







自1960 年第一颗美国气象卫星成功发射至今,遥感技术迅速发展,地球轨道上充满了全球尺度的各种各样的对地观测卫星,人类已有近半个世纪历史遥感数据积累。随着高分辨率对地观测时代的来临,遥感平台和传感器的不断改进和增加使得各种遥感数据量快速增加,空间分辨率、时间分辨率、光谱分辨率等技术指标不断提高,在数据层面上已经表现出体量大 (Volume)、种类多 (Variety)、 变 化 快 (Velocity)、 准 确 性(Veracity) 和高价值 (Value) 的“5V”特征,我们进入了一个前所未有的遥感大数据时代。遥感数据量的急剧增长,遥感数据多样化和复杂性的增加,使得遥感数据实时处理的需求日益突出,这些对于传统的遥感数据存储和处理提出了挑战。
遥感云计算技术的发展和平台的出现为遥感大数据处理和分析提供了前所未有的机遇,具体表现为:1) 云端有海量数据资源,无需下载到本地处理;2) 云端提供批量和交互式的大数据计算服务;3) 云端提供应用程序接口 API (Application Programming Interface),无需在本地安装软件。这彻底改变了传统遥感数据本地下载、处理与分析的模式,进一步降低了使用遥感数据的准入门槛,极大提高了运算效率,加速了算法测试的迭代过程,使得原本在台式机或服务器上难以实现的全球尺度地球系统科学快速分析和应用成为可能。
云平台是支撑一切云计算服务的基础架构,在计算机网络的基础上提供各种计算资源的统一管理和动态分配,达到实现云计算的目的。从服务模式上看,云分为公有云、私有云和混合云,遥感云计算平台也可分为公有云平台、私有云平台和混合云平台。Python作为一门开源、跨平台的语言,具有可移植性高、可扩展性强以及丰富的第三方库的特点,在大数据处理、云计算等方面有着无与伦比的优势,例如目前非常流行的云计算框架OpenStack就是基于Python开发的、谷歌应用引擎(Google APP Engine)也是围绕Python构建的,此外,遥感云计算平台也常常将Python作为其应用程序接口。
本文将对一些常用的遥感云计算平台进行简要的介绍,并以公有云平台中发展最为成熟的Google Earth Engine为例演示演示Python在遥感大数据和云计算中的应用。需要强调的是,JavaScript版的Earth Engine的API学习是其他知识的基础,且Earth Engine官方并未提供Python版的API接口文档,读者可以直接类比JavaScript版的API来深入学习Python版的API。
1 遥感云计算平台介绍与比对
1.1 公有云平台
公有云是最常见的云计算部署类型。公有云资源(例如服务器和存储空间)由第三方云服务提供商拥有和运营,这些资源通过网络提供给用户服务。在公有云中,所有硬件、软件和其他支持性基础结构均为云提供商所拥有和管理。基于公有云的遥感云计算平台主要以美国谷歌地球引擎 GEE (Google Earth Engine)(Gorelick 等,2017)发展比较成熟,已经得到广泛应用,此外还有笛卡尔实验室的Descartes Labs、亚马逊的Amazon Web Services、微软的Microsoft Planetary Computer等;中国遥感云计算平台的建设也在快速推进中,如面向中科院A类先导专项“地球大数据科学工程”需求研发的地球大数据挖掘分析平台EarthDataMiner、航天宏图的遥感计算云服务平台 Pixel Information Expert(PIE) - Engine,均已取得了重要进展。
| 遥感云计算平台 | 厂商 | 可用数据集 | API | 技术特点 |
|---|---|---|---|---|
| Google Earth Engine | 谷歌(美国) | 遥感影像数据,地形数据,土地覆被数据,天气、降雨和大气数据,人口数据,部分矢量数据等 | JavaScript,Python | 数据丰富、算法高集成度以及可定制性、便于分享等,但在中国大陆没有服务器 |
| Descartes Labs | 笛卡尔实验室(美国) | 遥感影像数据、大气数据、SAR数据、高程数据、水文数据、地理位置/AIS数据,土地利用数据等 | Python | 与机器学习结合性高、跨行业的解决方案等,主要用于商用 |
| Amazon Web Services | 亚马逊(美国) | Landsat 8,Sentinel 1/2,中巴地球资源卫星(CBERS)数据,OpenStreetMap数据等 | C++,Go,Java,JavaScript,.NET,Node.js,PHP,Python,Ruby | 支持用户构建容器镜像、提供AWS Ground Station(卫星接受地面站)云服务 |
| Microsoft Planetary Computer | 微软(美国) | 遥感影像数据,地形数据,土地覆被数据,气象气候数据,人口数据,环境数据等 | JavaScript,Python,R | 注重气候变化和地球保护、仍处于内测阶段 |
| EarthDataMiner | 中国科学院(中国) | 卫星遥感数据,生物生态数据,大气海洋数据,基础地理数据及地面观测数据;地层学与古生物数据、中国生物物种名录、微生物资源数据、组学数据 | Python | 国产自研可控、包含众多国产遥感数据集,目前只对专项内部成员开放测试 |
| PIE-Engine | 航天宏图(中国) | 高分数据,风云数据,Landsat,Sentinel 1/2,Modis,葵花-8数据集 | JavaScript,Python | 国产自研可控、包含众多国产遥感数据集 |
超算作为计算研究的基础,服务国家重大科研项目,也服务教育、气象、海洋、人工智能、生物信息等应用领域的科学研究。随着“云计算”的发展,“超算”和“云计算”相结合,市场上诞生了“超算云”这个“新产品”。“超算云”服务,帮助用户更好、更方便地使用超算资源,成本相比过去也大幅降低。超算云平台也是遥感云计算常用的公有云平台之一,但与上述遥感云计算平台不同,超算云平台能为用户提供更为灵活自主的遥感云计算服务。如北京航天泰坦科技服务有限公司面向测绘与遥感数据生产的网络化分布式处理平台——泰坦超算平台(Titan SCP),其采用国际先进的调度和计算工作流技术,集成多星多传感器的联合区域网平差、高精度DSM自动提取、海量影像镶嵌等多个先进处理算法,支持国内外主流航空航天遥感影像,如GF、ZY02C、ZY-3、QuickBird、IKONOS、SPOT、WorldView等卫星影像及常规数码相机、框幅式相机、推扫式相机等航空影像。此外,国内的超算云平台还有国家超算中心、北京超级云计算服务平台、北鲲云超算云平台等。一般来说,超算中心的资源会优先供给科研项目,因此对高校用户较为友好,商业用户的优先级则相对较低。
1.2 私有云平台
私有云由专供一个企业或组织使用的云计算资源构成。私有云可在物理上位于组织的现场数据中心,也可由第三方服务提供商托管。但是,在私有云中,服务和基础结构始终在私有网络上进行维护,硬件和软件专供组织使用。遥感影像数据存储在公有云中势必会有数据安全性的隐患,因而构建一个私有云,用于存储遥感影像是十分必要的。不仅保证了数据的安全性,也使用户有了更多自主权。因此,基于私有云的遥感云计算平台可使组织更加方便地自定义资源,从而满足特定的需求,其使用对象通常为政府机构、金融机构以及其他具备业务关键性运营且希望对环境拥有更大控制权的中型到大型组织。很多高校和科研院所会有其自建的超算云平台,规模相对较小且一般不对外服务,因此也可将其归为私有云平台。
1.3 混合云平台
混合云平台是公有云和私有云的一个混合体,它将本地基础结构(或私有云)与公有云结合在一起,可以在两种环境之间移动数据和应用公共可以对外开放的内容放在公共网络上,相关保密内容只存放在私有云中。基于混合云的遥感云计算平台能够为用户提供更大的灵活性、更多的部署选项、更高的安全性和符合性,例如华为依托于华为云在人工智能、大数据等前沿技术的积累,构建的一站式全流程遥感智能开发云平台——地理智能体(GeoGenius),能够根据客户条件、建设目标、实施阶段等差异,提供公有云、混合云和多云协同的灵活部署能力。
2 Earth Engine Python API的应用示例
作为目前最火的编程语言,Google Earth Engine官方也为Python提供了一套API接口。通过这套API接口,开发者可以自由调用Earth Engine在线服务,实现遥感影像相关处理操作,还能结合目前非常流行的机器学习框架Tensorflow开展机器学习方面的操作。
2.1 环境配置
目前,虽然官方提供了Python版的API接口,但是在线的编辑器Code Editor只支持JavaScript版的API,所以如果想要学习或者使用Python版的API,第一步需要配置开发环境。
Earth Engine官方提供的配置方式主要有两种:1)使用Google Drive中的在线版的Google Colab,2)配置本地的Earth Engine开发环境。由于 GEE 在中国大陆没有服务器,本地配置容易受网络原因等限制,经常出现无法配置成功的情况,因此本书使用在线版的Google Colab作为开发环境进行教学演示.
2.1.1 在线Colab配置
1)登录Google Drive并关联Colab
Colaboratory (简称Colab)是Google Drive的一个关联应用,,旨在帮助传播机器学习培训和研究成果。它是一个 Jupyter 笔记本环境,不需要进行任何设置就可以使用,并且完全在云端运行和存储。关联Colab首先要注册谷歌云盘账号,进入谷歌云盘,依次点击New->More->Connect more apps,找到Google Colaboratory点击安装即可。
2)在Colab中新建文件
在Google Drive中,依次点击 New->More->Google Colaboratory,即可新建一个 Jupyter 笔记本(文件后缀名为.ipynb)。
2.1.2 Colab使用简介
1)导入Python版本API并获取授权
Google Colaboratory中默认安装了Earth Engine API,所以只需要导入并验证即可使用。但需要注意的是,每次打开或重启Colab内核,Google后台都会启动新的虚拟机器,所以每个新的Colab会话都必须运行一遍如下步骤:
# 导入API
import ee
# 验证身份信息
ee.Authenticate()
# 初始化
ee.Initialize()
上面的代码运行成功后便可以在Colab中使用Earth Engine Python API了,测试代码如下:
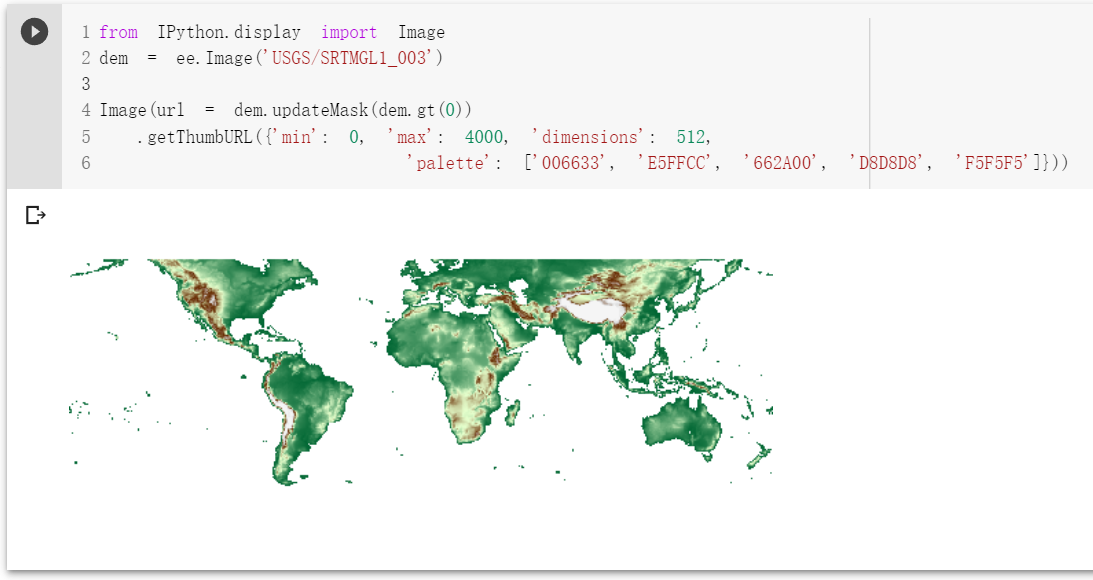
from IPython.display import Image
dem = ee.Image('USGS/SRTMGL1_003')
Image(url = dem.updateMask(dem.gt(0))\
.getThumbURL({'min': 0, 'max': 4000, 'dimensions': 512,
'palette': ['006633', 'E5FFCC', '662A00', 'D8D8D8', 'F5F5F5']}))
运行结果见下图:
2)Colab挂载Google Drive
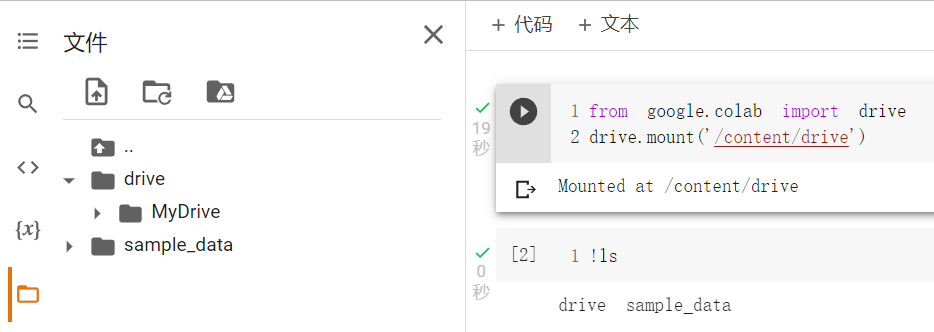
在 打开的Jupyter 笔记本插入一个代码块,执行以下代码。执行后会弹出一个网址和一个输入框,点击网址获取验证码,复制到输入框中点击回车即可。当前目录下的drive目录中的MyDrive目录就是Google Drive中的内容,可以像操作硬盘一样操作该目录。
from google.colab import drive
drive.mount('/content/drive')
运行结果见下图:
2.2 地图可视化
Colab中地图可视化的方式可分为两种,一种是静态图片展示,另一种是交互式地图展示,下面依次介绍这两种地图可视化方式。
2.2.1 静态图片展示
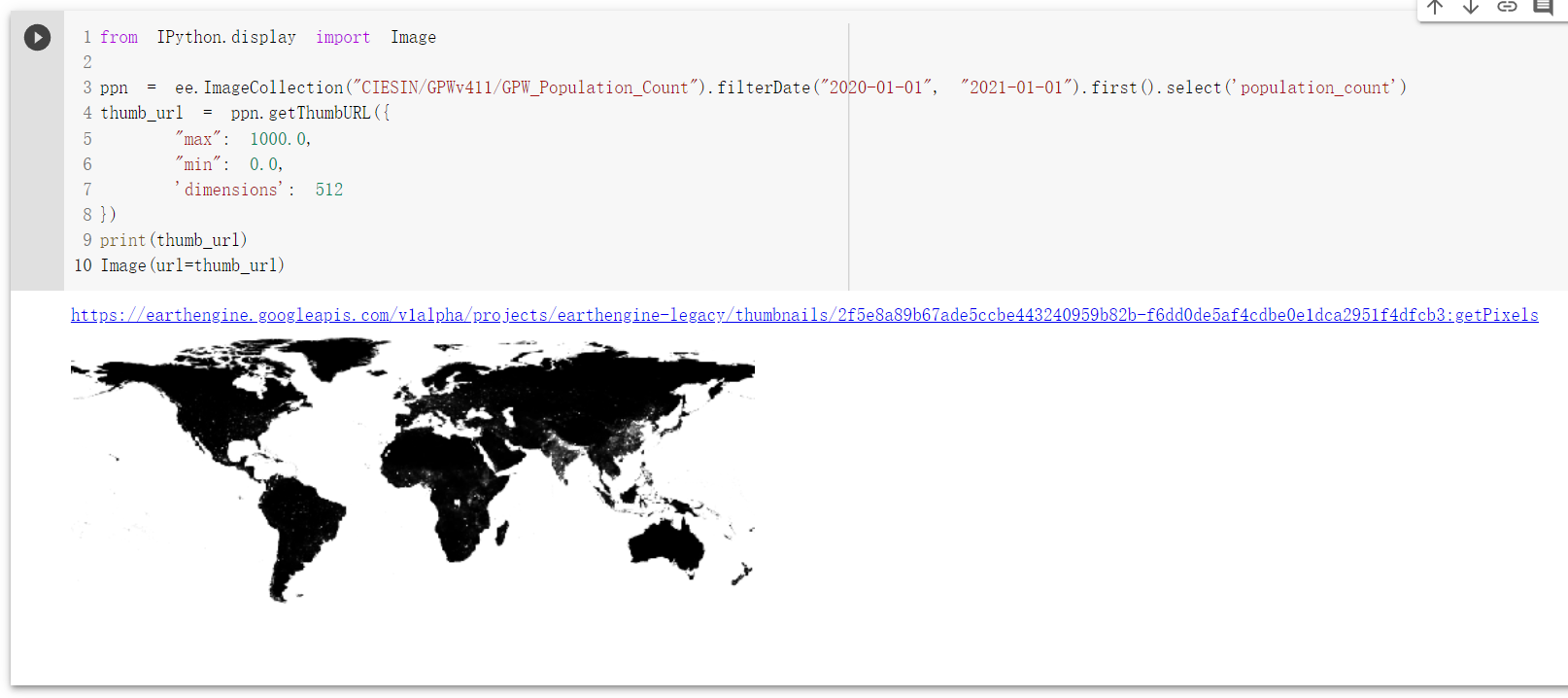
这种方式是使用IPython.display模块中的Image函数展示地图数据,展示的地图数据是由Earth Engine提供的生成缩略图的方法getThumbURL(),具体代码如下所示:
from IPython.display import Image
ppn = ee.ImageCollection("CIESIN/GPWv411/GPW_Population_Count")
.filterDate("2020-01-01", "2021-01-01")
.select('population_count').first()
thumb_url = ppn.getThumbURL({
"max": 1000.0,
"min": 0.0,
'dimensions': 512
})
print(thumb_url)
Image(url=thumb_url)
运行结果见下图:
2.2.2 交互式地图展示
Earth Engine的官方文档中使用第三方开源库folium在交互式Leaflet地图上展示ee.Image对象,但Folium没有用于处理来自Earth Engine的瓦片的默认方法,使用起来较为不便。因此,本文使用另外一个第三方开源库geemap进行交互式地图展示。geemap不是Colab默认库,需要先安装才能使用。安装geemap十分简单,只需要使用!pip install geemap安装即可。使用例子如下:
1 导入所需的库:
import ee
import geemap
2 创建交互式地图:
Map = geemap.Map(center=(30, 110), zoom=3)
Map
运行结果见下图:

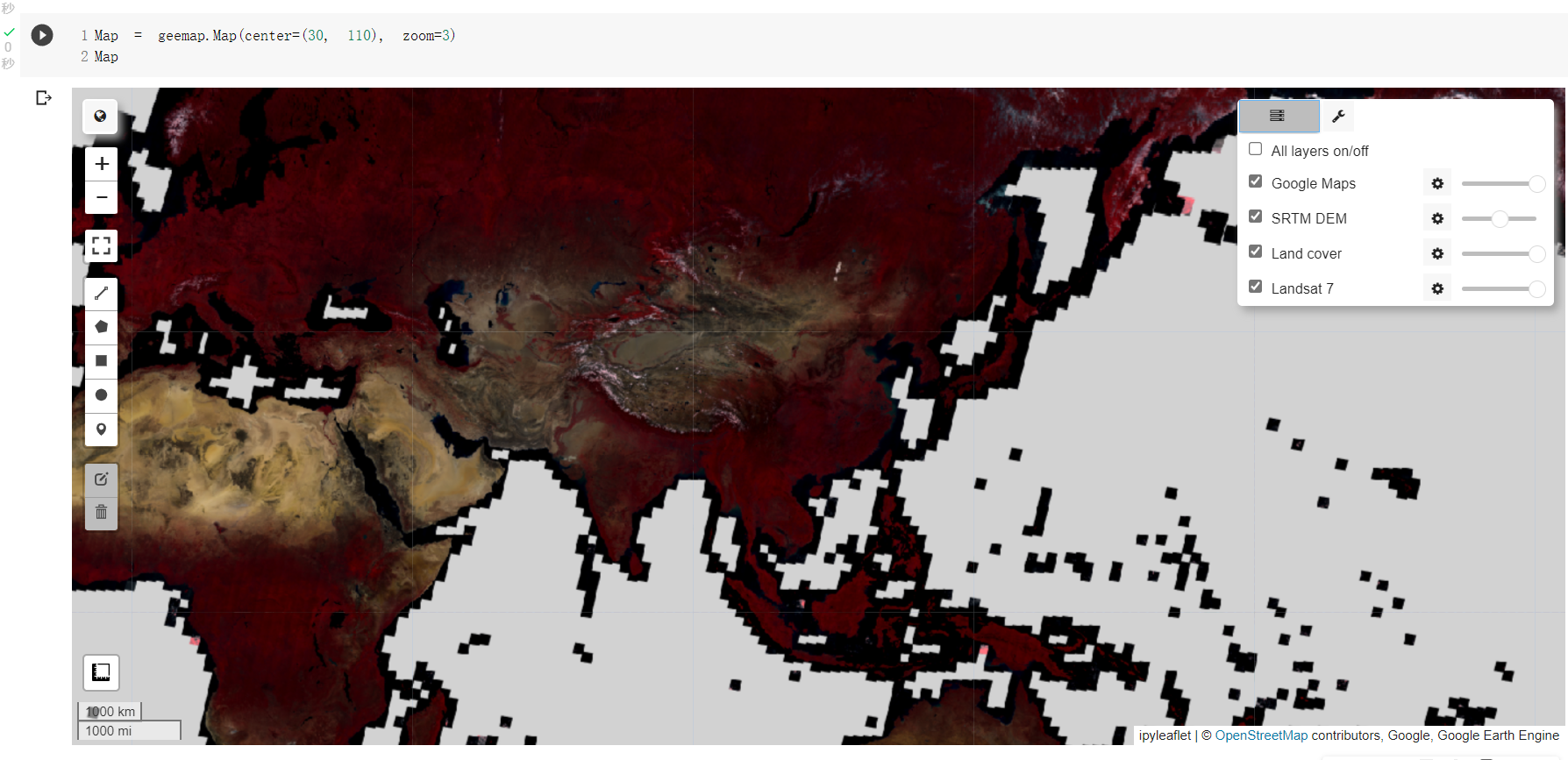
3 添加Earth Engine数据
dem = ee.Image('USGS/SRTMGL1_003')
landcover = ee.Image("ESA/GLOBCOVER_L4_200901_200912_V2_3").select('landcover')
landsat7 = ee.Image('LE7_TOA_5YEAR/1999_2003')
4 设置可视化参数
dem_vis = {
'min': 0,
'max': 4000,
'palette': ['006633', 'E5FFCC', '662A00', 'D8D8D8', 'F5F5F5']}
landsat_vis = {
'min': 20,
'max': 200,
'bands': ['B4', 'B3', 'B2']
}
5 在交互式地图展示数据
Map.addLayer(dem, dem_vis, 'SRTM DEM', True, 0.5)
Map.addLayer(landcover, {}, 'Land cover')
Map.addLayer(landsat7, landsat_vis, 'Landsat 7')
运行结果见下图:
3 基于Earth Engine Python API的植被物候信息提取
物候是指生物受所处环境(气候、水文、土壤等)的影响而出现的以年为周期的有节律的自然现象,包括植物的发芽、展叶、开花、落叶等过程。在全球变化的大背景下,作为指示气候与自然环境变化并反映地表过程的重要指标,物候的研究极为重要。遥感观测技术以其覆盖广、观测时间长、周期性强、空间连续,且能够完整反映植被生长季变化过程及年际变化差异等特点,为物候观测提供了新的手段。通常,将单位时间、单位面积内植被通过光合作用吸收的CO2总量或固定的总能量定义为总初级生产力(gross pri-mary productivity,GPP)。GPP作为全球碳循环的最大组成通量,是生态系统碳循环的关键指标。通量观测数据能够描述年际间生长季长度的CO2通量变化及这种变化对生态系统过程的反馈作用,是大尺度物候气候变化响应研究的热点。
本文拟用GEE数据集中的MODIS-GPP数据产品(MOD17A2H.006,空间分辨率 0.0001°,时间分辨率 8 d)开展物候信息提取,演示Python在Google Earth Engine中的应用。
3.1 加载并显示GPP数据
首先新建一个Jupyter Notebook文件,并使用如下命令安装所需的第三方库。
!pip install geemap
导入所需的GEE并验证,同时导入所需的第三方库。
import ee
import os
import geemap
import geemap.colormaps as cm
# 验证身份信息
ee.Authenticate()
# 初始化
ee.Initialize()
使用geemap创建交互式地图,之后导入MOD17A2H.006数据产品,并将其可视化到交互式地图上。
Map = geemap.Map(center=(30, 110), zoom=4)
imCol = ee.ImageCollection('MODIS/006/MOD17A2H') \
.filterDate('2015-01-01', '2020-12-31') \
.select('Gpp')
# 将image collection转换为image.
image = imCol.toBands()
# 设置可视化参数
palette = cm.palettes.ndvi
gpp_vis = {
'min': 0.0,
'max': 1000.0,
'palette': palette
}
# 添加数据
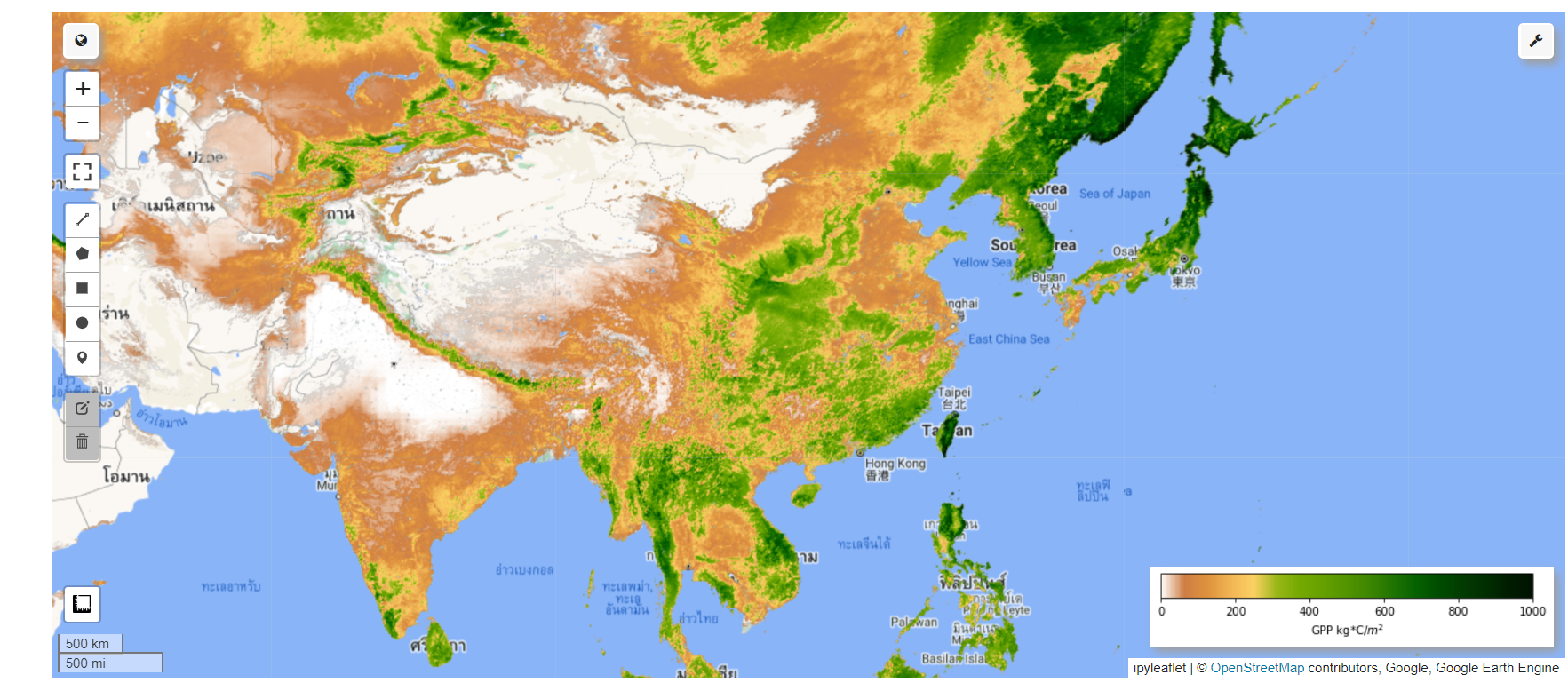
Map.addLayer(image, {}, 'MODIS GPP Time-series')
Map.addLayer(image.select(20), gpp_vis, 'MODIS GPP VIS')
# 设置绘图选项
Map.set_plot_options(add_marker_cluster=True, marker=None)
# 为交互式地图添加色带并在Jupyter Notebook中显示交互式地图
Map.add_colorbar(gpp_vis, label="GPP kg*C/$m^2$", layer_name='MODIS GPP VIS')
Map
运行结果如下图:
3.2 可视化并提取时间序列GPP值
通过上面的代码,我们已经成功创建了一个交互式地图,并MODIS-GPP产品进行了可视化展示。需要注意的是,我们向交互式地图中添加了两个图层,一个是包含筛选后的2015-01-01到2020-12-31所有期GPP数据的影像,其中每一期GPP数据都是该影像的一个波段;另一个是这个影像的第21个波段,也是筛选的第一期GPP数据,即上图中彩色可视化的影像。可以在交互式地图中滑动鼠标滚轮缩放地图,右击拖动地图。
可视化2015-01-01到2020-12-31长时间序列的GPP值需要geemap提供的Plotting工具,首先点击交互式地图右上角的Toolbar图标,在打开的工具列表中点击Plotting工具,在交互式地图中点击后便会在地图中显示一个点标记同时在右下角创建一个GPP随时间变化的折线图,如下图所示,还可多次点击查看不同位置GPP时间序列变化图。
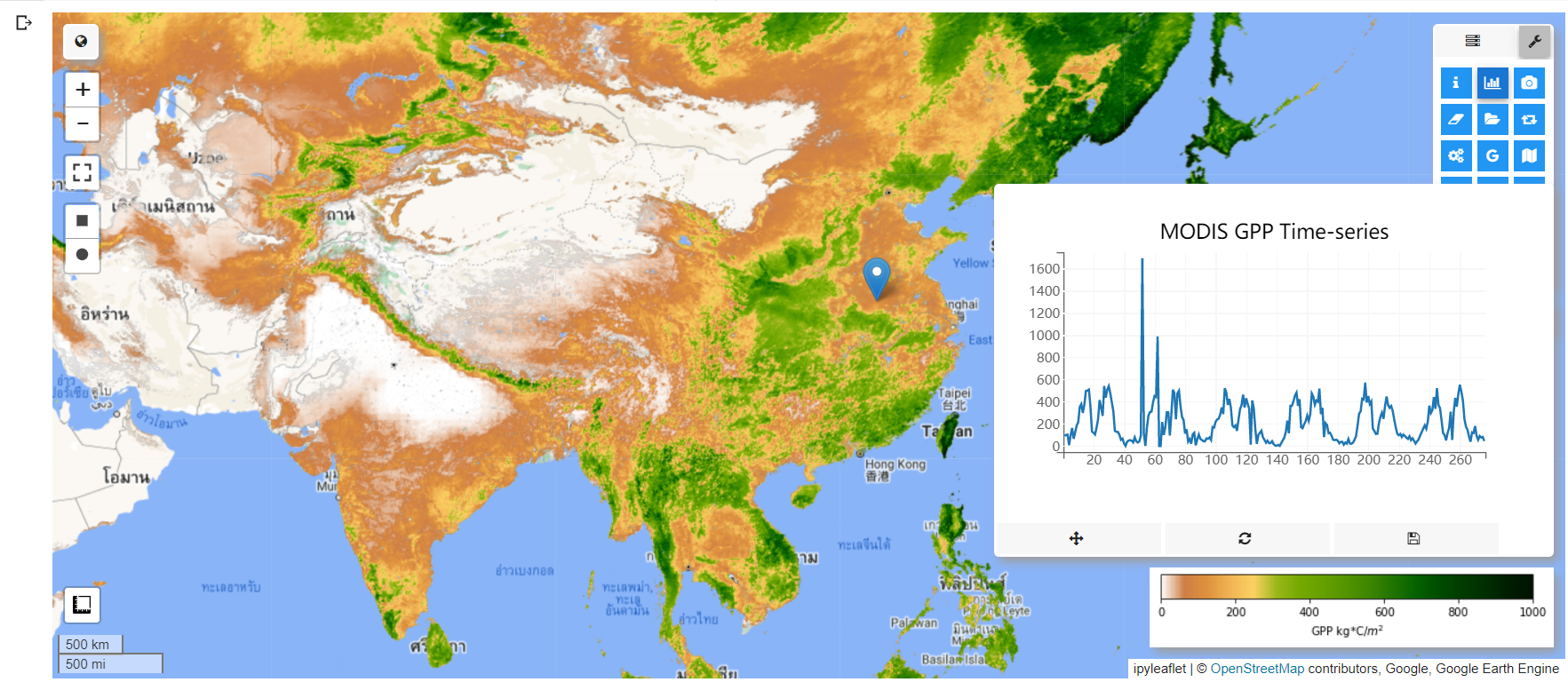
geemap会记录用户点击的所有的点,还可将各个点的像元值导出为csv或者shapefile格式的文件保存。这里我们将其导出为csv格式并保存,以便后续分析,导出代码如下。
# 设置文件导出路径为家目录
out_dir = os.path.expanduser('~')
out_csv = os.path.join(out_dir, 'points_gpp.csv')
Map.extract_values_to_points(out_csv)
3.3 GPP时间序列数据的平滑处理
受到传感器状态、大气干扰、地面状况等影响,GPP时序数列需要通过滤波算法或函数拟合的方法重建时序数列。Whittaker平滑基于补偿最小二乘原理,通过平衡保真度和粗糙度平滑时间序列,具有快速便捷、参数简单的特点。因此本文使用Whittaker平滑方法对GPP时间序列数据进行平滑处理,基于Python实现的Whittaker平滑代码如下。
import numpy as np
def ws(y, r=2, d=3):
"""Whittaker smooth function, returning a numpy array.
Args:
y (array_like): Long time series data to smooth.
r (int | float, optional): The weight of smopthing. Default to 2.
d (int, optional): The weight of roughness. Default to 3.
Raises:
ValueError: The range of valid values in the dataset is between 0 and 3000!
Returns:
ndarray: The Whittaker smooth result.
"""
y = np.array(y, dtype=np.float64)
if y[(y<0)|(y>3000)].size:
raise ValueError("The range of valid values in the dataset is between 0 and 3000!")
m = y.size
E = np.eye(m)
D = np.diff(E, n=d, axis=0)
t = E+r*np.dot(D.T, D)
z = np.dot(np.linalg.inv(t), y.T)
return z
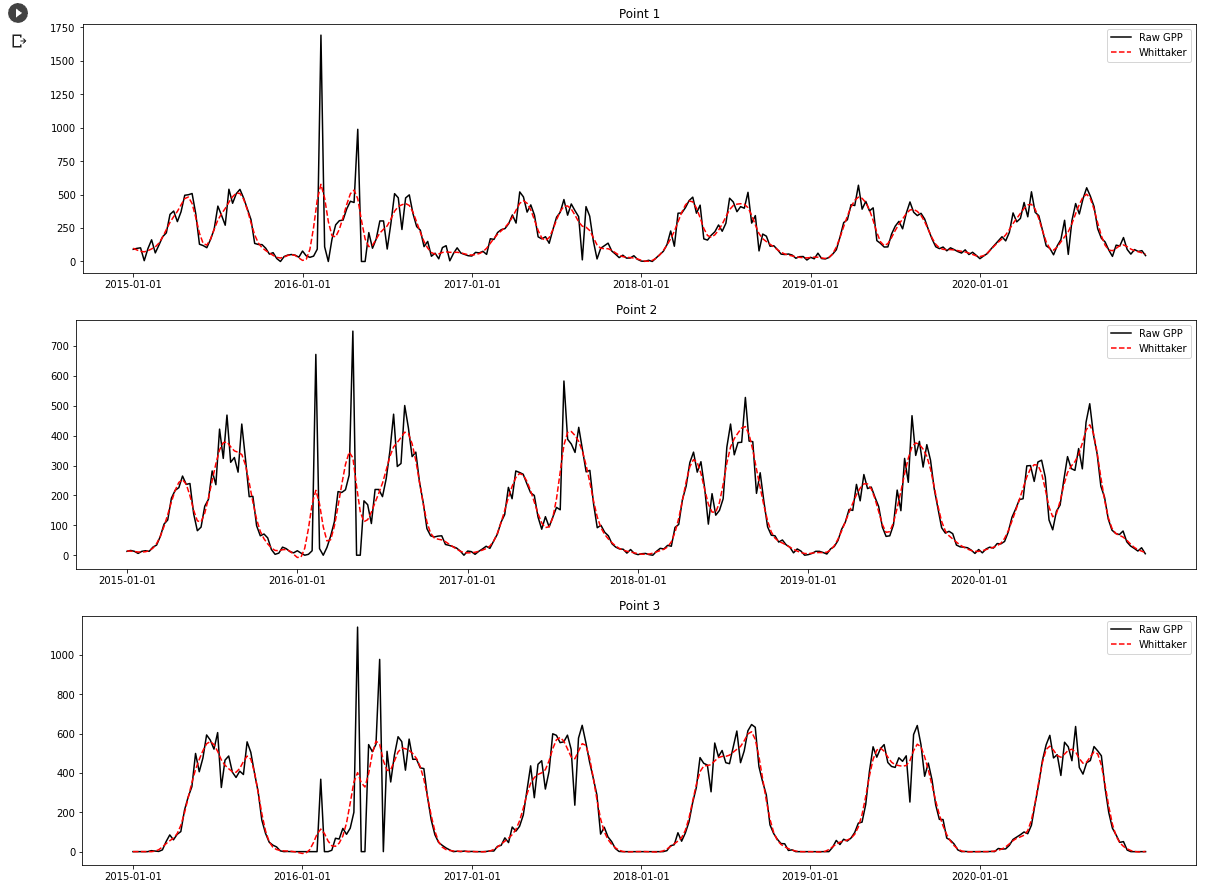
进而对上节提取的GPP数据进行平滑处理,同时可视化展示平滑结果,具体代码如下。
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('/root/points_gpp.csv')
for i in range(df.shape[0]):
id = df.loc[i, 'id']
point_gpp = df.iloc[i, 3:]
try:
smooth_point_gpp = ws(point_gpp)
except Exception as e:
print(e)
continue
plt.figure(figsize=(16, 4), constrained_layout=True)
plt.title("Point {}".format(id))
plt.plot(np.arange(len(point_gpp)), point_gpp, 'k-', label="Raw GPP")
plt.plot(np.arange(len(smooth_point_gpp)), smooth_point_gpp, 'r--', label="Whittaker")
plt.xticks(np.arange(len(point_gpp))[::46], ['2015-01-01', '2016-01-01', '2017-01-01', '2018-01-01', '2019-01-01', '2020-01-01'])
plt.legend()
运行结果如下图:
3.4 基于GPP时间序列数据分析的物候提取
季节性振幅法(Sa),又称动态阈值法,是指从基础水平开始计算,当拟合曲线的左半部分达到振幅指定的分数值,即定义为生长季开始;季节结束由拟合曲线的右半部分达到指定的分数值来定义。因此本文使用季节性振幅法来提取物候,基于Python实现的季节性振幅法代码如下。
import numpy as np
# 以下两函数用于计算任意两直线的交点
def calc_abc_from_line_2d(x0, y0, x1, y1):
# 给出两点坐标,计算其一般直线方程的a, b, c三个参数
a = y0 - y1
b = x1 - x0
c = x0*y1 - x1*y0
return a, b, c
def get_line_cross_point(line1, line2):
# 计算两条直线的交点
# line1 : list. eg: [x0, y0, x1, y1] 包含一条直线的两个点的坐标
a0, b0, c0 = calc_abc_from_line_2d(*line1)
a1, b1, c1 = calc_abc_from_line_2d(*line2)
D = a0 * b1 - a1 * b0
if D == 0:
return None
x = (b0 * c1 - b1 * c0) / D
y = (a1 * c0 - a0 * c1) / D
return x, y
def season_extract_by_sa(gpp_values, period, start_amplitude=0.2, end_amplitude=0.2):
"""Season extract function using sa, returning two numpy array.
Args:
gpp_values (array_like): Long time series data to smooth.
period (int): The period of gpp_values.
start_amplitude (float, optional): The start amplitude of sa. Default to 2.
end_amplitude (float, optional): The end amplitude of sa. Default to 2.
Raises:
ValueError: Period is wrong! OR start_amplitude | end_amplitude must between 0 and 1!
Returns:
(ndarray, ndarray): The satat and end season time.
reference:
IMESAT—a program for analyzing time-series of satellite sensor data
"""
# gpp_values: gpp
# period: 周期
# start_amplitude, end_amplitude分别表示季节开始和结束的振幅
length = gpp_values.size
if length%period:
raise ValueError("Period is wrong!")
# 振幅需在0和1之间
if start_amplitude>=1 or start_amplitude<=0:
raise ValueError("start_amplitude must between 0 and 1!")
if end_amplitude>=1 or end_amplitude<=0:
raise ValueError("end_amplitude must between 0 and 1!")
gpp_values = np.array(gpp_values, dtype=np.float64)
# 计算数据共有多少年
years = length//period
# 存放生长季开始结束时间的数组
start_ts = np.zeros(shape=(years, ))
end_ts = np.zeros(shape=(years, ))
# 逐年计算生长季开始结束时间
for year in range(years):
year_values = gpp_values[year*period:(year+1)*period]
max_arg = np.argmax(year_values)
left_min_arg = np.argmin(year_values[:max_arg])
start_x = left_min_arg+(max_arg-left_min_arg)*start_amplitude+period*year
x, y = get_line_cross_point([start_x, 0, start_x, gpp_values[max_arg]],
[int(start_x), gpp_values[int(start_x)], int(start_x)+1, gpp_values[int(start_x)+1]])
start_ts[year] = x
right_min_arg = np.argmin(year_values[max_arg:])
end_x = max_arg+right_min_arg-right_min_arg*end_amplitude + period*year
x, y = get_line_cross_point([end_x, 0, end_x, gpp_values[max_arg]],
[int(end_x), gpp_values[int(end_x)], int(end_x)+1, gpp_values[int(end_x)+1]])
end_ts[year] = x
return start_ts, end_ts
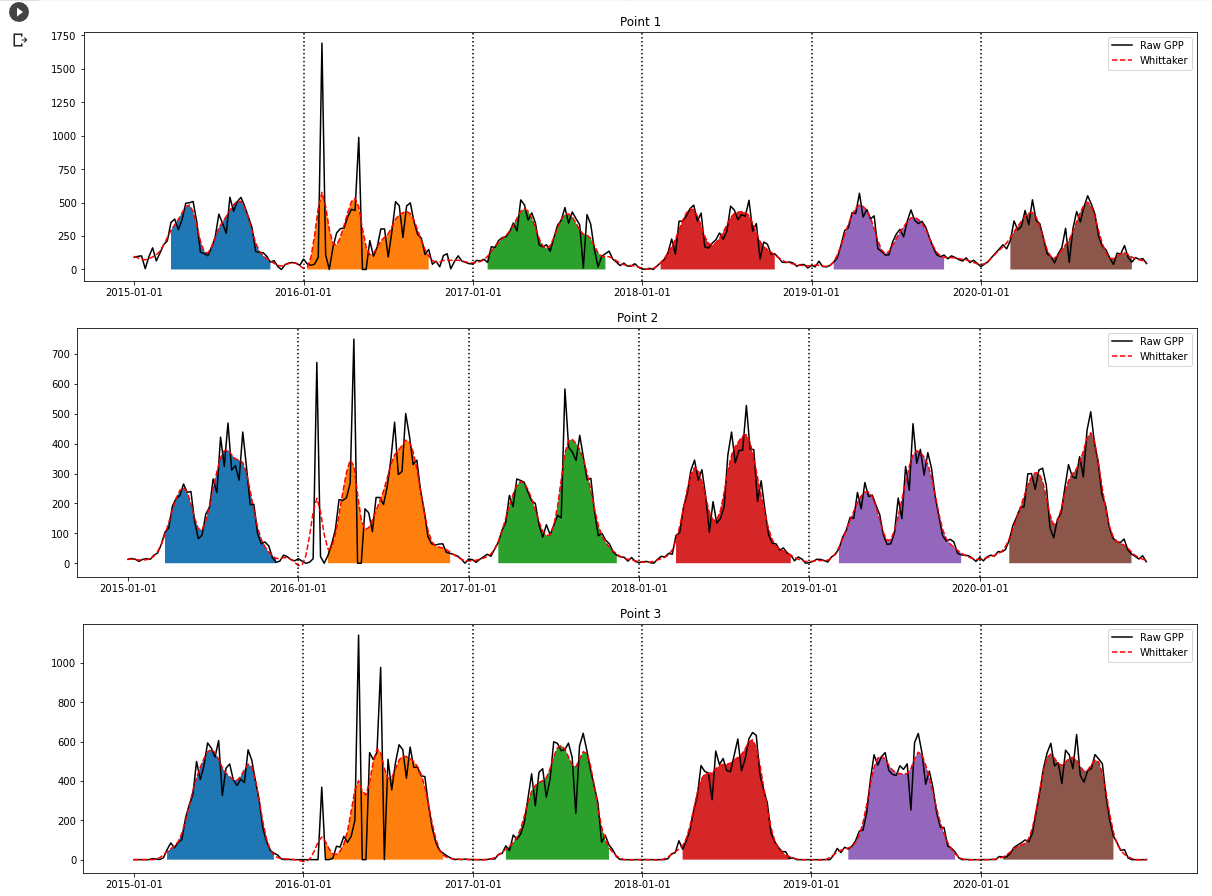
进而对上节平滑后的GPP数据进行季节提取,同时可视化展示季节提取结果,具体代码如下。
import pandas as pd
import matplotlib.pyplot as plt
def pretty_plot(x_positions, start_ts, end_ts, smooth_point_gpp):
for x_position in x_positions:
plt.axvline(x_position, ymin=0, ymax=smooth_point_gpp.max(), c='k', ls=':')
for start_t, end_t in zip(start_ts, end_ts):
x_range = np.arange(int(start_t), int(end_t)+2)
plt.fill_between(x_range, smooth_point_gpp[x_range])
df = pd.read_csv('/root/points_gpp.csv')
for i in range(df.shape[0]):
id = df.loc[i, 'id']
point_gpp = df.iloc[i, 3:]
try:
smooth_point_gpp = ws(point_gpp)
except Exception as e:
print(e)
continue
plt.figure(figsize=(16, 4), constrained_layout=True)
plt.title("Point {}".format(id))
plt.plot(np.arange(len(point_gpp)), point_gpp, 'k-', label="Raw GPP")
plt.plot(np.arange(len(smooth_point_gpp)), smooth_point_gpp, 'r--', label="Whittaker")
start_ts, end_ts = season_extract_by_sa(smooth_point_gpp, 46, 0.3, 0.3)
pretty_plot(np.arange(len(point_gpp))[::46][1:], start_ts, end_ts, smooth_point_gpp)
plt.xticks(np.arange(len(point_gpp))[::46], ['2015-01-01', '2016-01-01', '2017-01-01', '2018-01-01', '2019-01-01', '2020-01-01'])
plt.legend()
运行结果如下图:
学习更多GIS相关知识,请移步公众号GeodataAnalysis:
















 1448
1448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









