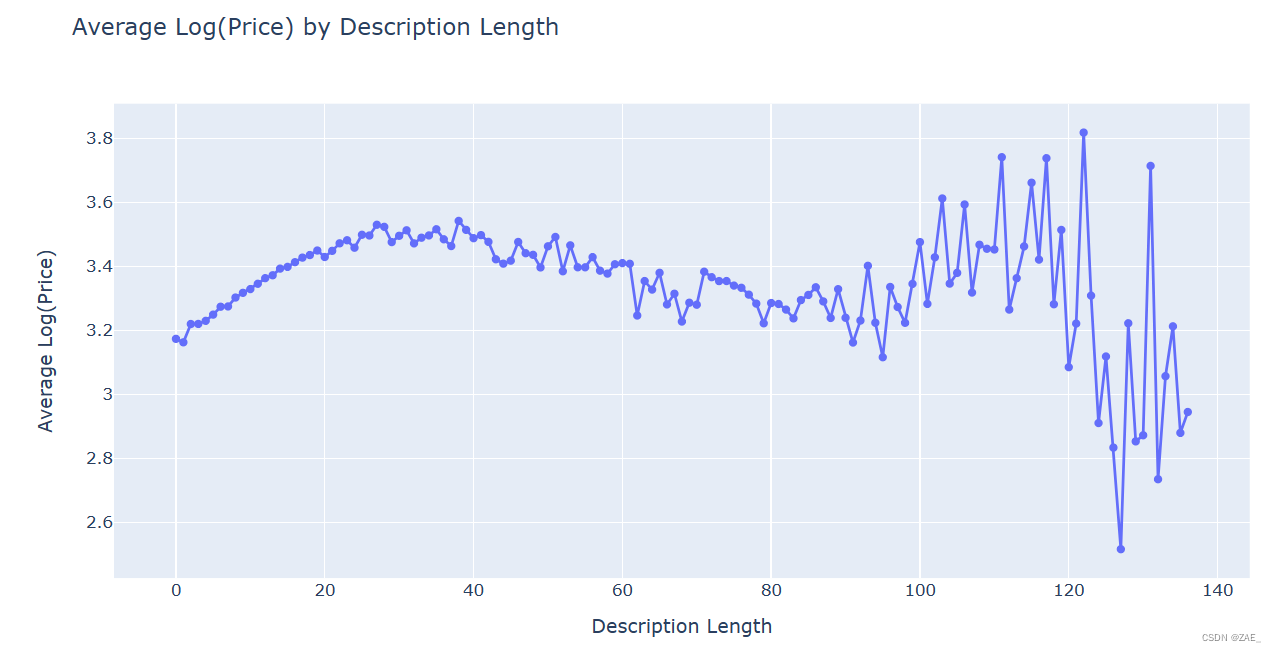
4.商品描述长度对价格的影响分析
商品描述 由于它是非结构化数据,因此解析这个特定项目会更具挑战性。 这是否意味着更详细和更长的描述会导致更高的出价? 我们将删除所有标点,删除一些英语停用词(即冗余词,如“a”,“the”等)以及长度小于3的任何其他词:
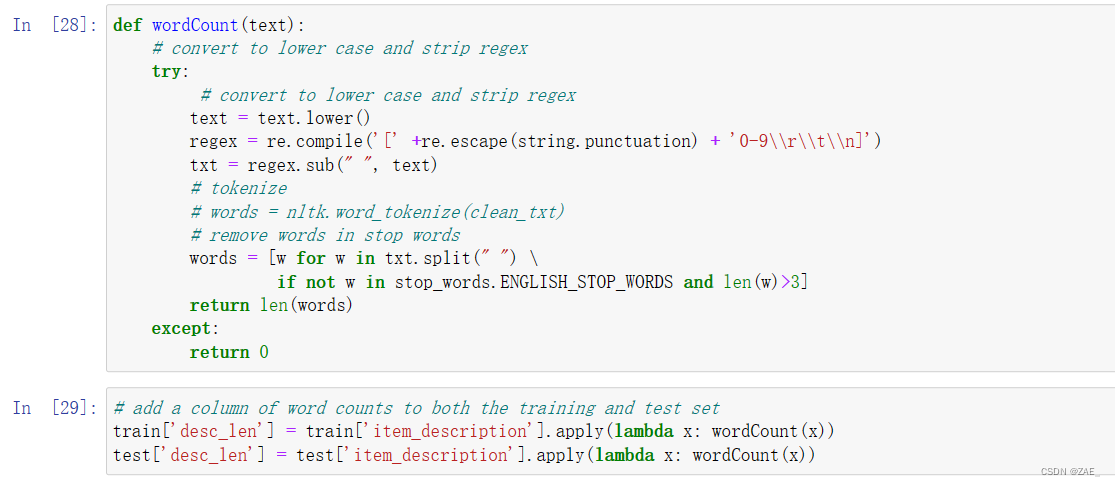
5.关键词的词云可视化展示
# 创建一个字典,以大类为键,对应的所有描述文本为值
cat_desc = dict()
for cat in general_cats:
# 获取特定大类下的所有商品描述文本,并将它们拼接成一个字符串
text = " ".join(train.loc[train['general_cat']==cat, 'item_description'].values)
# 使用自定义的分词函数 tokenize 将文本转换成词语列表
cat_desc[cat] = tokenize(text)
# 找到前四个大类中最常见的 100 个词
women100 = Counter(cat_desc['Women']).most_common(100)
beauty100 = Counter(cat_desc['Beauty']).most_common(100)
kids100 = Counter(cat_desc['Kids']).most_common(100)
electronics100 = Counter(cat_desc['Electronics']).most_common(100)
# 定义生成词云的函数
def generate_wordcloud(tup):
wordcloud = WordCloud(background_color='white',
max_words=50, max_font_size=40,
random_state=42
).generate(str(tup))
return wordcloud
# 创建一个 2x2 的图形布局,用于显示四个大类的词云图
fig, axes = plt.subplots(2, 2, figsize=(30, 15))
# 绘制 Women Top 100 词云图
ax = axes[0, 0]
ax.imshow(generate_wordcloud(women100), interpolation="bilinear")
ax.axis('off')
ax.set_title("Women Top 100", fontsize=30)
# 绘制 Beauty Top 100 词云图
ax = axes[0, 1]
ax.imshow(generate_wordcloud(beauty100))
ax.axis('off')
ax.set_title("Beauty Top 100", fontsize=30)
# 绘制 Kids Top 100 词云图
ax = axes[1, 0]
ax.imshow(generate_wordcloud(kids100))
ax.axis('off')
ax.set_title("Kids Top 100", fontsize=30)
# 绘制 Electronics Top 100 词云图
ax = axes[1, 1]
ax.imshow(generate_wordcloud(electronics100))
ax.axis('off')
ax.set_title("Electronic Top 100", fontsize=30)

6.基于tf-idf提取关键词信息
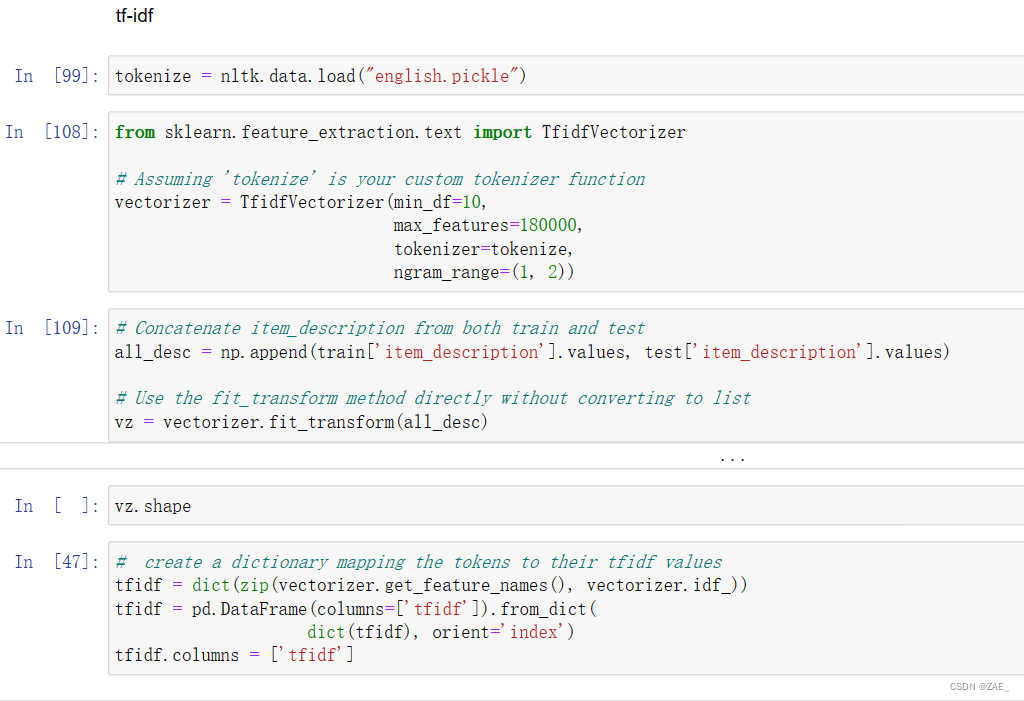
这段代码是用TF-IDF(Term Frequency-Inverse Document Frequency)方法从文本数据中提取关键词信息。首先,导入了Scikit-learn库中的TfidfVectorizer类,设置了一些参数,如最小文档频率(min_df)、最大特征数(max_features)、n-gram范围等。
然后,通过自定义的tokenizer函数对文本进行分词处理。接着,将训练集和测试集中的item description字段合并,并用TfidfVectorizer的fit_transform方法直接得到TF-IDF矩阵。
最后,通过建立一个字典将标记(tokens)与它们的TF-IDF值相映射,并将结果存储在一个DataFrame中。这个DataFrame包含两列,一列是关键词,另一列是对应的TF-IDF值。
总体来说,这段代码用于通过TF-IDF方法从文本数据中提取关键词信息,得到一个包含关键词及其TF-IDF值的DataFrame。
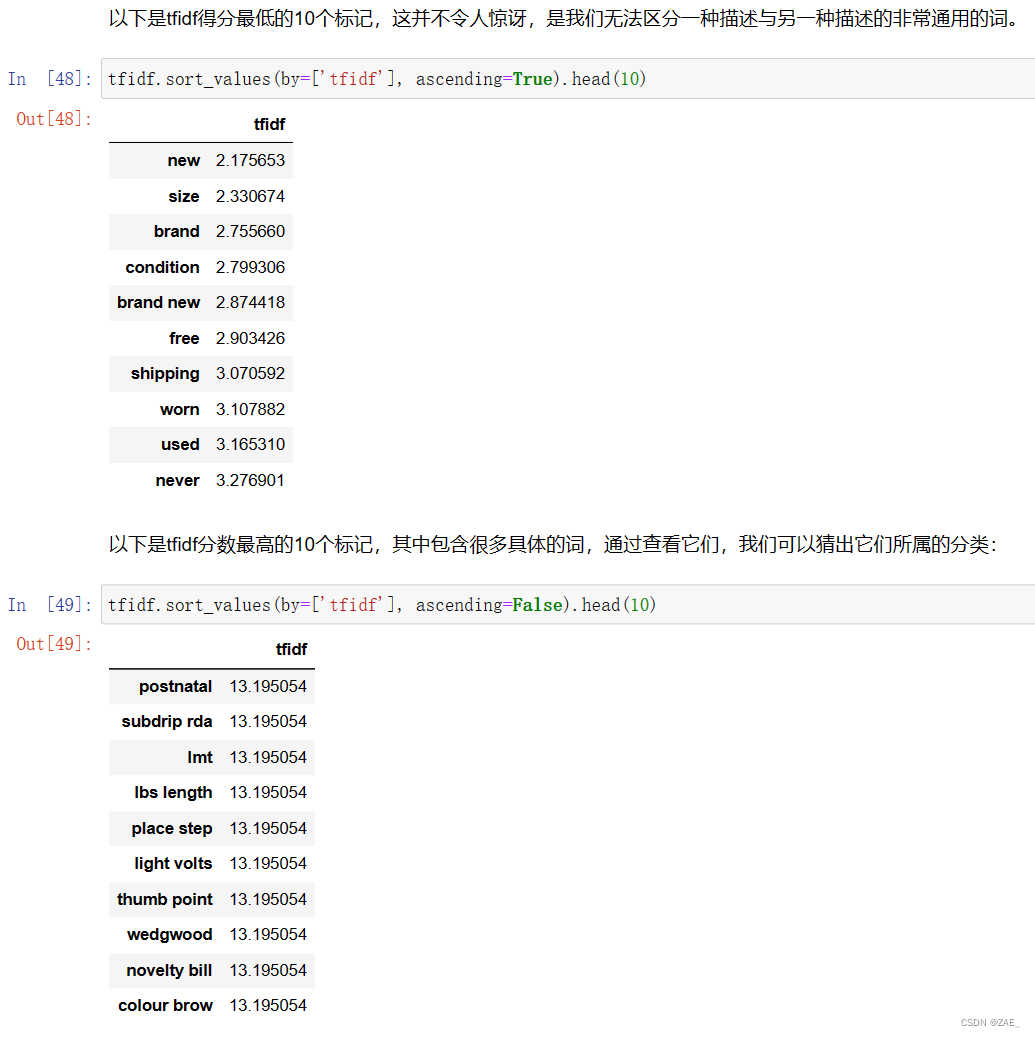
7.通过降维进行可视化展示
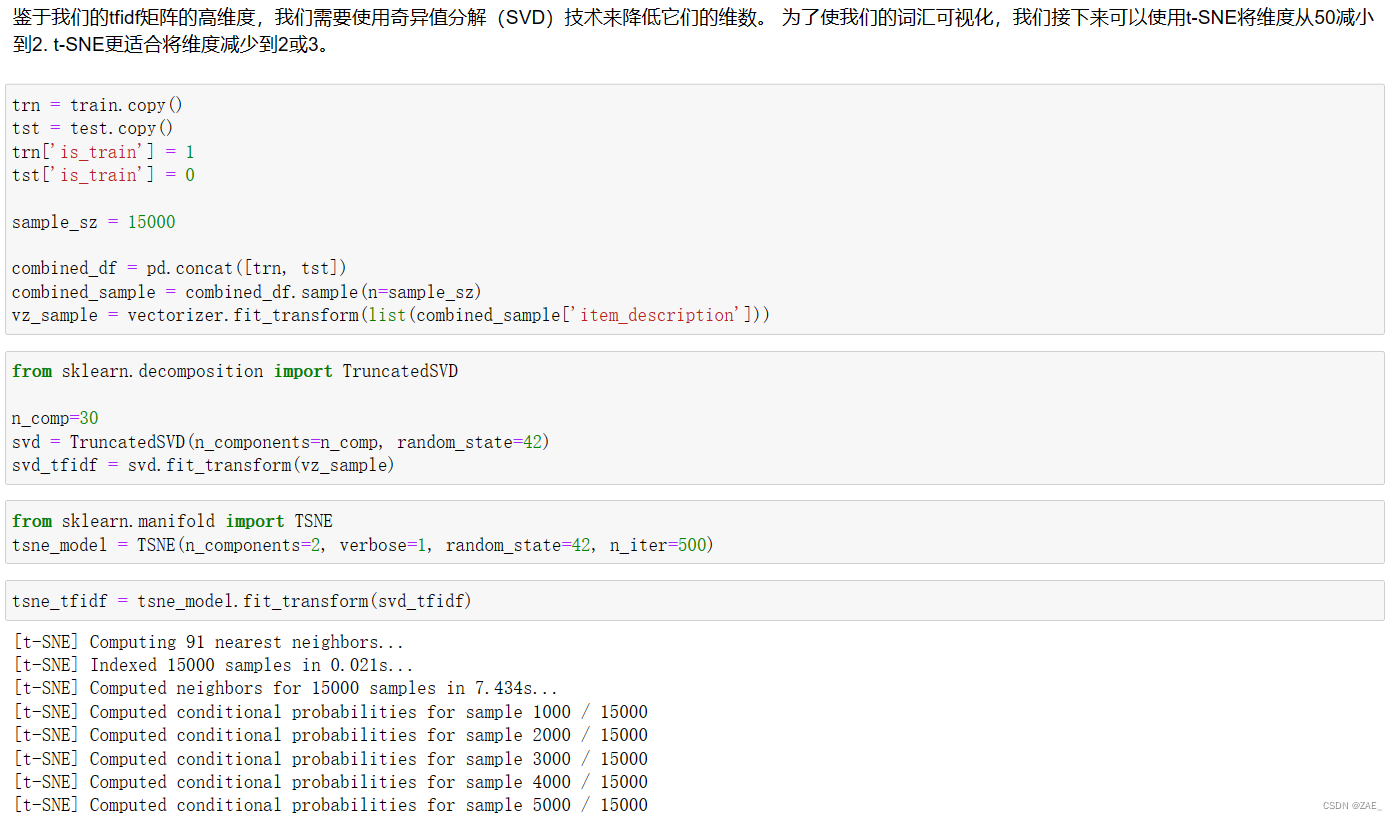
这段代码的目标是通过奇异值分解(SVD)和 t-分布邻域嵌入(t-SNE)技术对高维度的TF-IDF矩阵进行降维,以便进行可视化。首先,将训练集和测试集合并,并从中随机抽取一定数量的样本。
然后,使用TfidfVectorizer将文本数据转换成TF-IDF矩阵。接下来,通过TruncatedSVD对TF-IDF矩阵进行奇异值分解,将其降至更低维度(这里是30维)。
最后,使用t-SNE将降维后的数据进一步减少到2维,以便进行可视化。t-SNE是一种降维算法,特别适用于将高维数据映射到2或3维,以便在二维或三维空间中展示数据的结构和相似性。
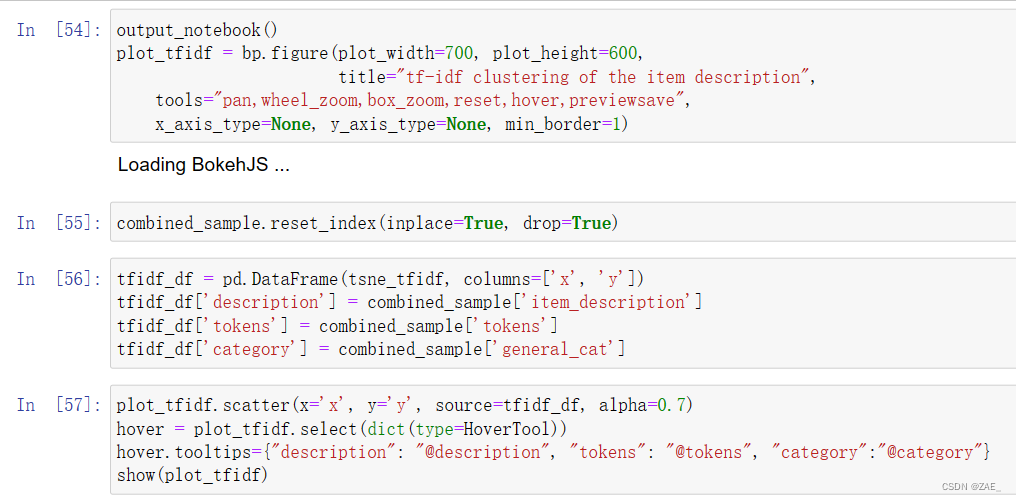
这段代码使用Bokeh库创建了一个交互式的散点图,用于可视化经过TF-IDF处理、SVD降维和t-SNE降维的文本数据集:
-
Bokeh设置: 首先,通过Bokeh库创建了一个图表对象
plot_tfidf,指定了图表的一些属性,如宽度、高度、标题以及可用的工具(pan、zoom等)。 -
数据准备: 将经过处理的样本数据
combined_sample重新索引,并创建一个DataFrametfidf_df包含 t-SNE 降维后的坐标('x'和'y'列)以及一些原始数据,如描述('description'列)、标记('tokens'列)、类别('category'列)。 -
绘制散点图: 使用
scatter方法在图表上绘制散点图,x轴和y轴分别表示 t-SNE 降维后的坐标。每个散点的透明度设置为0.7以提高可读性。 -
工具设置: 通过
HoverTool工具设置悬停提示,以显示每个散点的描述、标记和类别信息。
这段代码的最终效果是一个交互式的散点图,你可以通过悬停查看每个数据点的详细信息,从而更好地理解文本数据在降维空间中的分布和聚类情况。
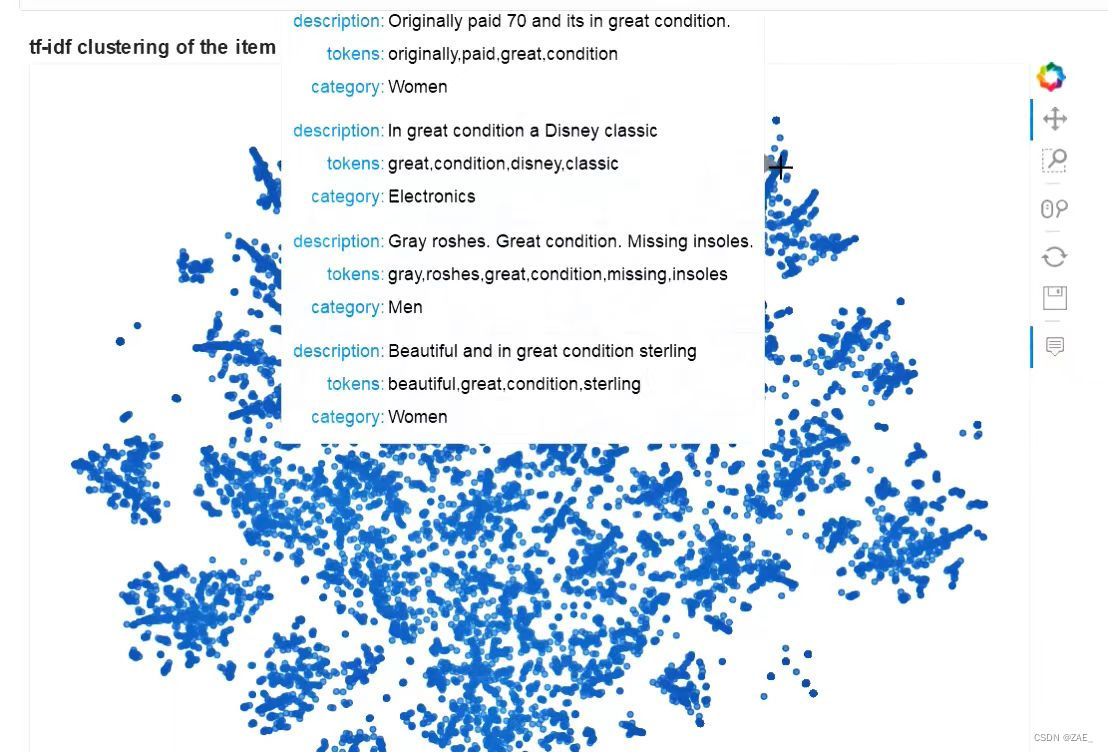
8.聚类分析与主题模型展示
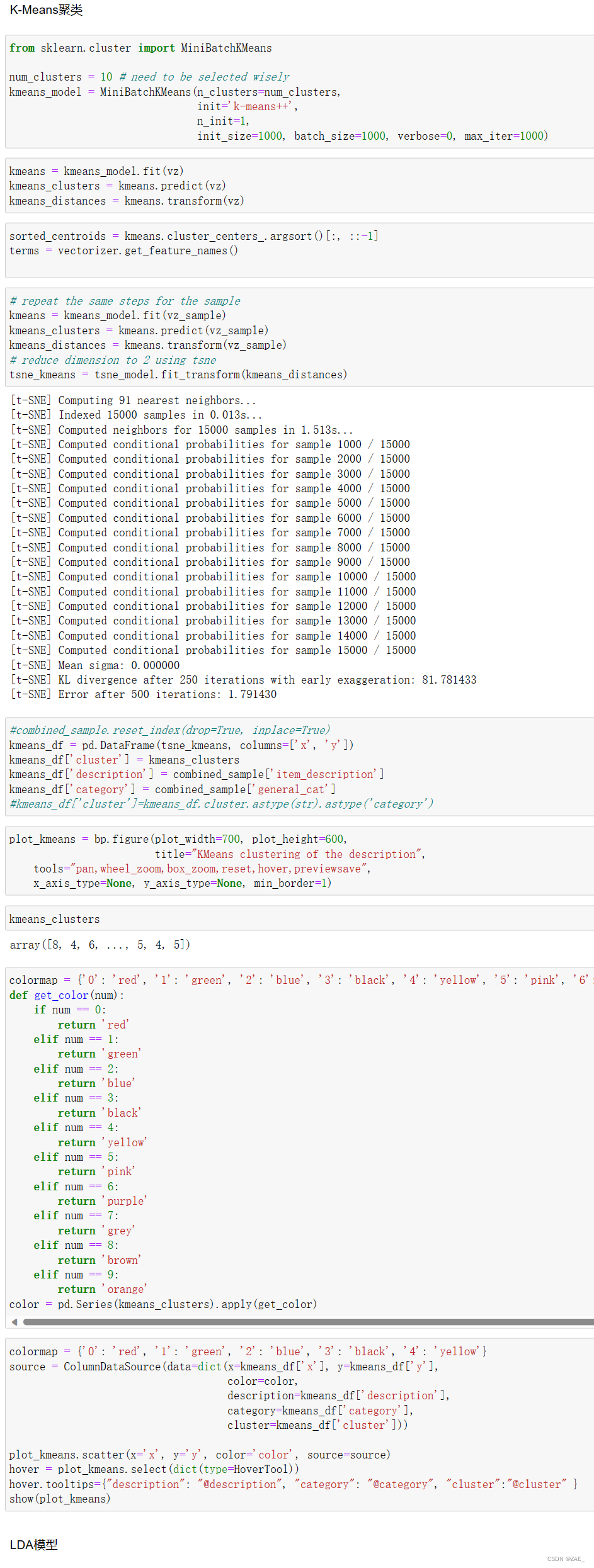
这段代码实现了对文本数据进行K-Means聚类,并通过t-SNE降维进行可视化。以下是简要介绍:
-
K-Means聚类模型: 使用Scikit-learn中的MiniBatchKMeans类建立K-Means模型。在这里,你选择了10个聚类中心。通过拟合训练集的TF-IDF矩阵,得到聚类标签、距离等信息。
-
降维到2维: 使用t-SNE对K-Means聚类结果的距离信息进行降维,将其减少到2维,以便后续可视化。
-
数据整理: 将降维后的结果整理为DataFrame,包含坐标('x'和'y'列)、聚类标签('cluster'列)、描述('description'列)、类别('category'列)等信息。
-
Bokeh可视化: 创建Bokeh图表对象,设置图表属性,并通过scatter方法绘制散点图。每个散点的颜色表示所属的K-Means聚类。
-
悬停提示: 使用HoverTool设置悬停提示,显示每个散点的描述、类别和所属聚类。
-
颜色映射: 通过设定颜色映射,将K-Means聚类结果映射到不同颜色,增强可视化效果。
-
显示图表: 最后,通过show方法显示Bokeh图表。
整个流程实现了对文本数据进行K-Means聚类,并通过t-SNE降维进行可视化,使你能够更清晰地观察文本数据在降维空间中的聚类情况。
t-SNE(t-Distributed Stochastic Neighbor Embedding)是一种用于降维和可视化高维数据的非线性技术。它主要用于将高维数据映射到二维或三维空间,以便更好地理解数据的结构和相似性。
以下是t-SNE的简要介绍:
-
非线性降维: t-SNE是一种非线性降维技术,与PCA等线性方法不同。它更擅长保留数据中的局部结构,特别适用于高维数据中的簇状结构。
-
相似性映射: t-SNE通过映射数据点之间的相似性概率来构建降维空间。在高维空间中,相似的数据点具有较高的概率成为邻居,而不相似的数据点则有较低的概率成为邻居。
-
KL散度最小化: t-SNE的优化目标是最小化在高维空间和低维空间之间的KL(Kullback-Leibler)散度。通过梯度下降优化这个目标,t-SNE将相似的数据点映射到降维空间中的近邻位置。
-
悬崖效应: t-SNE在优化过程中有一个“悬崖效应”,这意味着相似的数据点在映射后更倾向于聚集在一起,而不相似的点则远离彼此。
-
随机初始化: t-SNE的优化是基于梯度的,但它对初始配置敏感。因此,不同的运行可能产生不同的结果。通常,可以通过多次运行并选择具有最小KL散度的结果来提高稳定性。
总体而言,t-SNE是一种强大的工具,特别适用于可视化高维数据,帮助我们发现数据中的结构和模式。
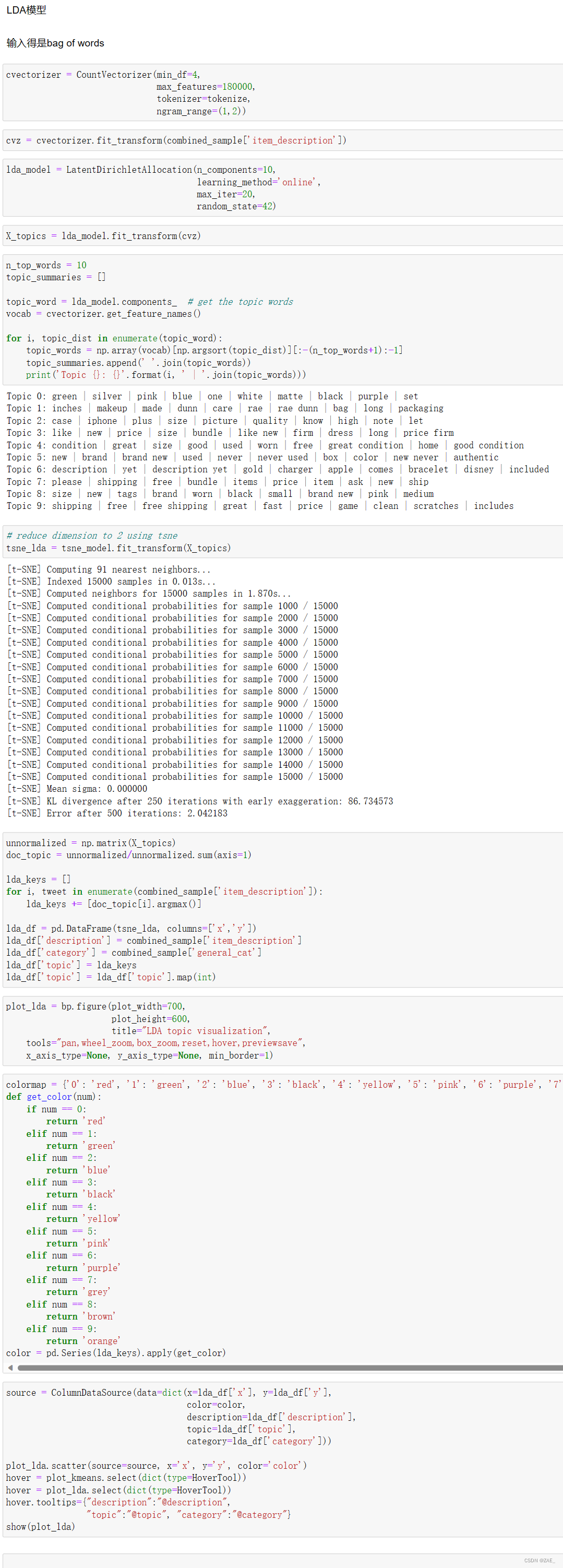
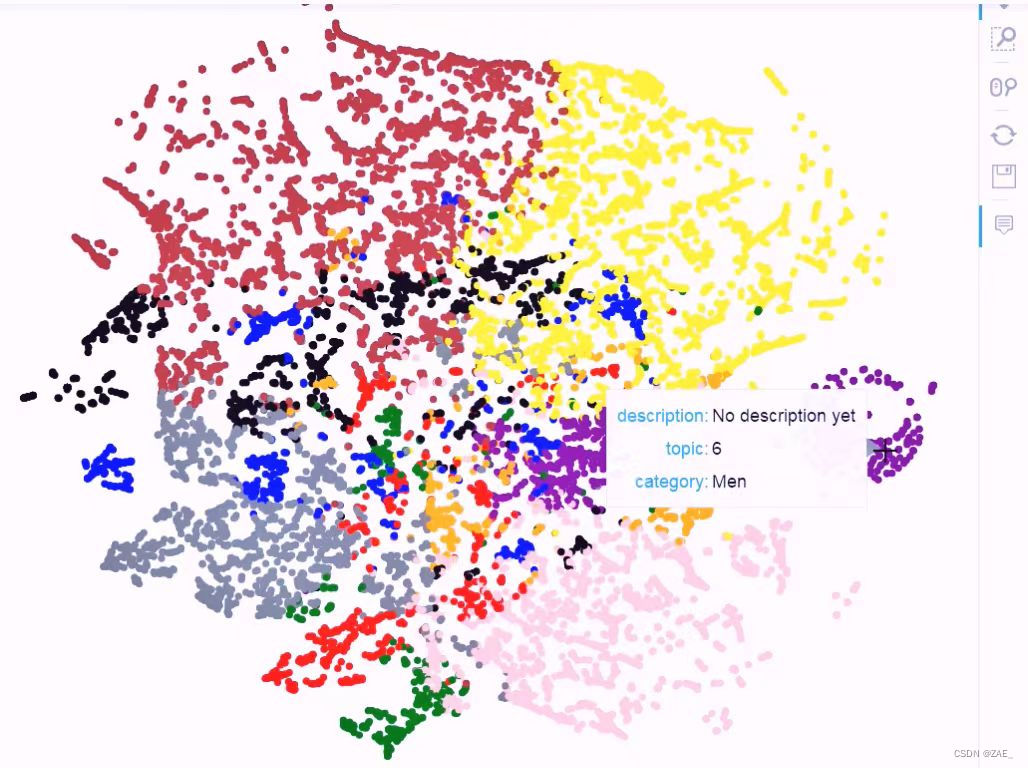
这段代码实现了使用Latent Dirichlet Allocation(LDA)模型对文本数据进行主题建模,并通过t-SNE降维进行可视化。以下是简要介绍:
-
文本向量化: 使用CountVectorizer将文本数据转换为词袋(bag of words)表示,得到稀疏矩阵
cvz。 -
LDA模型建立: 创建LDA模型,指定主题数为10,并使用fit_transform方法获取文本数据的主题分布矩阵
X_topics。 -
获取主题词汇: 通过LDA模型的components_属性获取每个主题的词汇分布,并获取每个主题的关键词,存储在
topic_summaries中。 -
t-SNE降维: 使用t-SNE对主题分布进行降维,得到二维坐标。
-
数据整理: 将降维后的结果整理为DataFrame,包含坐标、描述、类别、主题等信息。
-
Bokeh可视化: 创建Bokeh图表对象,通过scatter方法绘制散点图,颜色表示主题。
-
悬停提示: 使用HoverTool设置悬停提示,显示每个散点的描述、主题、类别等信息。
-
颜色映射: 设定颜色映射,将主题映射到不同颜色,以增强可视化效果。
-
显示图表: 通过show方法显示Bokeh图表。
整个流程实现了对文本数据进行LDA主题建模,并通过t-SNE降维进行可视化,使其能够更清晰地观察文本数据在主题空间中的分布和关联情况。
LDA(Latent Dirichlet Allocation)是一种用于主题建模的概率模型,常被用于分析文本数据。以下是LDA的简要介绍:
-
目标和原理: LDA的目标是发现文档集合中隐藏的主题,并确定每个文档包含哪些主题,以及每个主题包含哪些词。它基于概率分布,假设文档是通过从一组主题中选择词汇生成的。
-
基本假设: LDA基于以下假设:
- 每个文档是由多个主题组成的,每个主题的贡献度不同。
- 每个主题是由多个词汇组成的,每个词汇在该主题中的贡献度不同。
-
模型生成过程: LDA的生成过程可以描述为:
- 为每个文档选择主题分布。
- 对于文档中的每个词汇,选择一个主题。
- 根据选择的主题,选择一个词汇。
-
推断过程: LDA的推断过程是为了从给定的文档集合中找出主题分布和词汇分布。这通常涉及到使用采样方法(如Gibbs采样)进行参数估计。
-
应用领域: LDA广泛用于文本挖掘、主题分析、推荐系统等领域。通过识别文档中的主题,LDA帮助理解文本数据的结构,发现其中隐藏的关联和主题。
-
实现库: 在Python中,可以使用Scikit-learn、Gensim等库来实现LDA模型。
总体而言,LDA是一种有力的工具,可用于揭示文本数据中的主题结构,为深入理解和分析文本提供帮助。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









