







文章目录
一、简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
https://blog.csdn.net/qq_35246620/article/details/88576800
https://blog.csdn.net/qq_26735495/article/details/108719844
https://blog.csdn.net/long9827/article/details/108637471
二、HDFS
搭建集群(阿里云ubuntu服务器上搭建)
-
这里设置三台服务器,但是这里我搭建只是用了两个(主节点master和数据节点slave1)
-
搭建高可用集群阿里上的五台服务器,一主一备三集群(master主,slave1从,slave2,slave3,slave4集群节点),请跳转到第七部分
需要JDK环境,且保证各个节点中的hadoop安装目录在相同目录路径下!!!
-
服务器上搭建时,同一个区域中的服务器(配置使用内网搭建,速度快)
修改 vi /etc/hosts 的文件,使用内网的ip
172.27.66.8 master 172.27.66.9 slave1 172.27.66.10 slave2 -
在相应的主机中修改名称(或者是修改hosts的文件的名称,为了便于后期使用,建议修改名称)
hostnamectl set-hostname master hostnamectl set-hostname slave1 hostnamectl set-hostname slave2 -
设置主机之间的相互免密登录(设置公钥)
-
安装hadoop
配置系统配置文件,在 /etc/profile 中加入
export PATH=$PATH:/home/hadoop-3.2.2/bin:/home/hadoop-3.2.2/sbin source /etc/profile -
修改配置文件(/home/hadoop-3.2.2/etc/hadoop)
修改 core-site.xml
<configuration> <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> <description>HDFS 的 URI,文件系统://namenode标识:端口</description> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoopData</value> <description>namenode 上传到 hadoop 的临时文件夹</description> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> </configuration>修改 hdfs-site.xml
<configuration> <!-- hdfs保存namenode当前数据的路径,默认值需要配环境变量,建议使用自己创建的路径,方便管理--> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoopData/dfs/name</value> <description>datanode 上存储 hdfs 名字空间元数据</description> </property> <!-- hdfs保存datanode当前数据的路径,默认值需要配环境变量,建议使用自己创建的路径,方便管理--> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoopData/dfs/data</value> <description>datanode 上数据块的物理存储位置</description> </property> <!-- hdfs存储数据的副本数量(避免一台宕机),可以不设置,默认值是3 --> <property> <name>dfs.replication</name> <value>1</value> <description>副本个数,默认配置是 3,小于两台主机的数量</description> </property> <!--hdfs 监听namenode的web的地址,默认就是9870端口,如果不改端口也可以不设置 --> <property> <name>dfs.namenode.http-address</name> <value>hadoop101:9870</value> </property> </configuration>修改 yarn-site.xml
<!-- 必须配置指定YARN的老大(ResourceManager)在哪一台主机 --> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <!-- 必须配置提供mapreduce程序获取数据的方式 默认为空 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>修改 mapred-site.xml
<configuration> <!-- 必须设置,mapreduce程序使用的资源调度平台,默认值是local,若不改就只能单机运行,不会到集群上了 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 这是3.2以上版本需要增加配置的,不配置运行mapreduce任务可能会有问题,记得使用自己的路径 --> <property> <name>mapreduce.application.classpath</name> <value> /home/hadoop-3.2.2/etc/hadoop, /home/hadoop-3.2.2/share/hadoop/common/*, /home/hadoop-3.2.2/share/hadoop/common/lib/*, /home/hadoop-3.2.2/share/hadoop/hdfs/*, /home/hadoop-3.2.2/share/hadoop/hdfs/lib/*, /home/hadoop-3.2.2/share/hadoop/mapreduce/*, /home/hadoop-3.2.2/share/hadoop/mapreduce/lib/*, /home/hadoop-3.2.2/share/hadoop/yarn/*, /home/hadoop-3.2.2/share/hadoop/yarn/lib/* </value> </property> </configuration>修改 workers
slaves文件里面记录的是集群里所有DataNode的主机名(这里包括了NameNode)
master slave1修改 start-dfs.sh 和 stop-dfs.sh,将以下参数添加到start-dfs.sh和stop-dfs.sh的顶部
路径 /home/hadoop-3.2.2/sbin
HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root修改 start-yarn.sh 和 stop-yarn.sh 以下参数添加到start-yarn.sh和stop-yarn.sh的顶部
路径 /home/hadoop-3.2.2/sbin
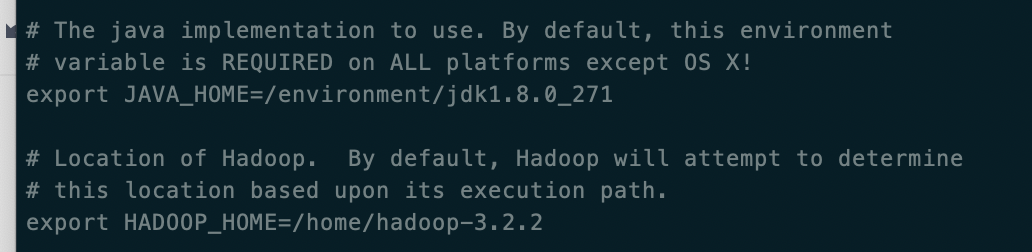
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root修改 hadoop-env.sh文件下,添加java的地址和HADOOP_HOME地址
路径/home/hadoop-3.2.2/etc/hadoop
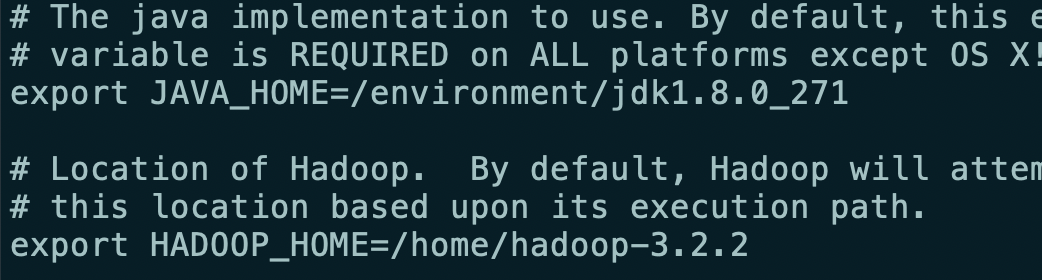
修改yarn-env.sh 文件添加java的地址
路径/home/hadoop-3.2.2/etc/hadoop
-
在其它节点中也进行相应的配置
直接复制 hadoop 的文件目录到跟主节点相同的路径下
scp -r /home/hadoop-3.2.2 root@slave1:/home/ -
在主机中格式化namenode
#在主机下格式化namenode hdfs namenode -format #启动和关闭HDFS start-dfs.sh stop-dfs.sh #启动和关闭yarn start-yarn.sh stop-yarn.sh #启动全部 start-all.sh stop-all.sh -
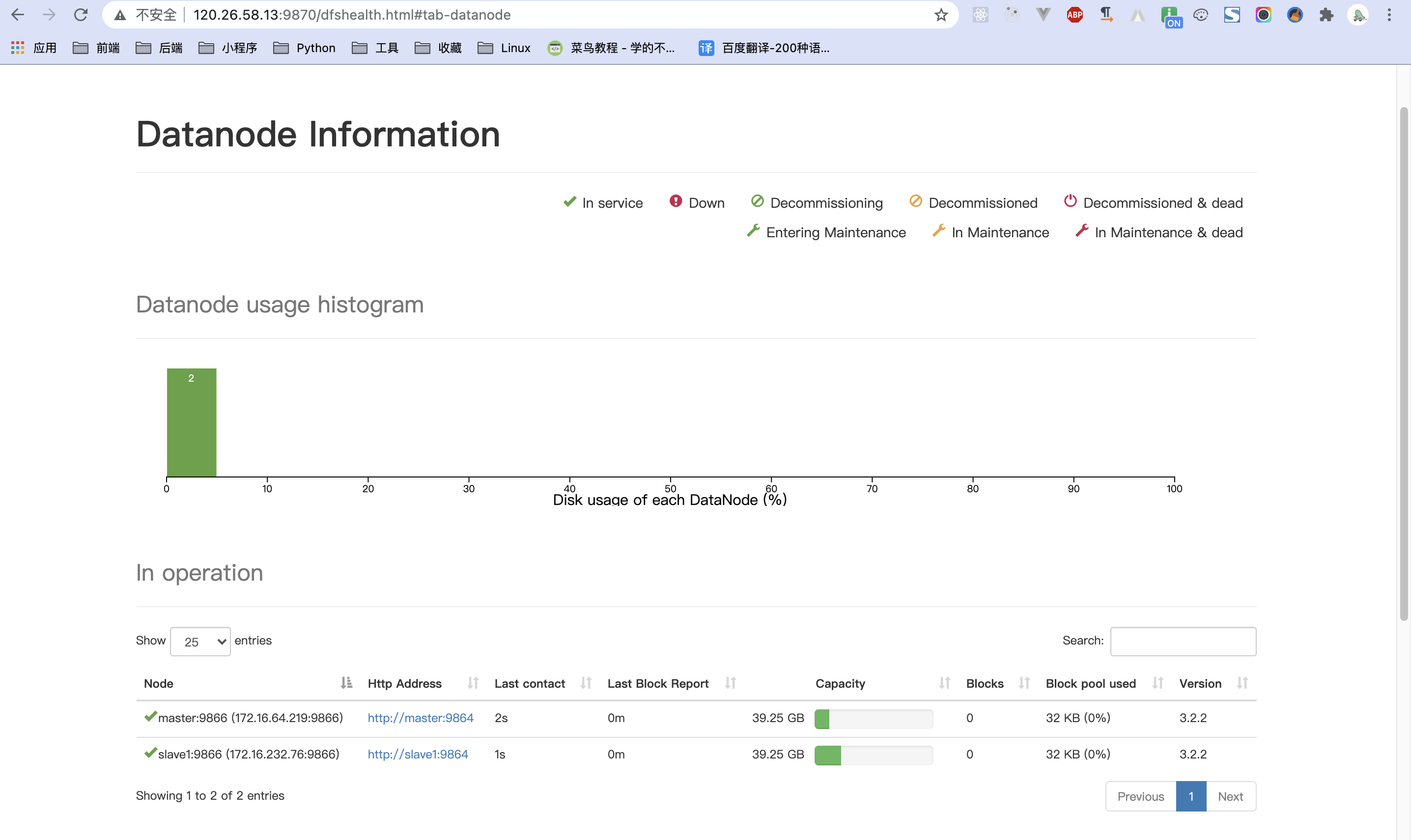
打开安全组的9870端口, 访问3.x以上版本为9870,2.x为50070
主节点master
子节点slave1

出现以下则搭建成功
三、启动yarn资源管理器
start-yarn.sh
jps
#出现ResourceManager和NodeManager说明启动成功
四、上传文件到hdfs中
命令操作hdfs
hadoop fs -count /a #获取文件数量
hadoop fs -rm -r /user #删除文件夹
hadoop fs -du /b/a.jpg #查看文件大小
hadoop fs -find /b -iname "a.jpg*" #模糊查询
hadoop fs -ls / #列出目录
hadoop fs -mkdir /test #在根目录下创建一个目录test
hadoop fs -put ./test.txt /test #将本地的test.txt文件上传到HDFS根目录下的test文件夹中去
hadoop fs -copyFromLocal ./test.txt /test #同上
hadoop fs -get /test/test.txt #从HDFS目录中获取文件
hadoop fs -getToLocal /test/test.txt #同上
hadoop fs -cp /test/test.txt /test1 #HDFS内部的复制
hadoop fs -rm /test1/test.txt #移除
hadoop fs -mv /test/test.txt /test1 #如果两个参数中所包含的文件是再用一个文件夹下则该指令为重命名,如果两个文件不再同一个文件夹下则该指令为移动
修改目录下的权限,在web界面中可以直接删除文件
hdfs dfs -chmod -R 777 /home
SprngBoot 操作hdfs
mac操作时,需在上**/etc/hosts** 上增加ip映射

文件的分割
文件大小 < 块设定值,文件不会被切割,直接存放到 hdfs 上,占用磁盘的空间就是文件大小
文件大小 > 块设定值,文件被切割为块大小的 N 份文件,最后一份不够块大小也上面一样,只占用本身大小的磁盘空间
下面中mp.mp4的文件大小大于块的128,将存在DataNode中(因为设置的时候副本设置为1),若上传的文件的数量小于块的数量,则会直接存放在NameNode中


五、HBase数据库
HDFS是文件系统,而HBase是数据库,其实也没啥可比性。「你可以把HBase当做是MySQL,把HDFS当做是硬盘。HBase只是一个NoSQL数据库,把数据存在HDFS上。
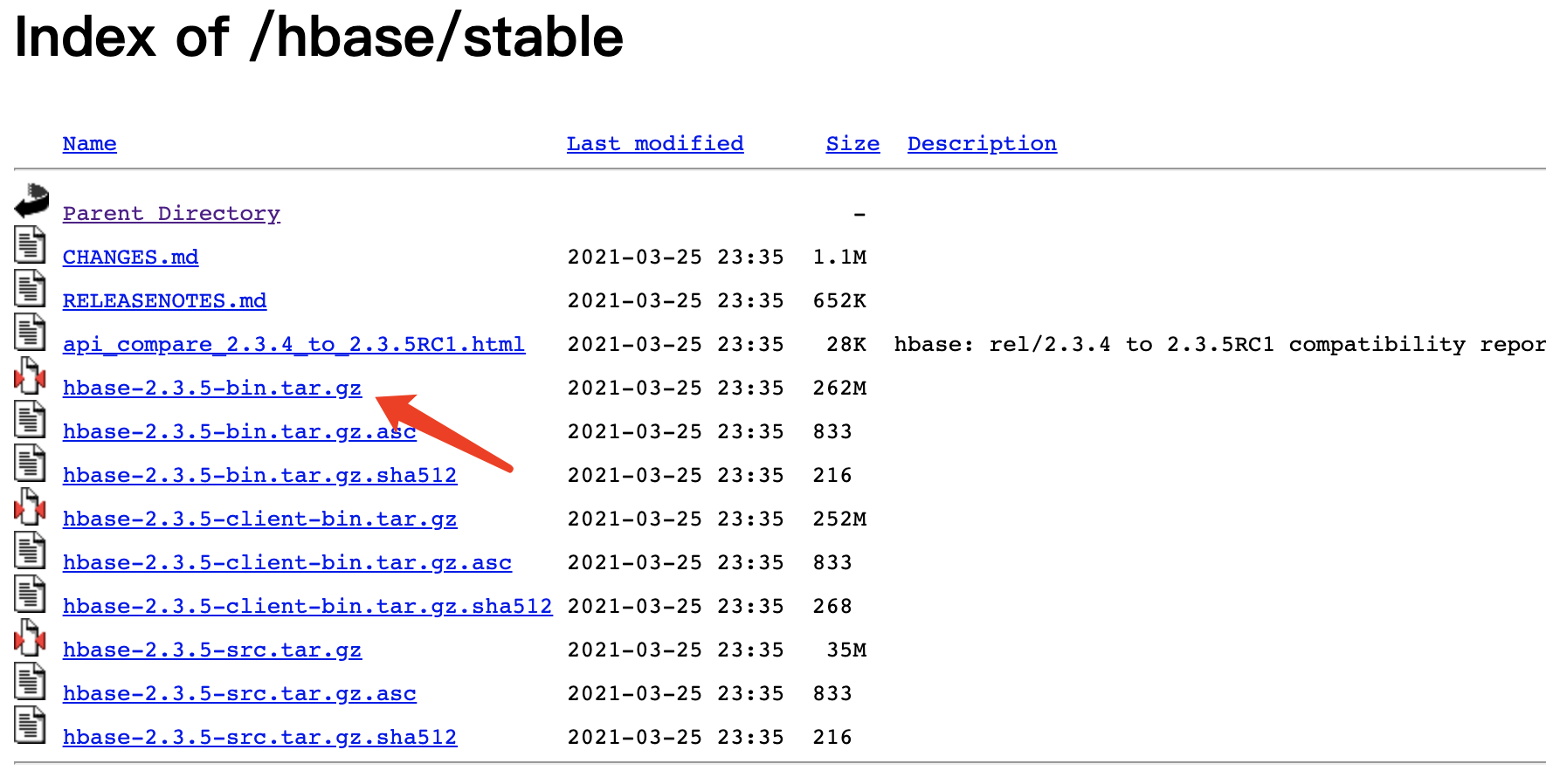
安装
与hdfs一样,各个节点中的安装目录最好是相同的
-
-
修改配置文件
https://blog.csdn.net/hll19950830/article/details/79953654
https://blog.csdn.net/xqclll/article/details/53907032
cd /home/environment/hbase-2.3.5/conf修改hbase-site.xml
# 修改hbase的配置文件hbase-site.xml 加入 <!--设置hbase模式为集群模式--> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 设置tmp文件路径 --> <property> <name>hbase.tmp.dir</name> <value>/home/environment/hbaseTmp/</value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> <!--设置hbase的master端口地址,与hdfs中的core-site.xml中的defaultFS中的地址端口一致,路径可以不一样--> <property> <name>hbase.rootdir</name> <value>hdfs://master:9000/hbaseData</value> </property> <!--设置zookeeper位于哪几个节点上--> <property> <name>hbase.zookeeper.quorum</name> <value>master,slave1</value> </property>修改 hbase-env.sh
#修改jdk路径 export JAVA_HOME=/environment/jdk1.8.0_271 #修改为安装的hadoop的配置文件目录 export HBASE_CLASSPATH=/home/hadoop-3.2.2/etc/hadoop #使用hbase自带的zookeeper 否则设置为false export HBASE_MANAGES_ZK=true修改regionservers
master slave1 -
将整个文件hbase-2.3.5文件目录传到其它节点上并修改对应节点上的jdk路径和hadoop的配置文件目录
-
配置环境变量 hbse
export PATH=$PATH:/home/environment/hbase-2.3.5/bin source /etc/profile -
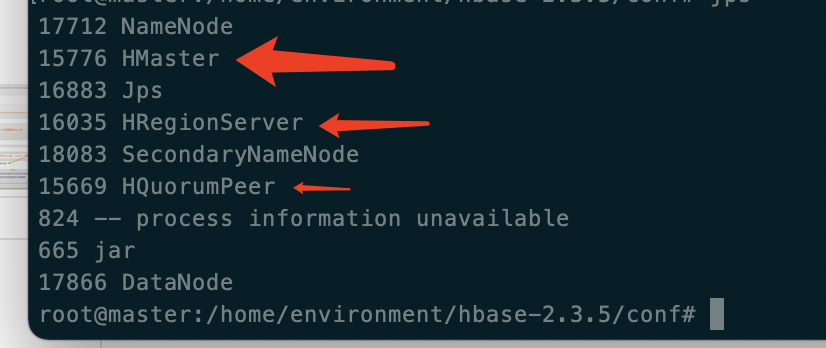
在主节点中使用 start-hbase.sh 启动
master中
slave1

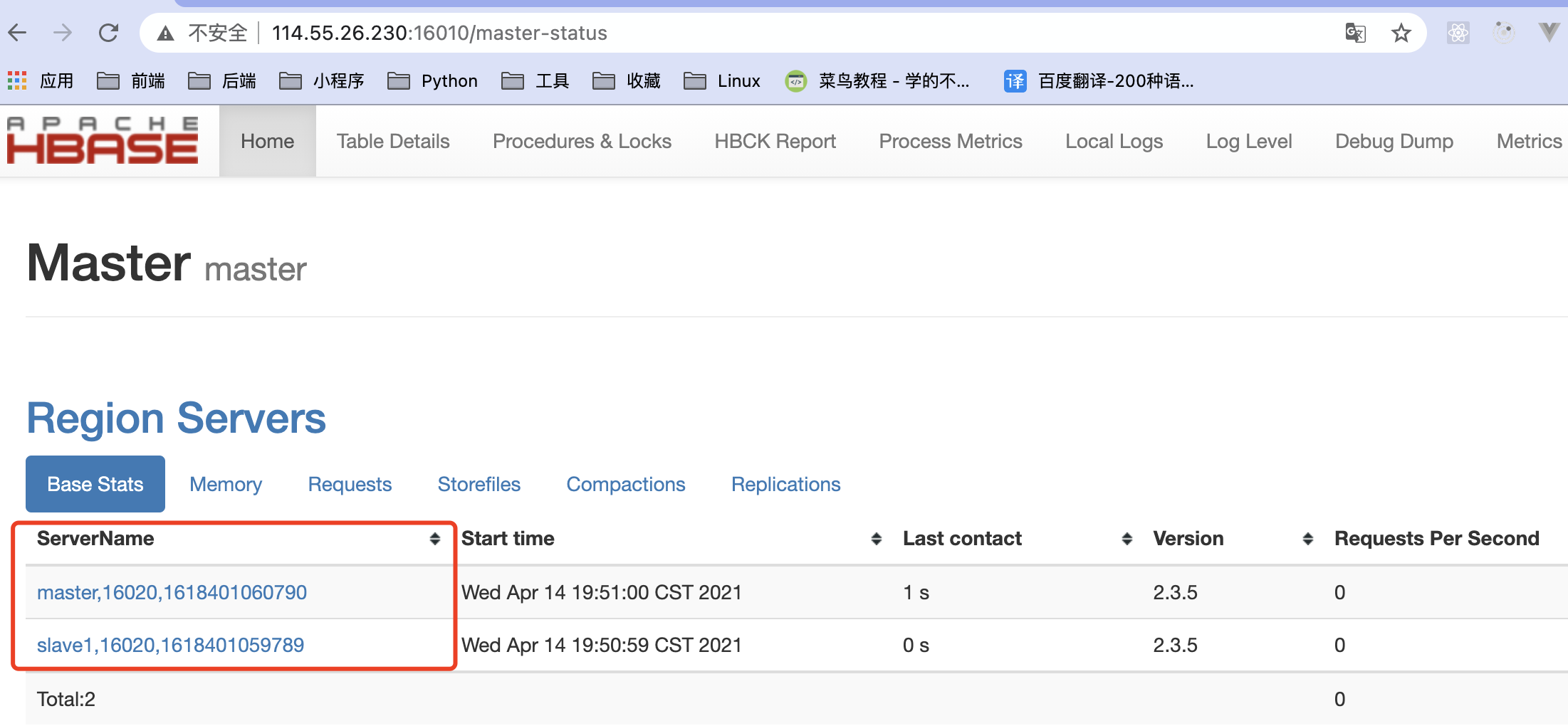
访问16010端口出现下面表示搭建成功
java操作
java实现hbase数据库的增删改查操作(新API) 12
六、Spark
简介
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
安装scala
-

-
配置环境变量
#scala export PATH=$PATH:/home/environment/scala-2.13.5/bin source /etc/profile -
测试是否成功

安装spark

-
修改配置文件conf文件下的 spark-env.sh.template 和 workers.template重命名
cp spark-env.sh.template spark-env.sh,修改spark-env.sh文件,增加export JAVA_HOME=/environment/jdk1.8.0_271 export HADOOP_HOME=/home/hadoop-3.2.2 export HADOOP_CONF_DIR=/home/hadoop-3.2.2/etc/hadoop export SCALA_HOME=/home/environment/scala-2.13.5 export SPARK_HOME=/home/environment/spark export SPARK_MASTER_IP=master #export SPARK_MASTER_PORT=7077 #修改web访问页面的端口,默认为8080 export SPARK_MASTER_WEBUI_PORT=8099 #export SPARK_WORKER_CORES=3 #export SPARK_WORKER_INSTANCES=1 export SPARK_WORKER_MEMORY=1G #export SPARK_WORKER_WEBUI_PORT=8081 #export SPARK_EXECUTOR_CORES=1 #export SPARK_EXECUTOR_MEMORY=1G #export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$HADOOP_HOME/lib/nativecp workers.template workers,设置的ip映射名称
-
将 scala 和 spark 的安装目录拷贝到其它节点中
* 注意修改启动的配置文件的 java 和 hadoop 目录文件信息(尽量放置在相同的目录下)*
-
启动
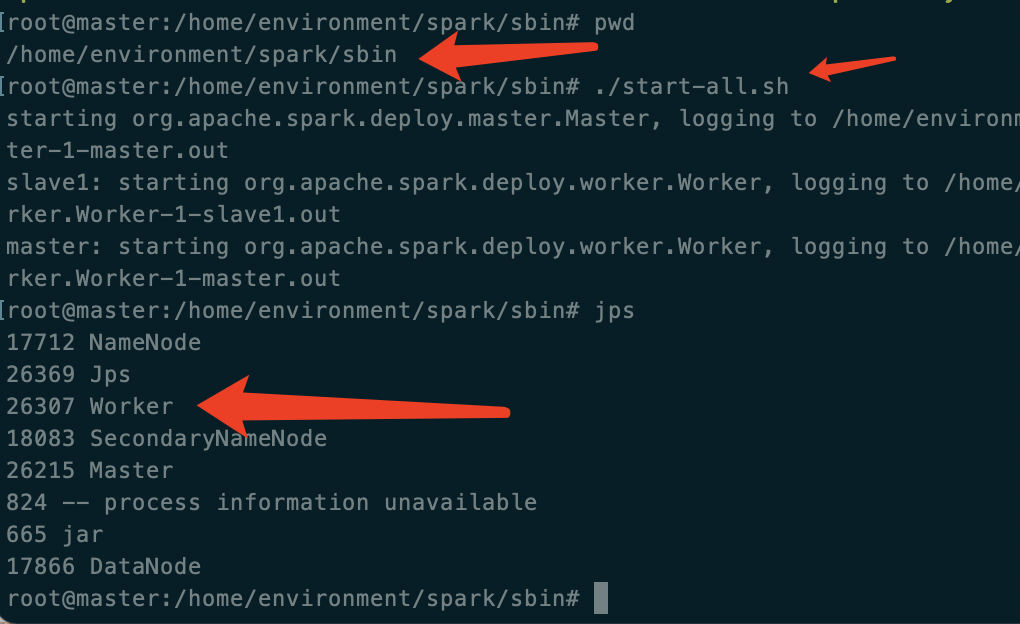
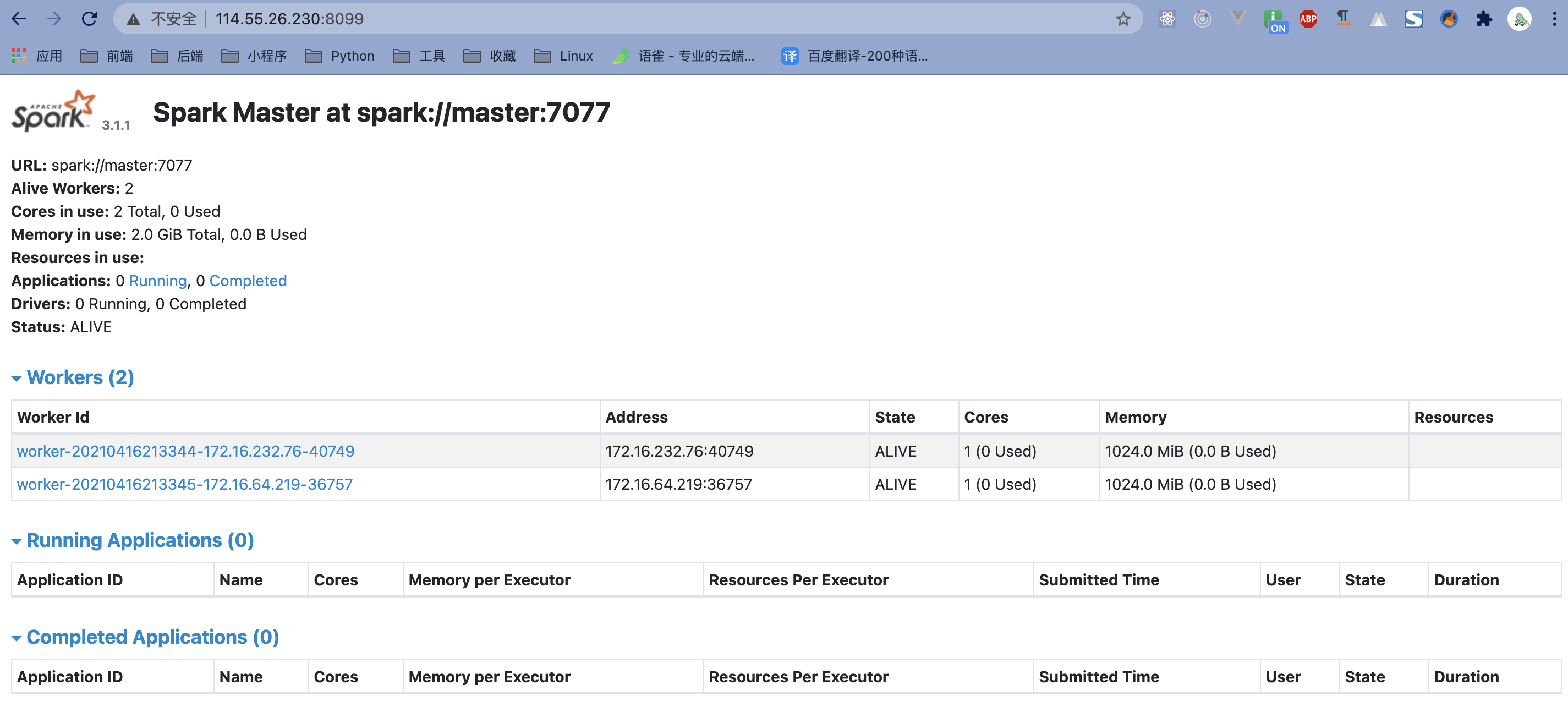
在 sbin 目录下启动 ./start-all.sh
主副节点中出现 Worker 则表示启动成功
测试
在阿里云ECS的Ubuntu中安装Spark,参考测试 19
-
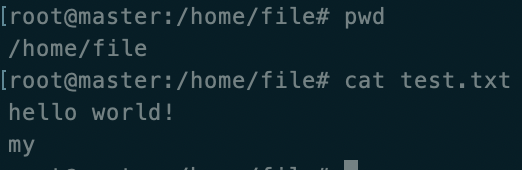
在服务器文件夹中创建一个文件
-
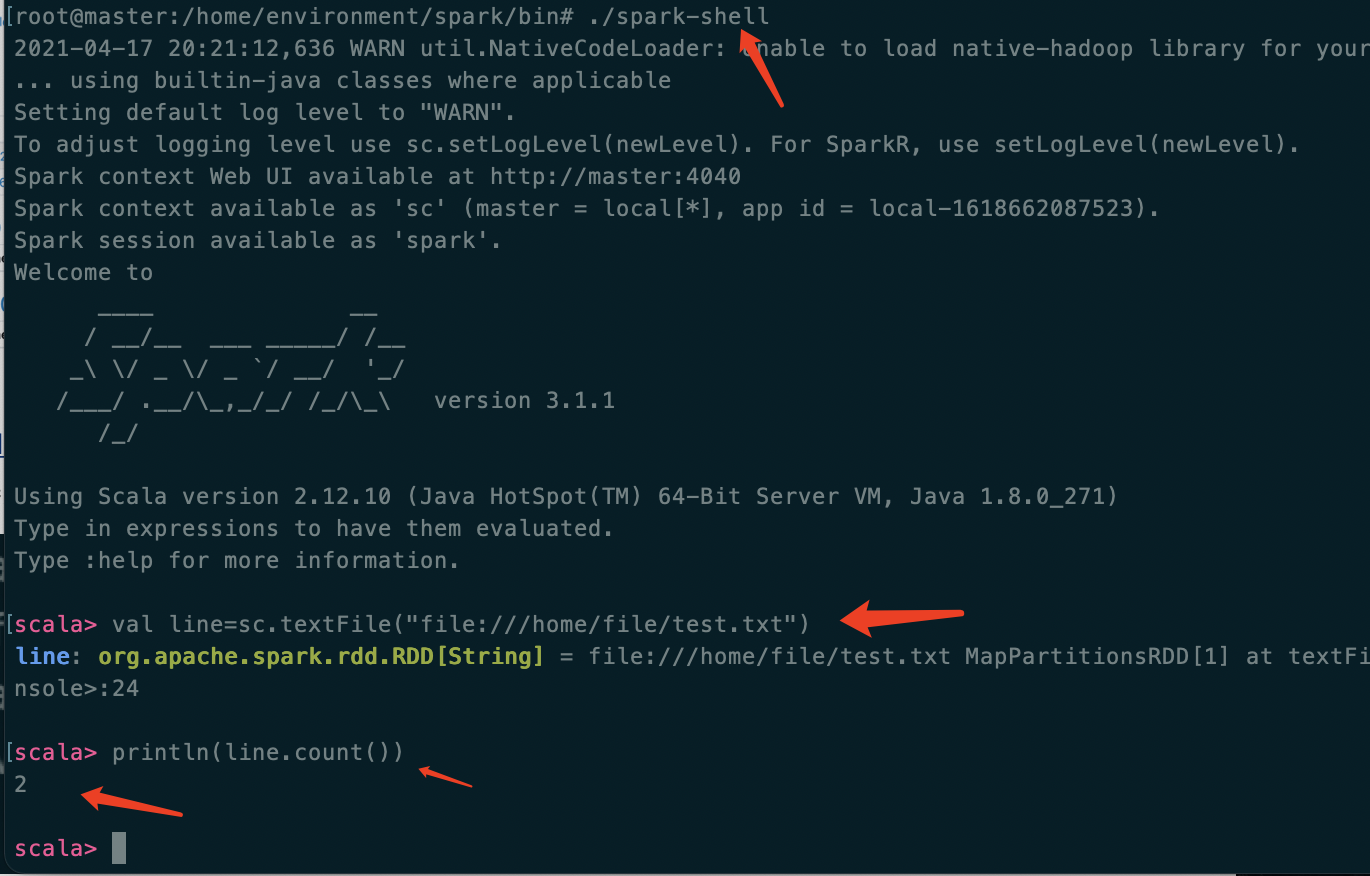
在 spark 的安装目录的 /home/environment/spark/bin 目录中执行 ./spark-shell 进入客户端
执行读取服务器文件下的目录,打印出文件中的行数,使用 :quit 退出
-
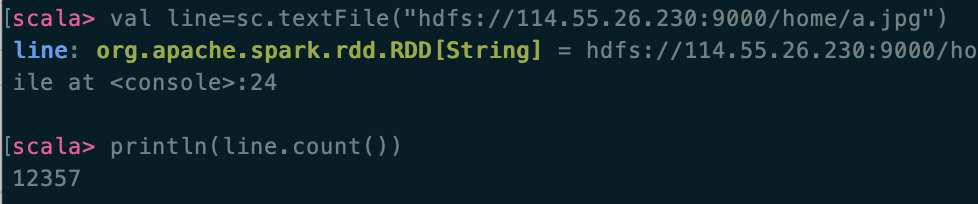
读取hdfs文件系统中的文件 hdfs://192.168.1.106:9000/home/a.jpg (这里以读取图片为例)

七、搭建高可用的zookeeper+hadoop服务器
各个节点中安装目录需要相同!!!
安装
https://blog.csdn.net/qq_42711214/article/details/84109404
https://blog.csdn.net/dzh1125641239/article/details/90674170
https://blog.csdn.net/qq_26907251/article/details/78813798
这里搭建的为阿里上的五台服务器,一主一备三集群(master主,slave1从,slave2,slave3,slave4集群节点),使用的是阿里云相同区域下的内网ip
cat /etc/hosts
172.16.232.76 master
172.16.64.220 slave1
172.16.64.221 slave2
172.16.64.222 slave3
172.16.184.32 slave4
各个节点之间免密登录
配置
在 home 目录下创建 hadoopData 目录
大部分配置与上面的hdfs配置一样,其中 core-site.xml 和 hdfs-site.xml 和 start-dfs.sh 不一样
workers内网
172.16.64.221
172.16.64.222
172.16.184.32
start-dfs.sh 和 stop-dfs.sh 增加HDFS_JOURNALNODE_USER和HDFS_ZKFC_USER
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://masters</value>
<description>HDFS 的 URI,文件系统://namenode标识:端口</description>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoopData</value>
<description>namenode 上传到 hadoop 的临时文件夹</description>
</property>
<!-- 指定ZooKeeper集群的地址和端口。注意,数量一定是奇数,且不少于三个节点-->
<property>
<name>ha.zookeeper.quorum</name>
<value>172.16.64.221:2181,172.16.64.222:2181,172.16.184.32:2181</value>
</property>
hdfs-site.xml
<!-- hdfs保存namenode当前数据的路径,默认值需要配环境变量,建议使用自己创建的路径,方便管理-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoopData/dfs/name</value>
<description>datanode 上存储 hdfs 名字空间元数据</description>
</property>
<!-- hdfs保存datanode当前数据的路径,默认值需要配环境变量,建议使用自己创建的路径,方便管理-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoopData/dfs/data</value>
<description>datanode 上数据块的物理存储位置</description>
</property>
<!-- hdfs存储数据的副本数量(避免一台宕机),可以不设置,默认值是3 -->
<property>
<name>dfs.replication</name>
<value>3</value>
<description>副本个数,默认配置是 3,小于两台主机的数量</description>
</property>
<!-- 指定 hdfs 的 nameservices 为 master,和 core-site.xml 文件中的设置保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>masters</value>
</property>
<!-- master 下面有两个 namenode 节点,分别是 h1 和 h2 (名称可自定义) -->
<property>
<name>dfs.ha.namenodes.masters</name>
<value>h1,h2</value>
</property>
<!-- 指定 h1 节点的 rpc 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.masters.h1</name>
<value>172.16.232.76:9000</value>
</property>
<!-- 指定 h1 节点的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.masters.h1</name>
<value>172.16.232.76:9870</value>
</property>
<!-- 指定 h2 节点的 rpc 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.masters.h2</name>
<value>172.16.64.220:9000</value>
</property>
<!-- 指定 h2 节点的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.masters.h2</name>
<value>172.16.64.220:9870</value>
</property>
<!-- 指定 NameNode 元数据在 JournalNode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://172.16.64.221:8485;172.16.64.222:8485;172.16.184.32:8485/masters</value>
</property>
<!-- 指定 JournalNode 在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoopData/journaldata</value>
</property>
<!-- 开启 NameNode 失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方 -->
<property>
<name>dfs.client.failover.proxy.provider.masters</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,每个机制占用一行 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用 sshfence 隔离机制时需要 ssh 免密码 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置 sshfence 隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!-- 一旦需要NameNode切换,使用ssh方式进行操作 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
启动
-
配置好相关的信息后首先启动三个集群服务器(salve2,3,4)上的 zookeeper 服务器 具体相关的配置参考 zookeeper 配置,使用的是外网的 ip,下面为zookeeper的配置
server.1=112.124.9.194:2888:3888 server.2=121.40.249.161:2888:3888 server.3=121.41.215.127:2888:3888 admin.serverPort=8081 quorumListenOnAllIPs=true
-
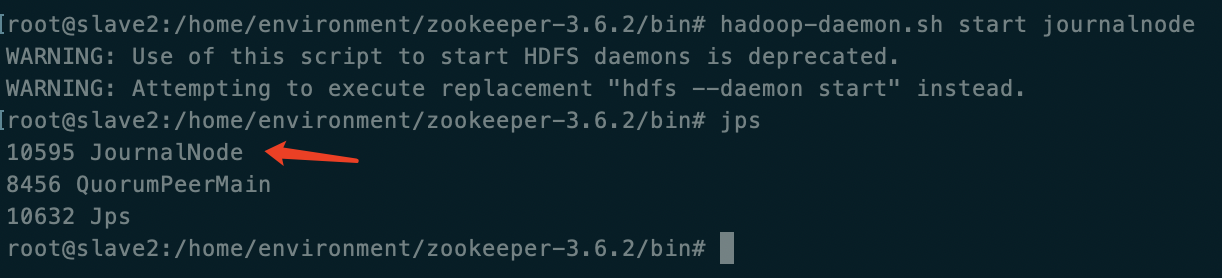
启动三个集群服务器(salve2,3,4)的 journalnode
使用命令
hadoop-daemon.sh start journalnode警告处理因为为3.0版本,改为
hdfs --daemon start journalnodehttps://blog.csdn.net/leanaoo/article/details/83279235
http://wenda.chinahadoop.cn/question/2847
journalnode是为了同步NameNode的操作,与DataNode的个数无关,这里这是把journalnode搭建在DataNode中
三个服务器节点上都出现则成功
-
主 NameNode(master) 上执行
hdfs namenode -format将 /home/hadoopData 下的 dfs 文件 scp 到 slave1 的相同目录中,一般自动生成
-
在主 NameNode(master) 中执行
hdfs zkfc -formatZK -
在主 NameNode(master)执行
start-dfs.sh启动集群服务器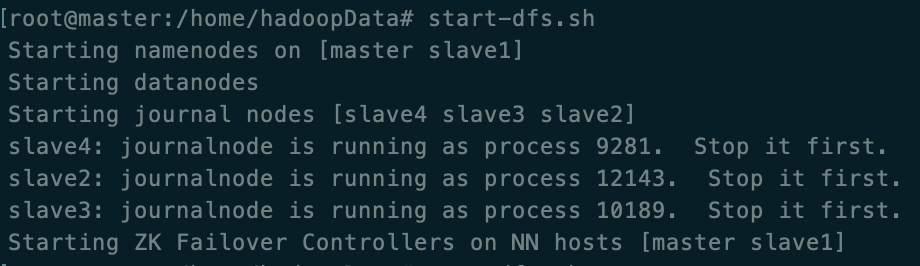
master(jenins.war和jar是别的程序)
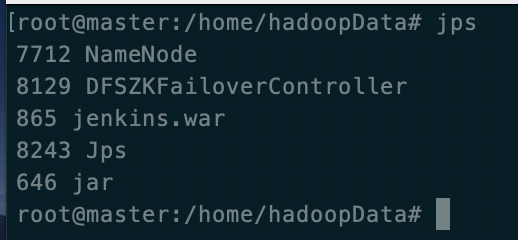
slave1
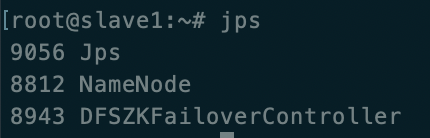
slave2
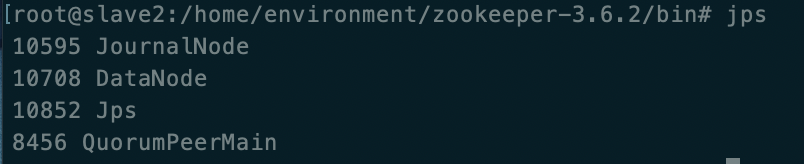
slave3
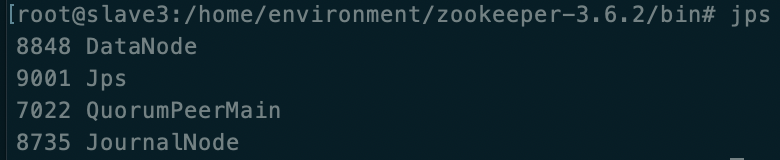
slave4
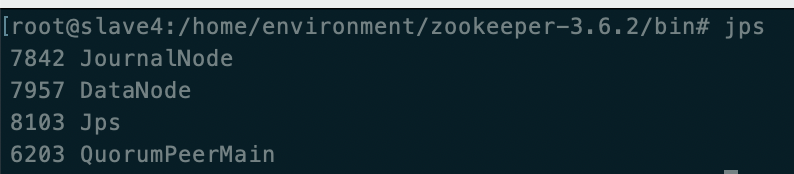
-
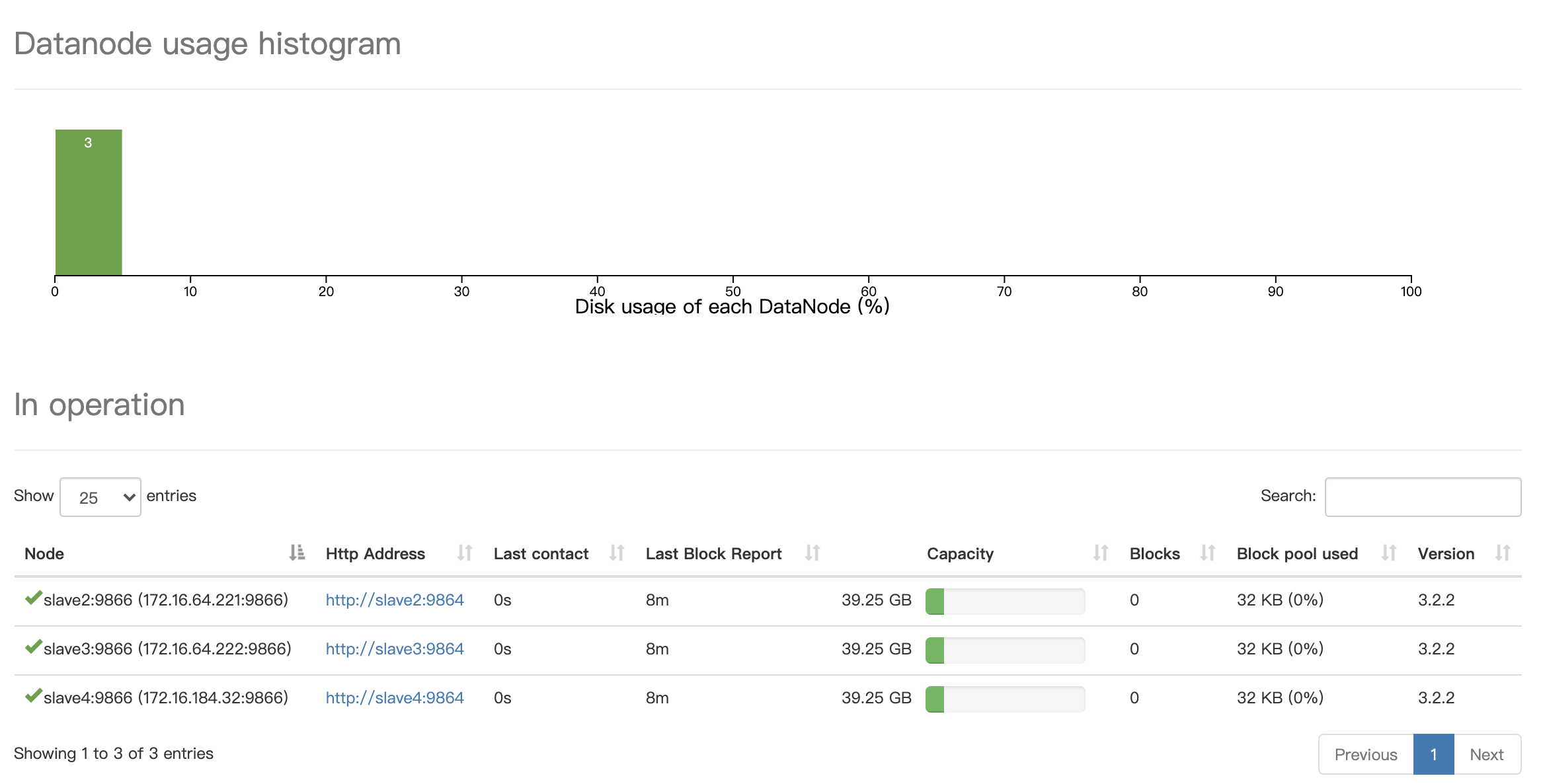
web页面
从master或slave1中查看DataNode节点
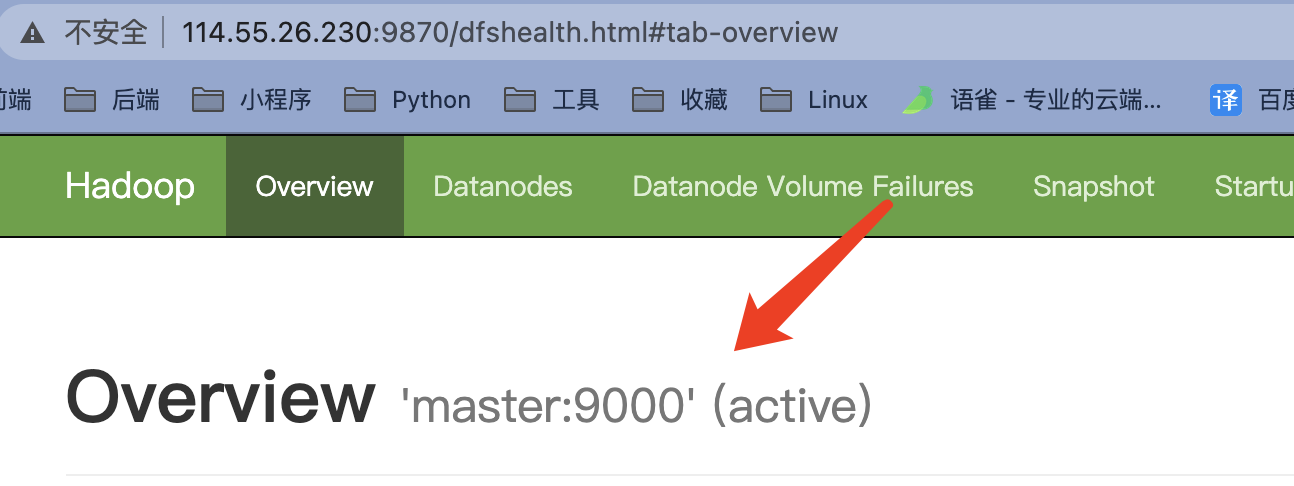
主(初始时为active提供服务状态)
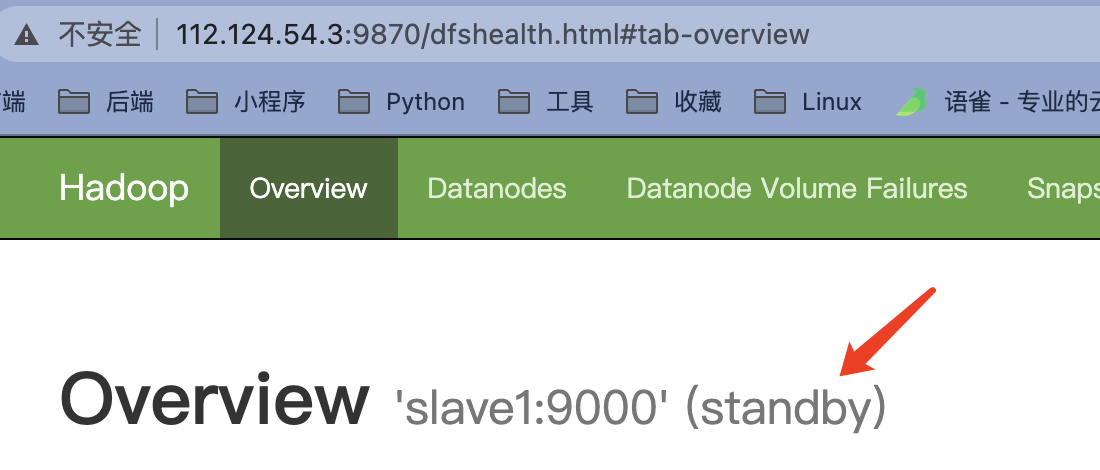
备(初始时为standby休眠状态)
测试
- 停止主(master)中的服务(相当于意外停止等)
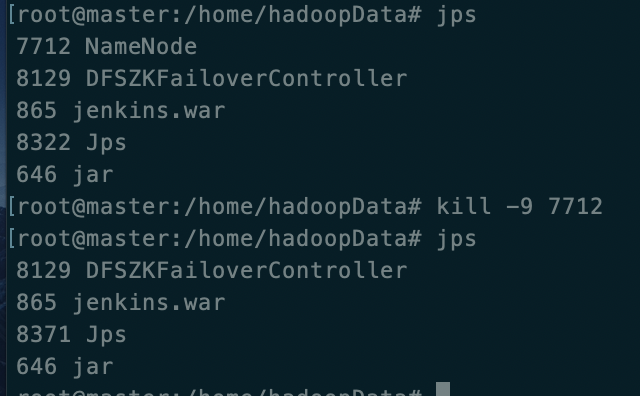
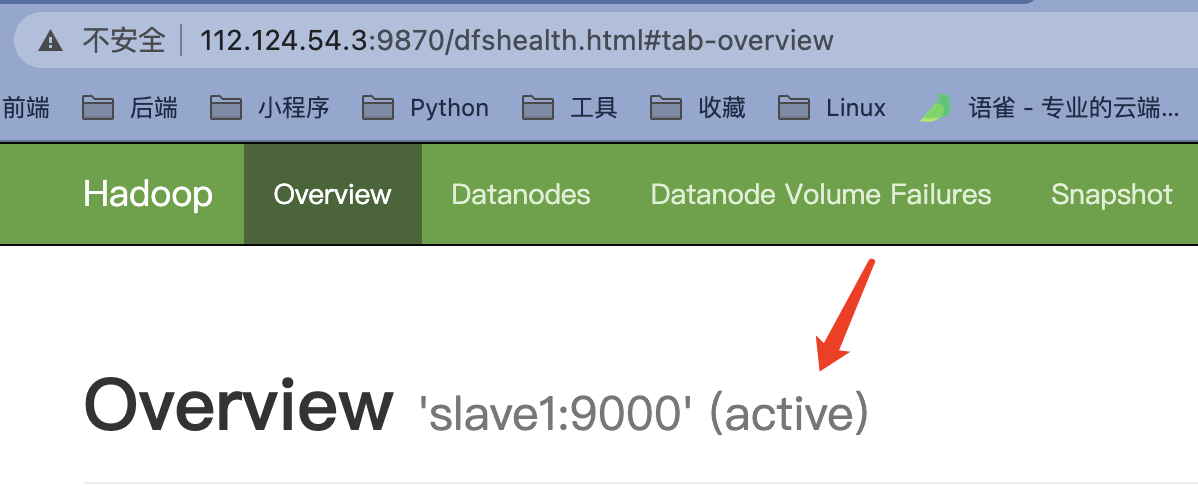
- 之前的 master(主) 页面无法访问, slave1(备) 状态从 standby 转化为 active 成了主
-
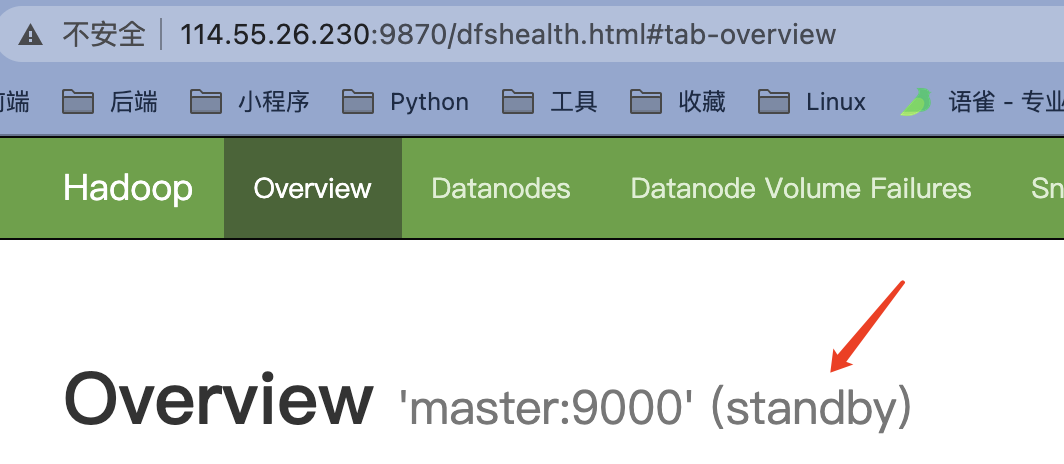
重新启动master(主)已经从active转化为standby 变成了备
hadoop-daemon.sh start namenode**(3.0版本使用 **hdfs --daemon start journalnode)

八、yarn 的高可用
使用这个时需要先启动上面的配置并启动zookeeper+hadoop服务以后
配置Hadoop中的 mapred-site.xml 和 yarn-site.xml
mapred-site.xml
<!-- 必须设置,mapreduce程序使用的资源调度平台,默认值是local,若不改就只能单机运行,不会到集群上了 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 这是3.2以上版本需要增加配置的,不配置运行mapreduce任务可能会有问题,记得使用自己的路径 -->
<property>
<name>mapreduce.application.classpath</name>
<value>
/home/hadoop-3.2.2/etc/hadoop,
/home/hadoop-3.2.2/share/hadoop/common/*,
/home/hadoop-3.2.2/share/hadoop/common/lib/*,
/home/hadoop-3.2.2/share/hadoop/hdfs/*,
/home/hadoop-3.2.2/share/hadoop/hdfs/lib/*,
/home/hadoop-3.2.2/share/hadoop/mapreduce/*,
/home/hadoop-3.2.2/share/hadoop/mapreduce/lib/*,
/home/hadoop-3.2.2/share/hadoop/yarn/*,
/home/hadoop-3.2.2/share/hadoop/yarn/lib/*
</value>
</property>
yarn-site.xml , 使用的是阿里的内网,zookeeper为集群服务器
<!-- Site specific YARN configuration properties -->
<!-- 配置可以在 nodemanager 上运行 mapreduce 程序 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 激活 RM 高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定 RM 的集群 id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>RM_CLUSTER</value>
</property>
<!-- 定义 RM 的节点 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 指定 RM1 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>172.16.232.76</value>
</property>
<!-- 指定 RM2 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>172.16.64.220</value>
</property>
<!-- 激活 RM 自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置 RM 状态信息存储方式,有 MemStore 和 ZKStore -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 配置为 zookeeper 存储时,指定 zookeeper 集群的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>172.16.64.221:2181,172.16.64.222:2181,172.16.184.32:2181</value>
</property>
-
将master(主)上的配置文件同步到 slave1中
-
在master(主)中启动
start-yarn.sh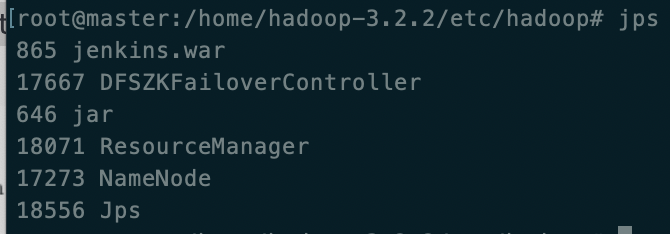
-
看下slave1中有没有ResourceManager,没有则使用
yarn-daemon.sh start resourcemanager启动3.0版本以上使用
yarn --daemon start resourcemanager -
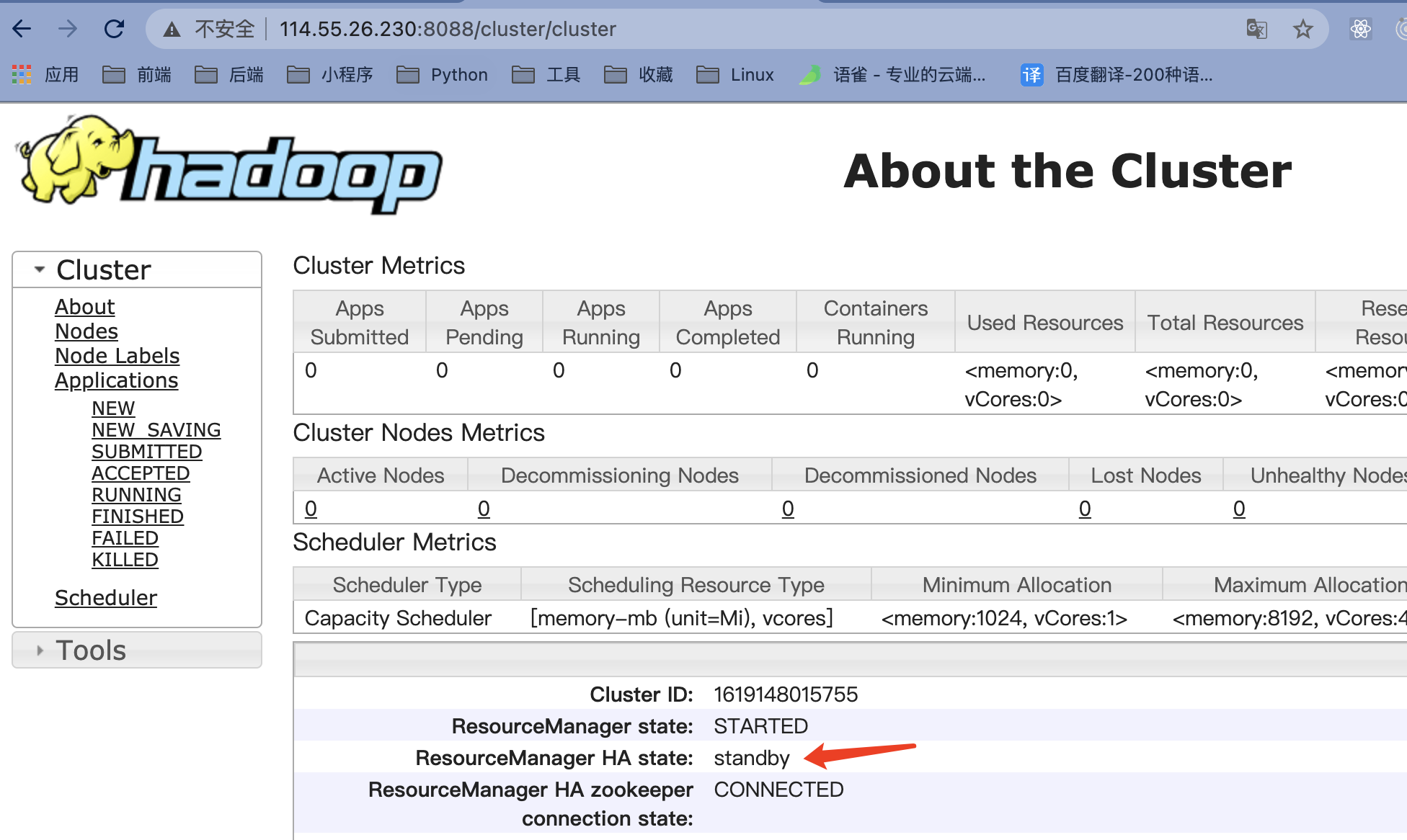
查看maste(主)和slave1(备)的8088端口
主(master)
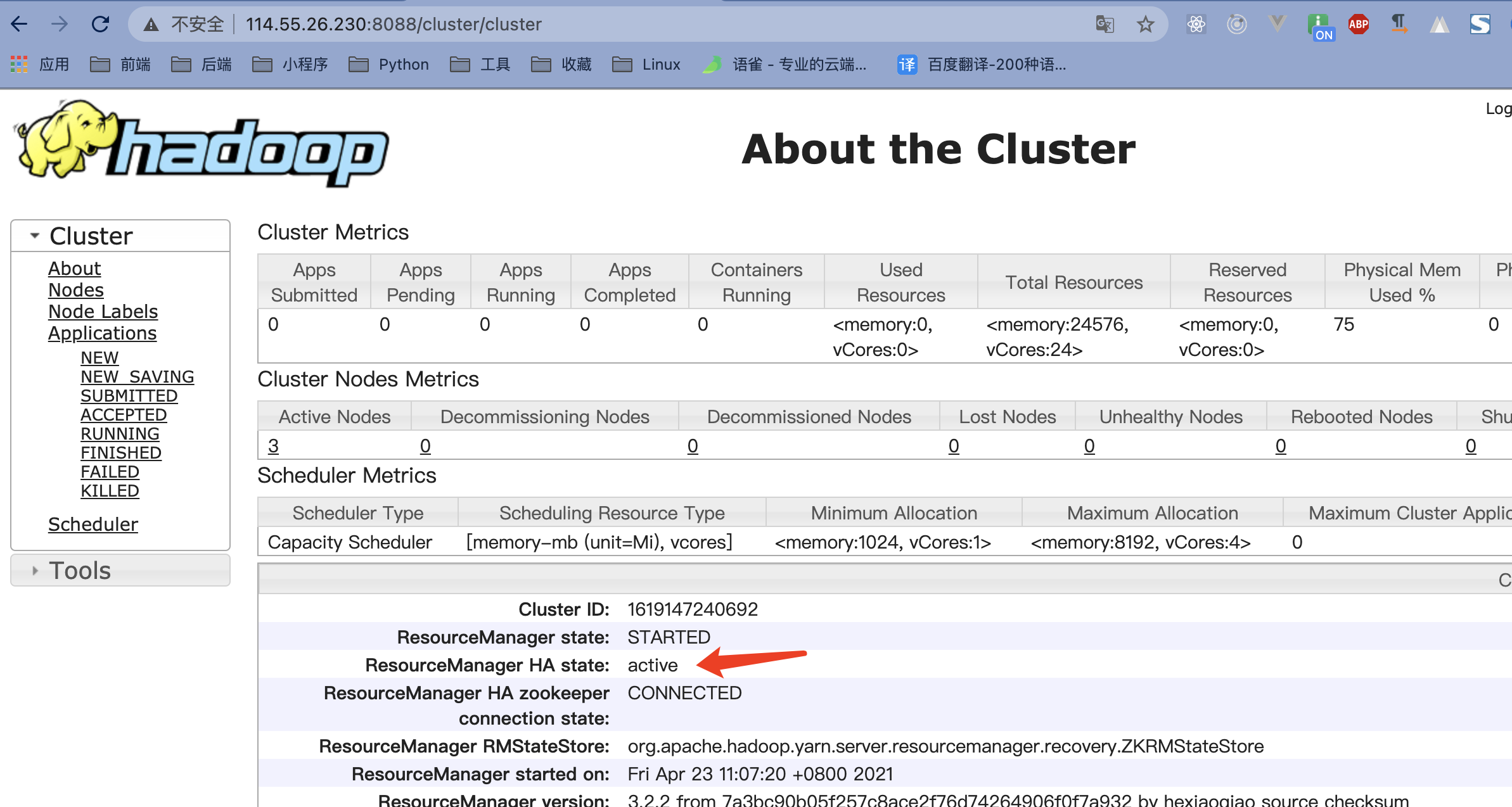
备(slave1)
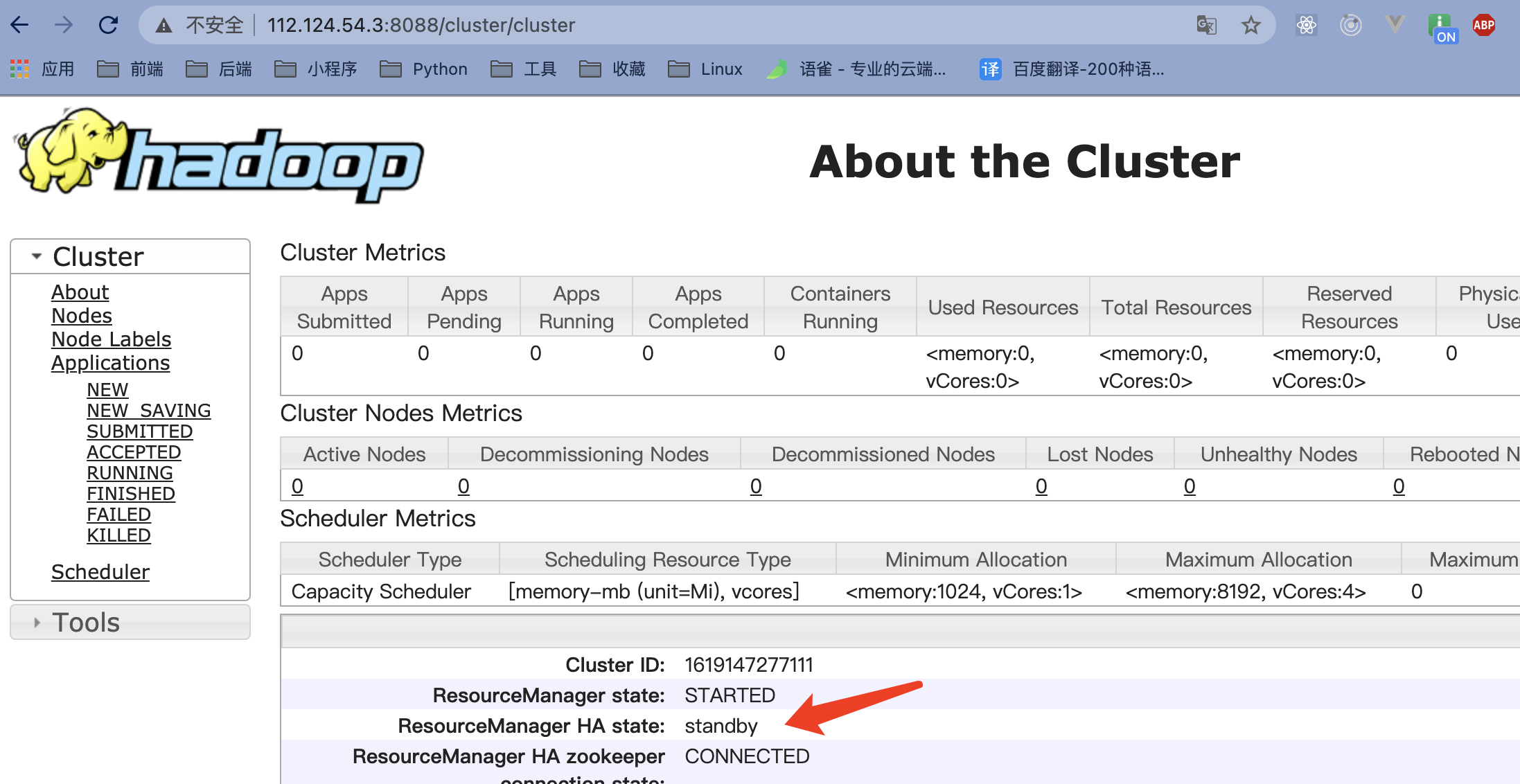
-
停止备后
主(master)页面无法打开,备(slave1)状态变成active 成了主
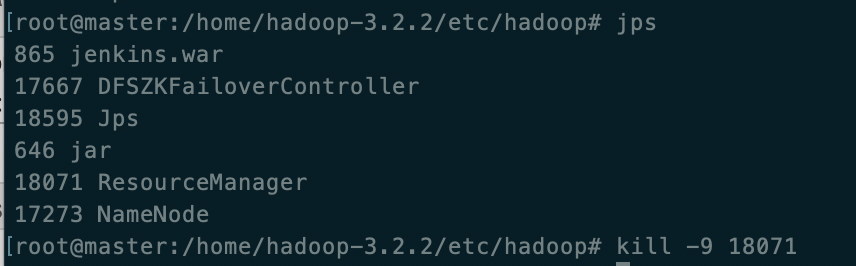
主(master)页面无法打开,备(slave1)状态变成active 成了主
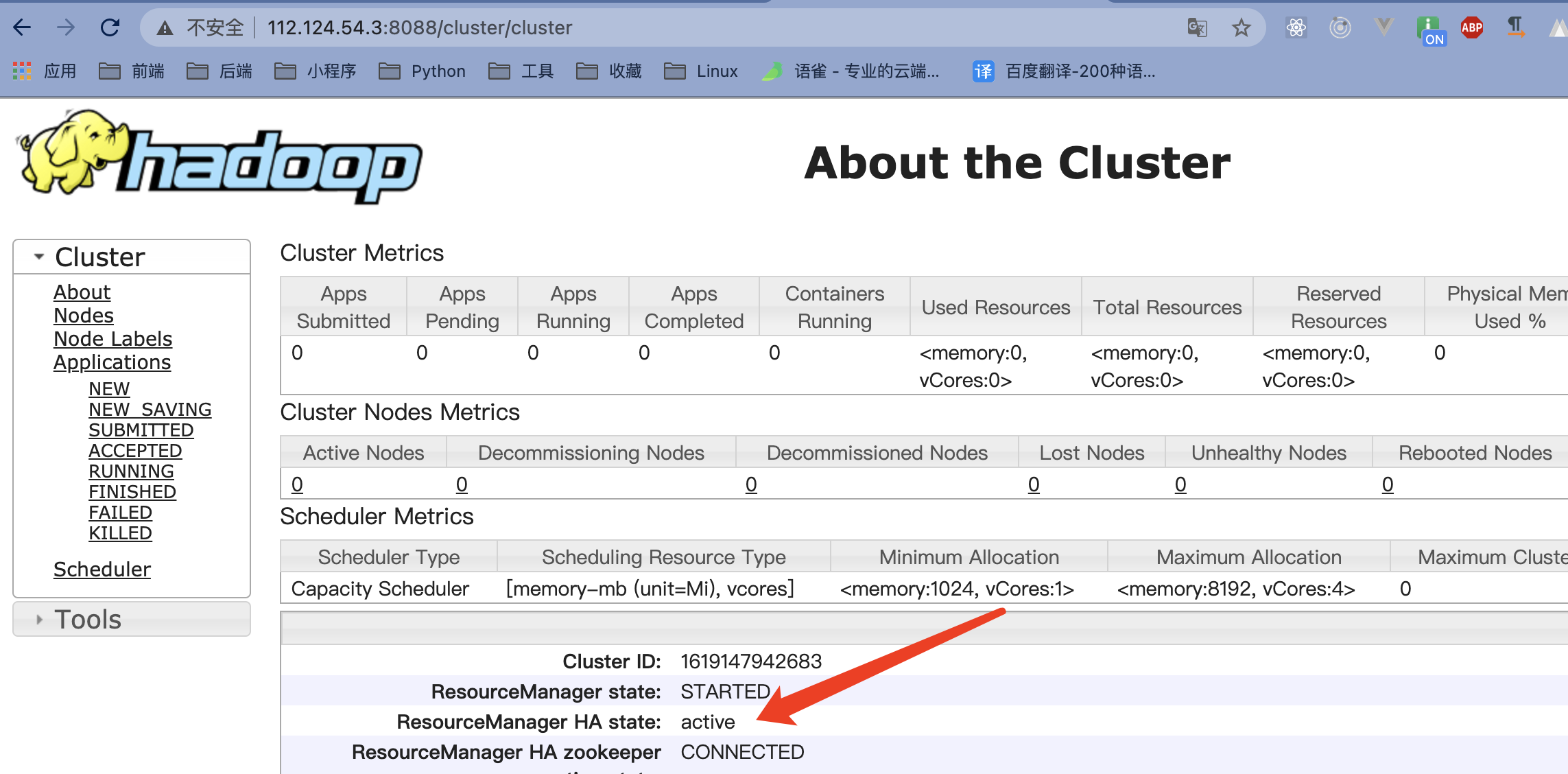
重新启动后,之前主(master)的状态变成变成了standby
九、hbase 的高可用
启动上面的高可用hdfs
修改hbase配置文件 hbase-site.xml 和 regionservers
hbase-site.xml
<!-- 指定 region server 的共享目录,用来持久化 HBase。这里指定的 HDFS 地址是要跟 core-site.xml 里面的 fs.defaultFS 的 HDFS 的 IP 地址或者域名、端口必须一致 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://masters/hbaseData</value>
</property>
<!-- 启用 hbase 分布式模式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- Zookeeper 集群的地址列表,用逗号分割。默认是 localhost,是给伪分布式用的。要修改才能在完全分布式的情况下使用 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>172.16.64.221,172.16.64.222,172.16.184.32</value>
</property>
<!-- 指定数据拷贝 2 份,hdfs 默认是 3 份 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 指定 hbase 的 master -->
<property>
<name>hbase.master</name>
<value>h1</value>
</property>
<!-- 本地文件系统tmp目录 -->
<property>
<name>hbase.tmp.dir</name>
<value>/home/hadoopData/hbasetmp</value>
</property>
<!-- 使用本地文件系统设置为false,使用hdfs设置为true -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
regionservers
172.16.64.221
172.16.64.222
172.16.184.32
-
在将配置好的配置文件拷贝到slave1(备)上,并配置hbase的环境变量
-
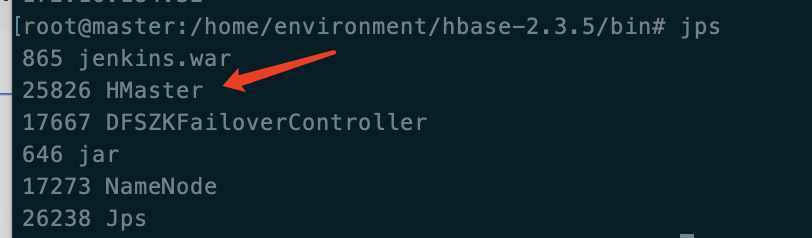
在master(主)上启动hbase,start-hbase.sh 在bin目录下启动,或者添加环境变量中直接使用
-
在slave1(备)中执行 hbase-daemon.sh start master (3.0以上使用 hdfs --daemon start master)或 (start-hbase.sh)
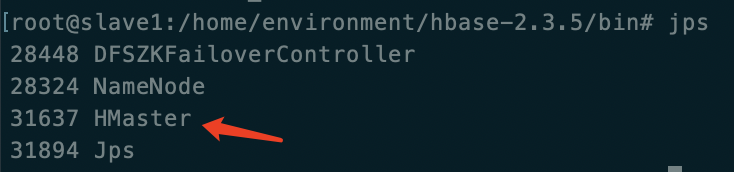
master(主)
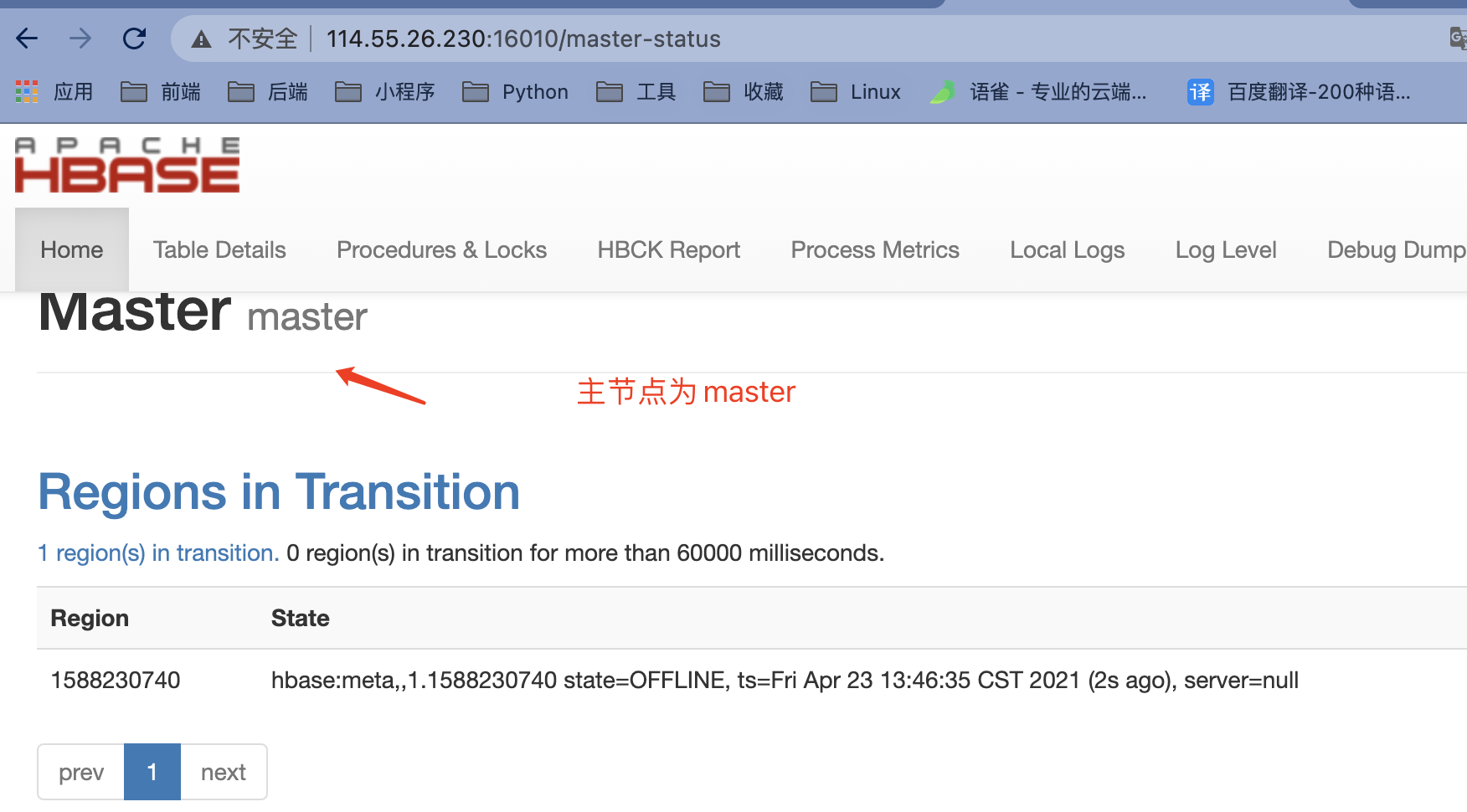
slave1(备)
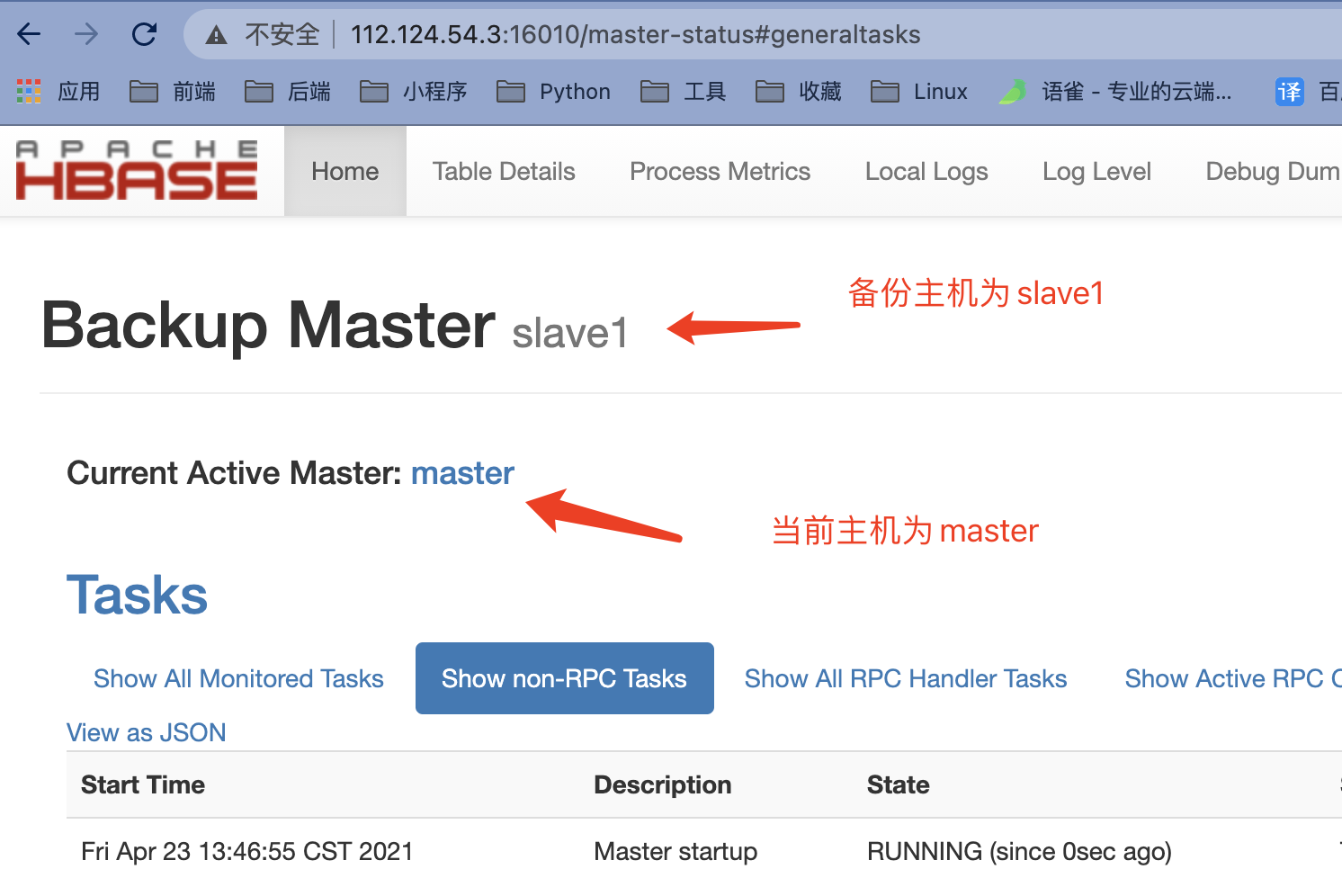
测试
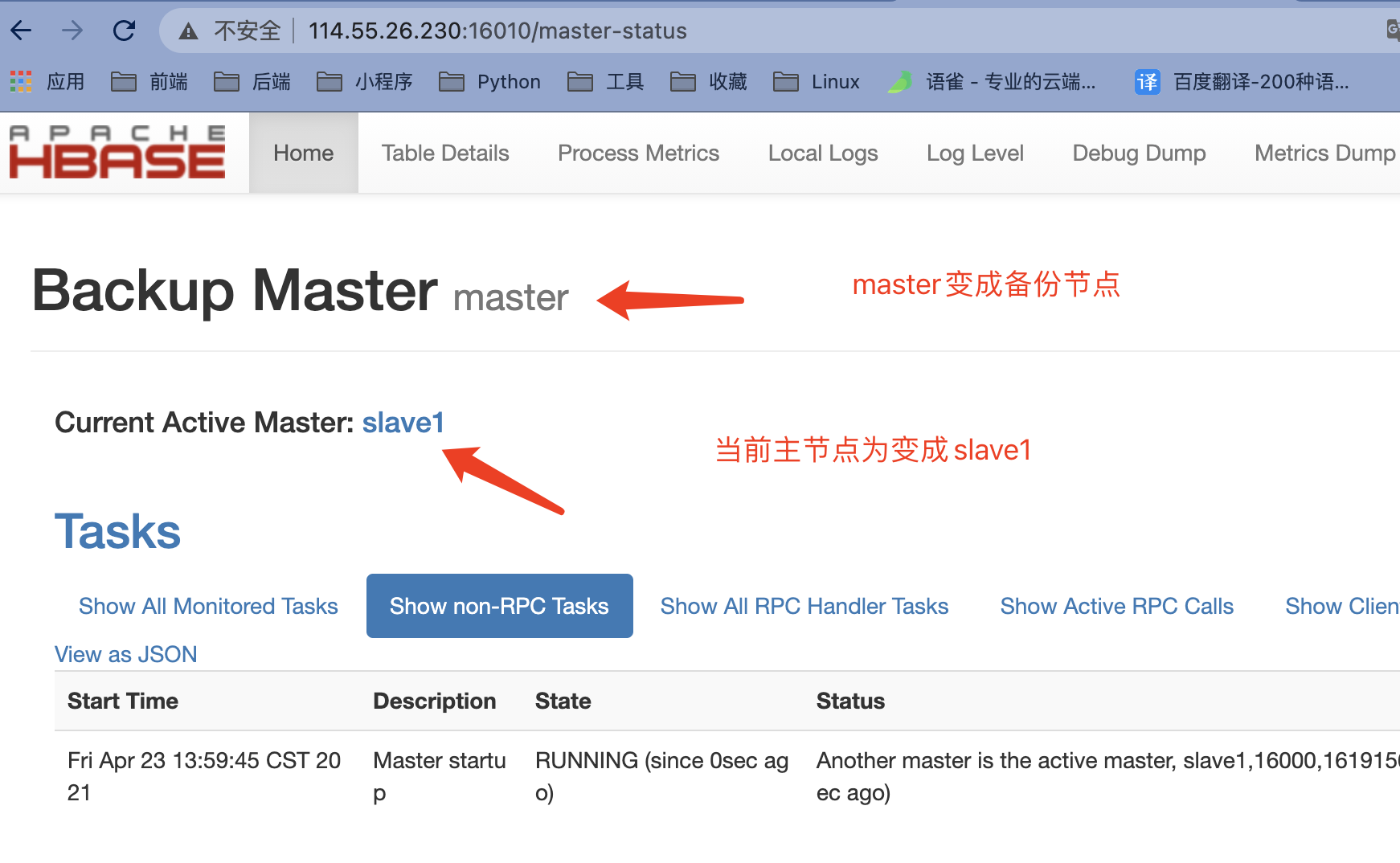
停止(kill掉HMaster或者是停止掉stop-hbase.sh)master(主)后重新启动(start-hbase.sh)master(主)
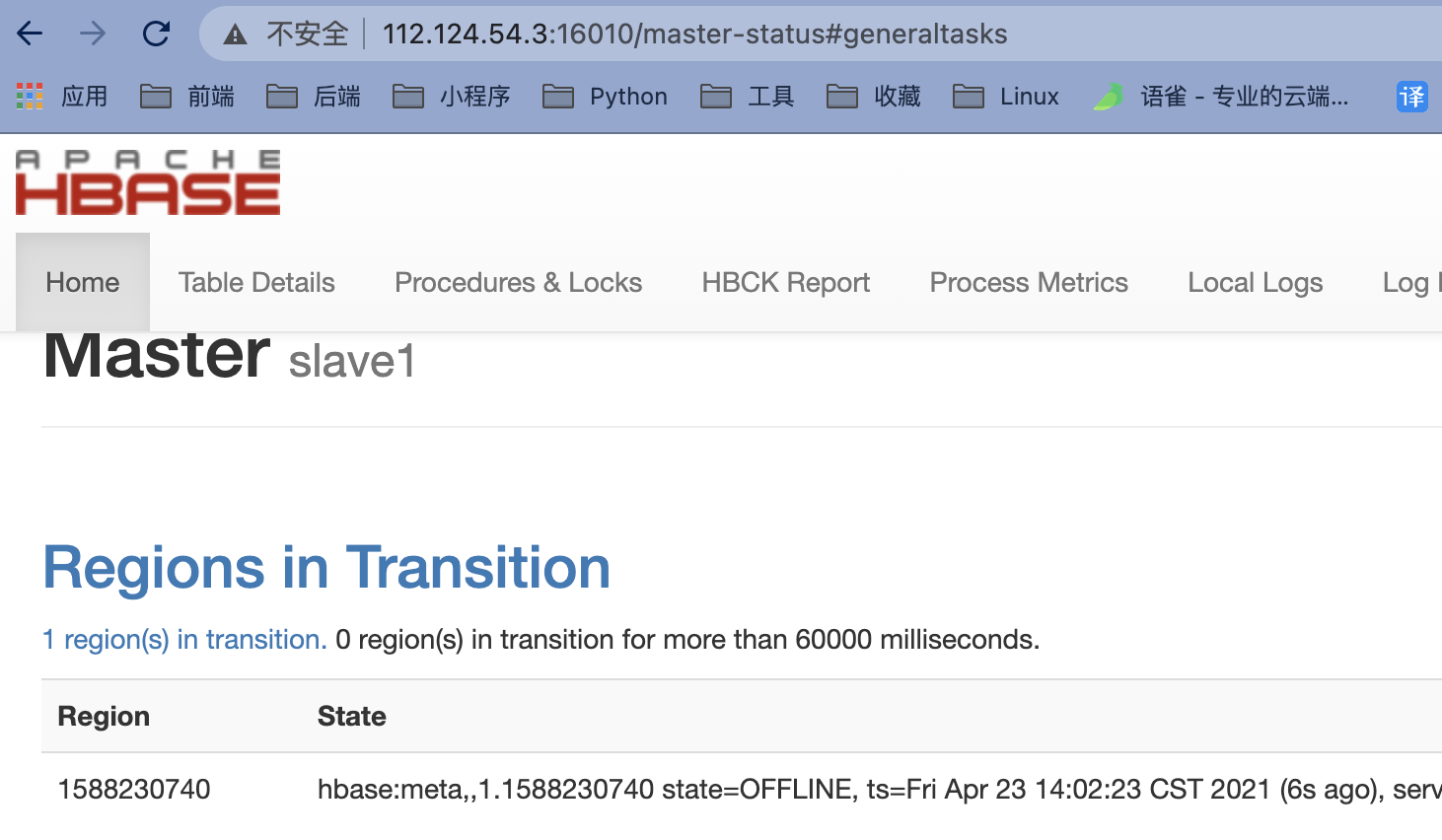
当DataNode的其中一个节点突然宕机
默认超时时间为10分钟+30秒
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认的大小为3秒。
hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒
heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒
<property>
<name>heartbeat.recheck.interval</name>
<value>5000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
https://blog.csdn.net/hsg77/article/details/81030745
https://blog.csdn.net/qq_42038319/article/details/111212791
-
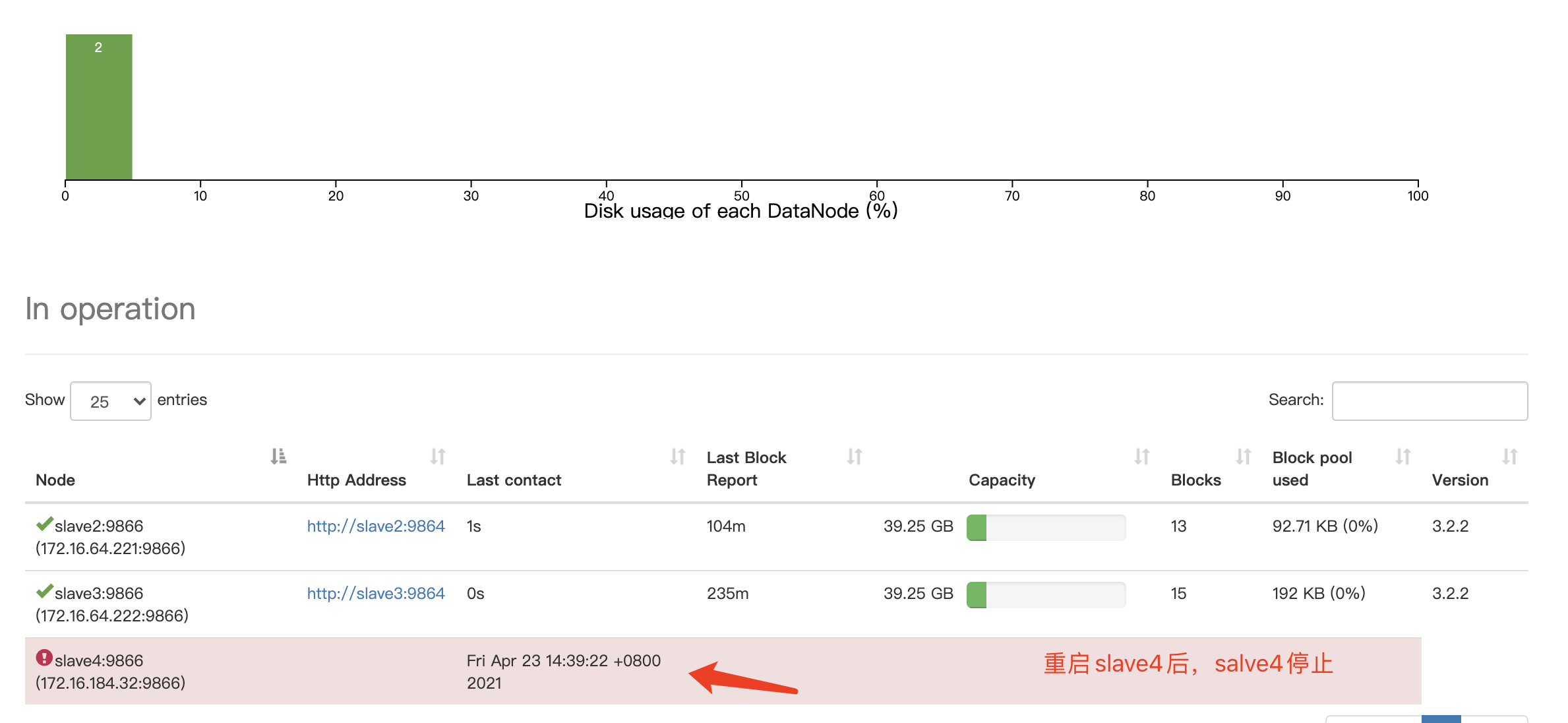
zookeeper将重新选举(如果宕机掉了主节点)
-
启动zookeeper(bin目录下执行
./zkServer.sh start)
-
启动journalnode(
hadoop-daemon.sh start journalnode或hdfs --daemon start journalnode)
-
启动datanode(
hadoop-daemon.sh start datanode或hdfs --daemon start datanode)
-
正常重启恢复
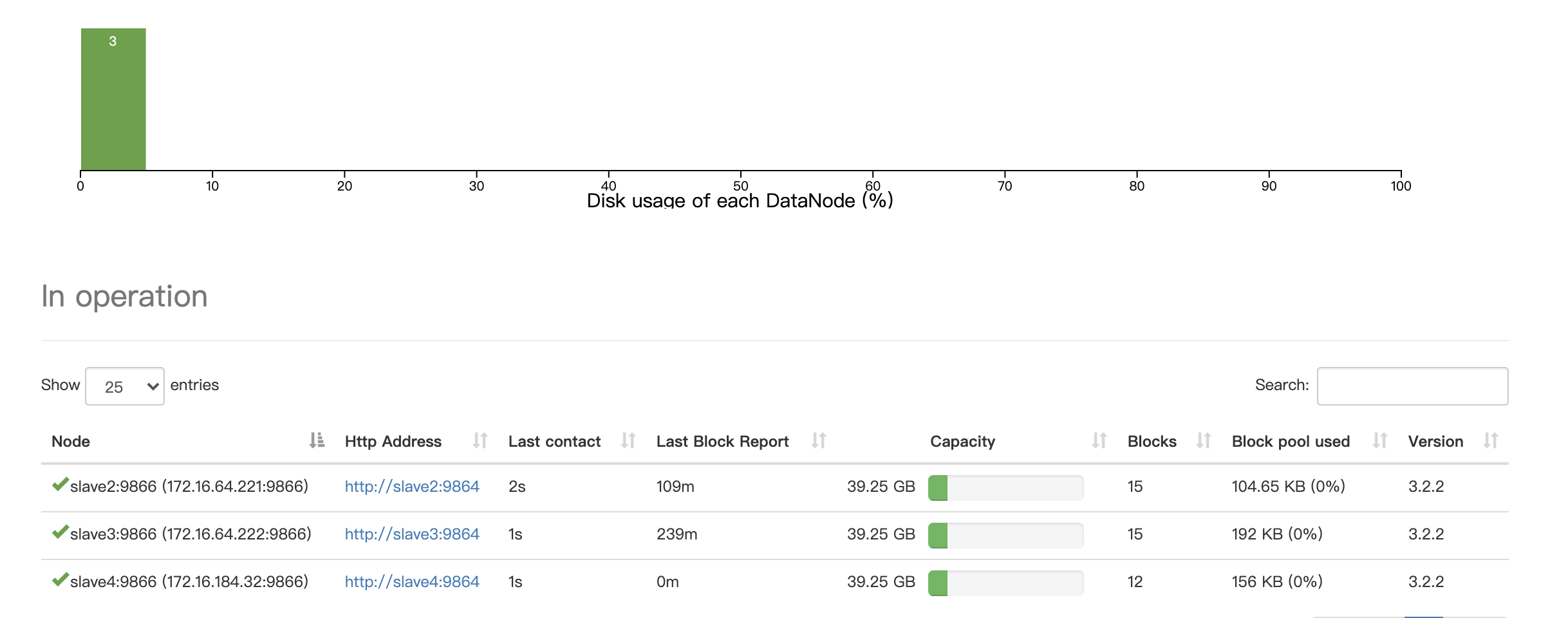
当NameNode的其中一个节点突然宕机
启动
hadoop-daemon.sh start namenode 或 hdfs --daemon start namenode
hadoop-daemon.sh start zkfc 或 hdfs --daemon start zkfc
十、命令、SpringBoot操作
出现 Call From master to localhost:9000 failed on connection exception…的错误:
修改 /hadoop/etc/hadoop/hdfs.site.xml
找到dfs.permissions属性修改为false,关闭检查权限(默认为true)
hadoop fs -setrep -R 2 /home/a.jpg : 修改文件的副本数
hadoop fs -rmr dir:删除目录dir
hadoop fs -mkdir dir:创建目录dir
hadoop fs -ls / :查看根目录文件
hdfs dfs -copyFromLocal /local/data /hdfs/data:将本地文件上传到 hdfs上(原路径只能是一个文件)
hdfs dfs -put /tmp/ /hdfs/ :和 copyFromLocal 区别是,put 原路径可以是文件夹等
hdfs dfs -chmod -R 777 /home:修改目录权限
hadoop fs -du -s -h:查看文件夹的大小
hdfs+hbase springboot测试代码,关注公众号原棵哈回复hadoop获取

参考网址
https://blog.csdn.net/qq_35246620/article/details/88576800 ↩︎
https://blog.csdn.net/qq_26735495/article/details/108719844 ↩︎
https://blog.csdn.net/long9827/article/details/108637471 ↩︎
https://blog.csdn.net/weixin_40990818/article/details/82086213 ↩︎
https://www.cnblogs.com/rhgaiymm/p/12849869.html ↩︎
https://blog.csdn.net/u011165335/article/details/106303379 ↩︎
https://blog.csdn.net/y12345678904/article/details/109230432 ↩︎
https://www.cnblogs.com/jhxxb/p/10693533.html ↩︎
https://downloads.apache.org/hbase/stable/ ↩︎
https://blog.csdn.net/hll19950830/article/details/79953654 ↩︎
https://blog.csdn.net/xqclll/article/details/53907032 ↩︎
https://blog.csdn.net/m0_37138008/article/details/72843248 ↩︎
http://c.biancheng.net/view/6532.html ↩︎
https://www.scala-lang.org/download/ ↩︎
https://blog.csdn.net/weixin_40782143/article/details/87895553 ↩︎
https://blog.csdn.net/weixin_42001089/article/details/82346367 ↩︎
https://downloads.apache.org/spark/spark-3.1.1/spark-3.1.1-bin-hadoop3.2.tgz ↩︎
https://www.jianshu.com/p/594be19e29c3 ↩︎
http://dblab.xmu.edu.cn/blog/2081-2/ ↩︎
https://blog.csdn.net/qq_42711214/article/details/84109404 ↩︎
https://blog.csdn.net/dzh1125641239/article/details/90674170 ↩︎
https://blog.csdn.net/qq_26907251/article/details/78813798 ↩︎
https://blog.csdn.net/leanaoo/article/details/83279235 ↩︎
http://wenda.chinahadoop.cn/question/2847 ↩︎
https://www.cnblogs.com/xd502djj/p/4645298.html ↩︎
https://blog.csdn.net/hsg77/article/details/81030745 ↩︎
https://blog.csdn.net/qq_42038319/article/details/111212791 ↩︎
https://blog.csdn.net/weixin_40990818/article/details/82086213 ↩︎
















 8355
8355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











