







对于非结构化的数据类型:
示例代码:
import pandas as pd
data1 = [1, 2, 3, 4, 5]
data2 = [11, 22, 33, 44, 55, 66, 77, 88, 99]
data3 = [111, 222, 333]
df = pd.DataFrame({"单": data1, "双": data2, "三": data3})
print(df)运行上面代码将会报下面错误:
![]()
上述问题解决方法:使用from_dict()方法,行数为key值,列数为最长的values的长度,而其他较短的values则用NaN填充。
示例代码:
import pandas as pd
data1 = [1, 2, 3, 4, 5]
data2 = [11, 22, 33, 44, 55, 66, 77, 88, 99]
data3 = [111, 222, 333]
# 使用from_dict,数据未对齐的用NaN来代替
df = pd.DataFrame.from_dict({"单": data1, "双": data2, "三": data3}, orient='index')
print(df)
print(df.T)运行结果:
0 1 2 3 4 5 6 7 8
单 1 2 3 4.0 5.0 NaN NaN NaN NaN
双 11 22 33 44.0 55.0 66.0 77.0 88.0 99.0
三 111 222 333 NaN NaN NaN NaN NaN NaN
单 双 三
0 1.0 11.0 111.0
1 2.0 22.0 222.0
2 3.0 33.0 333.0
3 4.0 44.0 NaN
4 5.0 55.0 NaN
5 NaN 66.0 NaN
6 NaN 77.0 NaN
7 NaN 88.0 NaN
8 NaN 99.0 NaN将数据保存在csv文件中:
示例代码:
import pandas as pd
data1 = [1, 2, 3, 4, 5]
data2 = [11, 22, 33, 44, 55, 66, 77, 88, 99]
data3 = [111, 222, 333]
# 使用from_dict,数据未对齐的用NaN来代替
df = pd.DataFrame.from_dict({"单": data1, "双": data2, "三": data3}, orient='index')
print(df)
print(df.T)
# 将df数据保存在csv文件中
df.to_csv("./new_test.csv")生成的csv文件数据:

一般情况下这不是我们想要的数据保存形式,需要把行列转置一下,这也说明了df.T不会改变原来的df数据。
修改后的代码如下:
import pandas as pd
data1 = [1, 2, 3, 4, 5]
data2 = [11, 22, 33, 44, 55, 66, 77, 88, 99]
data3 = [111, 222, 333]
# 使用from_dict,数据未对齐的用NaN来代替
df = pd.DataFrame.from_dict({"单": data1, "双": data2, "三": data3}, orient='index')
print(df)
print(df.T)
new_df = df.T
# 将df数据保存在csv文件中
# df.T.to_csv("./new_test.csv")
new_df.to_csv("./new_test.csv")生成的csv文件数据:
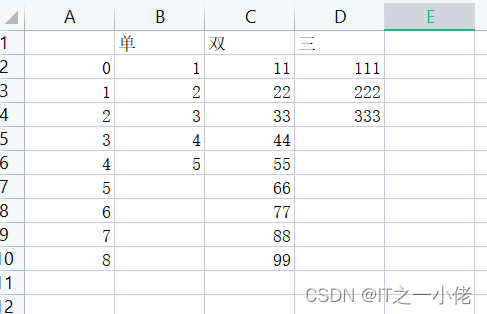
此时生成的csv文件的格式基本上符合要求了,但是第一列出现了序列号,这一般也不是我们想要的。添加to_csv("./new_test.csv", index=False)去掉索引。
最终的示例代码:
import pandas as pd
data1 = [1, 2, 3, 4, 5]
data2 = [11, 22, 33, 44, 55, 66, 77, 88, 99]
data3 = [111, 222, 333]
# 使用from_dict,数据未对齐的用NaN来代替
df = pd.DataFrame.from_dict({"单": data1, "双": data2, "三": data3}, orient='index')
print(df)
print(df.T)
# 将df数据保存在csv文件中
df.T.to_csv("./new_test.csv", index=False)生成的csv文件数据:
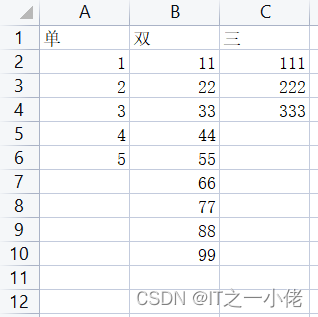















 922
922











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









