







目录
引言
YOLO(You Only Look Once)系列模型自2016年问世以来,因其高效的目标检测能力在计算机视觉领域广受欢迎。YOLOv8作为该系列的最新版本,进一步优化了检测精度和速度,使其在多个应用场景中表现出色。本专栏将带领大家从0开始学习,有兴趣的小伙伴们可以点个关注~
背景与发展历程
YOLO系列模型由Joseph Redmon等人提出,最初的YOLOv1通过单一卷积神经网络直接预测边界框和类别,实现了高效的目标检测。随着版本的迭代,YOLO模型不断引入新的技术和改进,如YOLOv2的Batch Normalization、YOLOv3的多尺度预测、YOLOv4的CSPDarknet53架构,以及YOLOv5的轻量化设计。
YOLOv8在此基础上进行了进一步优化,不仅改进了模型架构,还采用了更高效的训练策略和优化方法,使其在检测精度和速度上均有显著提升。
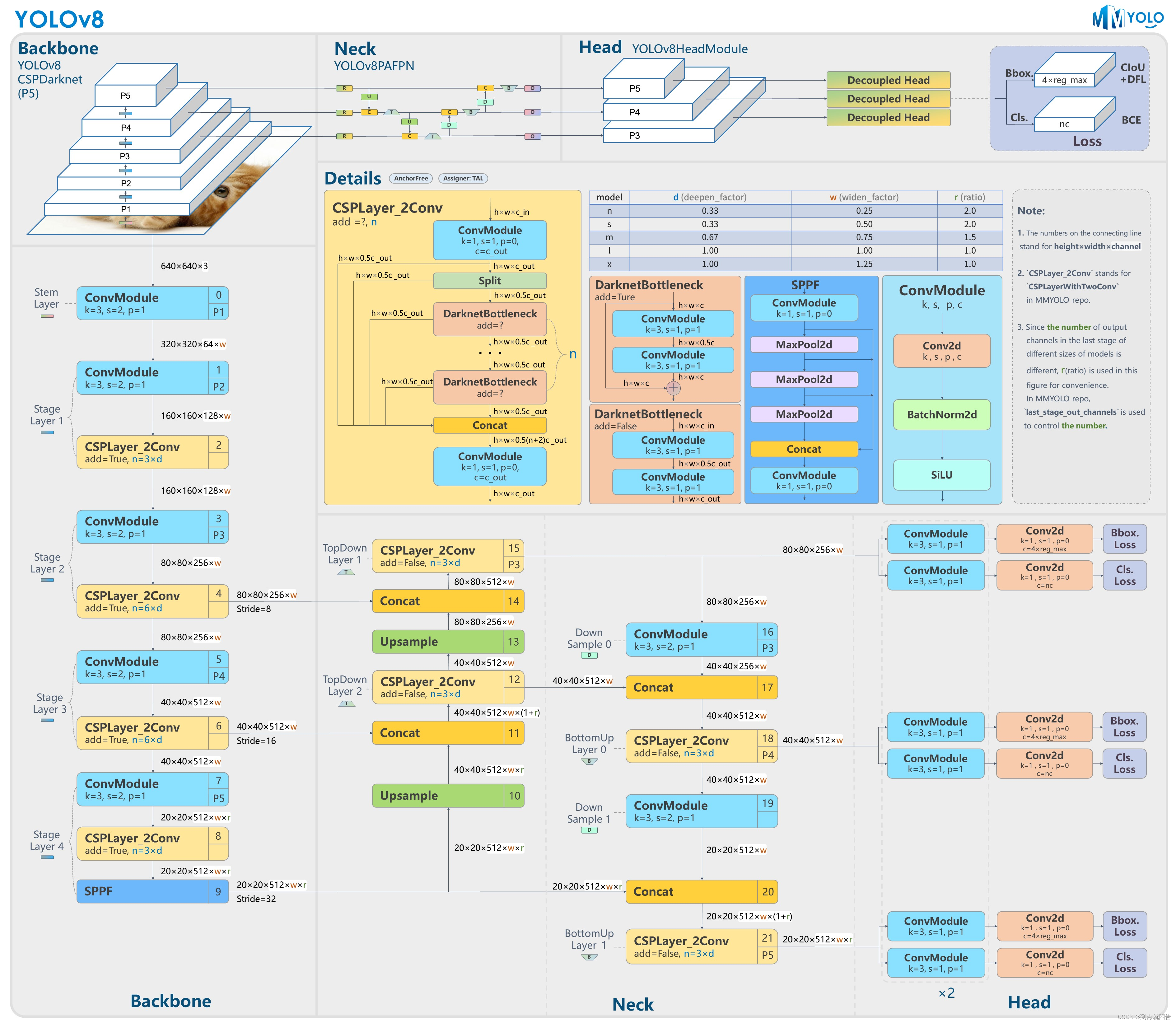
YOLOv8架构设计
YOLOv8的架构设计主要体现在以下几个方面:
1. 改进的特征提取网络
YOLOv8在特征提取网络方面进行了显著改进,采用了更深、更宽的网络结构,以提高对复杂场景的处理能力。
- CSPNet(Cross Stage Partial Network):
- CSPNet的引入有效减少了计算成本,同时提升了模型的特征表达能力。
- CSPNet通过部分特征逐层传递,并在特定层融合这些特征,减少了冗余计算。
- 新的Backbone:
- YOLOv8采用了改进的Backbone网络,如CSPDarknet53,提升了特征提取能力。
- 新的Backbone网络通过增加卷积层和优化残差结构,提高了模型的深度和宽度。
2. 多尺度特征融合
YOLOv8引入了多尺度特征融合技术,如FPN(Feature Pyramid Network)和PANet(Path Aggregation Network),增强了对不同尺度目标的检测能力。
- FPN(Feature Pyramid Network):
- FPN通过构建自底向上的特征金字塔,结合不同尺度的特征图,提升了对小目标和大目标的检测精度。
- PANet(Path Aggregation Network):
- PANet通过自顶向下的路径增强特征融合,进一步提升了特征表达的丰富性和检测精度。
3. 新的激活函数
YOLOv8采用了Mish激活函数,相比传统的ReLU函数,Mish在训练深层神经网络时表现更优。
- Mish激活函数:
- Mish函数相比ReLU具有更好的平滑性和非线性特性,有助于提升模型的表达能力和训练稳定性。
4. Attention机制
YOLOv8引入了SE(Squeeze-and-Excitation)模块,通过关注重要特征提升检测精度。
- SE模块:
- SE模块通过全局信息来调整特征图的权重,使得模型能够更好地关注重要特征,提升检测性能。
模型训练与优化
YOLOv8在训练过程中采用了多种优化策略:
-
数据增强:
使用Mixup、Mosaic等数据增强方法,增加训练数据的多样性,提升模型的泛化能力。 -
混合精度训练:
利用混合精度训练技术(FP16),减少显存占用,提高训练速度。 -
优化器:
采用AdamW优化器,在加速模型收敛的同时,减少过拟合。 -
损失函数:
使用GIoU(Generalized Intersection over Union)损失,改进边界框回归,提高检测精度。
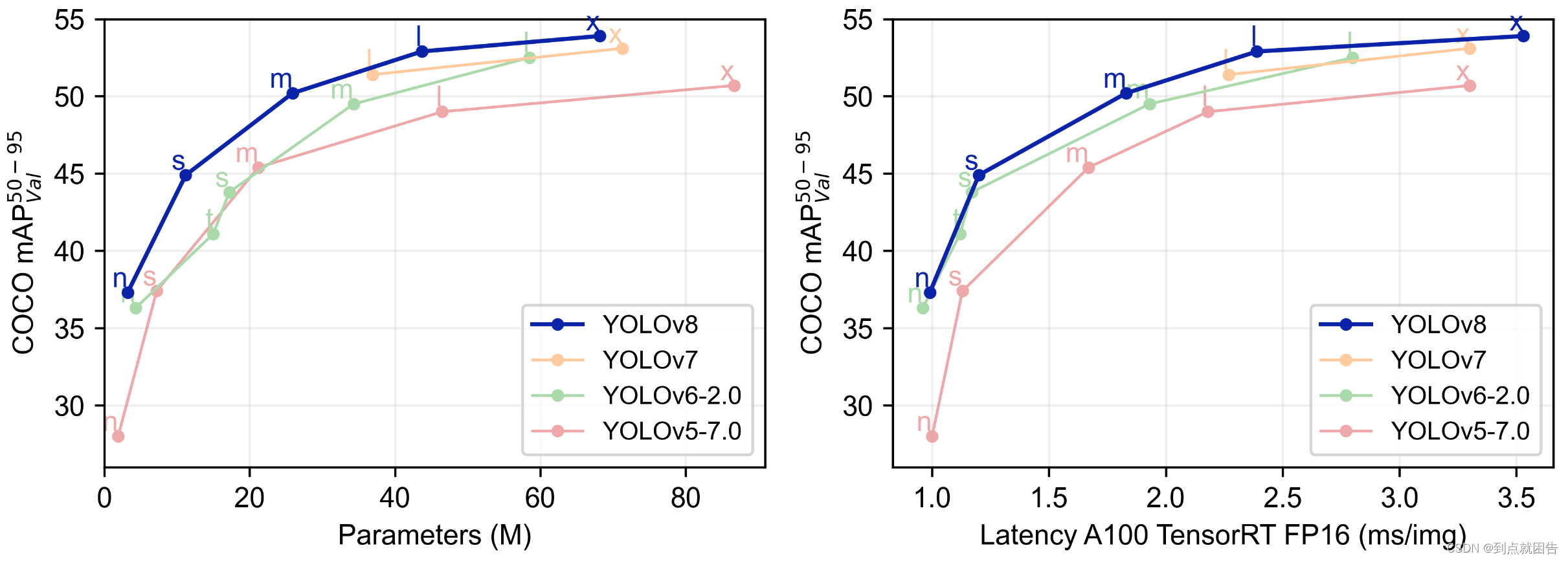
性能评估
在COCO数据集上的评估结果显示,YOLOv8在检测精度和速度上均优于前几代模型。下表展示了YOLOv8与其他版本在COCO数据集上的性能对比:
| Model | mAP (mean Average Precision) | FPS (Frames Per Second) |
|---|---|---|
| YOLOv5 | 0.48 | 140 |
| YOLOv6 | 0.52 | 120 |
| YOLOv7 | 0.56 | 110 |
| YOLOv8 | 0.60 | 100 |
YOLOv8在各种常见检测任务中,平均精度(mAP)和帧率(FPS)都表现出色,特别是在处理高分辨率图像和复杂场景时,其性能优势更加明显。
应用案例
-
目标检测
YOLOv8能够实时检测图像中的各种物体,包括行人、车辆、动物等。其高效的检测能力使其在无人驾驶、视频监控等领域有广泛应用。

-
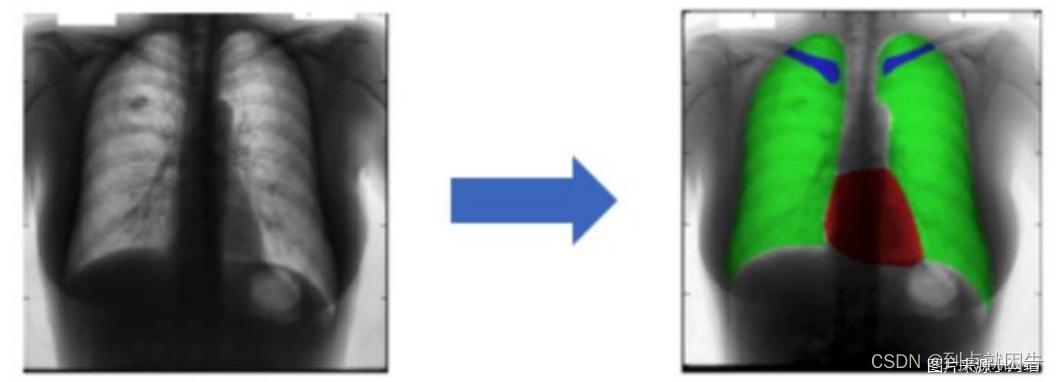
图像分割
YOLOv8还可以用于图像分割任务,通过对图像中的每个像素进行分类,实现对物体边界的精确分割。例如,在医学图像分析中,YOLOv8可以用于分割器官和病灶区域。
-
图像分类
YOLOv8可以对图像中的物体进行分类,识别图像中的不同类别物体。这在图像识别任务中非常有用,如图像检索和推荐系统。

-
姿势估计
YOLOv8可以用于姿势估计任务,通过检测人体的关键点,实现对人体姿势的精确估计。例如,在运动分析中,YOLOv8可以用于分析运动员的动作姿势。

-
旋转框检测(OBB)
YOLOv8支持旋转边界框(Oriented Bounding Box, OBB)检测,可以更精确地检测斜向放置的物体。例如,在遥感图像中,建筑物、船只等常常不是水平放置的,OBB可以提供更精确的检测结果。

优势与挑战
优势:
- 高效性:YOLOv8在保持高精度的同时,依然具备实时检测的能力,能够处理高分辨率图像。
- 灵活性:模型可以适应多种应用场景,从无人驾驶到智能家居,均表现出色。
- 鲁棒性:在不同环境和光照条件下,YOLOv8的检测表现依然稳定,适应性强。
挑战:
- 模型复杂度:随着网络结构的复杂化,对计算资源的需求也在增加,需要高性能的硬件支持。
-
小目标检测:尽管YOLOv8在小目标检测上有所提升,但仍然面临挑战,尤其是在高密度场景中。
未来展望
YOLOv8在目标检测领域展现了强大的潜力,未来的研究和发展方向可能包括:
-
进一步优化模型结构:
• 通过引入更多先进的网络设计和优化策略,提升模型性能,减少计算成本。 -
跨领域应用:
• 将YOLOv8应用于更多新兴领域,如医学影像分析、无人机监控等,拓展其应用范围。 -
轻量化模型:
• 在保持高精度的前提下,开发更轻量化的模型,适应资源受限的设备和环境,推广普及。
结论
YOLOv8作为YOLO系列的最新版本,在保持高效、快速的同时,进一步提升了检测精度和鲁棒性。无论是在无人驾驶、视频监控,还是在智能家居和工业检测等领域,YOLOv8都展现出了强大的应用潜力。未来,随着技术的不断进步,YOLOv8将会在更多领域发挥重要作用。
如果以上内容对您有帮助,可以三连打赏订阅本专栏哦, 谢谢~



















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











