







在Flink SQL的window计算中,为了提高性能,Flink SQL根据minibatch的设计思想引入了slice机制。首先Flink SQL把window分成了两大类
- Aligned Window: 具有预先定义的边界,边界的定义与data stream或者收到的数据无关,比如hopping window, tumbling window, cumulative window都属于aligned window
- Unaligned Window: 根据收到的数据动态决定边界,目前Flink中只有一种session window
对于aligned window,Flink SQL希望将他们分成一定数量并且不相交的slice,使每一个元素都属于某个slice,这样在做window计算的时候相当于是两步,第一步使用local aggregate计算slice中的结果,第二部使用整体的window对slice的计算结果作global aggregate。稍微看了下slice相关的代码,感觉还是比较复杂的(对我而言),尽量把它们都分析完,尽量不烂尾
2. SliceAssigner
对于这种slice作minibatch优化的情况,首先我们可能想到的第一个问题就是怎样把收到的每个record assign给不同的slice呢,这篇文章里我们着重看一下这点
2.1. Class Hierarchy

可以看到class hierarchy还是稍微有点复杂,感觉读Java代码一个很不爽的地方就是各种interface, abstract class绕来绕去,class里的properties全是接口,很多代码不run一下根本不知道实现类是什么,确实这样很符合工程标准,但读起来略痛苦(也应该是我比较菜的原因)。对于aligned window的每个类型都有相应的assigner
2.2. 具体分析
首先我们来看一看最顶端的SliceAssigner接口
package org.apache.flink.table.runtime.operators.window.slicing;
import org.apache.flink.annotation.Internal;
import org.apache.flink.table.data.RowData;
import java.io.Serializable;
/**
* A {@link SliceAssigner} assigns element into a single slice. Note that we use the slice end
* timestamp to identify a slice.
*
* <p>Note: {@link SliceAssigner} servers as a base interface. Concrete assigners should implement
* interface {@link SliceSharedAssigner} or {@link SliceUnsharedAssigner}.
*
* @see SlicingWindowOperator for more definition of slice.
*/
@Internal
public interface SliceAssigner extends Serializable {
/**
* Returns the end timestamp of a slice that the given element should belong.
*
* @param element the element to which slice should belong to.
* @param clock the service to get current processing time.
*/
long assignSliceEnd(RowData element, ClockService clock);
/**
* Returns the last window which the slice belongs to. The window and and slices are both
* identified by the end timestamp.
*/
long getLastWindowEnd(long sliceEnd);
/** Returns the corresponding window start timestamp of the given window end timestamp. */
long getWindowStart(long windowEnd);
/**
* Returns an iterator of slices to expire when the given window is emitted. The window and
* slices are both identified by the end timestamp.
*
* @param windowEnd the end timestamp of window emitted.
*/
Iterable<Long> expiredSlices(long windowEnd);
/**
* Returns the interval of slice ends, i.e. the step size to advance of the slice end when a new
* slice assigned.
*/
long getSliceEndInterval();
/**
* Returns {@code true} if elements are assigned to windows based on event time, {@code false}
* based on processing time.
*/
boolean isEventTime();
}可以看到主要的一个函数是assignSliceEnd,也就是给一个元素分配对应的slice,而这里slice是使用slice end作唯一标识
接下来我们看AbstractSlicedSliceAssigner
/**
* A basic implementation of {@link SliceAssigner} for elements have been attached window start
* and end timestamps.
*/
private abstract static class AbstractSlicedSliceAssigner implements SliceAssigner {
private static final long serialVersionUID = 1L;
private final int sliceEndIndex;
protected final SliceAssigner innerAssigner;
public AbstractSlicedSliceAssigner(int sliceEndIndex, SliceAssigner innerAssigner) {
checkArgument(
sliceEndIndex >= 0,
"Windowed slice assigner must have a positive window end index.");
this.sliceEndIndex = sliceEndIndex;
this.innerAssigner = innerAssigner;
}
@Override
public long assignSliceEnd(RowData element, ClockService clock) {
return element.getLong(sliceEndIndex);
}
@Override
public long getWindowStart(long windowEnd) {
return innerAssigner.getWindowStart(windowEnd);
}
@Override
public Iterable<Long> expiredSlices(long windowEnd) {
return innerAssigner.expiredSlices(windowEnd);
}
@Override
public long getSliceEndInterval() {
return innerAssigner.getSliceEndInterval();
}
@Override
public boolean isEventTime() {
// it always works in event-time mode if input row has been attached slices
return true;
}
}这里的abstract class为slice assigner接口提供了基本的实现,但可以发现它把核心逻辑都delegate给innerAssigner
SliceAssigner最终同样可以划分为两种,标准是某一个element是否可以属于多个window,比如对于一个element可以同时属于多个hopping和cumulate window,这种就实现接口SliceSharedAssigner;但对于tumbling window则实现接口SliceUnsharedAssigner,由于前相对来说比较复杂,因此我们主要看前者
/**
* The {@link SliceAssigner} for elements have been attached slice end timestamp, and the slices
* are shared.
*/
public static final class SlicedSharedSliceAssigner extends AbstractSlicedSliceAssigner
implements SliceSharedAssigner {
private static final long serialVersionUID = 1L;
private final SliceSharedAssigner innerSharedAssigner;
public SlicedSharedSliceAssigner(int sliceEndIndex, SliceSharedAssigner innerAssigner) {
super(sliceEndIndex, innerAssigner);
this.innerSharedAssigner = innerAssigner;
}
@Override
public void mergeSlices(long sliceEnd, MergeCallback callback) throws Exception {
innerSharedAssigner.mergeSlices(sliceEnd, callback);
}
@Override
public Optional<Long> nextTriggerWindow(long windowEnd, Supplier<Boolean> isWindowEmpty) {
return innerSharedAssigner.nextTriggerWindow(windowEnd, isWindowEmpty);
}
@Override
public long getLastWindowEnd(long sliceEnd) {
return innerAssigner.getLastWindowEnd(sliceEnd);
}
}SlicedSharedSliceAssigner实现了SliceSharedAssigner接口,对于核心的函数mergeSlices, nextTriggerWindow等同样交给具体的innerSharedAssigner实现
2.3. CumulativeSliceAssigner
最终我们来到了CumulativeSliceAssigner,来看下它的实现。首先在构造的时候要传入一些参数
public static CumulativeSliceAssigner cumulative(
int rowtimeIndex, ZoneId shiftTimeZone, Duration maxSize, Duration step) {
return new CumulativeSliceAssigner(
rowtimeIndex, shiftTimeZone, maxSize.toMillis(), step.toMillis(), 0);
}
protected CumulativeSliceAssigner(
int rowtimeIndex, ZoneId shiftTimeZone, long maxSize, long step, long offset) {
super(rowtimeIndex, shiftTimeZone);
if (maxSize <= 0 || step <= 0) {
throw new IllegalArgumentException(
String.format(
"Cumulative Window parameters must satisfy maxSize > 0 and step > 0, but got maxSize %dms and step %dms.",
maxSize, step));
}
if (maxSize % step != 0) {
throw new IllegalArgumentException(
String.format(
"Cumulative Window requires maxSize must be an integral multiple of step, but got maxSize %dms and step %dms.",
maxSize, step));
}
this.maxSize = maxSize;
this.step = step;
this.offset = offset;
}rowtimeIndex为-1表示使用processing time,>=0则表示使用event time;另外是时间所属的timezone;最后是构建cumulate window所需要的max size和step;默认的offset为
2.3.1. assignSliceEnd
在AbstractSliceAssigner中会从element中提出timestamp并且调用innterSharedAssigner(这里也就是CumulativeSliceAssigner)为其assign slice
public long assignSliceEnd(long timestamp) {
long start = TimeWindow.getWindowStartWithOffset(timestamp, offset, step);
return start + step;
}
/**
* Method to get the window start for a timestamp.
*
* @param timestamp epoch millisecond to get the window start.
* @param offset The offset which window start would be shifted by.
* @param windowSize The size of the generated windows.
* @return window start
*/
public static long getWindowStartWithOffset(long timestamp, long offset, long windowSize) {
return timestamp - (timestamp - offset + windowSize) % windowSize;
}实现看上去并不算复杂,使用step作为间隔,首先根据timestamp将其与step对齐,之后再加一个step作为slice end
2.3.2. getWindowStart, getLastWindowEnd
这两个function放在一起说
public long getLastWindowEnd(long sliceEnd) {
long windowStart = getWindowStart(sliceEnd);
return windowStart + maxSize;
}
@Override
public long getWindowStart(long windowEnd) {
return TimeWindow.getWindowStartWithOffset(windowEnd - 1, offset, maxSize);
}先看getWindowStart,它并不是对step进行对齐,而是对max size进行对齐,也就是说如果step为1小时,max size为1天,对于晚上00:00:00:000,它会根据timestamp 23:59:59:999进行计算,得到的是这一整天的window。进而对于getLastWindowEnd,也就是上面的道德一整天window的end
2.3.3. expiredSlices
在给定了一个window结束时间之后,expiredSlices会返回对于所有应该expired slice的iterator
@Override
public Iterable<Long> expiredSlices(long windowEnd) {
long windowStart = getWindowStart(windowEnd);
long firstSliceEnd = windowStart + step;
long lastSliceEnd = windowStart + maxSize;
if (windowEnd == firstSliceEnd) {
// we share state in the first slice, skip cleanup for the first slice
reuseExpiredList.clear();
} else if (windowEnd == lastSliceEnd) {
// when this is the last slice,
// we need to cleanup the shared state (i.e. first slice) and the current slice
reuseExpiredList.reset(windowEnd, firstSliceEnd);
} else {
// clean up current slice
reuseExpiredList.reset(windowEnd);
}
return reuseExpiredList;
}它主要用于找到所有expiredSlice并且对它们的状态进行清理
2.3.4. mergeSlices
@Override
public void mergeSlices(long sliceEnd, MergeCallback callback) throws Exception {
long windowStart = getWindowStart(sliceEnd);
long firstSliceEnd = windowStart + step;
if (sliceEnd == firstSliceEnd) {
// if this is the first slice, there is nothing to merge
reuseToBeMergedList.clear();
} else {
// otherwise, merge the current slice state into the first slice state
reuseToBeMergedList.reset(sliceEnd);
}
callback.merge(firstSliceEnd, reuseToBeMergedList);
}根据cumulate window的特性(比如step为1小时,max size为6小时的cumulate window,它会逐步输出前1个,前2个,前3个,前4个...前6个的结果,所以可以之后的slice都放进第1个,和第1个share状态)将之后的slice和第1个slice进行merge
2.3.5. nextTriggeringWindow
@Override
public Optional<Long> nextTriggerWindow(long windowEnd, Supplier<Boolean> isWindowEmpty) {
long nextWindowEnd = windowEnd + step;
long maxWindowEnd = getWindowStart(windowEnd) + maxSize;
if (nextWindowEnd > maxWindowEnd) {
return Optional.empty();
} else {
return Optional.of(nextWindowEnd);
}
}找到下一个会触发的window,同样使用上面step为1小时,max size为6小时的cumulate window为例,如果当前的window end是2小时,那么下一个出发的就是3小时;但是如果当前的window end是6小时,那么说明这个cumulate window已经结束,可以清理状态进行下一次计算,没有要继续触发的window
我们着重分析了slice assigner机制,但是这个思路其实不太对,过于着眼于细节,应该先大概了解为什么要这样做,这样做的步骤是什么,最后才是怎样把element分配到不同的slice里。所以之前我去看了下mini-batch aggregation的优化并总结了一篇文章,现在回头继续看Window中的优化。
1. Local Global Window Aggregation优化
这个优化其实和官方文档中给出的Local-Global Aggregation比较像,都是把aggregation的过程分成了两部分,第一部分是local aggregation,第二部分是global aggregation,除了官方文档中提到的可以避免hotspot problem之外,local global window aggregation还有一个好处就是可以重用某些状态。如果是cumulate window,之后所有的slice都可以复用第一个slice的状态

我们的测试环境为Flink 1.14.3,测试代码如下
public class CumulateWindowTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
ParameterTool parameterTool = ParameterTool.fromArgs(args);
env.setRestartStrategy(
RestartStrategies.failureRateRestart(
6,
org.apache.flink.api.common.time.Time.of(10L, TimeUnit.MINUTES),
org.apache.flink.api.common.time.Time.of(5L, TimeUnit.SECONDS)));
env.getConfig().setGlobalJobParameters(parameterTool);
env.setParallelism(1);
EnvironmentSettings settings =
EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);
// SQL query
String sourceSql =
"CREATE TABLE source_table (\n"
+ " user_id STRING,\n"
+ " price BIGINT,\n"
+ " row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),\n"
+ " WATERMARK FOR row_time AS row_time\n"
+ ") WITH (\n"
+ " 'connector' = 'datagen',\n"
+ " 'rows-per-second' = '1',\n"
+ " 'fields.user_id.length' = '2',\n"
+ " 'fields.price.min' = '1',\n"
+ " 'fields.price.max' = '10'\n"
+ ")";
String sinkSql =
"CREATE TABLE sink_table (\n"
+ " start_time TIMESTAMP,\n"
+ " end_time TIMESTAMP,\n"
+ " sum_price DOUBLE\n"
+ ") WITH (\n"
+ " 'connector' = 'print'\n"
+ ")";
String selectWhereSql =
"INSERT INTO sink_table\n"
+ "SELECT window_start, window_end, COUNT(*)\n"
+ "FROM TABLE(CUMULATE(TABLE source_table, DESCRIPTOR(row_time), INTERVAL '2' SECONDS, INTERVAL '10' SECONDS))\n"
+ "GROUP BY window_start, window_end\n";
tEnv.getConfig().getConfiguration().setString("pipeline.name", "Cumulate Window Test");
tEnv.executeSql(sourceSql);
tEnv.executeSql(sinkSql);
tEnv.executeSql(selectWhereSql);
}
}2. TwoStageOptimizedWindowAggregateRule
在之前分析mini-batch aggregation优化的文章里已经提到过Flink SQL的整体流程以及优化框架,这里不再赘述,我们直接看相关rule - TwoStageOptimizaedWindowAggregateRule的实现
2.1. matches

matches函数规定了在什么条件下这个rule可以被apply,可以发现有四个条件
- Table config中指定的aggregation phase strategy不能是ONE_PHASE
- Window要使用event time
- 所有的aggregation function都要支持merge()函数
- Input不是shuffle distribution
在table config中,aggregation phase strategy的默认值是AUTO,所以说即使不需要任何配置,只要满足(2)(3)(4)条件,这个优化就会自动生效,不需要在table config中显示声明。
2.2. onMatch
在onMatch函数中,可以发现它主要做了3件事情
2.2.1. 生成Local Aggregate Function
首先Flink会生成localAgg
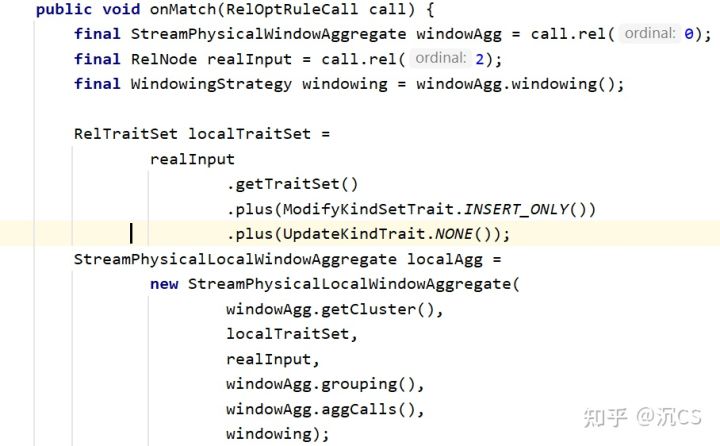
可以看到localAgg就是StreamPhysicalLocalWindowAggregate,而在之前mini-batch的源码分析文章中我们可以知道,StreamPhysical会转化为ExecNode,最终转化为Transformation,因此我们这里看一下ExecNode怎样转化为Transformation
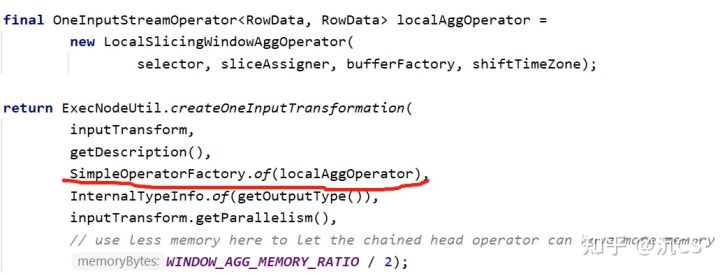
能够发现主要的逻辑都在LocalSlicingWindowAggOperator中,其中的关键函数如下

processElement会把进来的element放入windowBuffer里,而在处理watermark的时候,首先要分清楚函数里的两个概念:currentWatermark指的是目前系统中当前的watermark,而nextTriggerWatermark则指的是应该触发window的watermark
这里WindowBuffer的实现为RecordsWindowBuffer.java

可以看到它主要就是把record加入到buffer里,并在buffer已满或者需要触发window的时候调用flush,flush中会使用combineFunction将recordsBuffer中的元素combine起来
combineFunction的实现为LocalAggCombiner.java,它会根据生成的aggregator对元素进行处理

另外我们可以在log找到生成的LocalWindowAggsHandler,它的核心函数如下,因为在例子中我们需要的是COUNT(*),所以这里就是简单的+1L

2.2.2. 生成Exchange
onMatch做的第二件事情就是生成Exchange,它会在local aggregate和global aggregate中间对data进行转换

可以看到核心函数是satisfyDistribution
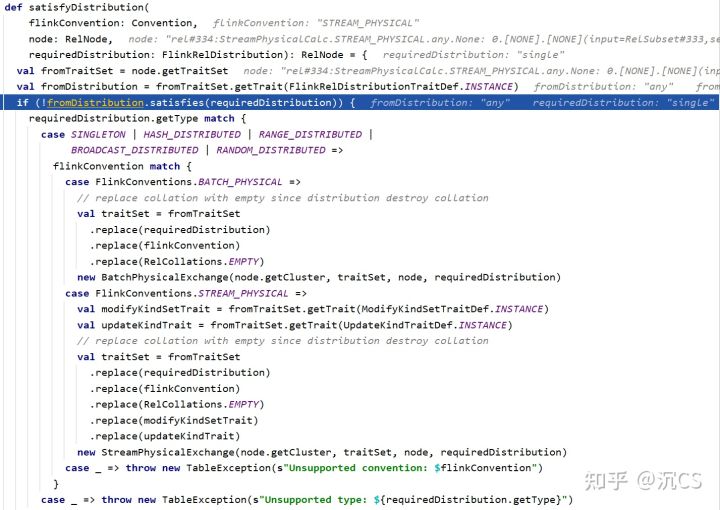
在运行过程中flinkConvention为STREAM_PHYSICAL,所以最终生成的是StreamPhysicalExchange,在生成Transformation的过程中,因为我们在代码中设置了parallelism为1,所以会使用GlobalPartitioner

2.2.3. 生成Global Aggregate Function
在onMatch函数中,最终会生成globalAgg并调用转换,也就是说将输入的StreamPhysicalWindowAggregate转化成了
StreamPhysicalLocalWindowAggregate -> StreamPhysicalExchange -> StreamPhysicalGlobalWindowAggregate

话不多说,直接来看它最后转化成Transformation的过程

可以看到它主要的processing logic都在windowOperator中,而windowOperator又是由localAggsHandler, globalAggsHandler和stateAggsHandler三部分组成,在查看了它们的代码之后惊讶的发现它们好像除了名字,其他的实现全都是一样的,核心函数有两个,分别是accumulate和merge


这两个函数都不难理解,这里就不再展开。那么它们什么时候会被调用呢?对于cumulate window,如下所示,在build()中会创建SliceSharedWindowAggProcessor
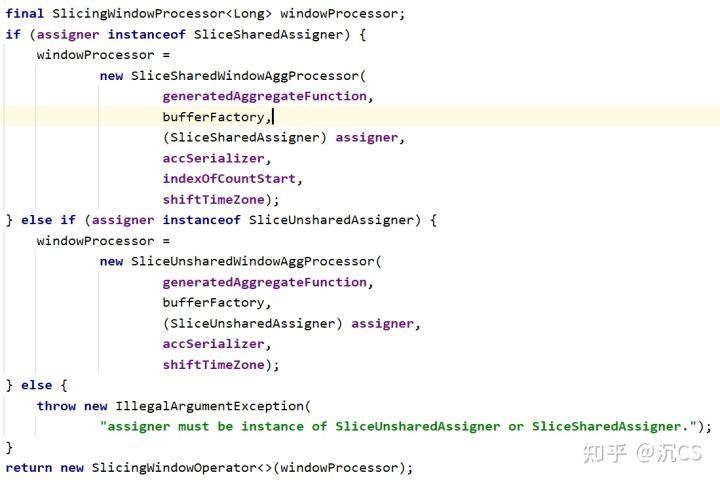
它继承自AbstractWindowAggProcessor,processElement在父类中实现

主要的逻辑也是将element放入windowBuffer,那么从对local aggregate的分析可知,既然由windowBuffer,那么一定也有相应的advanceProgress和combineFunction,这里的combineFunction就是GlobalAggCombiner,它对于combine的实现如下
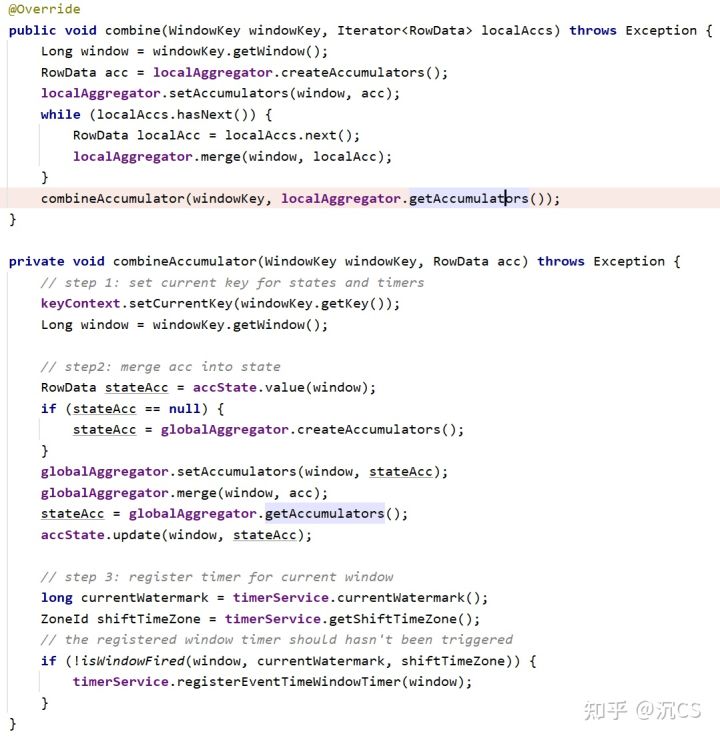
在代码中,它首先使用localAggregator将local的结果给merge起来,接着在combineAccumulator中,它会将merge的结果写入accState,也就是state backend中,同时给当前尚未fire的window注册trigger
最后在build()函数中,它会使用SlicingWindowOperator将生成的SliceSharedWindowAggProcessor包裹起来,SlicingWindowOperator在上面提到的注册的event timer出发时,会fire整个window

而fireWindow这个函数,还是依赖于SliceSharedWindowAggProcess

所以整体window的触发过程是,首先如果watermark已经达到window出发的标准,那么windowBuffer会将records combine起来,放入state backend并且注册定时器,在SlicingWindowOperator中onTimer会fire window并清空state
这两篇文章一起,从源码角度分析了Flink SQL对于window aggregation的优化,作者只是Flink一名小学生,如果有不对或者错误之处还请大家指出,非常感谢















 687
687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









