







Pandas数据结构
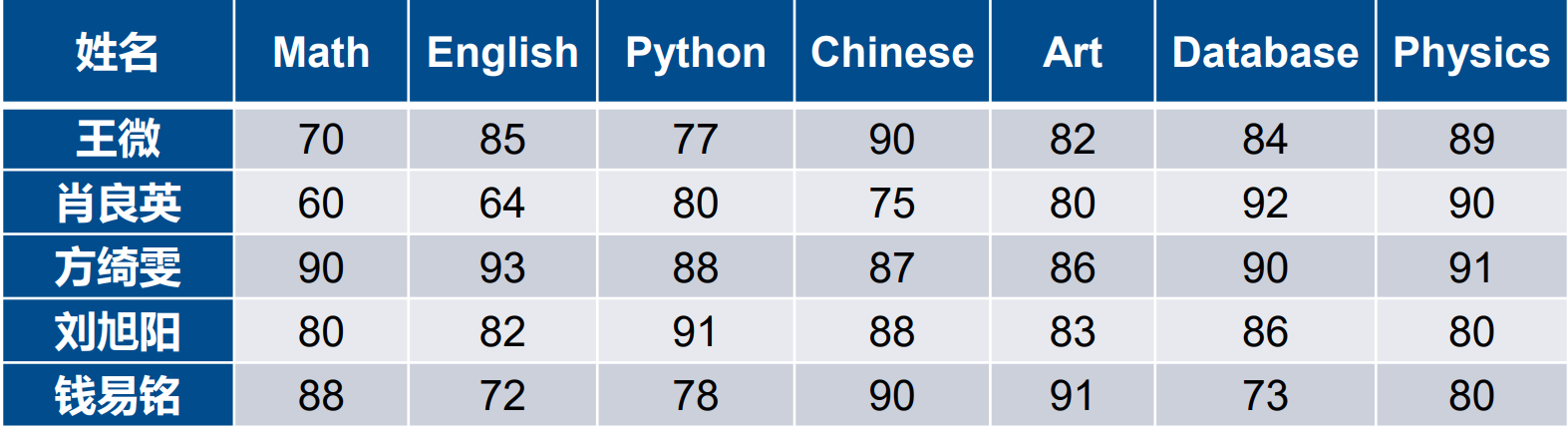
使用NumPy存储学生成绩信息
◆学生姓名,一维ndarray
◆课程名称,一维ndarray
◆课程成绩,二维ndarray
能否将这些数据组织在一个数据结构中?
◆将二维的数据的行与学生姓名数组关联
◆将二维的数据的列与课程名称数组关联
pandas是基于python的数据分析工具包
◆ Series数据结构:一维数据
◆ DataFrame数据结构:二维数据和高维数据
◆ 汇集多种数据源数据、处理缺失数据
◆ 对数据进行切片、聚合和汇总统计
◆ 实现数据可视化
为方便使用Series和DataFrame,将其导入本地命名空间
>>> from pandas import Series, DataFrame
Series 是类似于数组的一维数据结构,由索引(index)和值(values) 两个相关联的数组组成:
Series创建
Series([data,index,....])
data:Python的列表或Numpy的一维ndarray对象
index:列表,若省略则自动生成0 ~n-1的序号标签
用字典创建Series对象,将字典的key作为索引:
>>> height=Series({'13':187,'14':190,'7':185,'2':178, '9':185})
Series数据选取方法
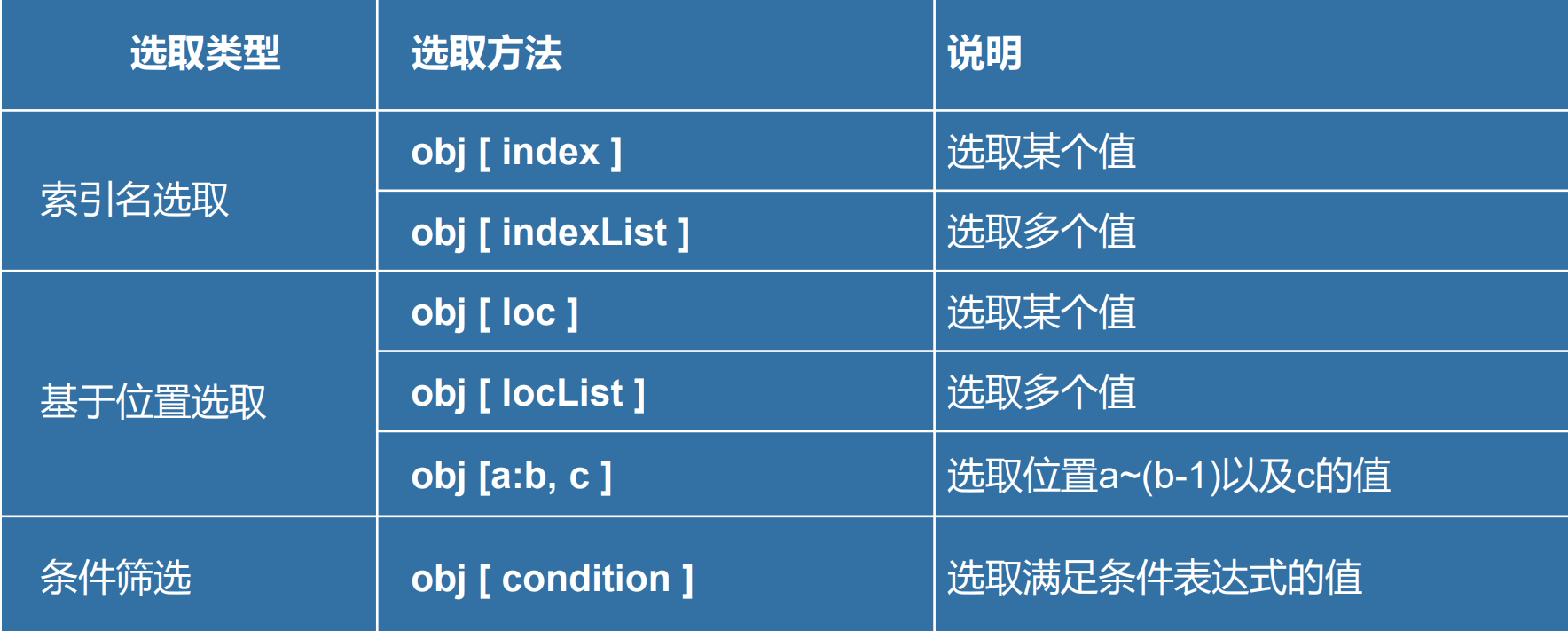
索引名选取,需要加单引号,位置选取不需要加
>>> height[height.values>=186 ] #检索高于186的球员
2. 球员身高修改
>>> height['13'] = 188#将13号队员的身高修改为188
>>> height[1:3] = 160#修改位置 1、2的数据,标量赋值
Series不能直接添加新数据
append()函数将两个Series拼接产生一个新的Series
不改变原Series
3. 增加新球员
>>> a = Series([190,187], index=['23','5'])
>>> new = height . append( a )
4. 删除离队球员
>>> new = height . drop( ['13', '9'] ) #删除13、9号球员数据
Series的drop()函数默认不删除原始对象的数(产生新对象)
Inplace=True:表示删除原始数据
Series对象创建后,值可以修改,索引也可以修改,用新的列表替换即可。
5. 更改球员球衣号码
>>> height.index=[13,14,7,2,9] #注意这里是数字索引
Series的索引为数字,基于位置序号访问需要使用iloc方式,不能直接用位置属性
>>> height.iloc[0]
DataFrame
DataFrame 包括值(values)、行索引(index)和列索引(columns)
DataFrame 创建方法:
DataFrame ( data,index = […],columns=[…] )
data:列表或NumPy的二维ndarray对象
index,colunms:列表,若省略则自动生成0 ~n-1的序号标签
eg:
创建DataFrame对象students记录3名学生的信息:行索引为数字序号;列索引为age、weight和height
>>> data = [[19,170,68],[20,165,65],[18,175,65]]#这里使用的是列表
>>> students = DataFrame(data, index=[1,2,3], columns=['age','height','weight'])

data列表的每个元素初始化为DataFrame的一行值
DataFrame数据选取方法

students.loc[ : , ['height','weight']] #“:”表示所 有行的数据
students.iloc[1:, 0:2] #通过切片抽取某些行和列的数据
#筛选身高大于168的同学,显示其身高和体重值
>>> mask = students['height']>=168
>>> mask
1 True
2 False
3 True
Name: height, dtype: bool
#mask对象索引为2的行值为False,对应students索引为2的行未选中
>>> students.loc[ mask, ['height','weight'] ]
height weight
1 170 68
3 175 65
2. 增加学生信息
#列索引标签不存在,添加新列;存在则为值修改
>>> students['expense'] = [1500,1600,1200] #为学生 增加月消费数据
DataFrame对象可以添加新的列,但不能直接增加新的行
增加行需要通过两个DataFrame对象的合并实现

#筛选不合理数据,重新赋值
>>> students.loc[students['expense']<500, 'expense' ] = 1200
>>> students.drop(1, axis=0) #axis=0表示行
>>> students.drop('expense', axis=1)#删除expense列,axis=1 表示列
>>> students.drop([1, 2], axis=0) #删除多行,给出行索引名列表
如果需要直接删除原始对象的行或列,设置参数 inplace=True #删除多列,并修改students对象
>>> students.drop(['age','weight'], axis=1, inplace=True)
Pandas支持多种格式的数据导入和导出
◼ CSV、TXT、Excel、HTML等文件格式
◼ MySQL、SQLServer等数据库格式
◼ JSON等Web API数据交换格式
常用CSV、TXT、Excel 3种文件的数据读写
CSV是一种特殊的文本文件,通常使用:
逗号:字段之间的分隔符
换行符:记录之间分隔符
读取CSV文件方法
read_csv( file, sep=',', header='infer’, index_col=None, names=None, skiprows,...)
参数说明: file 字符串,文件路径和文件名
sep 字符串,每行各数据之间的分隔符,默认为‘,’
header header=None,文件中第一行不是列索引
index_col 数字,用作行索引的列
names 列表,定义列索引,默认文件中第一行为列索引
skiprows 整数或列表,需要忽略的行数或需要跳过的行号列表
从students1.csv文件读出数据,保存为DataFrame对象
>>> student = pd.read_csv( 'data\student1.csv ')
文件中每个同学已有序号,读取时作为行索引
>>> student = pd.read_csv( 'data\student1.csv ', index_col = 0 )
文本文件包含中文,使用“UTF-8”编码格式保存
◆ 其他格式,Python 3读取时报“utf-8” 错误
保存方法
◆ 用“记事本”程序打开文件,选择“文件”的“另存为”菜单
◆ 点击最下方的“编码”下拉列表
◆ 选择“UTF-8” →“保存“
不是以逗号隔开的文本文件,读取时需要设置分隔符参数sep
分隔符既可以是指定字符串,也可以是正则表达式

>>> colNames = ['性别','年龄','身高','体重','省份','成绩']
>>> student = pd.read_csv('data\student2.txt', sep='\t', index_col=0, header=None, names= colNames )#指明: 1)文件中不包括列索引 2)列索引名由指定列表给出
数据保存到文件
to_csv (file, sep, mode, index, header,...)

新建DataFrame对象student,并将数据保存到out.csv文件
>>> data = [[19,68,170],[20,65,165],[18,65,175]]
>>> student =DataFrame( data,index=[1,2,3], columns=['age','weight','height'] )
>>> student . to_csv(‘out.csv', mode='w', header=True, index=False)
从Excel文件中读取数据的函数类似CSV文件
需给出数据所在的Sheet表单名
读取方法: read_excel(file, sheetname, ...)
缺失数据处理
主要有数据滤除和数据填充两类方法
1. 数据滤除 obj.dropna(axis, how, thresh,...)

缺失数据被表示为NaN, 赋值时使用np.nan
◆ 样本容量大,忽略缺失行
◆ 样本容量较小,采用合适的值来填充
>>> stu.dropna() #缺省删除包含有缺失值的行(序号1、3、5的行被滤除)
>>> stu.dropna(thresh=8) #保留有效数据个数≥8的行(序号5的行被滤除)
2. 数据填充 填充有两种基本思路:
◆ 用默认值填充
◆ 用已有数据的均值/中位数来填充
格式: obj.fillna (value, method, inplace...)

列填充,构造{列索引名:值}形式的字典对象作为实际参数
>>> stu.fillna( {‘年龄’:20, ‘体重’:stu[‘体重’].mean()} )
用前一行数据替换当前行的空值
>>> stu.fillna(method='ffill') #每个空值用上一行同列的值填充,没有前一行, 不填充
填充操作产生新的数据对象,原始数据不会被修改
直接填充原始数据中的缺失值
fillna() 增加参数设置:inplace=True
去重:
去重函数 obj.drop_duplicates()
数据合并
原数据的列与新增数据的列完全相同
轴向连接:concat()函数
>>> newstu = pd.concat([stu1,stu2], axis=0) #axis=0,表 示按行进行数据追加
教务表“学号”与一卡通表“ID”表示相同概念
◼ 比较两张表每行的“学号”与“ID”(键)进行拼接
merge ( x,y,how,left_on,right_on ...)

参数how定义了四种合并方式
1)inner:内连接,拼接两个数据对象中键值交集的行,其余忽略
2)outer:外连接,拼接两个数据对象中键值并集的行
3)left:左连接,取出x的全部行,拼接y中匹配的键值行。
4)right:右连接,取出y的全部行,拼接x中匹配的键值行。
2、3或4种合并方法
◆ 当某列数据不存在则自动填充NaN
数据排序
Series和DataFrame 都支持排序
◆ 按照列数据值排序
◆ 按列数据生成排名
1. DataFrame 值排序
obj.sort_values(by, ascending,inplace...)

>>> stu.sort_values(by='成绩', ascending=False) #按成绩降序排列
指定多个列排序,如:by=['身高','体重’]
◆ 先按“身高”排序,
◆ 若某些行的“身高”相同,这几行再按“体重”排序
>>> stu.sort_values(by=['身高','体重'], ascending=True)
2. 排名
排名给出每行的名次
◆ 定义等值数据的处理方式,如并列名次取最小值或最大值,也可以取均值。
排名函数形式 obj.rank(axis,method,ascending,...)

>>> stu['成绩排名'] = stu['成绩'].rank(method='min', ascending=False)#增加“成绩排名”列。















 1377
1377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











