







一、先看文档
所有的优化器都在torch.optim里面
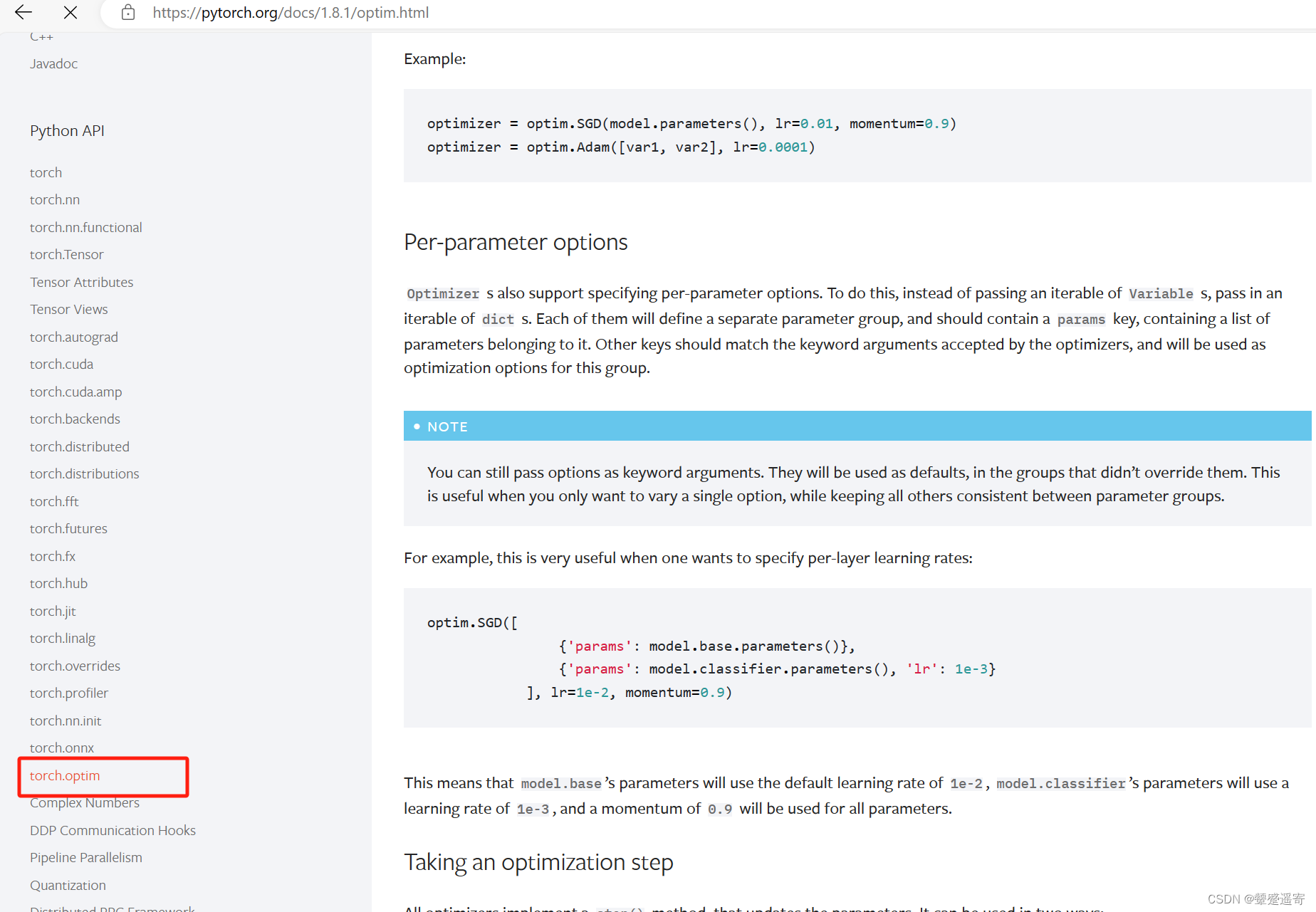
**下面是一些优化器的案例:
lr是学习速率
1、SGD
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
//需要导入的是我们模型的参数 比如tudui.parameters().//
2、Adam
optimizer = optim.Adam([var1, var2], lr=0.0001)
//需要导入的是两个变量//**
前面构造和优化器optimizer后,后面就可以使用了
需要用到step方法
举例:
for input, target in dataset:
optimizer.zero_grad()
//先对optimizer的所有数据梯度清零,
因为这里面的梯度可能是上一步剩下的(相当于篮子被上一步占用了)//
output = model(input) //这是对输入数据进行神经网络操作计算。。//
loss = loss_fn(output, target) //这里可以计算上一步神经网络的loss损失。//
loss.backward() //反向传播//
optimizer.step() //根据上一步的反向传播进行step方法(会对我们的卷积核之类的进行优化)//
这里会有不同的优化算法及介绍

torch.optim.Adadelta(params, lr=1.0, rho=0.9, eps=1e-06, weight_decay=0)
torch.optim.Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0, initial_accumulator_value=0, eps=1e-10)
torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
等等。。。
二、代码实践
1、先把上次课代码整体复制过来:
from torch.nn import Sequential
from torch import nn
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear
import torchvision
from torch.utils.data import DataLoader
dataset=torchvision.datasets.CIFAR10("./P23_dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader=DataLoader(dataset,batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1=Sequential(
Conv2d(3,32,5,1,2),
MaxPool2d(2),
Conv2d(32, 32, 5, 1, 2),
MaxPool2d(2),
Conv2d(32, 64, 5, 1, 2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
tudui=Tudui()
loss=nn.CrossEntropyLoss()
for data in dataloader:
imgs,targets=data
output=tudui(imgs)
result_loss=loss(output,targets)
result_loss.backward()
print("ok")
2、设置一个优化器:
我们这里选择SGD
tudui=Tudui()
optim=torch.optim.SGD()
loss=nn.CrossEntropyLoss()
for data in dataloader:
imgs,targets=data
output=tudui(imgs)
result_loss=loss(output,targets)
result_loss.backward()
print("ok")
看下需要什么参数:

填写:
tudui=Tudui()
optim=torch.optim.SGD(tudui.parameters(),lr=0.01)
这里导入tuidui的参数,学习速率设置为0。01
在循环中加入优化
tudui=Tudui()
optim=torch.optim.SGD(tudui.parameters(),lr=0.01)
loss=nn.CrossEntropyLoss()
for data in dataloader:
imgs,targets=data
output=tudui(imgs)
result_loss=loss(output,targets)
optim.zero_grad()
result_loss.backward()
optim.step()
2、debug看下效果:
打上断点
找到grad梯度
进行到下一行:
运行:opitim.zero_grad()
可以看到grad还是None
进行到下一行:
运行:result_loss.backward()

进行到下一行:
optim.step()

再循环中多次运行:

个人理解就是随着循环一个样本一个样本优化,但是幅度不大
from torch.nn import Sequential
from torch import nn
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear
import torchvision
from torch.utils.data import DataLoader
import torch
dataset=torchvision.datasets.CIFAR10("./P23_dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader=DataLoader(dataset,batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1=Sequential(
Conv2d(3,32,5,1,2),
MaxPool2d(2),
Conv2d(32, 32, 5, 1, 2),
MaxPool2d(2),
Conv2d(32, 64, 5, 1, 2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
tudui=Tudui()
optim=torch.optim.SGD(tudui.parameters(),lr=0.01)
loss=nn.CrossEntropyLoss()
for data in dataloader:
imgs,targets=data
output=tudui(imgs)
result_loss=loss(output,targets)
optim.zero_grad()
result_loss.backward()
optim.step()
print(result_loss)
最终输出的是这次循环后的每个样本损失:
tensor(2.3529, grad_fn=)
tensor(2.2961, grad_fn=)
tensor(2.2118, grad_fn=)
tensor(2.3829, grad_fn=)
tensor(2.3430, grad_fn=)
tensor(2.3058, grad_fn=)
tensor(2.2360, grad_fn=)
tensor(2.2662, grad_fn=)
3、我们多经过几次神经网络学习几次会怎样呢
epoch ——轮
我们创建学习20轮
设running_loss损失初始为0
在每一轮中把他类加上每张数据的损失
累加起来
for epoch in range(20):
runing_loss=0.0
for data in dataloader:
imgs,targets=data
output=tudui(imgs)
result_loss=loss(output,targets)
optim.zero_grad()
result_loss.backward()
optim.step()
runing_loss=result_loss+runing_loss
print(runing_loss)
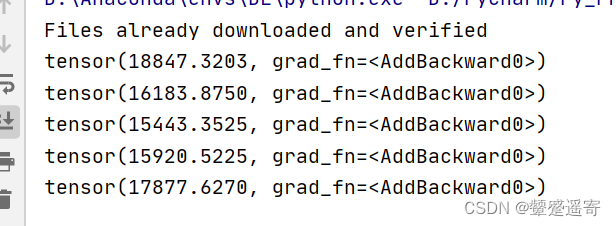
我们发现第三轮学习之后损失达到最小
后面15920又增大了是因为反向优化。。负优化了

















 4613
4613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









