







1. 随机函数
NumPy中也有自己的随机函数,包含在random模块中。它能产生特定分布的随机数,如正态分布等。接下来介绍一些常用的随机数。

numpy.random.rand
返回 0 到 1 之间的随机浮点数
numpy.random.rand(d0,d1,…,dn)- rand函数根据给定维度生成[0,1)之间的数据,包含0,不包含1
- 数量均匀分布
- dn表示每个维度
- 返回值为指定维度的array
# 创建4行2列的随机数据
np.random.rand(4,2)
'''
array([[0.02533197, 0.80477348],
[0.85778508, 0.01261245],
[0.04261013, 0.26928786],
[0.81136377, 0.34618951]])
'''
numpy.random.randn
标准正态分布又称为u分布,是以0为均值、以1为标准差的正态分布,记为N(0,1)。
numpy.random.randn(d0,d1,…,dn)- randn函数返回一个或一组样本,具有标准正态分布。
- dn表示每个维度
- 返回值为指定维度的array
from matplotlib import pyplot as plt
a = np.random.randn(10)
print(a)
# 直方图
plt.hist(a) 
numpy.random.randint()
返回随机整数
numpy.random.randint(low, high=None, size=None, dtype=’l’)- 返回随机整数,范围区间为[low,high),包含low,不包含high
- 参数:low为最小值,high为最大值,size为数组维度大小,dtype为数据类型,默认的数据类型是np.int
- high没有填写时,默认生成随机数的范围是[0,low)
np.random.randint(10,size=5) # array([1, 0, 6, 8, 0])
np.random.randint(2,10,size=5) # array([7, 6, 7, 8, 3])
np.random.randint(2,10,size=(2,5))
'''
array([[7, 7, 2, 7, 4],
[5, 8, 6, 9, 7]])
'''
# 返回1个[1,5)之间的随机整数
np.random.randint(1,5) # 2
numpy.random.sample
返回半开区间[0.0, 1.0)内的随机浮点数。
numpy.random.sample(size=None)np.random.seed()
随机种子
numpy.random.randn(d0,d1,…,dn)- 使用相同的seed()值,则每次生成的随机数都相同,使得随机数可以预测
- 但是,只在调用的时候seed()一下并不能使生成的随机数相同,需要每次调用都seed()一下,表示种子相同,从而生成的随机数相同。
L1与L2不同
np.random.seed(2)
L1 = np.random.randn(3, 3)
L2 = np.random.randn(3, 3)
print(L1)
print("-"*10)
print(L2)L1与L2相同
np.random.seed(1)
L1 = np.random.randn(3, 3)
np.random.seed(1)
L2 = np.random.randn(3, 3)
print(L1)
print("-"*10)
print(L2)numpy.random.normal
正态分布返回一个由size指定形状的数组,数组中的值服从 μ=loc,σ=scale 的正态分布。
numpy.random.normal(loc=0.0, scale=1.0, size=None)- loc : float型或者float型的类数组对象,指定均值 μ
- scale : float型或者float型的类数组对象,指定标准差 σ
- size : int型或者int型的元组,指定了数组的形状。如果不提供size,且loc和scale为标量(不是类数组对象),则返回一个服从该分布的随机数。
2. 常用函数
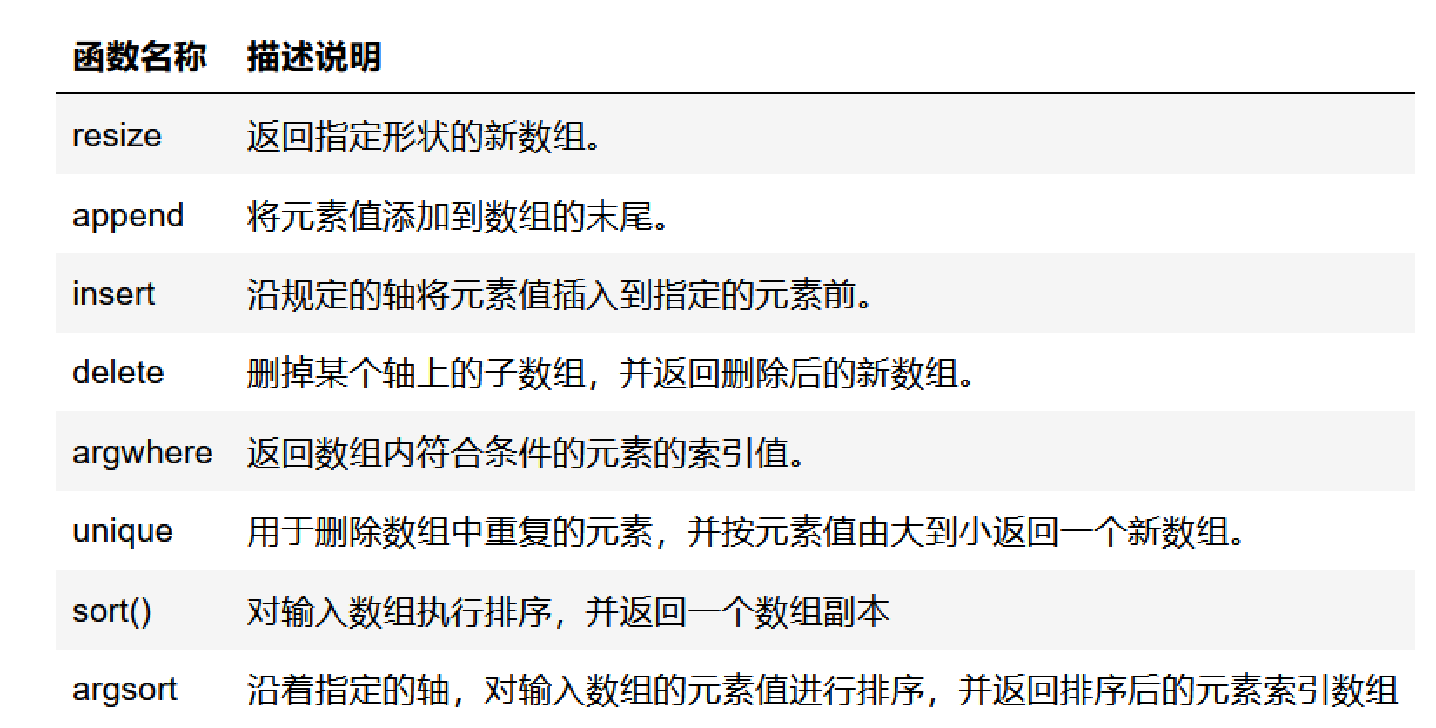
numpy.resize()
numpy.resize(arr, shape)numpy.resize() 返回指定形状的新数组。
numpy.resize(arr,shape) 和ndarray.resize(shape, refcheck=False)区别:
- numpy.resize(arr,shape),有返回值,返回复制内容.如果维度不够,会使用原数组数据补齐
- ndarray.resize(shape, refcheck=False),修改原数组,不会返回数据,如果维度不够,会使用0补齐
numpy.append()
在数组的末尾添加值,默认返回一个一维数组。
numpy.append(arr, values, axis=None)参数说明:
- arr:输入的数组;
- values:向 arr 数组中添加的值,需要和 arr 数组的形状保持一致;
- axis:默认为 None,返回的是一维数组;当 axis =0 时,追加的值会被添加到行,而列数保持不变,若 axis=1 则与其恰好相反。
a = np.array([[1,2,3],[4,5,6]])
#向数组a添加元素
print (np.append(a, [7,8,9])) # [1 2 3 4 5 6 7 8 9]
#沿轴 0 添加元素
print (np.append(a, [[7,8,9]],axis = 0))
'''
[[1 2 3]
[4 5 6]
[7 8 9]]
'''
#沿轴 1 添加元素
print (np.append(a, [[5,5,5],[7,8,9]],axis = 1))
'''
[[1 2 3 5 5 5]
[4 5 6 7 8 9]]
'''
numpy.insert()
表示沿指定的轴,在给定索引值的前一个位置插入相应的值,如果没有提供轴,则输入数组被展开为一维数组。
numpy.insert(arr, obj, values, axis)参数说明:
- arr:要输入的数组
- obj:表示索引值,在该索引值之前插入 values 值;
- values:要插入的值;
- axis:指定的轴,如果未提供,则输入数组会被展开为一维数组。
a = np.array([[1,2],[3,4],[5,6]])
#不提供axis的情况,会将数组展开
print (np.insert(a,3,[11,12])) # [ 1 2 3 11 12 4 5 6]
#沿轴 0 垂直方向
print (np.insert(a,1,[11],axis = 0))
'''
[[ 1 2]
[11 11]
[ 3 4]
[ 5 6]]
'''
#沿轴 1 水平方向
print (np.insert(a,1,11,axis = 1))
'''
[[ 1 11 2]
[ 3 11 4]
[ 5 11 6]]
'''
numpy.delete()
该方法表示从输入数组中删除指定的子数组,并返回一个新数组。它与 insert() 函数相似,若不提供 axis 参数,则输入数组被展开为一维数组。
numpy.delete(arr, obj, axis) 参数说明:
- arr:要输入的数组;
- obj:整数或者整数数组,表示要被删除数组元素或者子数组;
- axis:沿着哪条轴删除子数组。
a = np.arange(12).reshape(3,4)
#a数组
print(a)
'''
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
'''
#不提供axis参数情况
print(np.delete(a,5)) # [ 0 1 2 3 4 6 7 8 9 10 11]
#删除第二列
print(np.delete(a,1,axis = 1))
#删除多行
print(np.delete(a,[1,2],axis = 0))
# 注意不能使用切片的形式
# print(np.delete(a,[1:4]))np.s_[1:4] # slice(1, 4, None)
np.r_[1:4] # array([1, 2, 3])
np.c_[1:4]
'''
array([[1],
[2],
[3]])
'''numpy.argwhere()
该函数返回数组中非 0 元素的索引,若是多维数组则返回行、列索引组成的索引坐标。
print(x)
'''
[[0 1 2]
[3 4 5]]
'''
#返回所有大于1的元素索引
y=np.argwhere(x>1)
print(y,y.shape)
'''
[[0 2]
[1 0]
[1 1]
[1 2]] (4, 2)
'''
numpy.unique()
用于删除数组中重复的元素,其语法格式如下:
numpy.unique(arr, return_index, return_inverse, return_counts)参数说明:
- arr:输入数组,若是多维数组则以一维数组形式展开;
- return_index:如果为 True,则返回新数组元素在原数组中的位置(索引);
- return_inverse:如果为 True,则返回原数组元素在新数组中的位置(索引);
- return_counts:如果为 True,则返回去重后的数组元素在原数组中出现的次数。
a = np.array([5,2,6,2,7,5,6,8,2,9])
# 对a数组的去重,并排序
uq = np.unique(a)
print(uq) # [2 5 6 7 8 9]
u,indices = np.unique(a, return_index = True)
# 打印去重后数组在原数组的索引
print(u)
print('-'*20)
print(indices)
'''
[2 5 6 7 8 9]
--------------------
[1 0 2 4 7 9]
'''
ui,indices = np.unique(a,return_inverse = True)
print (ui)
print('-'*20)
# 打印原数组在去重后数组的索引
print (indices)
'''
[2 5 6 7 8 9]
--------------------
[1 0 2 0 3 1 2 4 0 5]
'''
# 返回去重元素的重复数量
uc,indices = np.unique(a,return_counts = True)
print (uc)
# 元素出现次数:
print (indices)
'''
[2 5 6 7 8 9]
[3 2 2 1 1 1]
'''
numpy.sort()
对输入数组执行排序,并返回一个数组副本。
numpy.sort(a, axis, kind, order)参数说明:
- a:要排序的数组;
- axis:沿着指定轴进行排序,如果没有指定 axis,默认在最后一个轴上排序,若 axis=0 表示按列排序,axis=1 表示按行排序;
- kind:默认为 quicksort(快速排序);
- order:若数组设置了字段,则 order 表示要排序的字段。
a = np.array([[3,7,5],[6,1,4]])
#调用sort()函数
print(np.sort(a)) # 默认axis=1 行的数据排序
'''
[[3 5 7]
[1 4 6]]
'''
print(np.sort(a, axis = 0)) # 列的数据排序
'''
[[3 1 4]
[6 7 5]]
'''
#设置在sort函数中排序字段
dt = np.dtype([('name', 'S10'),('age', int)])
a = np.array([("raju",21),("anil",25),("ravi", 17), ("amar",27)], dtype = dt)
#再次打印a数组
print(a)
print('--'*10)
#按name字段排序
print(np.sort(a, order = 'name'))
'''
[(b'raju', 21) (b'anil', 25) (b'ravi', 17) (b'amar', 27)]
--------------------
[(b'amar', 27) (b'anil', 25) (b'raju', 21) (b'ravi', 17)]
'''numpy.argsort()
argsort() 沿着指定的轴,对输入数组的元素值进行排序,并返回排序后的元素索引数组。示例如下:
a = np.array([90, 29, 89, 12])
print("原数组:",a)
sort_ind = np.argsort(a)
print("打印排序元素索引值:",sort_ind)
#使用索引数组对原数组排序
sort_a = a[sort_ind]
print("打印排序数组")
for i in sort_ind:
print(a[i],end = " ")
'''
原数组: [90 29 89 12]
打印排序元素索引值: [3 1 2 0]
打印排序数组
12 29 89 90
'''
a[sort_ind] # array([12, 29, 89, 90])














 2716
2716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









