







一、dropout(随机失活)的用处
当你的网络存在过拟合现象时,可以考虑使用dropout正则化来处理。
二、dropout的做法
假设下图中左边的网络存在过拟合,dropout的做法就是对于网络中的每一层,设置一个概率值p,p表示对于该层的任一结点而言,保留它的概率为p,删除它的概率为1-p。假设每一层的p为0.5,则任何一个结点有50%的概率被删除,也就是网络中有接近一半的结点会被删除,同时删除网络图中对应的连线。因此使用dropout之后,我们得到了一个更加精简的网络模型。
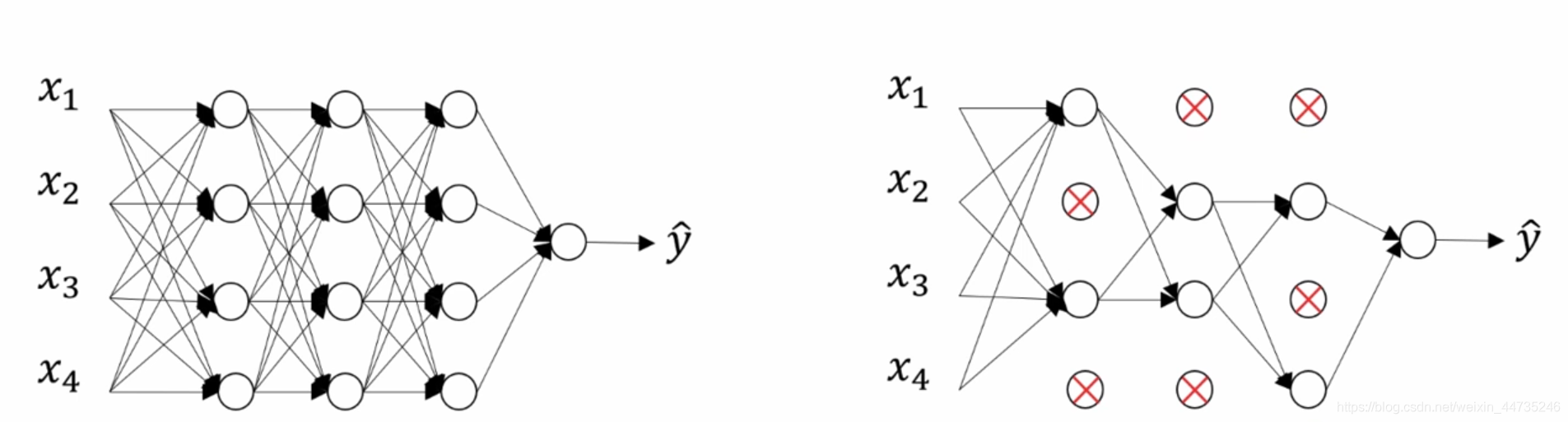
三、如何实施dropout
当前主要是用的是'Inverted dropout(反向随机失活)'。Inverted dropout的实现原理是在训练网络的每一个epoch,以keep_prob为概率来决定是否要保留该层中的任一结点。以一个三层网络的前向传播为例,代码实现如下:
keep_prob = 0.8
def foward(X):
# 3层neural network的前向传播
A1 = np.maximum(0, np.dot(W1, X) + b1) # 计算第一层网络的输出
D1 = (np.random.rand(*A1.shape) < keep_prob) # 以keep_prob为标准,判断该层结点哪些可以保留
Z1 = np.multiply(A1, D1) #dropout
Z1 /= keep_prob # 为了期望的一致,除以keep_prob
A2 = np.maximum(0, np.dot(W2, Z1) + b2)
D2 = (np.random.rand(*A2.shape) < keep_prob)
Z2 = np.multiply(A2, D2)
Z2 /= keep_prob
out = np.dot(W3, Z2) + b3
1、 np.random.rand()会生成一组在[0, 1)之间均匀分布的随机样本值。它主要应用于深度学习的dropout正则化方法,用于生成dropout随机向量D#number。
因此,上述代码中D1是一个大小和A1一致的随机向量,D1的值只有True和False。
2、将随机向量D1与第一层网络层的输出相乘,在python的相乘操作中,“False”被处理为0,“True”被处理为1,执行Z1 = np.multiply(A1, D1) 之后就等价于删除了某些结点。
3、最后将得到的Z值除以keep_prob,原因是:为了保网络中结点输出值的期望不变。
在没有进行dropout时,输出值为a,期望为a;
而在应用了dropout之后,每一个神经元有1-keep_prob的概率被删除,也就是有keep_prob的概率为a,1-keep_prob的概率为0,此时期望为a*keep_prob。因此需要执行除以keep_prob的操作。
四、为什么dropout有效?
首先,直观上理解使用dropout之后,相当于将原本较大、较复杂的网络变成一个相对简单的网络,网络参数也就少了,一定程度上也就减少了过拟合。
第二种直观认识,以下图为例,黄色神经元接受4个输入,并给出输出。使用了dropout之后,4个输入神经元中的任意一个都有一定概率在每次的epoch中被删除,这也就会导致黄色的神经元在训练的过程中不会过度依赖任意一个输入神经元,因为任意一个神经元都有着随时“战死”的可能。因此,不可能给其中的一个神经元赋予过大的权重,最终会使得dropout产生收缩权重的平方范数的效果,这也就和L2正则化的效果类似了。

五、注意
1、只是在训练阶段使用dropout,测试阶段不使用
2、可以给每一层设置不同的keep_prob,但是keep_prob也作为网络的超参数进行学习。一般对于参数较多的那一层选择较大的keep_prob。














 5742
5742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









