






运行YOLOv8
- 官网离线下载或Ubuntu命令行输入方式下载
- 准备好环境(本人是在服务器创建了yolov8_env)
- 安装依赖包
- 官方包ultralytics,在环境下输入pip install ultralytics(安装后可以输入yolo,命令可用则安装成功;卸载包pip uninstall ultralytics)
- 安装第三方模块,在文件所在目录下输入pip install -i requirements.txt
- 进入./ultralytics目录下(下载yolov8n.pt/yolov8s.pt…到此目录下,因为此处存放的是主要代码)
预测:
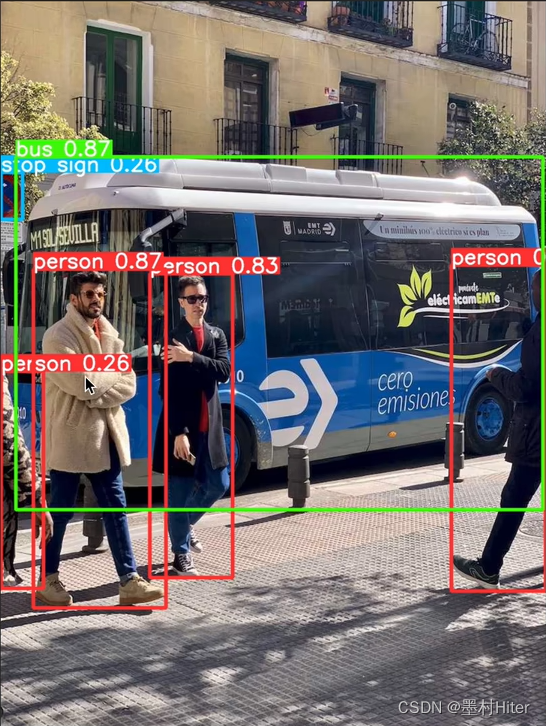
yolo predict model=yolov8n.pt source=assets/bus.jpg
检测结果存放在同级目录run/detect/predict*/bus.jpg(*代表系统自动编码的文件夹序列号)
训练:
yolo train data=coco128.yaml model=yolov8n.pt epochs=3 lr0=0.01
报错01

查看torch版本: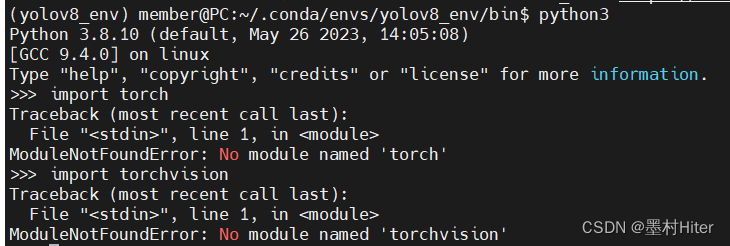
显示找不到torch,但conda list却显示有torch2.0.1版本,而且本地Pycharm在导包时也未报错。
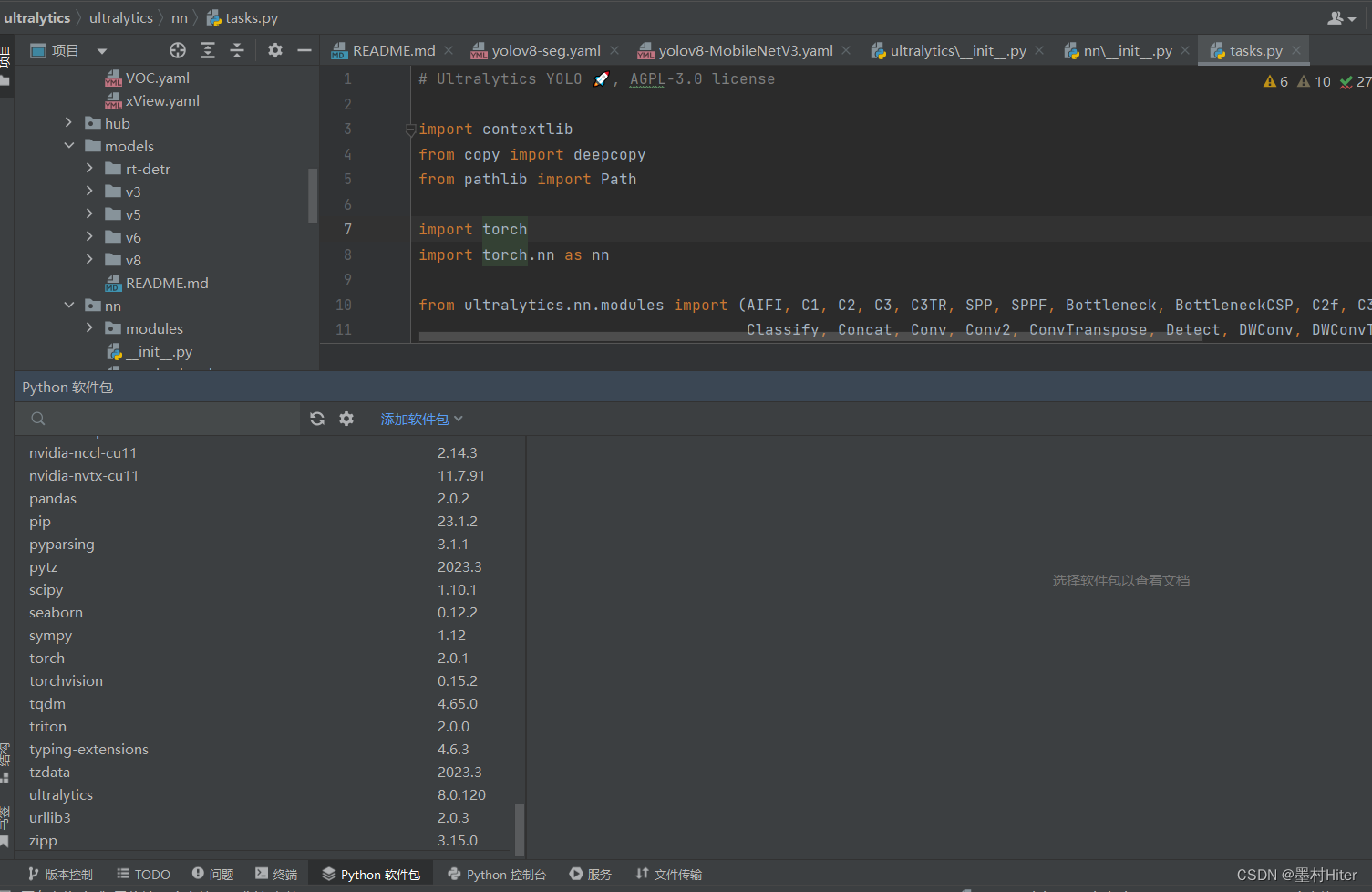
感觉这是一个非常新鲜的问题!我又使用MobaXterm远程登录服务器,利用命令行输入查看torch版本,同Pycharm终端显示相同,均找不到torch模块。
而且,我还有一个问题,如果训练时GET不到engine,那么预测时是怎么GET到的?它GET的是CPU吗?一切都只是我的猜测!

我又查看了CUDA版本(11.1 使用命令nvcc -V),gcc版本(9.4.0 使用命令gcc --versiion)。理论上来说,这么低版本的CUDA是无法安装2.0.1版本torch的才对!
为什么我会有这个判断!因为我很惨痛地耗费了一个下午安装CUDA,得到的经验教训!
教训一:安装torch首先要到官网查看版本,因为如果事先安装了高版本的CUDA,你会发现没有对应版本的torch可以下载,可以理解为torch还没有支持高版本CUDA。(别问我怎么知道!)
教训二:CUDA版本有默认gcc版本,所以Ubuntu系统下gcc版本过高,安装CUDA都会出现问题。
教训三:如果你不想搞清楚这些问题,推荐使用CUDA11.3版本和对应版本的cudnn和gcc。
回到现在的问题,我理解是conda list显示的并不是~/.conda/envs/yolov8_env/bin/python3所在环境下python3依赖包,也就是说我并没有配置好torch包。
因此首先,我需要尝试卸载torch和重安装torch!
1)torch2.0.1的主要更新功能:提升了模型运行速度的能力(针对大模型,新增了torch.compile能力),号称可以向下兼容,但很多人都出现GET不到engine的情况,具体原因还没搞清楚。
2)卸载torch2.0.1或删掉虚拟环境(删虚拟环境需要重新配置Pycharm解释器,但卸载torch有时候不干净,安装新的torch会有各种冲突,很麻烦!)
最终,我选择了卸载环境!
①回到base环境
②conda remove -n yolov8_env --all
③conda create -n torch1.8.0 python=3.8
④官网查看指令:
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge
(有同学建议将conda改为pip安装,别问我为什么,有什么区别,我TM也不懂!谁来救救我!)
在删除的时候,我有一个意外发现!
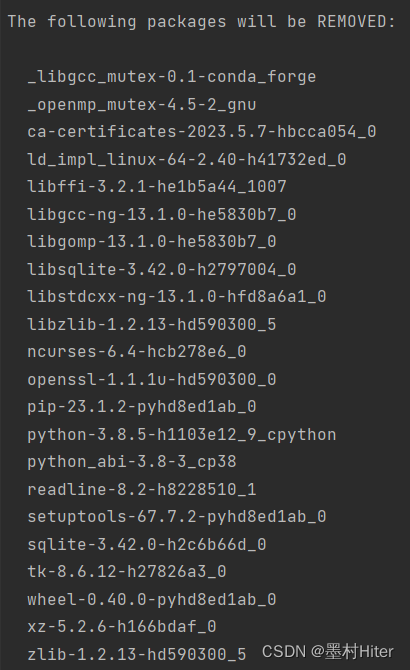
看到没有,就没有安装torch!所以,就不存在删除torch重装会比较麻烦的问题,直接安装torch!
使用conda指令安装,一直在Collecting package metadata卡住!
我偏偏不信这个邪!所以这就是代价了~

然后使用pip安装,结果又报错!是谁说用pip的?出来受死吧~(我后来按要求更新了pip版本,问题依然存在)

果断用conda指令安装,结果报了一个非常常见的错误:

这个问题,我曾经用删除镜像源的方式解决过!但在实验室的服务器,我不敢这么操作!
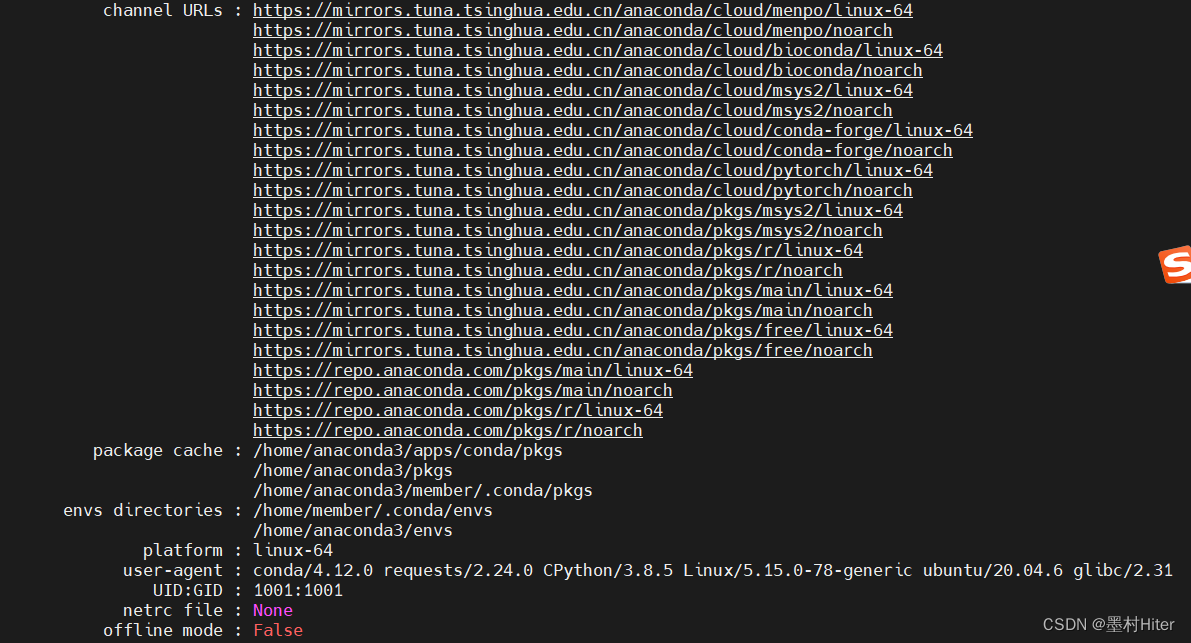 你们看看,这群实验室小比崽子们添加了多少镜像!索性最后冲过去了,安装完成后,查询torch,愣住了!还是不存在torch这个模块!
你们看看,这群实验室小比崽子们添加了多少镜像!索性最后冲过去了,安装完成后,查询torch,愣住了!还是不存在torch这个模块!
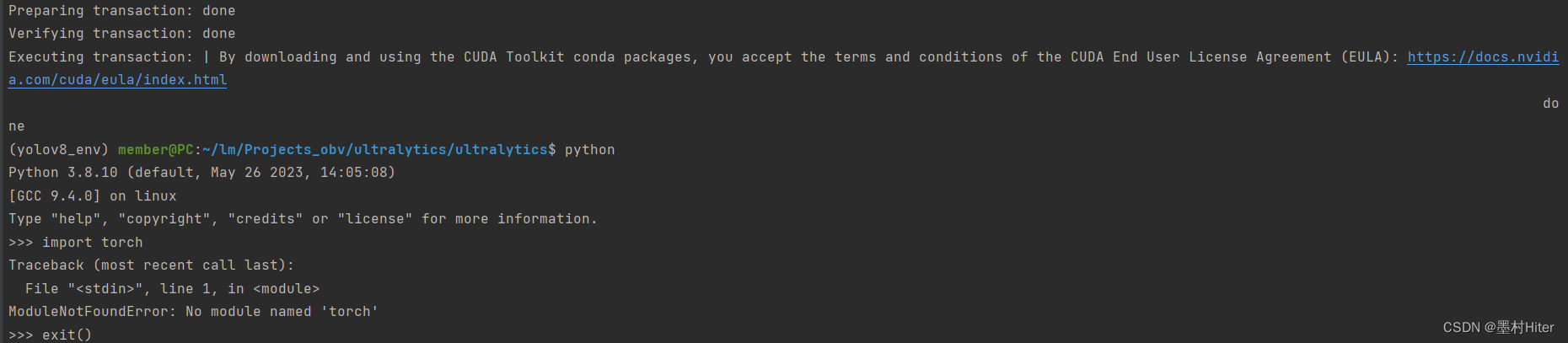
重新执行安装,显示如下:
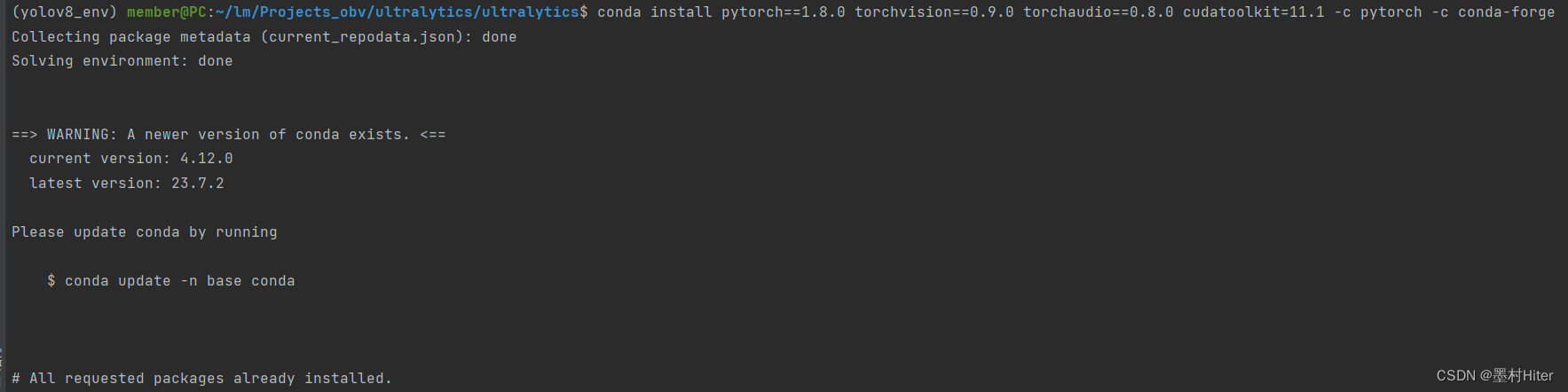
意识说,你要求的包已经安装啦!你的conda包太小啦,提醒你更新一下conda!再有就是cuda新版本有新品哦。我~滚你M!
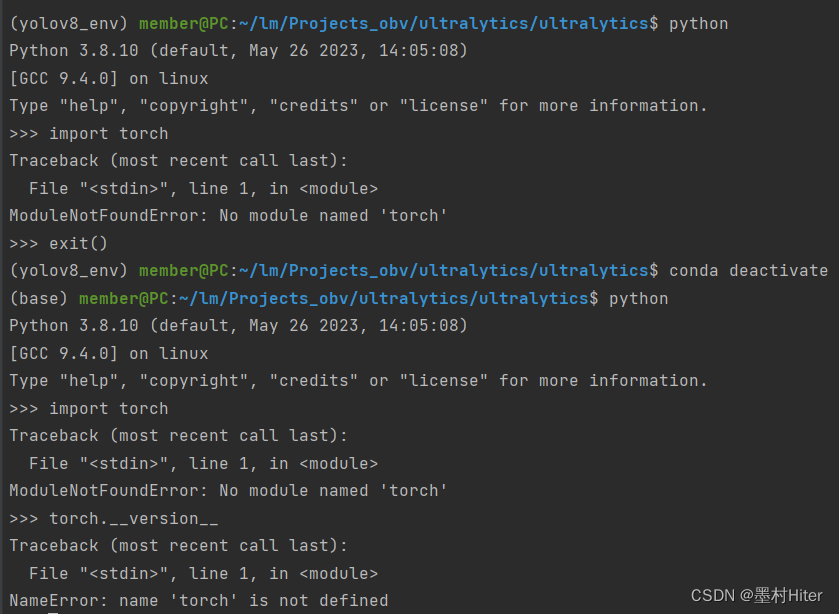
你们看到没有,在base环境下也无法查询和导入torch包!怎么回事呢?
我突然想到requirements文件和官方库ultralytics。是不是torch和相关依赖包,都已经在ultralytics里面了呢?
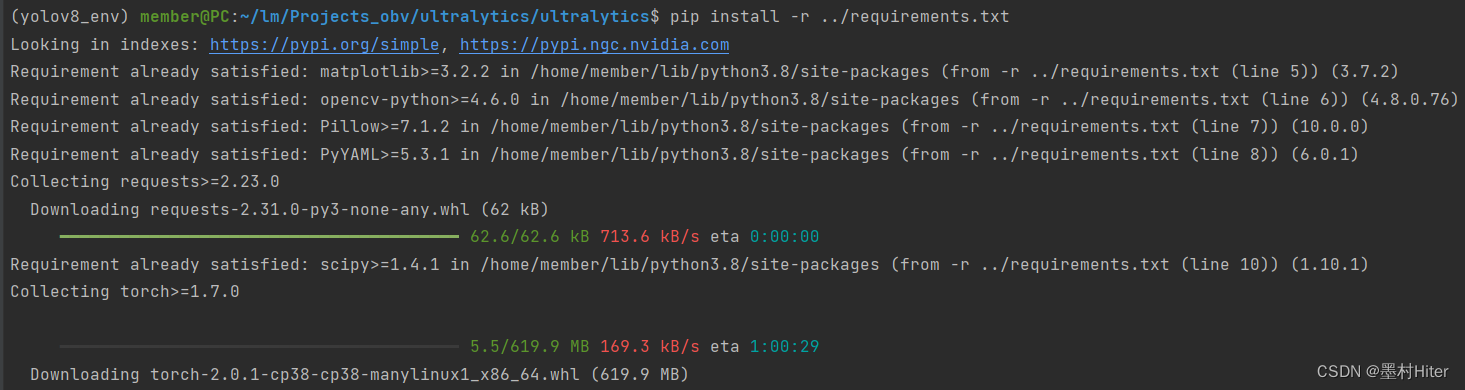
终于!它开始下载了58分钟,简直崩溃!而且等等,为什么又是2.0.1版本(req文档要求torch>=1.7,但你也没必要给我最新版本呐)?因为速度感人,我准备自己安装!怎么办?先前的命令已经不管用了,用req文档速度又很慢!
所以,我在官网上找到了下面这个安装指令:
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html

终于,可以正常且成功安装了!撒花~但没完结,在安装完成后,我还需要安装requirements.txt中的第三方依赖包(因为torch已经安装好了,所以安装时间上能够接受),以及搞明白官方库是怎么回事,都提供了哪些好用的功能。
重新开始学习yolov8
训练:
yolo train data=coco128.yaml model=yolov8n.pt epochs=3 lr0=0.01
报错02

RuntimeError: CUDA out of memory. Tried to allocate 84.00 MiB (GPU 0; 23.69 GiB total capacity; 1.71 GiB already allocated; 13.12 MiB free; 1.84 GiB reserved in total by PyTorch)

报出CUDA内存不足,这个原因我开始并不认可,给大家截图看一下服务器运行内存的情况(后来发现确实是内存不足,但是显存却很足,我很纳闷)。

一般报这种错误的原因:GPU内存不足,无法分配给PyTorch所需的内存空间。网络上给出的解决办法包括一下几种。

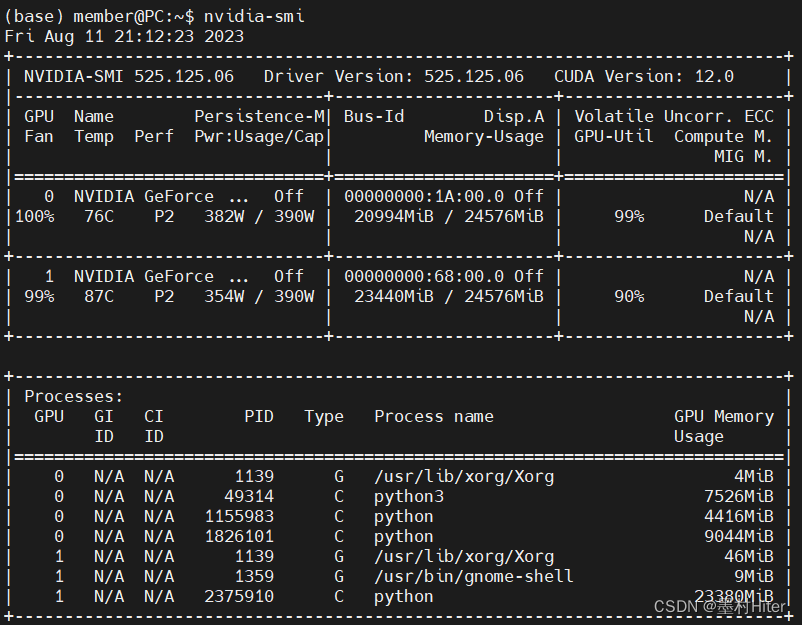
Persistence-M:显卡的持久模式。On-驱动程序在系统启动时就加载,最后一个进程关闭时仍然保持运行;Off-最后一个进程结束时卸载驱动。在一般使用场景下影响不大。
Bus-Id:GPU总线ID。
Disp.A:GPU是否运行显示任务,例如连接显示器等。
Volatile Uncorr. ECC:报告GPU错误检查&纠正(ECC)状态,N/A表示不支持ECC或未启用。
Fan:GPU转速百分比。
Temp:GPU当前温度。
Perf:GPU性能状态,P0-全速,P2-低功耗。
Pwr:Usage/Cap:GPU功耗/功耗上限。
Memory-Usage:GPU显存使用情况。
GPU-Util:GPU使用率(正在执行计算任务的比例)。
Compute M.:GPU计算模式。默认模式表示任何人或进程都可以启动计算任务,其他模式表示只有特定用户或进程可以启动计算任务。
通过分析,得到确实GPU0被占用,导致报错。
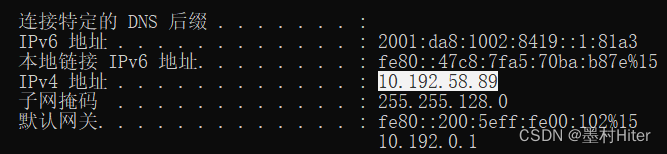
ipconfig查看自己的校园网ip,利用MobaXterm右下角查看ip=121.248.60.155的师兄弟正在占用GPU资源。
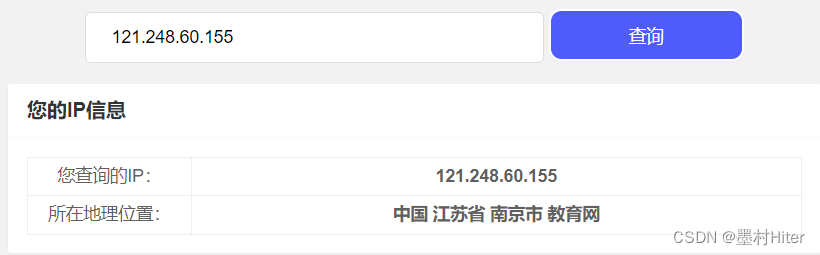
所以我很纳闷,也想明白GPU分配资源的方式是什么样的?长期任务和短期任务如何分配,先后顺序又是如何分配呢?
我又突然想到,我可以在本地电脑跑呀!这个时候Pycharm难用的远程映射功能,就发挥其作用了。下午还在吐槽的功能,现在顿时变成了香饽饽。
利用conda init初始化后,切换pytorch1.11环境,开始调试训练。
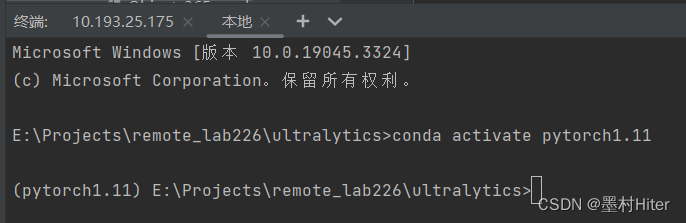

RuntimeError: CUDA out of memory. Tried to allocate 84.00 MiB (GPU 0; 4.00 GiB total capacity; 3.32 GiB already allocated; 0 bytes free; 3.42 GiB reserved in total by PyTorch) If reser
ved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF

自己本地电脑仍然报内存不足错误。按照提示,设置max_split_size_mb,防止碎片化内存分配。
方法1:解决内存碎片化
内存碎片化–》导致影响PyTorch性能,限制其处理更大模型和数据的能力。
- 什么是内存碎片?内存碎片形成的原因?
当内存分配和释放时,在分配的块间形成小的、不可用间隙时,就会出现内存碎片。
①动态内存分配
PyTorch运行时为张量&计算操作动态分配内存。如果分配不连续或频繁分配和释放,可能会导致内存碎片。
②可变大小的张量
可变大小的张量(PyTorch允许模型灵活定义&处理张量大小)频繁分配和释放时,可能会导致内存碎片。
③就地操作
就地操作的输出存储在某个输入张量的内存中,节约内存,但如果生成张量和原始张量显著不同,也可能会导致内存碎片。
④模型复杂性&层大小
复杂架构&大层的模型需大量内存资源,如果不能有效管理可用内存,在训练或推理期间分配和释放是,可能会导致内存碎片。
⑤批次大小
使用不同批次大小时,大批次分配内存无法有效用于较小批次,可能会导致内存碎片。当批次大小频繁变化或显著不同时,问题更加突出。
⑥GPU内存限制
如果可用内存有限,内存没有得到有效利用或由于内存不足而无法连续分配张量时,就会出现碎片。因此PyTorch必须仔细管理内存分配。 - 有哪些影响(后果)?
总结:导致内存分配和利用效率低下,内存消耗增加(需要额外空间容纳内存碎片块,总体内存使用量增加)、内存不足(较小的空闲内存块分散在各处,阻碍大张量有效分配)、训练时间变慢,显著影响模型的性能&效率。
①内存不足
①限制连续内存块使用
①阻碍大张量或中间计算缓冲区的有效分配
②内存使用量增加
③性能下降
PyTorch应用程序需要频繁内存分配&释放,导致开销增加,时间变慢,对训练或推理过程的整体吞吐量&效率产生负面影响。
④增加垃圾收集开销
导致垃圾收集(GC)开销增加,因其须频繁遍历和释放较小内存块,从而增加GC时间,带来额外计算开销并减慢PyTorch代码执行速度。 - 如何解决(避免)?
PyTorch提供max_split_size_mb可配置参数,控制内存碎片。
代码:
import torch
def set_max_split_size_mb(model, max_split_size_mb):
"""
Set the max_split_size_mb parameter in PyTorch to avoid fragmentation.
Args:
model (torch.nn.Module): The PyTorch model.
参数1:PyTorch模型
max_split_size_mb (int): The desired value for max_split_size_mb in megabytes.
参数2:整型数值,单位MiB
"""
for param in model.parameters():
param.requires_grad = False # Disable gradient calculation to prevent unnecessary memory allocations
# 禁用模型中所有参数的梯度计算,防止初始化过程不必要的内存分配
# Dummy forward pass to initialize the memory allocator
# 创建虚拟张量dummy_input,并通过model前向传递,使内存分配器分配内存并建立内存初始状态。
dummy_input = torch.randn(1, 1)
model(dummy_input)
# Get the current memory allocator state
# 检索内存分配器torch.cuda.memory._get_memory_allocator(),允许访问分配器方法&属性
allocator = torch.cuda.memory._get_memory_allocator()
# Update max_split_size_mb in the memory allocator
# 调用分配器set_max_split_size方法更新max_split_size_mb参数,MiB-->B
allocator.set_max_split_size(max_split_size_mb * 1024 * 1024)
for param in model.parameters():
param.requires_grad = True # Re-enable gradient calculation for training
# 重启所有参数的梯度,使模型正常训练
# Example usage
# 示例
if __name__ == "__main__":
# Create your PyTorch model
# 创建model
model = torch.nn.Linear(10, 5)
# Set the desired max_split_size_mb value (e.g., 200 MB)
# 设置max_split_size_mb值,200MiB
max_split_size_mb = 200
# Call the function to set max_split_size_mb
# 调用函数
set_max_split_size_mb(model, max_split_size_mb)
- 如何监控和诊断内存碎片?如何优化内存管理(实现更好的性能&扩展性)?
三种策略:观察、测量和分析
①观察内存分配错误
留意内存不足(OOM)的错误&其他内存相关的异常
②内存分析工具
PyTorch内置内存分析器,跟踪内存分配&释放,PyTorch探查器,识别内存使用模式&潜在碎片来源。(利用上下文管理器torch.autograd.profiler.profile或函数torch.cuda.profiler.profile启用)
③监控GPU内存使用率
nvidia-smi
torch.cuda.memory_allocated()
torch.cuda.memory_cached()
④优化数据加载和批处理
避免低效数据加载和批处理方式,利用预取、并行加载、适量批量大小数据加载器等方法优化加载管道,最大限度减少内存碎片。
⑤尝试不同配置
改变max_split_size_mb,测量内存使用情况、模型性能,评估对内存碎片的影响,找到适合特定用例的最佳设置。
结论:随着时间推移,内存分配错误会导致性能下降,所以需要了解掌握其概念&含义,主动采取措施避免问题。
各位同学,学习完碎片内存处理的示例,我还是不明白怎么将其应用在YOLOv8代码中。这个model具体指的是那一块呢?
内存碎片的管理,对模型运行性能和效率有多大的影响呢?因为这一点非常重要,效率是我所做的课题关注的焦点。
方法2:修改bachsize

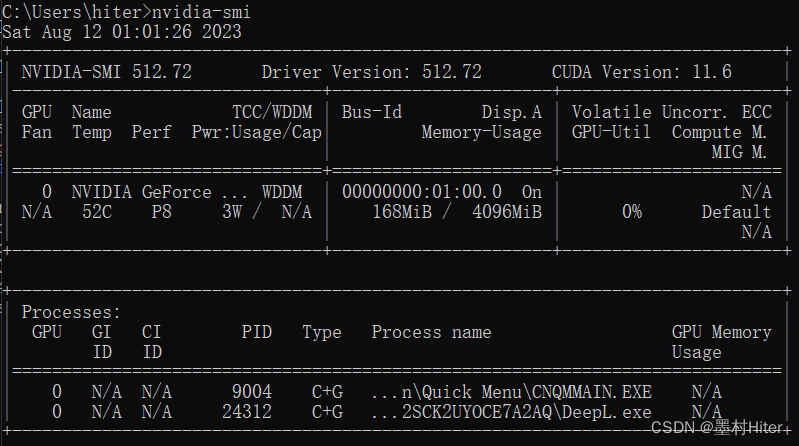
事实上,在本机进行训练时,内存是完全足够的(见上图)!最好的解决办法当然是方法1,但是我并不知道怎么去做,因此只能修改batchsize从默认16到2(8就失败了),避免内存一次性存入大张量,结果可以运行。
但这种方法,治标不治本,我不可能只用batchsize=2来做训练。但起码验证了代码的正确性,是可以跑通的!

方法3:释放GPU已占用的内存空间
利用torch.cuda.empty_cache(),结果并没有用!结束掉nvidia-smi中大PID进程DeepL.exe,也不能够有大的内存提升。所以我满脑子疑惑?
查资料明白,训练时,一般model、数据data、标签label都会放在GPU显存加速。呢么如何清理用完的张量呢?
还有,只要你把任何东西(无论多小的tensor)放到GPU显存,都至少占用512字节(根据CUDA版本略有不同)。这部分显存是CUDA Running时固有配件必须占用的显存。这又是为什么呢?


(这里nvidia-smi中的值,指的是进程占用显存,没错,显存缓冲区也会作为进程占用内存;但加法公式错误,allocated只是Tensor占用显存,应该是包含在显存缓冲区内,加上context占用,才是nvidia-smi进程占用显存才对!)
搞懂这三个函数的作用,所以我们开始做个小实验:
import torch
print(torch.cuda.memory_allocated())
print(torch.cuda.max_memory_allocated())
print(torch.cuda.memory_reserved()) # torch.cuda.memory_cached()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
x = torch.randn((2, 3), device=device)
print(torch.cuda.memory_allocated())
print(torch.cuda.max_memory_allocated())
print(torch.cuda.memory_reserved()) # torch.cuda.memory_cached()
y = torch.randn((200, 300 ,200, 20), device=device)
print(torch.cuda.memory_allocated())
print(torch.cuda.max_memory_allocated())
print(torch.cuda.memory_reserved()) # torch.cuda.memory_cached()
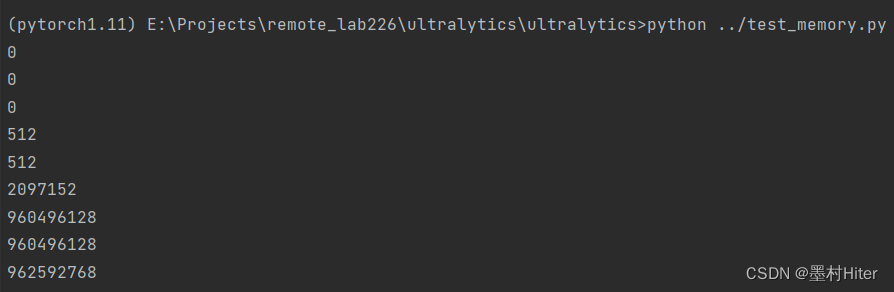
注意:2097152B=2048KiB=2MiB
为什么会出现上面的结果呢?显存缓冲区又是什么意思呢?
- 深度学习的训练过程
PyTorch进行训练时,有四大部分的显存开销:模型参数parameters、模型参数梯度gradients、优化器状态optimizer states、中间激活值(中间结果intermediate activations/results)。【注意优化器状态,并不是context显存开销,读到后面再返回来思考这句话】
为了分析阐述方便,将训练定义为四个步骤:
 ①前向传播
①前向传播

②反向传播

(看不懂?不重要,回头我再仔细研究)
③梯度更新

- 显存分析方法与Torch机制
(1)No Nvidia-smi

到这里,我就明白了。因为PyTorch特有的显存占用机制,才会存在内存碎片问题。
(2)torch.cuda is all you need

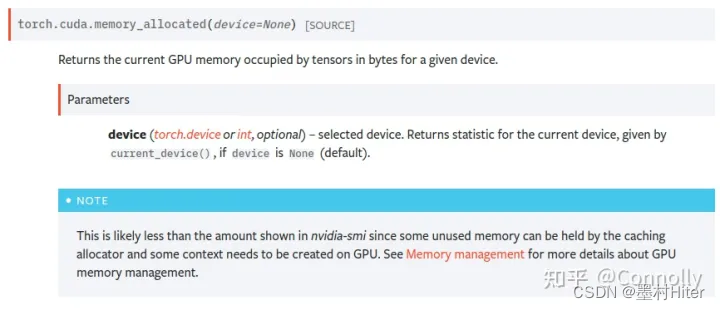
平时,我们还是多查看PyTorch的官方文档,准确而且精简。
(3)PyTorch context开销
那什么又是context开销呢?torch创建CUDA进程时的辅助开销(维护设备间工作的信息存储)。
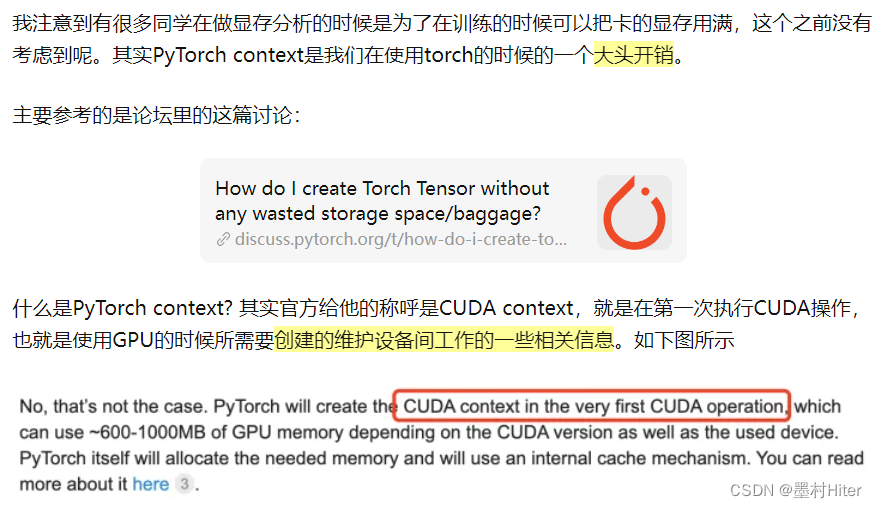


什么意思呢?在Windows下做一下实验看看。
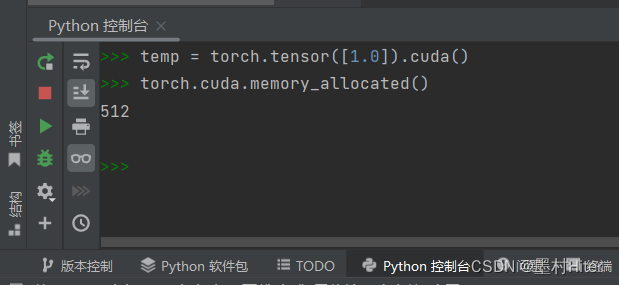
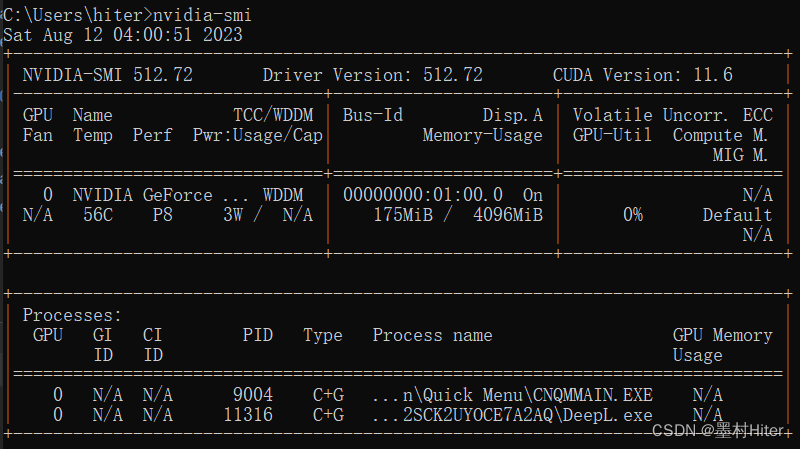
实际上GPU占用175MiB,Windows并没有看到context占用大小,我又调用了服务器命令,也没有发现。先不管怎么做计算,存疑:allocated+memory_reserved/cached+context=total memory usage(进程显存占用包含了context和cashed,作为总显存占用)
问题1:cashe区包不包含context?根据上下文,应该不包含!
问题2:cashe区包不包含memory_allocated?包含!
(4)PyTorch显存分配机制

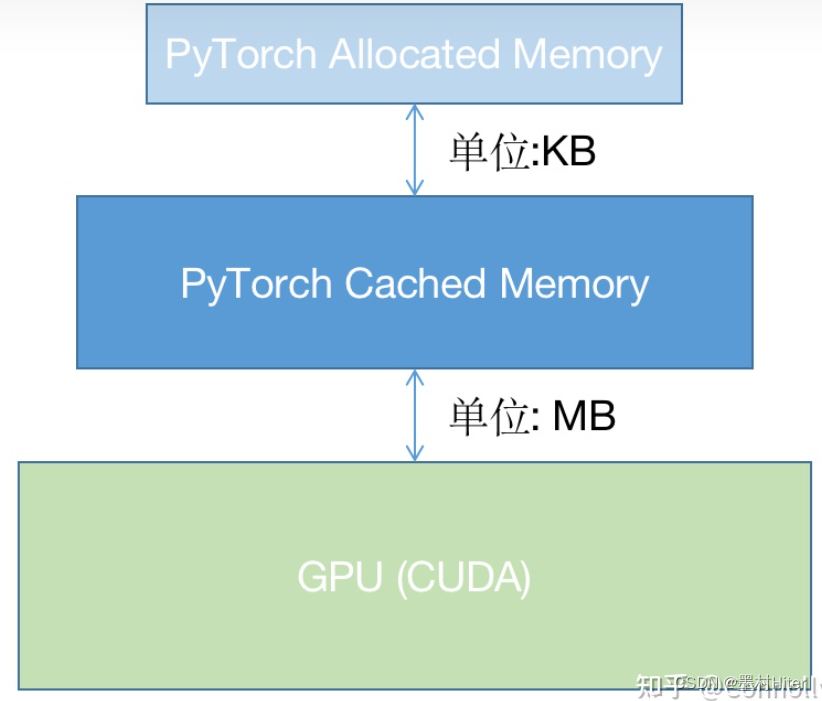


解读来说,reserved_memory-显存缓冲区(也就是被Torch占用,但又不使用存储信息的显存),以缓冲块的形式存在,并按照上述规则分配给四大显存开销。
(5)PyTorch显存释放机制

建议查看官方文档,仔细研究和了解。
- 训练过程中的显存分析

所以为什么loss必须得是标量呢?以后再仔细研究反向传播代码。先看下面两段代码的显存分析:
import torch
# 模型定义 mem = 0
model = torch.nn.Linear(1024, 1024, bias=False).cuda()
print(torch.cuda.memory_allocated()) # 显存增加4194304 = 1024*1024*4 =4MiB 存的是参数(每个参数4字节)
# 前向传播
optimizer = torch.optim.AdamW(model.parameters())
inputs = torch.tensor([1.0]*1024).cuda() # 显存增加4096(1024个4字节输入数)
print(torch.cuda.memory_allocated())
outputs = model(inputs) # 中间激活值(输出) 显存增加4096存的是输出(每个输出4字节)
print(torch.cuda.memory_allocated())
# 后向传播 消耗并释放中间激活值,并为每一个模型参数计算对应梯度,在每一次执行时,会为模型参数分配对应用来存储梯度的空间tid
loss = sum(outputs) # 显存增加512,这是torch allocate分配的最小单元
print(torch.cuda.memory_allocated())
loss.backward()
print(torch.cuda.memory_allocated()) # 第一次计算梯度显存增加4194304 = 1024*1024*4B = 4MiB(存的是梯度)
# 第二次以后显存减少:激活值大小(参考下面的代码理解)
# 参数更新
optimizer.step() # 第一次增加8388608,第二次就不增不减了
print(torch.cuda.memory_allocated())
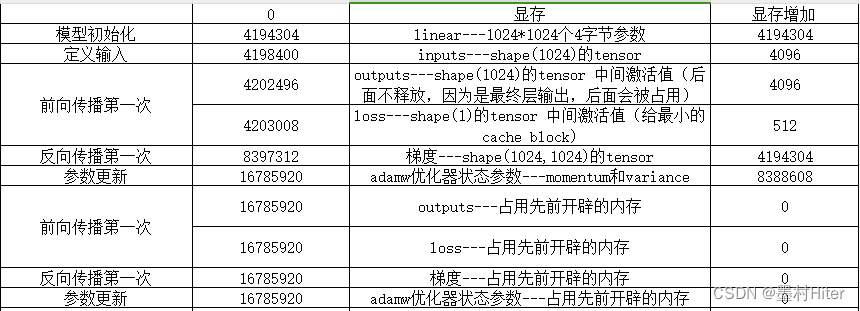
import torch
# 模型初始化
# mem = 0
linear1 = torch.nn.Linear(1024,1024, bias=False).cuda() # 显存增加4194304(1024*1024个4字节参数)
print(torch.cuda.memory_allocated())
linear2 = torch.nn.Linear(1024, 1, bias=False).cuda() # 显存增加4096(1024个4字节参数)
print(torch.cuda.memory_allocated())
# 输入定义
inputs = torch.tensor([[1.0]*1024]*1024).cuda() # shape = (1024,1024) 显存增加4194304(1024*1024个4字节输入数)
print(torch.cuda.memory_allocated())
# 前向传播
loss = sum(linear2(linear1(inputs))) # 显存增加4194304 + 512(1024*1024个4字节梯度参数+512字节的loss数)
print(torch.cuda.memory_allocated())
# 后向传播
loss.backward() # memory - 4194304 + 4194304 + 4096
print(torch.cuda.memory_allocated())
# 再来一次~
loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 (512没了,因为loss的ref还在)
print(torch.cuda.memory_allocated())
loss.backward() # memory - 4194304
print(torch.cuda.memory_allocated())

所以,通过excel表,分析和解释上面代码的显存占用逻辑,非常有利于理清楚逻辑。BUT我突然想修改代码,也就是把loss=sum(linear2(linear1(inputs)))分布写下来,改成:①output1=linear1(inputs)②output2=linear2(outut1)③loss=sum(output2)
再来看分布后的显存占用的逻辑,不出所料,并没有中间激活值显存的释放过程。
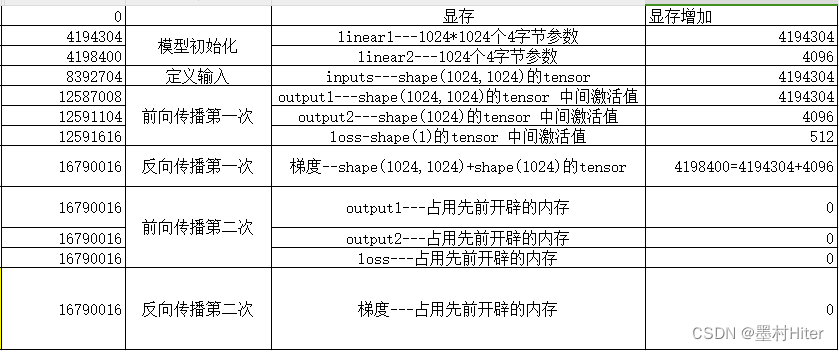
注意:

了解了显存占用机制,有什么用呢?这个,我们下面再说,回归到如何纠正报错问题。
。。。未完待续。。。

















 2850
2850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









