






一句话打头儿:为了优化计算资源消耗,更快、更高效,并且使用更少的资源,lgb诞生!
和xgboost一样同样是对gbdt的优化和更高效的实现,与xgboost主要的不同在对于连续值的直方图算法,和树生长策略的调整。Lightgbm的优点官方说法如下:
- 更快的训练速度
- 更低内存使用
- 更高的准确率
- 支持并行化学习
- 可处理大规模数据
- 支持直接使用category特征
1. 直方图算法
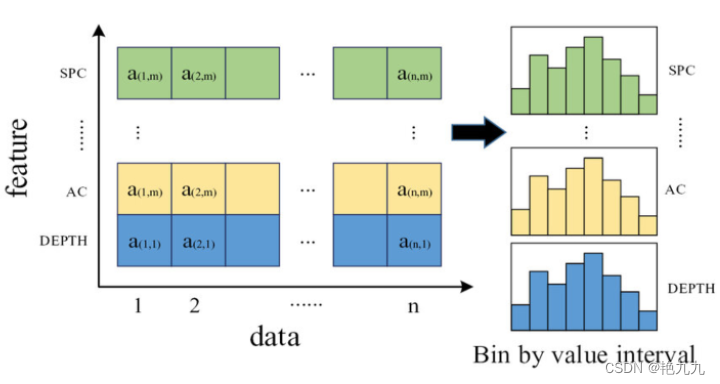
核心思想:
- 将连续的值离散成k个离散值,并构造宽度为k个直方图
- 遍历训练数据,统计每个离散值在直方图中的累积统计量
- 在进行特征选择时,只需要根据直方图的离散值,遍历寻找最佳分割点
2. 树的生长策略
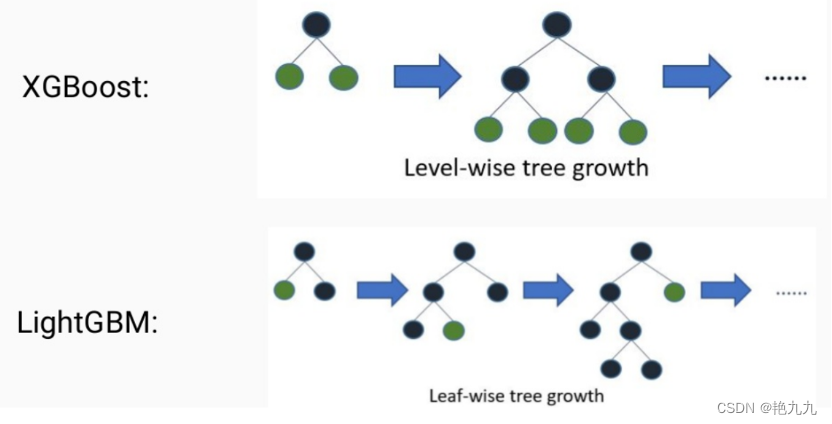
XGBoost采用的是按层生长的策略,能够同时分裂同一层的叶子,从而进行多线程优化,不容易过拟合。但很多叶子实际上分裂增益较低,没必要进行分裂,因此造成了不必要的计算开销。
LightGMB采用按叶子生长的策略,每次从当前所有叶子中找到分裂增益最大的(一般也是数据量最大的)一个叶子进行分裂,以此类推。这种方式可以降低更多的误差,得到更好的精度。
3. 构建过程
1. 设定初始预测:建立一个输出相同值的初始化模型。
对于回归问题,输出值可以为平均值
分类分体:输出值可以为最多的类别
2. 迭代构建弱学习器
1. 计算残差,(即预测值与真实值之间的差异,分类问题:计算损失函数的负梯度。
2. 将残差作为目标训练新决策树
训练树的过程:
1. 使用直方图将特征离散化(连续的特征值转换为离散的桶)
2. 采用叶子优先策略,通过直方图求和技术,快速找到最佳的分割点
3. 循环直到达到停止条件(如深度限制和其他约束)
3. 新决策树加入原有模型,更新模型预测
3. 重复步骤2直到停止(即满足停止条件,如n棵树)
4. LightGBM优点
- 高效:基于直方图的算法,可以减少计算时间和内存使用并且支持多核并行处理和 GPU 加速。
- 支持类别特征:能够直接处理类别特征。
- 叶子优先的分裂策略:与传统的深度优先或广度优先策略不同,LightGBM 采用叶子优先策略,这有助于获得更低的损失。
5. LightGBM缺点
- 对噪声和异常值敏感: 与其他基于树的方法一样都是基于偏差的算大,因此对噪声和异常值比较敏感。
- 可解释性较差: LightGBM 的模型通常被认为是黑盒模型,难以解释。虽然 LightGBM 提供了一些特征重要性的指标,但是解释模型的决策过程仍然比较困难。














 2618
2618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









