







目录
引言
《在大庆度过余年》是一部备受瞩目的电视剧,自上映以来吸引了大量观众,并在各大视频平台上获得了极高的播放量。随着第二部的上线,观众们的热情依旧高涨,弹幕作为观众表达情感、交流观点的重要途径,成为了研究观众反馈的重要数据来源。本文将介绍如何爬取弹幕,并进行情感分析,以了解观众对这部电视剧的真实反馈。
爬虫实现
首先,我们需要从企鹅视频平台爬取弹幕数据。企鹅视频的弹幕数据通常是通过特定的接口获取的,返回的内容通常是 JSON 格式的数据。为了实现弹幕数据的爬取,我们使用了 Python 的 requests 库。
1、数据来源分析
老规矩,我们F12打开开发者工具,通过查询找到数据来源

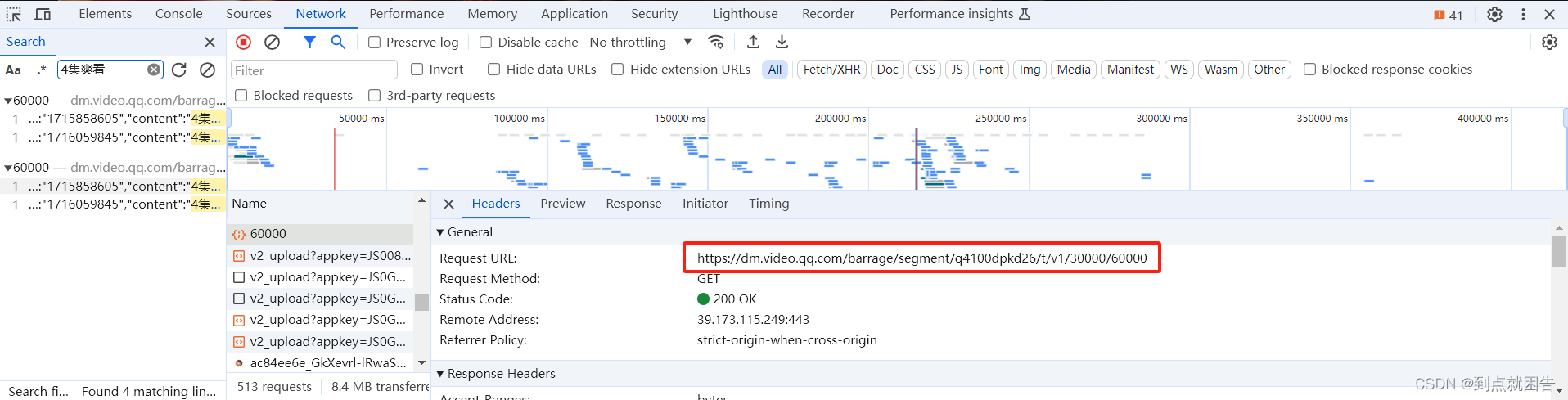
2、请求数据
import requests
url = 'https://dm.video.qq.com/barrage/segment/q4100dpkd26/t/v1/30000/60000'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers).json()
print(response )请求成功,可以得到我们上述看到的弹幕内容

3、解析数据
barrage_list = response['barrage_list']
for barrage in barrage_list:
content = barrage['content']
print(content)
4、保存数据
from DataRecorder import Recorder
recorder = Recorder('弹幕.csv')
# 设置编码
recorder.set.encoding('utf-8-sig')
recorder.set.head(['content'])
recorder.add_data((content))
recorder.record()将以上弹幕数据保存为csv表格数据,已进行下一步的情感分析。(不过,五年闺蜜结婚俩次...有点抽象
情感分析
1、读取表格数据
使用pandas库。Pandas 是 Python 编程语言中一个强大的数据分析和数据操作库,提供了快速、灵活和富有表现力的数据结构,使得数据清洗、数据处理、数据分析等工作变得简单、高效。
df = pd.read_csv('弹幕.csv')
df
2、情感分析
SnowNLP 是一个用于处理中文文本的 Python 库,专注于中文自然语言处理任务,如情感分析、文本分类、关键词提取等。它提供了一系列用于处理中文文本的工具和模型,使得中文文本处理变得更加方便和高效。
from snownlp import SnowNLP
def analyze_sentiment(text):
s = SnowNLP(text)
return s.sentiments3、可视化
Seaborn 是一个基于 Matplotlib 的 Python 数据可视化库,旨在提供一种简单直观的方法,使得数据可视化过程更加快捷、美观。它提供了一系列高级数据可视化功能,能够轻松创建各种统计图表,包括散点图、折线图、箱线图、直方图、核密度估计图等,同时支持对分类数据的可视化。
import seaborn as sns
df['sentiment'] = df['content'].apply(analyze_sentiment)
plt.figure(figsize=(10, 6))
sns.histplot(df['sentiment'], bins=20, kde=True)
plt.title('Sentiment Analysis of Danmaku for Qing Yu Nian 2')
plt.xlabel('Sentiment Score')
plt.ylabel('Frequency')
plt.show()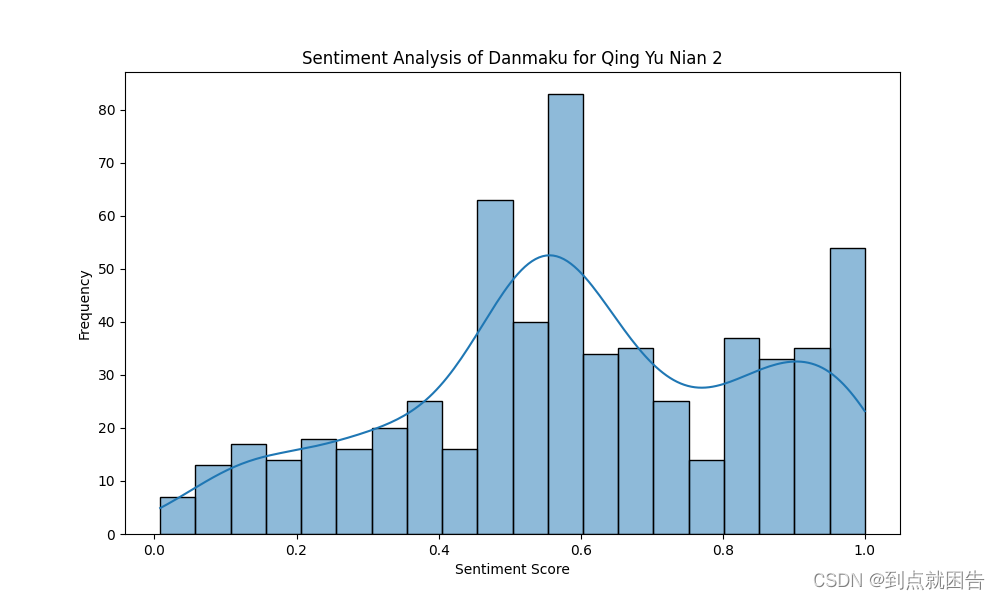
通过情感分析的结果,我们可以发现观众情感表达多种多样。大部分观众对剧情的发展和人物性格给予了积极的评价,认为剧情跌宕起伏、人物形象丰满,引人入胜。
总结
综合来看,弹幕爬取与情感分析不仅展现了观众对于该剧的多样化评价和情感表达,也反映了网络文化下观众与作品之间的互动与共鸣。通过这种方式,我们能够更深入地理解观众的观剧体验和情感需求,为制作方和创作者提供更有针对性的改进建议和参考,促进了影视作品与观众之间的良性互动与共赢。
觉得文章对您有用的话麻烦帮忙三连,谢谢~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











