







Transformer详解
1. 简介
Transformer是一个面向sequence to sequence任务的模型,在17年的论文《Attention is all you need》中首次提出。Transformer 是第一个完全依赖自注意力(self-attention)来计算输入和输出的表示,而不使用序列对齐的递归神经网络或卷积神经网络的转换模型。
1.1 Sequence to Sequence
简单地说就是输入一个向量,输出一个向量,两个向量长度不一定相等,如翻译任务等。Decoder这里要注意,其前面的输出会作为当前的输入,然后重复下去。
停止这个重复过程有AT(Autoregressive)和NAT(Non-autoregressive)两种方式。
AT:增加一个特殊的字符end,当输出为end,就停止
NAT:让模型输出一定长度的结果后截止,然后从中截取出需要的部分

2. Transformer网络结构
网络结构如下图所示,左边为编码器(encoder),右边为解码器(decoder)。
编码器:编码器是由N=6个相同的层堆叠而成。每层有两个子层。第一层是一个multi-head self-attention机制,第二层是一个简单的、按位置排列的全连接前馈网络。两个子层都采用了一个residual(残差)连接,然后进行层的归一化。也就是说,每个子层的输出是LayerNorm(x + Sublayer(x)),其中Sublayer(x)是由子层本身的输出。
解码器:解码器也是由N=6个相同层的堆栈组成。除了每个编码器层的两个子层之外,解码器还插入了第三个子层,它对编码器堆栈的输出进行multi-head self-attention。与编码器类似,两个子层都采用了一个residual(残差)连接,然后进行层的归一化。为确保对位置i的预测只取决于小于i的位置的已知输出,修改了解码器堆栈中的multi-head self-attention层。

2.1 Self-attention
self-attention做的就是每一输出都与所有的输入有关,从而有效地利用上下文信息,如下图所示,a为输入,b为输出。

计算步骤:(以b1的计算为例)
q = Wq * a , k = Wk * a , v = Wv * a;其中Wq、Wk、Wv为三个矩阵(或向量),通过学习得到。
- q与各个输入点乘,得到了它们之间的相关性,即下图中的Alpha(可以理解成分数或权重),一般会再通过Soft-max
- v为各个输入的特征,各个Alpha与v相乘求和得到b1
- b2等的计算类似,最后易得其实就是矩阵运算

计算公式:
Q、K、V即上面的Wq、Wk、Wv,dk是缩放因子
除以dk的原因:点积得到的结果维度很大,使得结果处于softmax函数梯度很小的区域,除以一个缩放因子,可以一定程度上减缓这种情况。
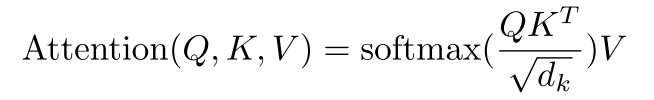
加上位置信息(Positional Encoding):
可以看到,上面各个输入之间没有位置信息,所以需要先进行positional encoding再进行计算,以利用位置信息。如下图所示,先给输入加上一个位置编码e,再计算attention。
位置编码e可以是认为设置,也可以尝试通过学习的方法得到。

2.2 Multi-head self-attention
Multi-head self-attention是self-attention的进阶版本,其实就是每个输入的q、k、v的数量变多,解决的是相关性的形式可能不是一种,所以想要提取到更多的相关性。
下面是Head=2时的示意图。

2.3 Masked Multi-head self-attention
self-attention计算了所有输入的相关性,但是有些任务中,输入是存在时间(或空间)差异的,即有的输入不需要与后面的输入计算相关性,所以采用masked的做法,遮掩其后面的输入。
如下图所示,b2只与a1和a2有关,与a3、a4无关。

2.4 Residual(残差)
Residual的做法就是将输入加到输出上,作为最后的输出,这种思想在Resnet中提出。
这样做的好处:解决了深度神经网络的退化问题,同等层数的前提下残差网络也收敛得更快(这里可以理解为通过计算残差,下一层中只需继续优化未匹配的地方,所以收敛快)
2.5 Layer normalization
Layer normalization是数据归一化的一种方式,计算均值和方差。即Transformer结构图中的Norm。
3. Self-attention与CNN、RNN的对比
3.1 优点
- Self-attention可并行计算
- CNN是Self-attention的一个子集
参考文献:
《On the Relationship between Self-Attention and Convolutional Layers》
《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》
3.2 缺点
attention只能处理固定长度的文本字符串。在输入系统之前,文本必须被分割成一定数量的段或块。这种文本块会导致上下文碎片化。例如,如果一个句子从中间分隔,那么大量的上下文就会丢失。
4. Vision Transformer中的Attention计算
下图中的Linear可以是线性层,也可以是卷积层,核心是改变通道数C产生Q、K、V,其他部分计算如下图所示。

5. Attention的pytorch实现
代码来自https://github.com/Meituan-AutoML/Twins,提供了local attention和标准attention的实现。
import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
from timm.models.vision_transformer import Block as TimmBlock
from timm.models.vision_transformer import Attention as TimmAttention
class GroupAttention(nn.Module):
def __init__(self, dim, num_heads=1, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., ws=1, sr_ratio=1.0):
"""
ws 1 for stand attention 这个注释有问题??ws=1应该是单像素attention了
"""
super(GroupAttention, self).__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# self.q = nn.Linear(dim, dim, bias=qkv_bias)
# self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.ws = ws
def forward(self, x, H, W):
"""
There are two implementations for this function, zero padding or mask. We don't observe obvious difference for
both. You can choose any one, we recommend forward_padding because it's neat. However,
the masking implementation is more reasonable and accurate.
Args:
x:
H:
W:
Returns:
"""
return self.forward_mask(x, H, W)
def forward_mask(self, x, H, W):
B, N, C = x.shape
x = x.view(B, H, W, C)
pad_l = pad_t = 0
pad_r = (self.ws - W % self.ws) % self.ws
pad_b = (self.ws - H % self.ws) % self.ws
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
_, Hp, Wp, _ = x.shape
_h, _w = Hp // self.ws, Wp // self.ws
mask = torch.zeros((1, Hp, Wp), device=x.device)
mask[:, -pad_b:, :].fill_(1)
mask[:, :, -pad_r:].fill_(1)
x = x.reshape(B, _h, self.ws, _w, self.ws, C).transpose(2, 3) # B, _h, _w, ws, ws, C
mask = mask.reshape(1, _h, self.ws, _w, self.ws).transpose(2, 3).reshape(1, _h*_w, self.ws*self.ws)
attn_mask = mask.unsqueeze(2) - mask.unsqueeze(3) # 1, _h*_w, ws*ws, ws*ws
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-1000.0)).masked_fill(attn_mask == 0, float(0.0))
qkv = self.qkv(x).reshape(B, _h * _w, self.ws * self.ws, 3, self.num_heads,
C // self.num_heads).permute(3, 0, 1, 4, 2, 5) # n_h, B, _w*_h, nhead, ws*ws, dim
q, k, v = qkv[0], qkv[1], qkv[2] # B, _h*_w, n_head, ws*ws, dim_head
attn = (q @ k.transpose(-2, -1)) * self.scale # B, _h*_w, n_head, ws*ws, ws*ws
attn = attn + attn_mask.unsqueeze(2)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn) # attn @v -> B, _h*_w, n_head, ws*ws, dim_head
attn = (attn @ v).transpose(2, 3).reshape(B, _h, _w, self.ws, self.ws, C)
x = attn.transpose(2, 3).reshape(B, _h * self.ws, _w * self.ws, C)
if pad_r > 0 or pad_b > 0:
x = x[:, :H, :W, :].contiguous()
x = x.reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def forward_padding(self, x, H, W):
B, N, C = x.shape
x = x.view(B, H, W, C)
pad_l = pad_t = 0
pad_r = (self.ws - W % self.ws) % self.ws
pad_b = (self.ws - H % self.ws) % self.ws
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
_, Hp, Wp, _ = x.shape
_h, _w = Hp // self.ws, Wp // self.ws
x = x.reshape(B, _h, self.ws, _w, self.ws, C).transpose(2, 3)
qkv = self.qkv(x).reshape(B, _h * _w, self.ws * self.ws, 3, self.num_heads,
C // self.num_heads).permute(3, 0, 1, 4, 2, 5)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
attn = (attn @ v).transpose(2, 3).reshape(B, _h, _w, self.ws, self.ws, C)
x = attn.transpose(2, 3).reshape(B, _h * self.ws, _w * self.ws, C)
if pad_r > 0 or pad_b > 0:
x = x[:, :H, :W, :].contiguous()
x = x.reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
else:
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
if __name__ == '__main__':
model = GroupAttention(dim=128, ws=2).cuda()
img = torch.randn((1, 16 * 32, 128)).cuda()
model.forward_padding(img, 16, 32)
















 5965
5965











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









