






* model parameter != attention weight
全连接神经网络其实是学到了 l l l 层每个输入节点 对 l + 1 l+1 l+1 层每个输出节点的 ’ 加权求和 ‘的贡献比,每个边是一个权重也就是一个输入节点到一个输出节点的贡献
* GAT
GAT learns to assign varying levels of importance to nodes in every nodes neighborhood, rather than treating all neighboring nodes with equal importance, as is done in GCN.
A single GAT layer can be described as
e
i
j
=
a
(
W
x
i
,
W
x
j
)
e_{ij}=a(Wx_i,Wx_j)
eij=a(Wxi,Wxj)
- x i , x j x_i,x_j xi,xj are the node feature vectors(input node embeddings) for node i i i and j j j respectively.
- e i j e_{ij} eij is the attention value for the edge ( n o d e i , n o d e j ) (node_i,node_j) (nodei,nodej) between node i i i and j j j, which means the importance of the edge ( n o d e i , n o d e j ) (node_i,node_j) (nodei,nodej)'s features for the souce node i i i.
- W W W is a learnable parameterized linear transformation matrix
推荐阅读这篇论文

左边这个图就是想说,a的作用就是,下面的拼接的8个圈圈表示的向量,线性变换成一个值,这个值就是attention注意力(代表j->i这个边的重要性),
a.shape = (2(Wh).shape[1]* , 1)
对于一个节点,我们计算出它所有的边的注意力,然后softmax归一化就得到每个边的注意力权重alpha,
然后看右边的图,每个边的注意力权重*尾结点(Wh),然后求和
W 的作用就是对原始的节点特征input进行维度变换,W.shape=(node_feat, out_feat)
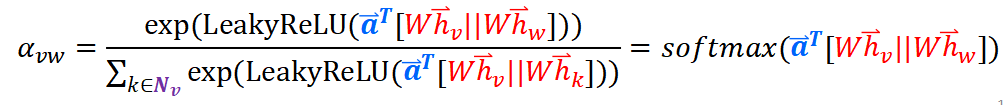


- 公式(1)对 l l l 层节点嵌入 h i ( l ) h_i^{(l)} hi(l)做了线性变换, W ( l ) W^{(l)} W(l)是该变换可训练的参数。
- 公式(2)计算了成对节点间的原始注意力分数。
- 它首先拼接了两个节点的 z z z 嵌入,注意 ∣ ∣ || ∣∣ 在这里表示拼接;
- 随后对拼接好的嵌入以及一个可学习的权重向量 a ⃗ ( l ) \vec a^{(l)} a(l) 做点积;
3/ 最后应用了一个LeakyReLU激活函数。这一形式的注意力机制通常被称为加性注意力,区别于Transformer里的点积注意力。
- 公式(3)对于一个节点所有入边得到的原始注意力分数应用了一个softmax操作,得到了注意力权重。
- 公式(4)形似GCN的节点特征更新规则,对所有邻节点的特征做了基于注意力的加权求和。
知乎好文 - 深入理解GAT

core codes in DGL
dgl.nn.pytorch.conv.GATconv
class GATconv(nn.Module):
def __init__(self, in_feats, out_feats, num_heads,feat_drop=0.,attn_drop=0., negative_slope=0.2,residual=False, activation=None,allow_zero_in_degree=False, bias=True):
super(GATConv, self).__init__()
......
if isinstance(in_feats, tuple):
self.fc_src = nn.Linear(self._in_src_feats, out_feats * num_heads, bias=False)
self.fc_dst = nn.Linear(self._in_dst_feats, out_feats * num_heads, bias=False)
else:
self.fc = nn.Linear(self._in_src_feats, out_feats * num_heads, bias=False)
### 划重点!!!注意这三个parameter是可学习的,dgl把 W*(h_i||h_j) 中的W参数拆成了两部分
### W = [attn_l || attn_r]
self.attn_l = nn.Parameter(th.FloatTensor(size=(1, num_heads, out_feats)))
self.attn_r = nn.Parameter(th.FloatTensor(size=(1, num_heads, out_feats)))
if bias:
self.bias = nn.Parameter(th.FloatTensor(size=(num_heads * out_feats,)))
else:
self.register_buffer('bias', None)
if residual:
if self._in_dst_feats != out_feats:
self.res_fc = nn.Linear(
self._in_dst_feats, num_heads * out_feats, bias=False)
else:
self.res_fc = Identity()
else:
self.register_buffer('res_fc', None)
self.feat_drop = nn.Dropout(feat_drop)
self.attn_drop = nn.Dropout(attn_drop)
self.leaky_relu = nn.LeakyReLU(negative_slope)
self.reset_parameters()
self.activation = activation

in torch
class GraphAttentionLayer(nn.Module):
"""
Simple GAT layer, similar to https://arxiv.org/abs/1710.10903
"""
def __init__(self, in_features, out_features, dropout, alpha, concat=True):
super(GraphAttentionLayer, self).__init__()
self.dropout = dropout
self.in_features = in_features
self.out_features = out_features
self.activation_alpha = alpha # Alpha for the leaky_relu.
self.concat = concat
self.W = nn.Parameter(torch.empty(size=(in_features, out_features)))
nn.init.xavier_uniform_(self.W.data, gain=1.414)
self.a = nn.Parameter(torch.empty(size=(2*out_features, 1))) # parameter for the all_combinations_matrix
nn.init.xavier_uniform_(self.a.data, gain=1.414)
self.leakyrelu = nn.LeakyReLU(self.activation_alpha)
def forward(self, h, adj): # (h=x, adj=adj)
# softmax[a(W*h_i||W*h_j)]
# h is the hidden feature vector of nodes
Wh = torch.mm(h, self.W) # h*W # h.shape: (N, in_features), Wh.shape: (N, out_features)
a_input = self._prepare_attentional_mechanism_input(Wh)
#a_input是N*N个边edge_emb=(node_i emb||node_j emb) ,i和j都取值1~N
# a_input.shape = (N, N, 2*out_features)
#self.alpha.size = (2*out_features, 1)
# matmul(a_input, self.alpha) -> shape=(N,N,1)
# toch.squeeze降维作用, 当给定dim时,那么挤压操作只在给定维度上。将输入张量shape中的1 去除并返回。
# 如果输入是形如(A×1×B×1×C×1×D),那么输出形状就为: (A×B×C×D)
emb = self.leakyrelu(torch.matmul(a_input, self.a).squeeze(dim=2))
# (Wh)*a, edgeij_emb=(node_i emb || node_j emb), 乘self.a后维度变为(N,N,1),
# squezze后变成(N,N)
# emb.shape = (N,N), 现在的emb存储的是
zero_vec = -9e15*torch.ones_like(emb)
# torch.where(): 合并emb和zero_vec,adj>0(有edge)的地方对应的edge emb不变,还是等于(node_i emb || node_j emb)。
#^ 下面这句的作用是,通过adj找出存在的边,
# 若边存在(adj>0),则edgeij_emb=(node_i emb || node_j emb),
# 若不存在(adj=0),则edge_emb=0。
# adj_ij==0的两节点i和j不是邻居节点,他们间没有边,
# thus the edge embedding concatted by node i emb and node j emb should be zero,
# 也就是 edge_ij=(emb_i||emb_j) should be 0.
# 也相当于将adj中为1的元素变成了edgeij_emb(此时每个edge_emb是一个标量)
attention = torch.where(adj > 0, emb, zero_vec) #^ 将没有边的attention值置零
attention = F.softmax(attention, dim=1) #^ 逐行计算,每一列相加求weights,每行的weights之和为1
attention = F.dropout(attention, self.dropout, training=self.training)
h_prime = torch.matmul(attention, Wh) #(N,N).matmul(N, out_features)
if self.concat:
return F.elu(h_prime)
else:
return h_prime
def _prepare_attentional_mechanism_input(self, Wh):
N = Wh.size()[0] # number of nodes
# Below, two matrices are created that contain embeddings in their rows in different orders.
# (e stands for embedding)
# These are the rows of the first matrix (Wh_repeated_in_chunks):
# e1, e1, ..., e1, e2, e2, ..., e2, ..., eN, eN, ..., eN
# '-------------' -> N times '-------------' -> N times '-------------' -> N times
#
# These are the rows of the second matrix (Wh_repeated_alternating):
# e1, e2, ..., eN, e1, e2, ..., eN, ..., e1, e2, ..., eN
# '----------------------------------------------------' -> N times
#
#Wh_repeated_in_chunks(N*N, out_features) Wh is duplicated N times at dim=0
Wh_repeated_in_chunks = Wh.repeat_interleave(N, dim=0)
Wh_repeated_alternating = Wh.repeat(N, 1)
# Wh_repeated_in_chunks.shape == Wh_repeated_alternating.shape == (N * N, out_features)
# The all_combination_matrix, created below, will look like this (|| denotes concatenation):
# 每一个行都是边,由节点u的emb与节点v的emb拼接cat而成,把所有的节点全部拼起来不管都没有变,总共可能存在N*N个edge的emb
# e1 || e1
# e1 || e2
# e1 || e3
# ...
# e1 || eN
# e2 || e1
# e2 || e2
# e2 || e3
# ...
# e2 || eN
# ...
# eN || e1
# eN || e2
# eN || e3
# ...
# eN || eN
all_combinations_matrix = torch.cat([Wh_repeated_in_chunks, Wh_repeated_alternating], dim=1)
# all_combinations_matrix.shape == (N * N, 2 * out_features)
output = all_combinations_matrix.view(N, N, 2 * self.out_features)
# output.shape == (N, N, 2*out_features)
return output
















 2669
2669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









