






近段时间精读一篇目标检测综述-Object Detection in 20 Years: A Survey
论文地址:https://arxiv.org/abs/1905.05055
然后跟着B站up主 :同济子豪兄、跟着炮哥学、小土堆。跑了一些yolov5框架
写了一些,个人有不断改进的地方,请大家多指导!
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。
检测-Detection:解决“在哪里?是什么?”的问题,即定位出这个目标的位置并且知道目标物是什么。
CNN
用于目标检测任务的鼻祖训练和预测阶段分别如下:
训练阶段主要训练三部分:CNN最后两层的微调,Linear SVM和bounding-box regressor。主要步骤如下:
候选框(ROI)生成:使用了selective search的方法,Selective search是一种比较好的数据筛选方式,首先对图像进行过分割切成很多很多小块,然后根据小块之间的颜色直方图、梯度直方图、面积和位置等基本特征,把相近的相邻对象进行拼接,从而选出画面中有一定语义的区域。
特征提取:使用一预训练的CNN网络提取每个ROI的特征,将CNN的最后一个FN层换成我们自己的,比如样本有100类,那我们最后一层输出维度101(1类是背景)。训练使用SGD(梯度下降),样本组成:所有与Groud Truth框的IoU大于0.5的视作该类的正样本,每次SGD随机选择32个正样本和96个背景样本进行训练。这就是一个典型的CNN分类网络,正常训练即可,但是我们并不会全连接之后softmax输出分类,
类别预测:为每一个类别训练一个linear SVM分类器,为什么不用高维,思考一下?在这里使用了 hard negative mining(难例挖掘),即着重训练那些易错的样本。候选框精修(Bounding-box regression ):首先用NMS对同个类的region proposals进行合并,因为SVM会给我们的每个ROI一个分数,因此我们选取得分最高而且与ground-truth重叠度超过阈值的ROI,记为P,然后丢弃与该被选框重叠度较高的那些,对剩下的高分ROI,每个P与其对应的ground-truth组成一个样本对 () ,我们使用他们作为样本让线性回归学习一个从预测框到ground-truth的映射关系。
- 生成1k-2k个候选区域(使用的是selective search方法)
使用了selective search的方法,Selective search是一种比较好的数据筛选方式,首先对图像进行过分割切成很多很多小块,然后根据小块之间的颜色直方图、梯度直方图、面积和位置等基本特征,把相近的相邻对象进行拼接,从而选出画面中有一定语义的区域
- 使用CNN提取特征
- 非极大值抑制,例如行人检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。这时就需要用到NMS来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口
- 特征送入每一类的SVM分类器,判断正确与否
- 使用回归器精细修正候选框位置
Fast R-CNN
之所以提出Fast R-CNN,主要是因为R-CNN存在以下几个问题:
1、训练分多步。我们知道R-CNN的训练先要fine tuning一个预训练的网络,然后针对每个类别都训练一个SVM分类器,最后还要用regressors对bounding-box进行回归,另外region proposal也要单独用selective search的方式获得,步骤比较繁琐。
2、时间和内存消耗比较大。在训练SVM和回归的时候需要用网络训练的特征作为输入,特征保存在磁盘上再读入的时间消耗还是比较大的。
3、测试的时候也比较慢,每张图片的每个region proposal都要做卷积,重复操作太多。
所以在Fast R-CNN中我们提出改进:
改用网络使用VGG16,基于VGG16的Fast RCNN算法在训练速度上比RCNN快了将近9倍,比SPPnet快大概3倍;测试速度比RCNN快了213倍,比SPPnet快了10倍
Yolo
Yolo是一种卷积神经网络结构,yolo(意思是神经网络只需要看一次图片,就能输出结果),通过给出的物体坐标获取目标的特征信息,然后将信息存储、学习,在目标图像上找到符合的特征信息,确定目标位置。
Yolo网络结构
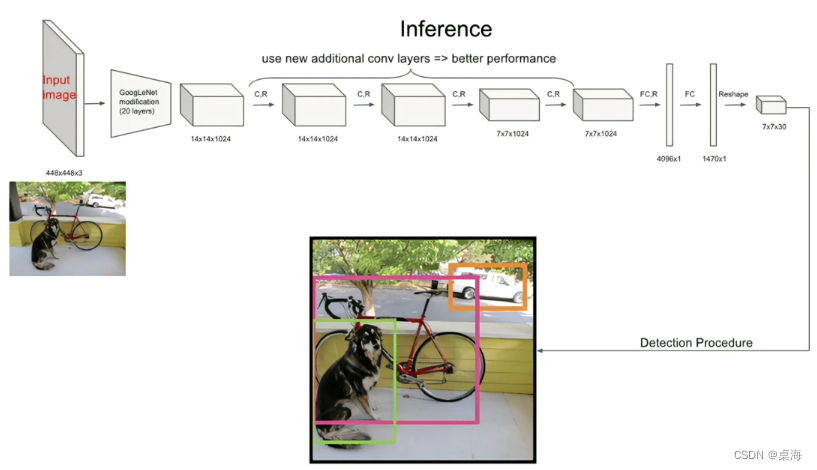
1)目的是从一张图片中可以识别出多个不同种类的物体
2)并且用一个框将每个物体框出来并得到坐标,也可以要得到物体的尺寸,包含5个信息:物体的中心位置(x,y),物体的长和宽(h,w),以及物体的种类置信度分数(score)
3)Yolo模型采用预定义预测区域的方法来完成目标检测,具体而言是将原始图像划分为 7x7=49 个网格(grid),每个网格允许预测出2个边框(bounding box,包含某个对象的矩形框),总共 49x2=98 个bounding box。我们将其理解为98个预测区,很粗略的覆盖了图片的整个区域,就在这98个预测区中进行目标检测。
Yolov1优缺点:
优点:
- YOLO很快,可以用于实时检测,因为用回归的方法,并且不用复杂的框架。
- YOLO会基于整张图片信息进行预测,而其他滑窗式的检测框架,只能基于局部图片信息进行推理。
- YOLO学到的图片特征更为通用。
缺点:
- 大的bbox偏离一点和小的bbox偏离一点对于损失函数的贡献不一样。
- 小目标的定位时会出现定位偏差较大的问题。
- 它很难泛化到新的、不常见的长宽比或配置的目标。我们的模型也使用相对较粗糙的特征来预测边界框,因为输入图像在我们的架构中历经了多个下采样层。
参考链接:Fast RCNN算法详解_fast r-cnn_AI之路的博客-CSDN博客
参考链接:yolo-目标检测算法简介_yolo定义_欧菲斯集团的博客-CSDN博客
参考链接:https://blog.csdn.net/mengxianglong123/article/details/125784062


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









