









 TextCNN是YoonKim在2014年提出的文本分类模型,它基于CNN但输入层处理的是经wordembedding的一维自然语言数据。尽管网络结构简单,仅包含一层卷积和一层最大池化,TextCNN仍能在多项数据集上表现出色,因其参数少、计算量小而训练速度快。模型主要区别在于处理一维数据的卷积方式,并且可以使用预训练的词向量(如word2vec)进行静态或动态初始化。
TextCNN是YoonKim在2014年提出的文本分类模型,它基于CNN但输入层处理的是经wordembedding的一维自然语言数据。尽管网络结构简单,仅包含一层卷积和一层最大池化,TextCNN仍能在多项数据集上表现出色,因其参数少、计算量小而训练速度快。模型主要区别在于处理一维数据的卷积方式,并且可以使用预训练的词向量(如word2vec)进行静态或动态初始化。
TextCNN是什么
提到CNN时,通常会认为其属于CV领域,是用于解决计算机视觉方向问题的模型,但是在2014年,Yoon Kim针对CNN的输入层做了一些变形,提出了文本分类模型TextCNN。与传统图像的CNN网络相比,TextCNN 在网络结构上没有任何变化(甚至更加简单了),从下图可以看出TextCNN 其实只有一层卷积,一层max-pooling,最后将输出外接softmax来进行n分类。
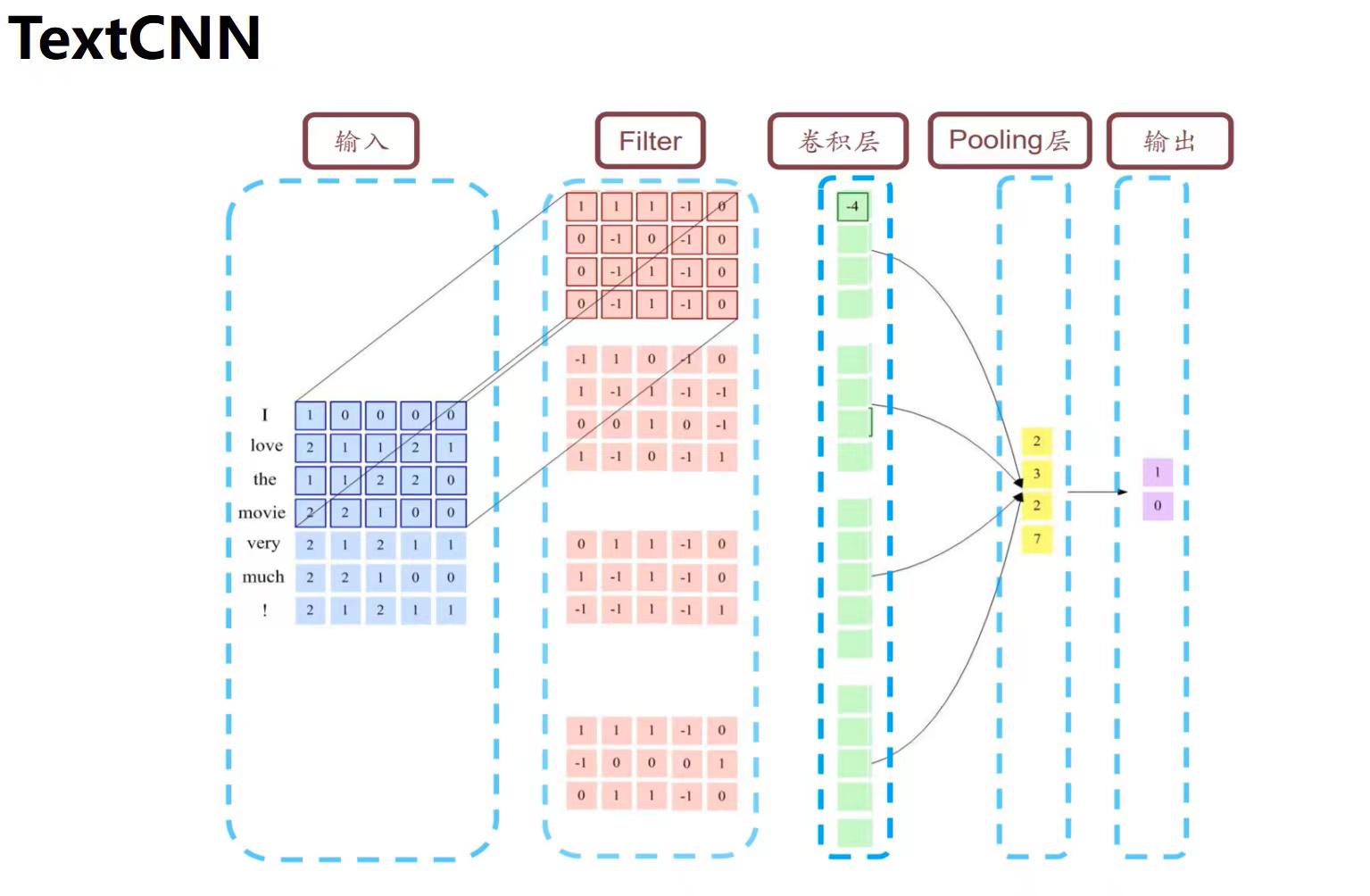
与图像当中CNN的网络相比,TextCNN 最大的不同是输入数据的不同:
图像是二维数据,图像的卷积核是从左到右,从上到下进行滑动来进行特征抽取。
自然语言是一维数据,虽然经过word embedding生成了二维向量,但是对词向量做从左到右滑动来进行卷积没有意义,需要将单个词向量看作整体来进行特征提取。比如 “今天” 对应的向量[0, 0, 0, 0, 1],按窗口大小为 1* 2 从左到右滑动得到[0,0],[0,0],[0,0],[0, 1]这四个向量,对应的都是"今天"这个词汇,这种滑动没有帮助。
TextCNN的优势
TextCNN最大优势网络结构简单 ,在模型网络结构如此简单的情况下,通过引入已经训练好的词向量依旧有很不错的效果,在多项数据数据集上超越benchmark。
网络结构简单导致参数数目少, 计算量少, 训练速度快,在单机单卡的v100机器上,训练165万数据, 迭代26万步,半个小时左右可以收敛。
TextCNN的详细过程
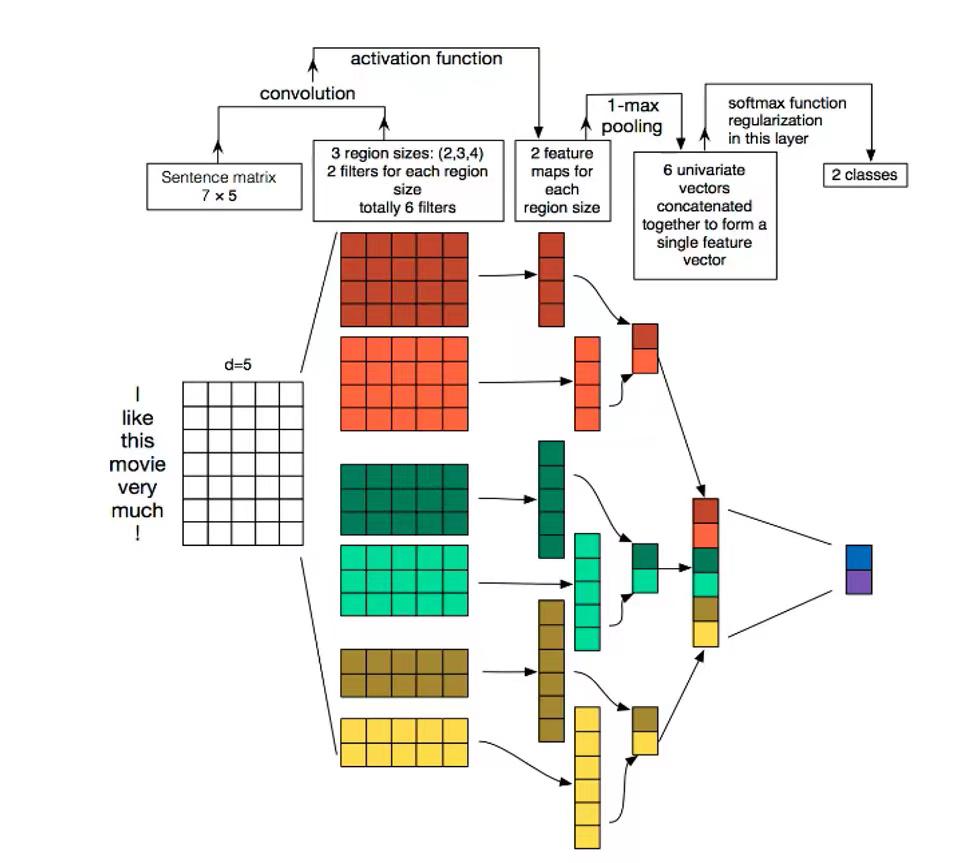
首先是对序列的补齐:上图中模型的len_max设置为7,句子I like this movie very much !长度为7,不需要额外的<PAD>填充。
构建词库并进行word embedding:根据训练数据中的所有句子构建word_2_idex词库,将单词转换为对应的索引,通常词库的长度为所有句子中不同单词的总数加2,因为<PAD>使用索引0用于表示填充的单词,<UNK>使用索引1用于表示词库中没有的单词。再对每个单词进行word embedding处理,图中每个单词的embedding_num设置为5,得到了一个7x5的输入矩阵。
确定input_channel的大小:对于图像来说存在R、G、B三个色彩空间,其对应的输入通道数为3,通常文本的输入通道数为1,可以采用不同的embedding方式(比如word2vec、Bert等)扩充输入通道。实践中也有利用静态词向量和fine-tunning词向量作为不同输入通道的做法,但是实验证明,单通道的TextCNN 表现都要优于多通道的TextCNN。图中采用单通道数。

a. CNN-rand(随机词向量)
指定词向量的维度embedding_num后,文本分类模型对不同单词的向量作随机初始化, 后续有监督学习过程中,通过BP的方式更新输入层的各个词汇对应的词向量。
b. CNN-static(静态词向量)
使用预训练的词向量,即利用word2vec、fastText或者Glove等词向量工具,在开放领域数据上进行无监督的学习,获得词汇的具体词向量表示方式,拿来直接作为输入层的输入,并且在TextCNN模型训练过程中不再调整词向量, 这属于迁移学习在NLP领域的一种具体的应用。
c. CNN-non-static(非静态词向量)
预训练的词向量+ 动态调整 , 即使用word2vec训练好的词向量初始化, 训练过程中再对词向量进行微调。
d. multiple channel(多通道)
借鉴图像中的RGB三通道的思想, 这里也可以用 static 与 non-static 两种词向量初始化方式来搭建两个通道。
确定卷积核的大小和数量:前面提到,在对文本处理时,卷积核的只从上到下滑动,所以卷积核的一个维度大小为embedding_num(此处为5)固定不变。样例中的卷积核有三种,分别是2x5,3x5,4x5尺寸的窗口,通过与输入矩阵进行卷积操作,得到卷积后的矩阵。
a. 卷积层由不同窗口大小的卷积核构成,窗口大小其实就是识别n-gram信息,卷积核大小对模型性能有较大影响;
b. 卷积核个数可以作为超参数,由自己定义,卷积核的数量对模型的性能有重要的影响,增加卷积核数量会增加模型的训练时间;
c. 同一个卷积核参数共享,可以极大减少参数个数,因为参数共享,所以一个卷积核只能提取同一类特征, 一个卷积核就是一类特征识别区;
确定output_channel的大小:样例中输出通道的大小为2,即每个尺寸的卷积核有两个,它们分别与输入矩阵进行卷积。
池化层:TextCNN中使用的最大池化,1-max pooling在卷积得到的矩阵中选择最大值代表该矩阵。
a. 平均池化(average pooling):平均池化就是对每个通道的所有数值求均值;
b. 最大池化(max pooling):最大池化就是对每个通道的所有数值求最大值;
c. 在TextCNN中1-max池化的性能优于其他池化策略。
拼接操作:将上一步各个矩阵池化后的结果进行拼接,作为最终分类的输入。
全连接层:根据池化层的输出和分类类别数量,构建全连接层,再经过softmax,得到最终的分类结果,torch.nn.Linear(input_num, num_class)即可定义全连接层。

















 1498
1498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









