






1.首先看merge的功能介绍:merge语句将来自两个或多个SAS数据集的观测值连接为单个观测值。
2.一对一合并:将来自两个或多个SAS数据集的观测值合并为新数据集中的单个观测值。语法是直接使用merge语句,不带by。SAS将merge语句中指定的所有数据集中的第一个观测值合并为新数据集中的第一个观测值,将所有数据集中的第二个观测值合并为新数据集中的第二个观测值,依此类推。在一对一合并中,新数据集中的观测数等于merge语句中指定的最大数据集中的观测数。
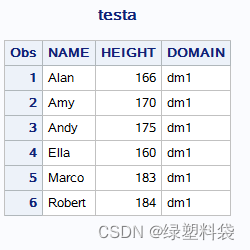
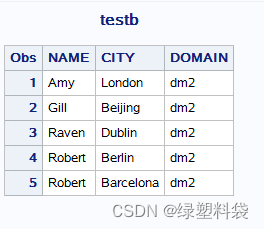
举例。首先制作两个数据集testa和testb:
通过不带by的merge语句进行合并:
data test1_1;
merge testa(in=a) testb(in=b);
ina=a;
inb=b;
run;
data test1_2;
merge testb(in=b) testa(in=a);
ina=a;
inb=b;
run; 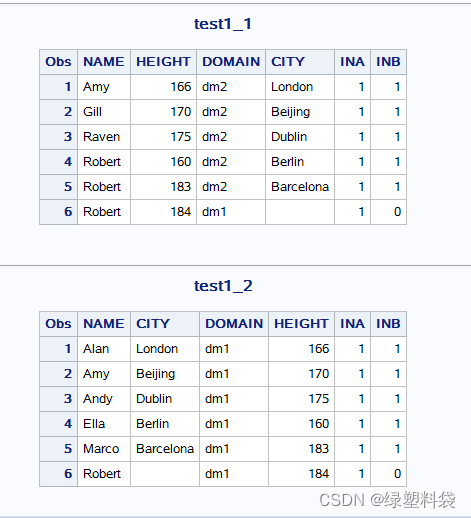
此时merge语句是通过行数依次进行连接,不进行匹配,新数据集的观测数为最大数据集testb的观测数。同时两个数据集在merge语句中出现的顺序不同也得到不同的结果,可以看出merge语句是以第二个数据集为基准进行合并的。
这种合并方式要求数据集事先被处理和排序好,否则会得到混乱的结果。
3.匹配合并:根据公共变量的值,将两个或多个SAS数据集的观测值合并为新数据集中的单个观测值。新数据集中的观测数是所有数据集中每个by组的最大观测数之和。merge语句不会在多对多匹配合并中产生笛卡尔积。相反,当至少一个数据集中的by组中存在观察值时,它执行一对一合并。当从一个数据集中读取了by组中的所有观测值,并且在另一个数据集中还有更多的观测值时,SAS执行一对多合并,直到所有by组观测值都被读取。
举例。还是上面的数据集testa和testb
data test2_1;
merge testa(in=a) testb(in=b);
by name;
ina=a;
inb=b;
run;
data test2_2;
merge testb(in=b) testa(in=a);
by name;
ina=a;
inb=b;
run;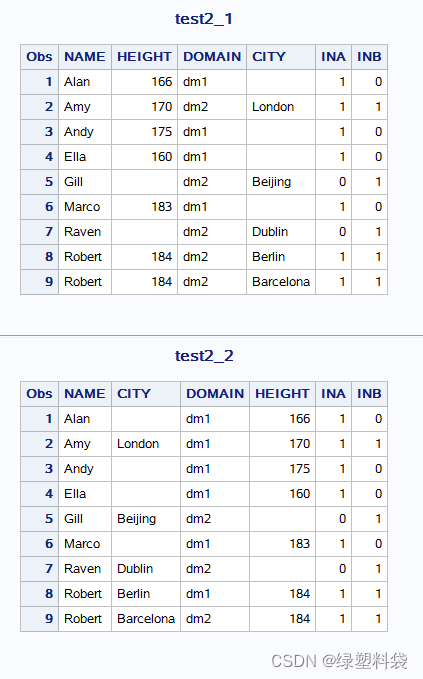
得到按照name变量的匹配的新数据集,merge语句中的数据集出现顺序决定了同名变量domain的覆盖方式,也是以第二个数据集为准。
4.in=option的用法.
首先看in= option的功能介绍:创建一个布尔变量,该变量指示数据集是否为当前观测提供了数据。在data步中,如果数据集对当前观测值提供了数据,则变量的值为1。否则,该值为0。
适用范围: 适用于SET,MERGE,MODIFY和 UPDATE操作,在数据集名称后的括号中指定IN= data set选项。IN=变量的值在data步中有效,此变量不包括在正在创建的SAS数据集中,需要分配一个新变量。















 2967
2967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









