







目录
前言
下午看完小米汽车发布会,雷军称小米汽车希望能做一辆媲美保时捷和特斯拉的Dream Car。看得人十分心痒痒,相信很多小伙伴们都和我一样。让我们来看看雷总微博下面大家对此的评价叭~
环境使用
Python 3.8
Pycharm专业版
模块使用
requests
re
csv
time
random
数据来源分析
1.明确需求
雷军关于小米SU7汽车的发布微博

2.抓包分析
按F12打开开发者工具,点击Fetch/XHR打开动态加载数据
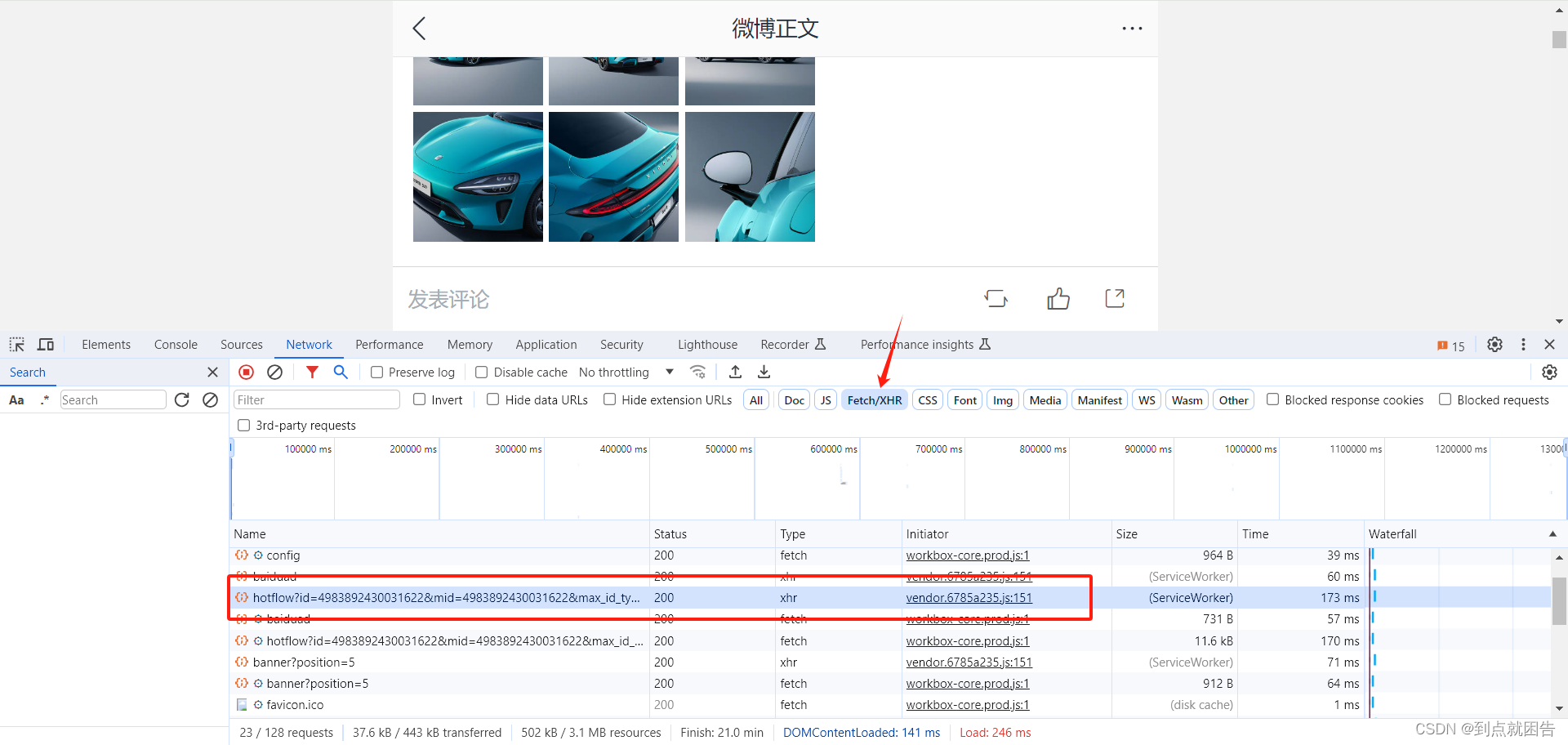
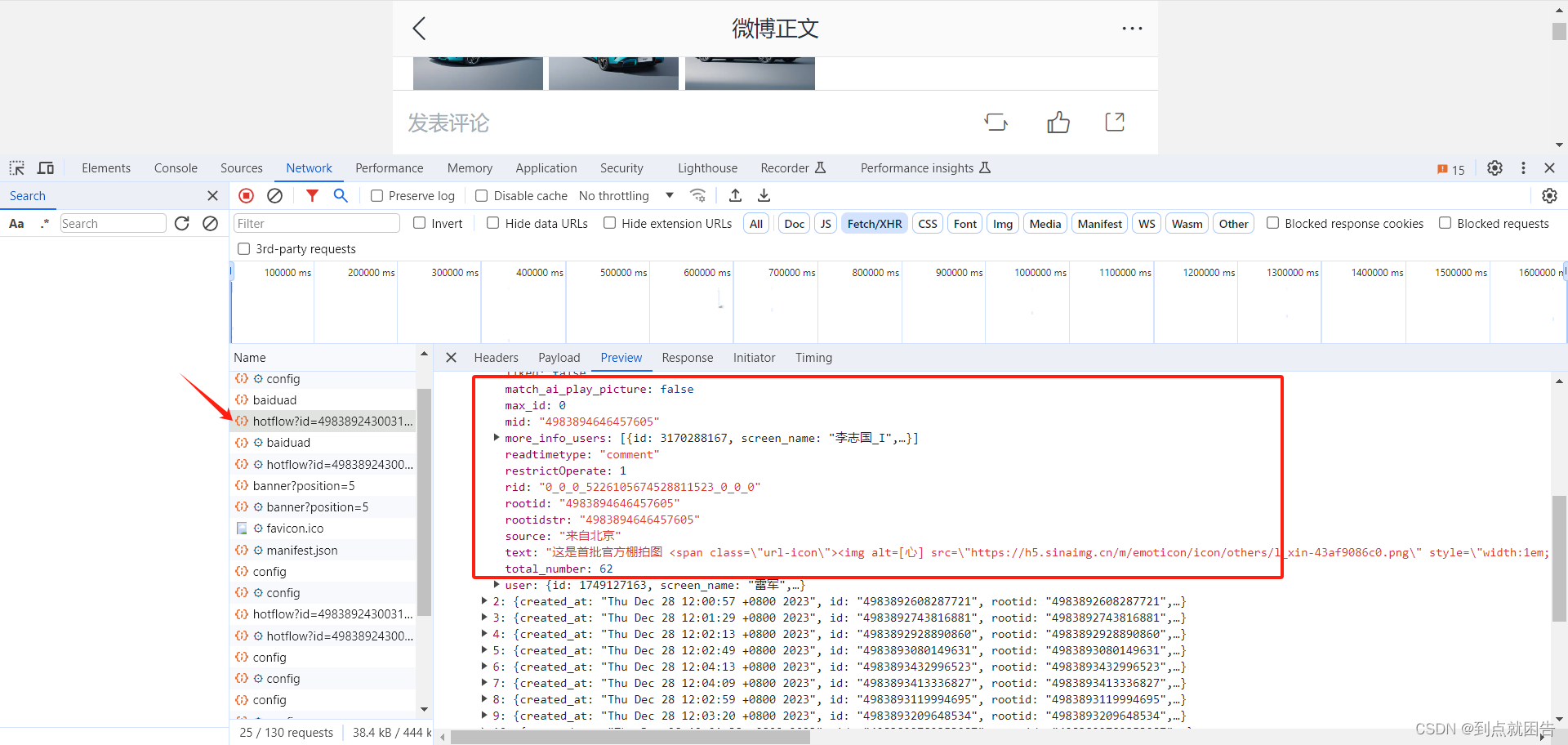
以下即是我们需要的评论数据
代码实现
导入模块
import requests
import random
import re
import csv
import time请求数据
模拟浏览器:
response.text 获取响应文本数据
response.json() 获取响应json字典数据
response.content 获取响应二进制数据
我们使用requests.get()方法向指定的url发送get请求,并获取到响应的内容
url = f'https://m.weibo.cn/comments/hotflow?id=4983892430031622&mid=4983892430031622&max_id={max_id}&max_id_type=0'
headers = {
'Referer': 'https://m.weibo.cn/detail/4983892430031622',
'User-Agent': random.choice(user_agents),
}
response = requests.get(url=url, headers=headers).json()解析数据
使用json键值对获取需要的评论信息,包括评论内容,评论时间,点赞数据,IP等。
data_list = response['data']
max_id = response['data']['max_id']
for data in data_list['data']:
comment = data['text'] # 内容
label = re.compile(r'</?\w+[^>]*>', re.S)
comment = re.sub(label, '', comment)
floor_number = data['floor_number'] # 楼层
create_time = time.strftime('%Y-%m-%d %H:%M:%S',
(time.strptime(data['created_at'].replace('+0800', '')))) # 时间
like_count = data['like_count'] # 点赞数量
screen_name = data['user']['screen_name'] # 昵称
id = data['user']['id'] # id
try:
source = data['source'] # ip
except:
source = '未知'
reply = data['total_number'] # 回复数量
print(screen_name, id, source, comment, floor_number, create_time, like_count, reply)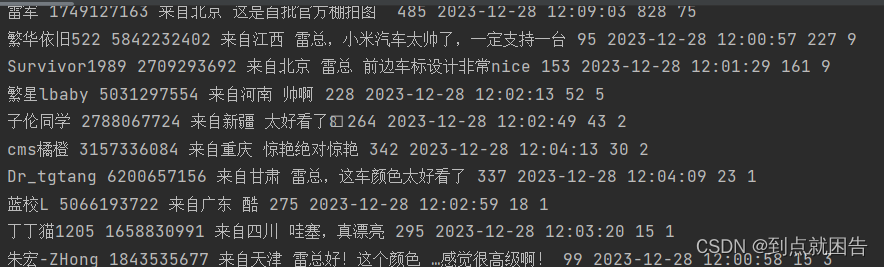
保存数据
使用csv模块保存以上数据
f = open(f'wb.csv', mode='a', encoding='utf-8-sig', newline='')
csv_write = csv.DictWriter(f, fieldnames=['昵称', 'id', 'ip', '内容', '楼层', '评论时间', '点赞量', '回复量'])
csv_write.writeheader()
总结
从评论可以看出来大家都小米汽车颜值赞赏有加,小编的期待值也是满满的呢!期待雷总几个月后给出的价格,让大家都能开上小米汽车。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











