






TextCNN
在2014年,美国纽约大学的Yoon Kim提出了一种TextCNN模型,把卷积神经网络(CNN)用于文本分类,利用多个不同大小的卷积核来提取文本中的特征,从而能够更好地捕捉局部的相关性。论文地址:Convolutional Neural Networks for Sentence Classification
1、网络结构
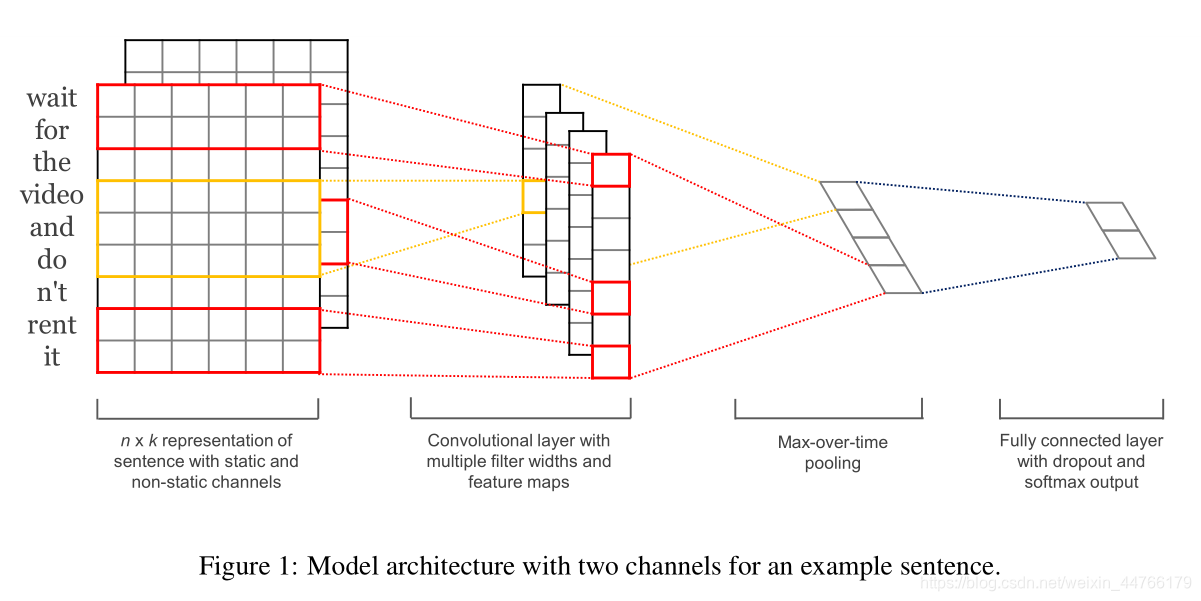
模型结构是CNN结构的一个微小变体。设为句子中第
i
i
i个单词对应的k维单词向量。长度为
n
n
n的句子(在必要的地方进行填充)表示为:
其中,
⨁
\bigoplus
⨁是连接操作。
x
i
:
i
+
j
x_{i:i+j}
xi:i+j表示单词
x
i
,
x
i
+
1
,
.
.
.
x
i
+
j
x_{i},x_{i+1},...x_{i+j}
xi,xi+1,...xi+j的连接。一个卷积操作对应一个卷积核
w
∈
R
h
k
w\in \mathbb{R}^{hk}
w∈Rhk,通过这个卷积核对h个单词进行卷积产生新的特征
c
i
c_{i}
ci。
c
i
=
f
(
w
⋅
x
i
:
i
+
h
−
1
+
b
)
c_{i}=f(w \cdot x_{i:i+h-1}+b)
ci=f(w⋅xi:i+h−1+b)。
b
∈
R
b \in \mathbb{R}
b∈R是一个偏置项,
f
f
f是一个非线性函数,如双曲正切。卷积核被用于句子
{
x
1
:
h
,
x
2
:
h
+
1
,
.
.
.
,
x
n
−
h
+
1
:
n
}
\{x_{1:h},x_{2:h+1},...,x_{n-h+1:n}\}
{x1:h,x2:h+1,...,xn−h+1:n}中每个可能的单词窗口来产生feature map
c
=
[
c
1
,
c
2
,
.
.
.
,
c
n
−
h
+
1
]
c=[c_{1},c_{2},...,c_{n-h+1}]
c=[c1,c2,...,cn−h+1],
c
∈
R
n
−
h
+
1
c \in \mathbb{R}^{n-h+1}
c∈Rn−h+1。然后,在feature map上应用一个max-over-time池操作,并将最大值
c
^
=
m
a
x
{
c
}
\hat{c} = max\{c\}
c^=max{c}作为对应于此特定卷积核的特性。其思想是捕获最重要的特性,并为每个特征图获取值最高的特征。这个合用方案自然处理可变的句子长度。模型使用多个卷积核(具有不同的窗口大小)来获得多个特征。这些特征形成倒数第二层,并传递给一个全连接的softmax层,其输出是标签上的概率分布。
TextCNN的详细原理
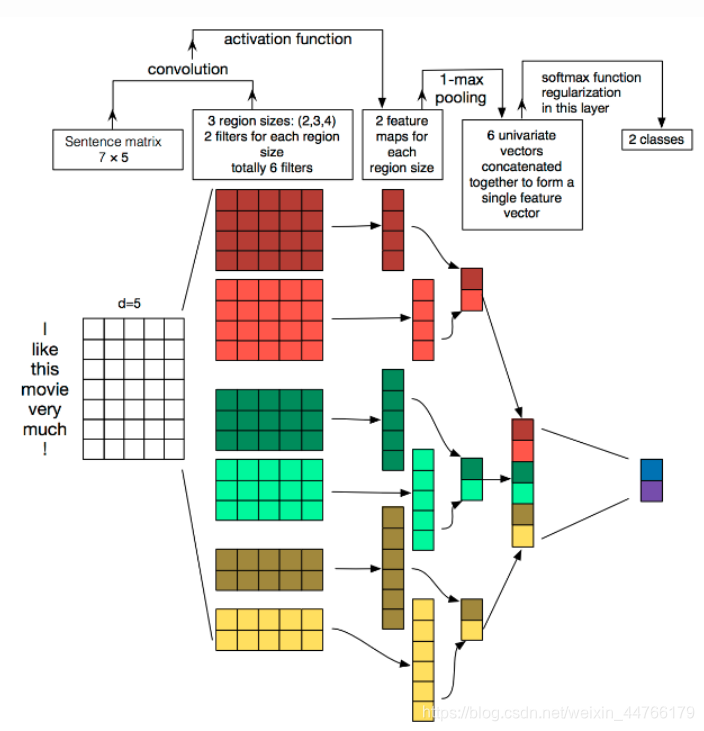
TextCNN详细过程:
Embedding:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点。
Convolution:然后经过 kernel_sizes=(2,3,4) 的一维卷积层,每个kernel_size 有两个输出 channel。
MaxPolling:第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示。
FullConnection and Softmax:最后接一层全连接的 softmax 层,输出每个类别的概率。
通道(Channels):
图像中可以利用 (R, G, B) 作为不同channel;
文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。
一维卷积(conv-1d):
图像是二维数据;
文本是一维数据,因此在TextCNN卷积用的是一维卷积(在word-level上是一维卷积;虽然文本经过词向量表达后是二维数据,但是在embedding-level上的二维卷积没有意义)。一维卷积带来的问题是需要通过设计不同 kernel_size 的 filter 获取不同宽度的视野。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









