






 本文介绍了CatBoost,一种在GBDT基础上改进的算法,重点解决了类别型特征处理、预测偏移和内存效率问题。通过OrderedTS和OrderedBoosting,它提供了高效且无偏的预测。尽管模型精度高,但可能对随机数设置敏感且训练调参时间较长。
本文介绍了CatBoost,一种在GBDT基础上改进的算法,重点解决了类别型特征处理、预测偏移和内存效率问题。通过OrderedTS和OrderedBoosting,它提供了高效且无偏的预测。尽管模型精度高,但可能对随机数设置敏感且训练调参时间较长。
目录
一句话概括:Category + boosting = CatBoost
CatBoost依然是在GBDT算法框架下的一种改进实现,主要解决的痛点是高效合理地处理类别型特征,另外是处理预测偏移问题(预测偏离在于类别特征编码和梯度提升方法)
1. 类别特征编码
对于categorical数据,类别特征编码说白了就是用一个数字合理代替类别。
- 回顾之前的算法是如何处理类别特征的
- GBDT:直接把类别型当作连续型数据对待。
- XGBoost:对类别特征One-hot编码后再输入模型。
- LightGBM:在每步梯度提升下,将类别特征转为GS (梯度统计Gradient Statistics)。
虽然LGBM用GS编码类别特征挺厉害的,但是存在两个问题:
- 计算时间长:因为每轮都要为每个类别值进行GS计算。
- 内存消耗大:对于每次分裂,都存储给定类别特征下,它不同样本划分到不同叶节点的索引信息。
为了克服以上问题,LGBM将长尾特征聚集到一类,但也因此丢失了部分信息。对此,Catboost作者认为,LGBM的GS没有TS好,因为TS省空间且速度快,每个类别存一个数就好了。那么什么是TS呢?
2. Greedy TS
Greedy TS使用平均值作为分裂标准.
- 举个例子

但是,greedy TS会存在潜在问题
1. 计算时使用当前特征,因此会造成目标泄漏,预测漂移
2. train/test 数不一样
因此Greedy TS并不完美,所以Catboost作者受到在线学习算法 (即随时间变化不断获取训练集) 的启发,提出了Ordered TS。
3. Ordered TS
具体步骤如下:
(1) 随机打乱训练集,获取一个随机排列顺序
(2) 在训练集中,计算样本Ordered TS
(3) 在测试集中,用全测试集数据去计算Greedy TS


这样即充分的使用了数据,又避免了目标泄漏。
4. Ordered Boosting
CatBoost 另一个处理预测偏移问题的解决方法在于使用ordered boosting作为梯度提升方法,他与传统的梯度提升区别在于对残差的计算方法不同。

传统残差计算:当前残差等于实际值减上一轮预测值,上一轮用来预测的模型是用全部数据集训练的,所以容易预测偏移。
排序提升残差计算:基于排序提升原则去计算,当前样本残差是用前面样本训练得到的模型预测值与样本真实值做差,这样的话,样本残差计算没有让自身参与进去,避免了预测偏移得到无偏残差。
5. 对称树
Catboost是用对称树 (Oblivious Decision Tree) 作为弱学习器,树的分裂从信息增益最大的特征开始分裂,每一层使用相同的分裂标准,因此不易过拟合,且能显著加速测试执行时间。
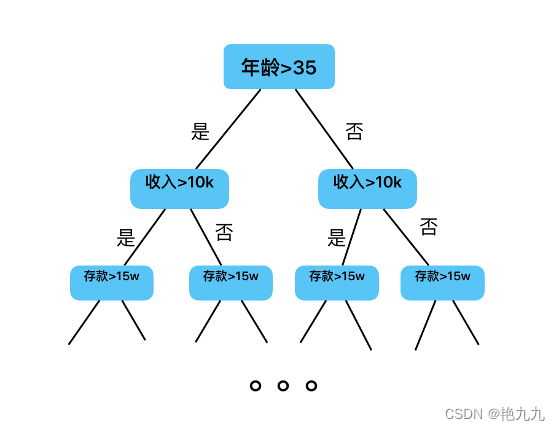
6. 构建过程
在Ordered TS 和Ordered Boosting 的改进下,Catboost有两种提升模式:Ordered和Plain,前者是Ordered TS + Ordered Boosting,后者是标准GBDT算法搭配Ordered TS。
7. Catboost优点
- 能够处理类别特征
- 能够有效防止过拟合
- 模型训练精度高
- 调参时间相对较多
8. Catboost缺点
- 对于类别特征的处理需要大量的内存和时间
- 不同随机数的设定对于模型预测结果有一定的影响















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









