






面试1013
- Linux
- 计算机网络
- 操作系统
- 数据库
- 数据结构与算法
- Java
- redis
- 算法题
- 人寿研发中心
- 1.为什么会选择Java开发
- 2.JVM内存回收机制
- 3.当存在多次GC,触发Full GC或者溢出情况,如何排查
- 4.项目RabbitMQ设计思路
- 5. 问了权限管理的实现,spring中aop以及在项目中的使用
- 6.开发时用过哪些框架,答:springboot,并且介绍了ioc和aop;
- 7.在开发时遇到过哪些困难;
- 8.项目中如何使用的java框架与技术栈
- 9.spring中的bean的管理,涉及到哪些设计模式
- 10.有了解多线程吗?主线程等待子线程的运行完成,如何实现
- 11.如何理解死锁?
- 12.无序数组中一个数数量超过一半,如何找到
- 13.tcp三次握手
- 14.你做这个项目的时候具体遇到了什么困难嘛?你是怎么解决的。
- 15.Set集合了解嘛?具体Set有哪些,能说一下区别嘛?
- 16. 多线程有具体的了解过嘛?能说一下怎样实现多线程?
- 17.集合里面,他们对于线程安全吗?
- 18.排序算法
- 终面
Linux
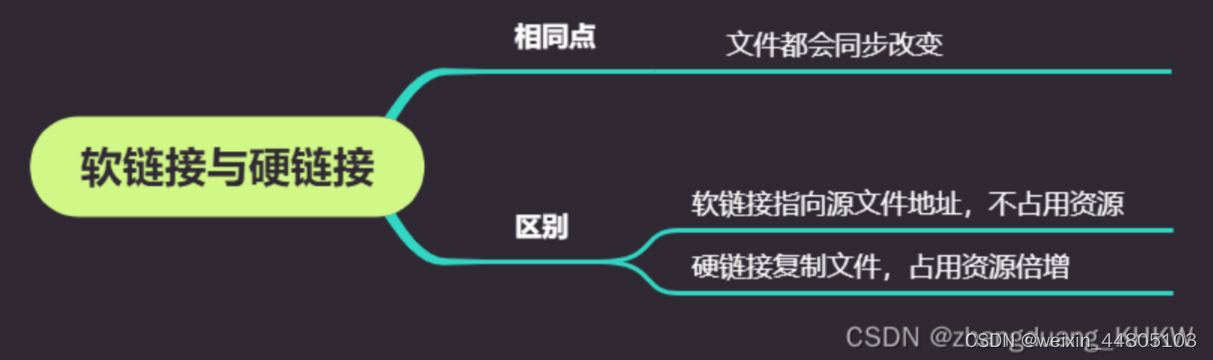
1.软连接和硬连接
命令
netstat命令:端口是否被占用
-p : 显示进程标识符和程序名称,每一个套接字/端口都属于一个程序。
grep
rwx:r代表可读,w代表可写,x代表该文件是一个可执行文件 4,2,1
ps -ef 查看所有正在运行的进程
计算机网络
1.多路复用
是媒体或带宽的共享。这是来自多个来源的多个信号被组合并通过单个通信/物理线路传输的过程。
2.TCP/IP模型?以及每一层对应七层模型哪个
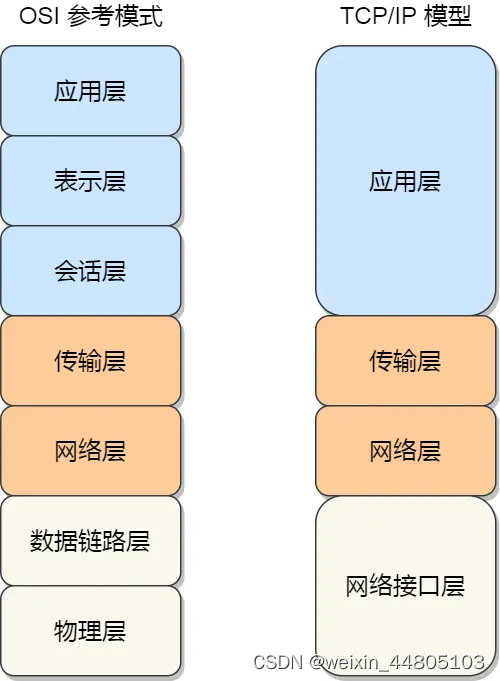
应表会 传网 数物
应 ------传网–网
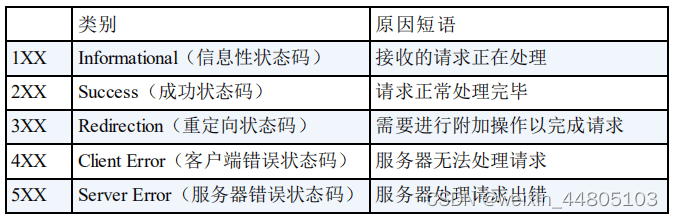
3.状态码

操作系统
1.页和段的区别
- 页是信息的物理单位,分页是为实现离散分配方式,以消减内存碎片,提高内存的利用率。段则是信息的逻辑单位,它含有一组其意义相对完整的信息。分段的目的是为了能更好地满足用户的需要。
- 页的大小固定且由系统决定;而段的长度却不固定,决定于用户所编写的程序。
- 分页的地址空间是一维的,程序员只需利用一个记忆符,即可表示一个地址;而分段的作业地址空间是二维的,程序员在标识一个地址时,既需给出段名,又需给出段内地址
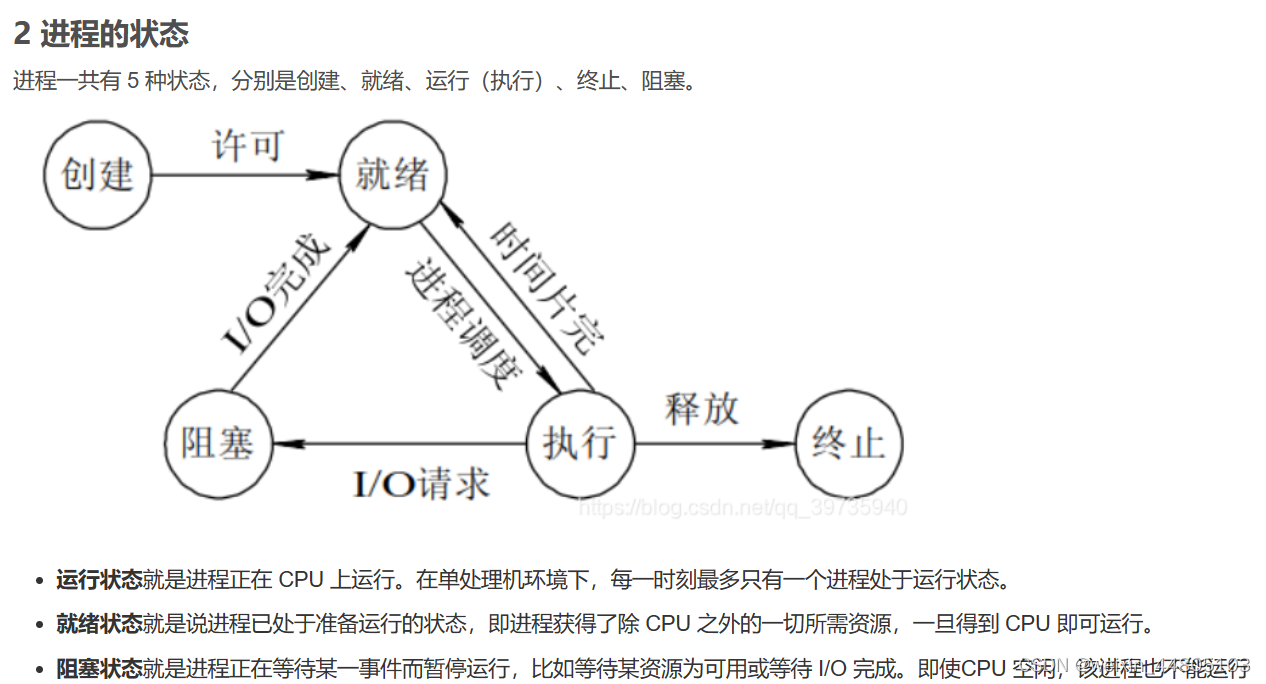
2. 进程的调度策略与进程的状态
-
先来先服务
非抢占式的调度算法,按照请求的顺序进行调度。 -
短作业优先
非抢占式的调度算法,按估计运行时间最短的顺序进行调度。 -
最短剩余时间优先
按剩余运行时间的顺序进行调度。 当一个新的作业到达时,其整个运行时间与当前进程的剩余时间作比较。 -
时间片轮转
将所有就绪进程按 FCFS(先来先服务) 的原则排成一个队列,每次调度时,把 CPU 时间分配给队首进程,该进程可以执行一个时间片。当时间片用完时,由计时器发出时钟中断,停止进程。
3.进程、线程、协程
- 进程是操作系统资源分配的最小单位,线程是cpu调度的最小单位。
进程有独立的系统资源,而同一进程内的线程共享进程的大部分系统资源,包括堆、代码段、数据段,每个线程只拥有一些在运行中必不可少的私有属性,比如tcb,线程Id,栈、寄存器。

4.僵尸进程
每个进程都需要一个父进程。当子进程终止时,它会向父进程发送一个SIGCHLD信号,告诉父进程它已经终止。如果父进程没有处理这个信号,就会导致子进程成为僵尸进程。
- 父进程由于阻塞无法接收SIGCHLD信号
- 父进程在处理SIGCHLD信号时阻塞了
数据库
1.B和B+树,平衡二叉树的区别?
- 二叉树/平衡二叉树/红黑树等都是有且仅有2个分支,共性就是数据量大的时候树的深度变深,增加IO的次数。
- B树会在节点上存储数据,这样一页存放的key的数量就会减少,增加树的深度。
- B+树 中非叶子节点去除了数据,这样就会增加一页中key的数量,而且叶子节点之间是通过链表相连,有利于范围查找和分页
B+树是一棵多路搜索树可以降低树的高度,提高查找效率,为了让一个查询尽量少地读磁盘,就必须让查询过程访问尽量少的数据块
2.隔离
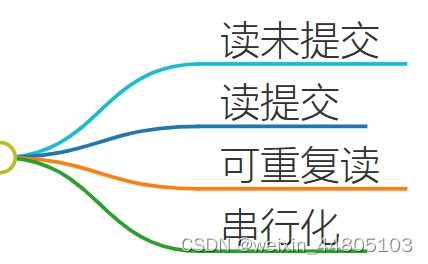

##3. acid
原子性:原子性是指一个事务是一个不可分割的单位,要么全部成功,要么全部失败。便可以利用undo log中的信息将数据回滚到修改之前的样子。
持久性:持久性是指一个事务一旦提交,它对数据库的改变是永久性的。当数据库的数据要进行新增或修改的时候,还要把这次的操作记录 到redo log里面。如果MySQL宕机了,还可以从redo log恢复数据。
隔离性:不同事务之间不能相互影响。写-写操作主要是通过锁实现的。如果是读- 写操作则是通过mvcc
一致性:事务不能破坏数据的完整性和业务的一致性。例如在转账时,不管事务成功还是失败,双方钱的总额不变。
4.解决幻读
图片来源:
添加链接描述



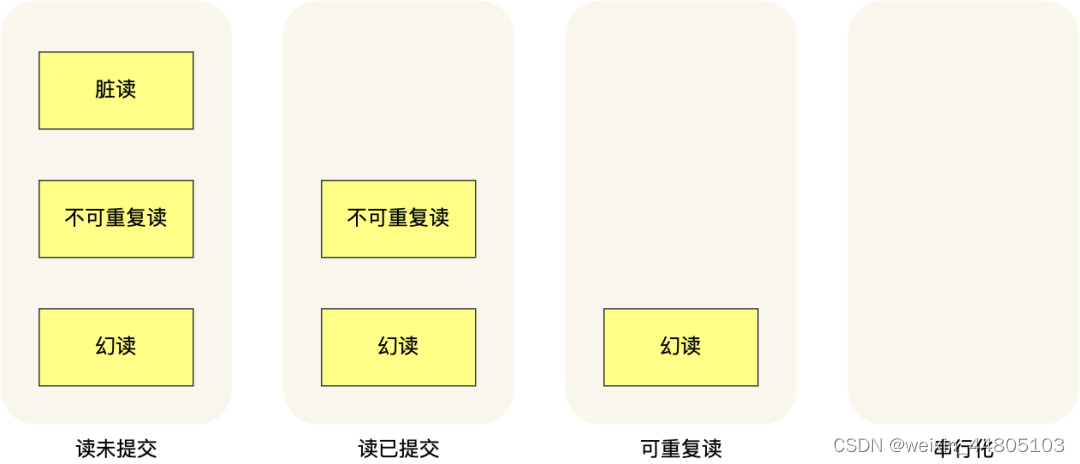
5.
数据结构与算法
排序算法
重要的:插入排序-堆排序-归并排序-快速排序
选泡插,
快归堆希统(桶排序)计(计数)基,
恩方恩老恩一三,
对恩加k/恩乘K
选堆希快不太稳

视频讲解的很好
冒泡排序

插入排序

选择排序
已排序和未排序

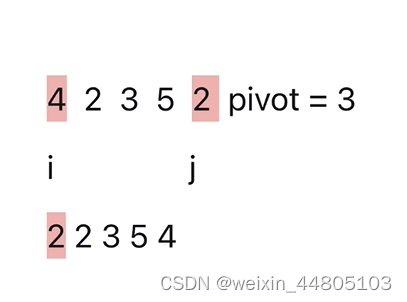
快速排序
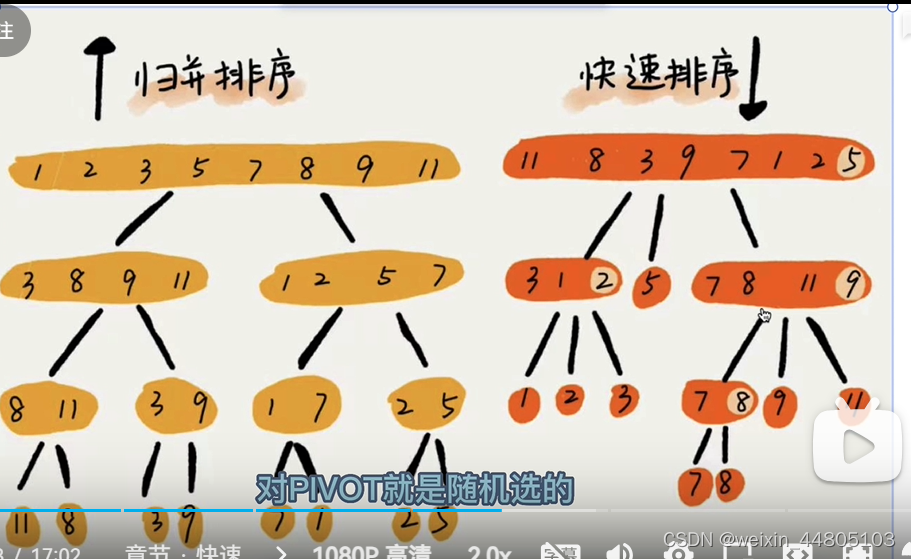

不稳定
用双指针去找pvot大的和小的
归并排序

堆排序

堆的上浮和下潜,以及优先队列的应用
Java
多态
多态是面向对象编程中的一个重要概念,它允许不同类型的对象对同一方法进行不同的实现。 父类的引用变量来引用子类的对象,从而实现对不同对象的统一操作。
- 继承关系
- 方法重写
- 父类引用指向子类对象
STATIC
静态代码块以用来优化代码性能,只会在类加载的时候执行一次


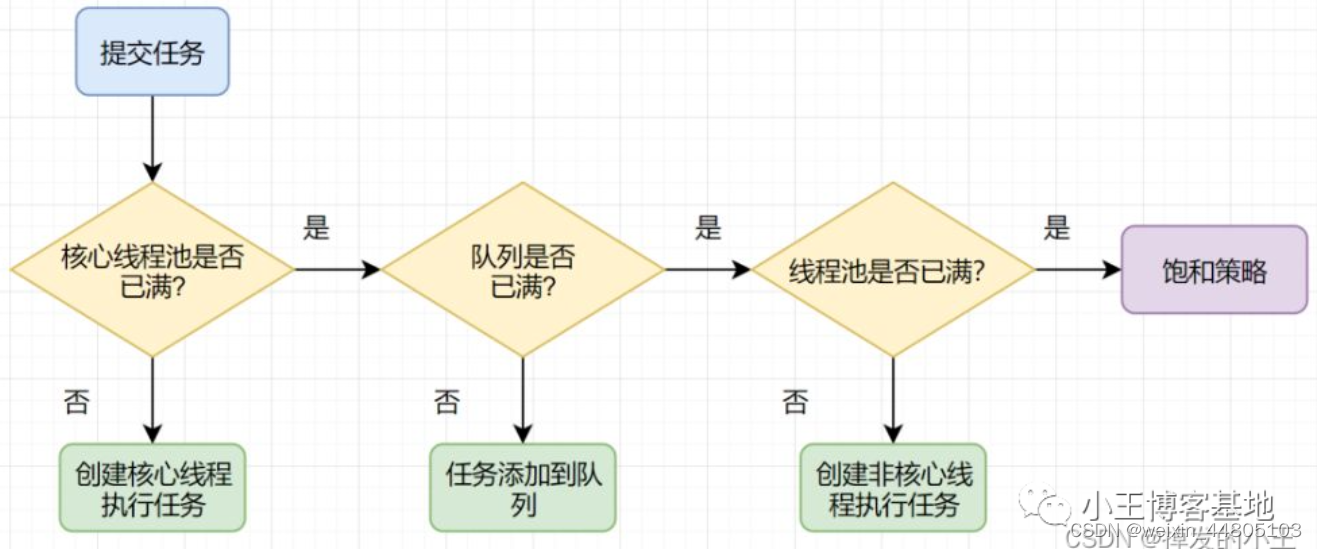
线程池

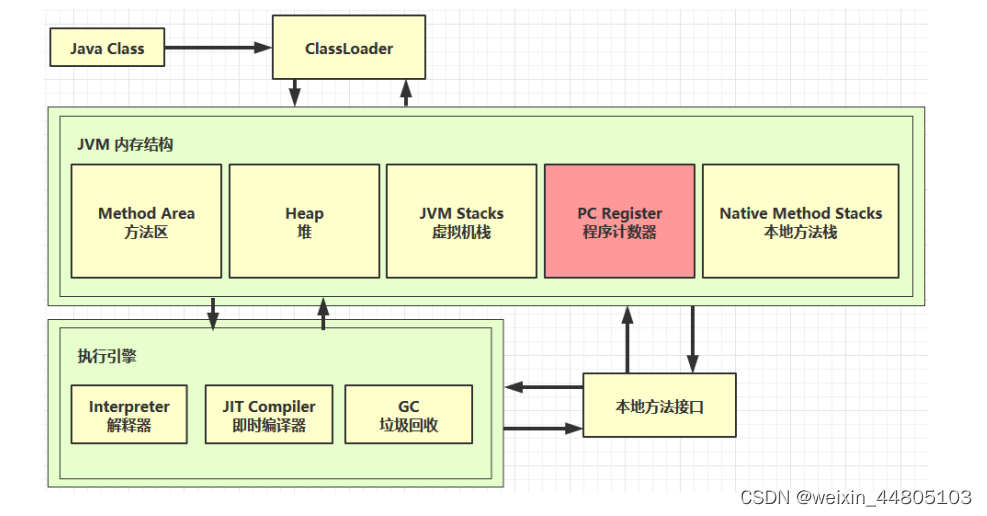
jvm内存
redis
redis的数据结构
Redis是一种存储key-value的内存型数据库,它的key都是字符串类型,value支持存储5种类型的数据:String(字符串类型)、List(列表类型)、Hash(哈希表类型、即key-value类型)、Set(无序集合类型,元素不可重复)、Zset(有序集合类型,元素不可重复)。
一致性hash算法
算法题
152.乘积最大的连续数组
贪心算法:

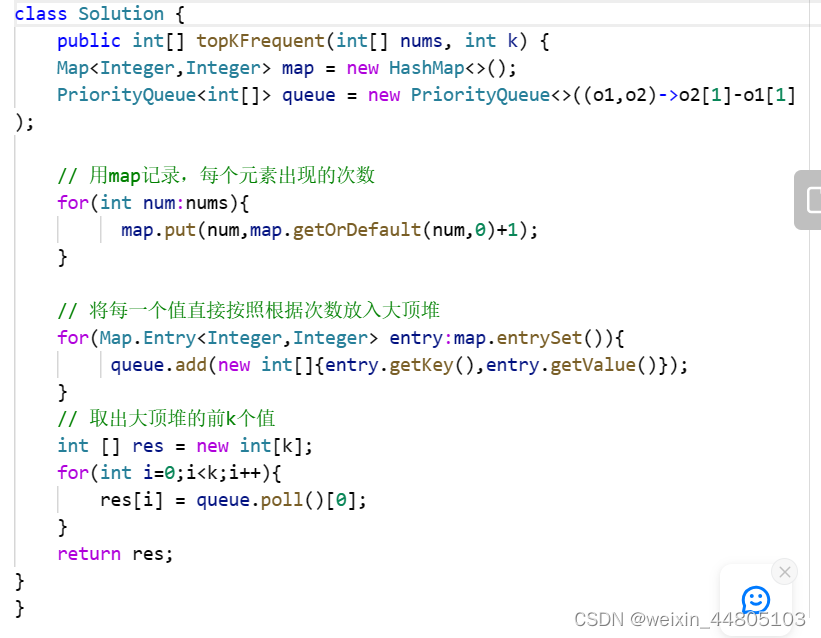
347 前K个高频字符
24.移除元素

链表找环
public static boolean isCircleByHash(ListNode head){
if (null == head){
return false;
}
Set<ListNode> set = new HashSet<>();//定义哈希集合
while (null != head){
if (set.contains(head)){//存在说明有环
return true;
}
set.add(head);
head = head.next;
}
return false;
}
146.LRU
class LinkNode{
int key;
int val;
LinkNode front;
LinkNode next;
public LinkNode(int key, int val){
this.key = key;
this.val = val;
}
}
class LRUCache {
Map<Integer,LinkNode> map = new HashMap<>();
LinkNode head = new LinkNode(0,0);
LinkNode tail = new LinkNode(0,0);
int capacity;
public LRUCache(int capacity){
this.capacity = capacity;
head.next = tail;
tail.front = head;
}
public void put(int key, int value) {
if(!map.containsKey(key)){
if(map.size() == capacity) deleteLastNode(); //weixie
LinkNode added = new LinkNode(key,value);
addFirst(added); //weixie
map.put(key,added);
}else{
LinkNode node = map.get(key);
node.val = value;
moveNodeTop(node); //weixie
}
}
public void deleteLastNode(){
LinkNode last = tail.front;
last.front.next = tail;
tail.front = last.front;
map.remove(last.key);
}
public void addFirst(LinkNode node){
LinkNode temp = head.next;
head.next = node;
node.front = head;
node.next = temp;
temp.front = node;
}
public void moveNodeTop(LinkNode node){
node.front.next = node.next;
node.next.front = node.front;
addFirst(node);
}
public int get(int key){
if(map.containsKey(key)){
LinkNode node = map.get(key);
moveNodeTop(node);
return node.val;
}else{
return -1;
}
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/
人寿研发中心
1.为什么会选择Java开发
2.JVM内存回收机制
3.当存在多次GC,触发Full GC或者溢出情况,如何排查
- Minor GC频繁,新生代空间较小,Eden区很快被填满,就会导致频繁Minor GC,因此可以通过增大新生代空间-Xmn来降低Minor GC的频率
- 原因导致FGC(大对象;内存泄漏,无法被回收(比如IO对象使用完后未调用close方法释放资源),先引发FGC,最后导致OOM;显式调用了gc方法;)
4.项目RabbitMQ设计思路
5. 问了权限管理的实现,spring中aop以及在项目中的使用
6.开发时用过哪些框架,答:springboot,并且介绍了ioc和aop;
7.在开发时遇到过哪些困难;
8.项目中如何使用的java框架与技术栈
9.spring中的bean的管理,涉及到哪些设计模式
10.有了解多线程吗?主线程等待子线程的运行完成,如何实现
主线程sleep
子线程join
使用CountDownLatch
使用CycleBarrier
11.如何理解死锁?
12.无序数组中一个数数量超过一半,如何找到
参考链接:
方法一:利用map
利用map的key -value模型来存放arr[i]和相对应出现的次数,最后用次数去跟数组长度一半去比较
方法二:排序求中间值
出现的次数超过长度一半,那给数组排序以后,它一定处在最中间的位置;
方法五:target-other>=1
因为这个数字出现次数超过数组长度的一半,所以目标数字的个数 减去其他数字的个数总和 一定是大于等于1的,当我们遇到目标值时+1,否则-1,当count为0时重新设置目标值,最后记录的位置一定是目标数字
13.tcp三次握手
14.你做这个项目的时候具体遇到了什么困难嘛?你是怎么解决的。
我:(我回答了spring+mybatis时因为mapper.xml文件没有配置好,导致出的错误)
面试官:你这个问题是比较小的,我想问的是那种大的
我:我具体做这个的时候,代码方面是没出过问题的,唯一算作比较大的就是之前需求没有理解好,项目中途得加模块)
15.Set集合了解嘛?具体Set有哪些,能说一下区别嘛?

16. 多线程有具体的了解过嘛?能说一下怎样实现多线程?
17.集合里面,他们对于线程安全吗?















 4371
4371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









