










4.2 哈希
4.2.1 哈希的定义与整数哈希
我们先来看一个小例子。 N N N个正整数{8, 3, 7, 6, 2}中,待查询的 M M M个正整数{7, 4, 2}是否有数值在其中出现。看得出来,7和2就出现在那 N N N个正整数中,只有4不在。
对于这个问题,一个很简单的想法,对于待查询的数值 x x x,我们可以直接暴力枚举,遍历所有 N N N个数,看是否有数跟 x x x相等。不过这种方法的时间复杂度为 O ( N M ) O(NM) O(NM),当 N N N和 M M M都很大的时候( 1 0 5 10^5 105级别),显然无法接受。
当然,这里肯定有更好的方法,我们可以尝试用空间换时间。

首先定义一个bool型数组hashTable,其中hashTable[x] == true表示正整数
x
x
x在N个正整数中出现过,而hashTable[x] == false表示正整数
x
x
x在
N
N
N个正整数中没有出现过。当一开始读入
N
N
N个正整数的时候,就可以为存在的
x
x
x赋值hashTable[x]=true进行预处理。当然,为了hashTable数组操作方便,一开始把它初始化为false是应有之义。之后,对于
M
M
M个待查询的数,我们就可以通过直接看对应的元素是否为true,来验证是否出现。这时的算法时间复杂度就降低到了
O
(
N
+
M
)
O(N+M)
O(N+M)。
除此之外,如果我们想知道待查询的数
x
x
x在
N
N
N个数中出现的次数,可以把hashTable数组的替换为int型,在读入
N
N
N个数时,使用hashTable[x]++来统计出现次数。
上面两个问题都是将输入的数作为数组下标来对这个数的性质进行统计。但是对于那些很大的数或者字符串就无法将它们直接作为数组下标了,有什么方法可以解决这个问题吗?那就是所谓的“哈希”了。
一般来说,哈希就是通过一个函数将元素转换为整数,使得该整数可以尽量唯一地代表这个元素。这个转换函数被称为哈希函数 H H H,元素转换前为 k e y key key,转换后就是整数 H ( k e y ) H(key) H(key),它表示一个地址。
- 常见的哈希函数(假设
k
e
y
key
key为整数)
直接定址法:指恒等变换( H ( k e y ) = k e y H(key) = key H(key)=key)或线性变换( H ( k e y ) = a ∗ k e y + b H(key) = a*key+b H(key)=a∗key+b)。平方取中法:取元素 k e y key key平方后的中间几位作为哈希地址。除留余数法:把元素 k e y key key除以一个数 m o d mod mod得到的余数作为哈希地址( H ( k e y ) = k e y % m o d H(key)=key \% mod H(key)=key%mod)。 m o d mod mod的选择一般要小于或者等于表长 m m m的最大素数(即 m o d ≤ m mod \leq m mod≤m) ,因为这样可以减少冲突。
虽然有很多方法可以构造哈希函数,但是到最后都会产生冲突这一问题。即有两个元素
k
e
y
1
key1
key1和
k
e
y
2
key2
key2,它们的哈希地址相同
H
(
k
e
y
1
)
=
H
(
k
e
y
2
)
H(key1)=H(key2)
H(key1)=H(key2)。我们没办法在同一地址放置两个数,所以解决冲突是非常有必要的。
- 常见解决冲突的方法(前两个又被称为开放定址法:都计算了新的哈希地址)
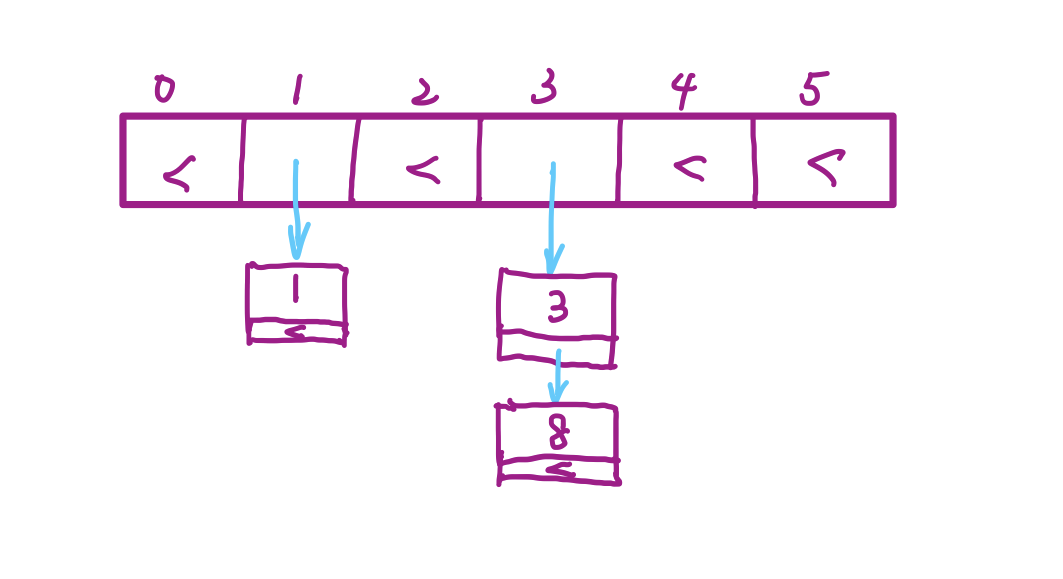
线性探查法:从发生冲突的地址 H ( k e y ) H(key) H(key)开始,依次探查下一个地址是否被占用,如果探查的地址超过了表长,就回到表的首地址继续循环,直到找到一个空位置为止。但是这种做法容易产生堆积问题,即连续多个位置被占用,这在一定程度上会降低效率。平方探查法:若在 H ( k e y ) H(key) H(key)位置发生冲突,探查的新的地址序列为 H ( k e y ) + 1 2 H(key)+1^2 H(key)+12, H ( k e y ) − 1 2 H(key)-1^2 H(key)−12, H ( k e y ) + 2 2 H(key)+2^2 H(key)+22, H ( k e y ) − 2 2 H(key)-2^2 H(key)−22, ⋯ \cdots ⋯。这样可以减少堆积现象。如果在检查过程中,求得的地址 H ( k e y ) + k 2 H(key)+k^2 H(key)+k2超过了表长 m m m,就将地址对 m m m取模;如果 H ( k e y ) − k 2 H(key)-k^2 H(key)−k2小于首地址,那么将 ( ( H ( k e y ) − k 2 ) % m + m ) % m ((H(key)-k^2)\%m+m)\%m ((H(key)−k2)%m+m)%m作为结果(等价于将 H ( k e y ) − k 2 H(key)-k^2 H(key)−k2不断加上 m m m直到出现第一个非负数)。如果想避免负数,可以只进行正向的平方探查。可以证明,如果 k k k在 [ 0 , m ) [0,m) [0,m)范围内都无法找到位置,那么当 k ≥ m k\geq m k≥m时,也一定无法找到位置。链地址法:不用计算新的哈希地址,而是将所有 H ( k e y ) H(key) H(key)相同的 k e y key key连接成一条单链表。哈希地址中存放的也不再是元素 k e y key key,而是单链表的表头指针。
4.2.2 字符串哈希初步
字符串哈希指将一个字符串 S S S映射为一个整数,使得该整数可以唯一地表示字符串 S S S。
对于字符串,我们可以将 A ∼ Z A \sim Z A∼Z视为 0 ∼ 25 0 \sim 25 0∼25,这样就将26个大写字母映射到了二十六进制中,然后从二十六进制转换到十进制。代码如下:
int hashFunc(char S[], int len){
int id = 0;
// 将二十六进制转换为十进制
for(int i=0; i<len; i++){
// 从左往右依次求
id = id*26 + (S[i]-'A');
}
}
这里与3.5节说的方法不太一样,将转换为二十六进制的字符串看成 a 0 a 1 ⋯ a n a_0a_1 \cdots a_n a0a1⋯an,转换成的十进制为:
( y ) 10 = a 0 ∗ 2 6 n + a 1 ∗ 2 6 n − 1 + ⋯ + a n ∗ 2 6 0 = ( ( ( a 0 ) ∗ 26 + a 1 ) ∗ 26 + a 2 ) ∗ 26 + a 3 ⋯ \begin{aligned} (y)_{10} &= a_0*26^{n} + a_1*26^{n-1} + \cdots + a_n*26^{0} \\ &= (((a_0)*26 + a_1)*26 + a_2)*26 + a_3 \cdots \end{aligned} (y)10=a0∗26n+a1∗26n−1+⋯+an∗260=(((a0)∗26+a1)∗26+a2)∗26+a3⋯
如果出现了小写字母,可以额外将 a ∼ z a \sim z a∼z作为 26 ∼ 51 26 \sim 51 26∼51,这样变成了五十二进制转换为十进制的问题:
int hashFunc(char S[], int len){
int id = 0;
for(int i=0; i<len; i++){
if(S[i]>='A' && S[i]<='Z'){
id = id*52 + (S[i]-'A');
}else if(S[i]>='a' && S[i]<='z'){
// 因为小写字母是从26开始的,所以要加26
id = id*52 + (S[i]-'a') + 26;
}
}
}
如果出现了数字,一般有两种处理方法:
- 按照小写字母的处理方法,将 0 ∼ 9 0 \sim 9 0∼9也算到进制中,增加到62进制。
- 如果只有字符串末尾有数字且能知道数字的个数,我们先将前面的英文字母转换成十进制,然后将末尾的数字拼接到转换成的十进制后面。比如“BCD4”,英文字母“BCD”先按前面的方法转换为十进制“731”,然后将4直接拼接到数字后变为”7314“。















 225
225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









