









基础环境搭建
手把手带小白用VMware虚拟机安装Linux centos7系统
Hadoop集群搭建及配置〇 —— Hadoop组件获取 & 传输文件
Hadoop集群搭建及配置⑤ —— Zookeeper 讲解及安装
Hadoop集群搭建及配置⑥ —— Hadoop组件安装及配置
Hadoop集群搭建及配置⑦—— Spark&Scala安装配置
1.1 修改主机名(三个节点都要)
本次集群搭建共有三个节点,包括一个主节点master,和两个从节点slave1和slave2。具体操作如下:
1.以主机点master为例,首次切换到root用户:su
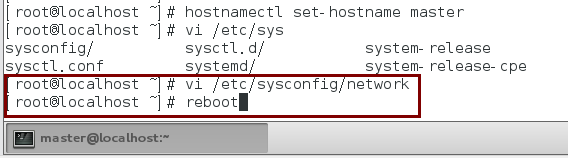
2.修改主机名为master:
hostnamectl set-hostname <hostsname>
例: hostnamectl set-hostname master
3.永久修改主机名,编辑/etc/sysconfig/network文件,内容如下:
NETWORKING=yes
HOSTNAME=master
保存该文件,重启计算机:reboot
查看是否生效:hostname

可以看到主机名字变为master。(记得三个节点都改为相对应的名字)
1.2 配置hosts文件
使各个节点能使用对应的节点主机名连接对应的地址。
hosts文件主要用于确定每个结点的IP地址,方便后续各结点能快速查到并访问。在上述3个虚机结点上均需要配置此文件。由于需要确定每个结点的IP地址,所以在配置hosts文件之前需要先查看当前虚机结点的IP地址是多少
- 1.可以通过ifconfig命令进行查看。
- 2.查看节点地址之后将三个节点的ip地址以及其对应的名称写进hosts文件。这里我们设置为 master、slave1、slave2。注意保存退出。
vi /etc/hosts
# ip 映射
192.168.142.128 master
192.168.142.129 slave1
192.168.142.130 slave2

1.3 永久关闭防火墙
centos7中防火墙命令用firewalld取代了iptables,当其状态是dead时,即防火墙关闭。
- 关闭防火墙:systemctl stop firewalld
- 查看状态:systemctl status firewalld
- systemctl disable firewalld.service # 禁止firewall开机启动
- systemctl start firewalld.service# 启动firewall


1.4 时间同步
1.4.1 时区一致
要保证设置主机时间准确,每台机器时区必须一致。实验中我们需要同步网络时间,因此要首先选择一样的时区。先确保时区一样,否则同步以后时间也是有时区差。可以使用date查看自己的机器时间。
1.4.2 选择时区:tzselect
由于hadoop集群对时间要求很高,所以集群内主机要经常同步。我们使用ntp进行时间同步,master作为ntp服务器,其余的当做ntp客户端。
(master)时间同步 tzselect 5 9 1 1

1.4.3 下载ntp
NTP是网络时间协议(Network Time Protocol),它是用来同步网络中各个计算机的时间的协议。
yum install –y ntp
master作为ntp服务器,修改ntp配置文件。(仅master上执行)
vi /etc/ntp.conf
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10


分别在slavel、 slave2中配置NTP,同样修改 /etc/ntp.conf 文件,注释掉server开头的行,并添加一行:server master 内容。

三个节点:
-
开机永久、启动ntp服务
systemctl restart ntpd.service & systemctl enable ntpd.service -
查看服务器状态
service status ntpd

其他机器同步(slave1,slave2)ntpdate master

1.5 配置SSH免密码登录
SSH主要通过RSA算法来产生公钥与私钥,在数据传输过程中对数据进行加密来保障数据的安全性和可靠性,公钥部分是公共部分,网络上任一结点均可以访问,私钥主要用于对数据进行加密,以防他人盗取数据。总而言之,这是一种非对称算法,想要破解还是非常有难度的。
Hadoop集群的各个结点之间需要进行数据的访问,被访问的结点对于访问用户结点的可靠性必须进行验证,hadoop采用的是ssh的方法通过密钥验证及数据加解密的方式进行远程安全登录操作,当然,如果hadoop对每个结点的访问均需要进行验证,其效率将会大大降低,所以才需要配置SSH免密码的方法直接远程连入被访问结点,这样将大大提高访问效率。
- 每个结点分别产生公私密钥:ssh-keygen -t dsa -P ‘’ -f ~/.ssh/id_dsa(三个节点)
秘钥产生目录在用户主目录下的.ssh目录中,进入相应目录查看:cd .ssh/
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa(三个集群)
cd ~/.ssh

id_rsa.pub为公钥,id_rsa为私钥,紧接着将公钥文件复制成authorized_keys文件:(仅master)
cat id_rsa.pub >> authorized_keys(注意在 .ssh /路径下操作)
ssh master

2. 让主结点master能通过SSH免密码登录两个子结点slave。(slave中操作)为了实现这个功能,两个slave结点的公钥文件中必须要包含主结点的公钥信息,这样当master就可以顺利安全地访问这两个slave结点了。
slave1结点通过scp命令远程登录master结点,并复制master的公钥文件到当前的目录下,且重命名为master_das.pub,这一过程需要密码验证。
salve中把master结点的公钥文件追加至authorized_keys文件。

配置SSH免密码登录
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa(三个集群)
cd ~/.ssh
cat id_rsa.pub >> authorized_keys(仅master)
ssh master 登出
scp master:~/.ssh/id_rsa.pub ./master_ras.pub(slave操作)
cat master_ras.pub >> authorized_keys
ssh slave1/slave2 (在master)

连接成功!!
















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











