










一 简单概念
机器视觉的四大任务
分类-Classification:解决“是什么?”的问题,即给定一张图片或一段视频判断里面包含什么类别的目标.
检测-Detection:解决“是什么?在哪里?”的问题,即定位出这个目标的的位置并且知道目标物是什么。
定位-Location:解决“在哪里?”的问题,即定位出这个目标的的位置。
分割-Segmentation:,解决“每一个像素属于哪个目标物或场景”的问题。
目标检测
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。
检测-Detection:解决“在哪里?是什么?”的问题,即定位出这个目标的位置并且知道目标物是什么。
yolo是一种卷积神经网络结构,yolo(意思是神经网络只需要看一次图片,就能输出结果),通过给出的物体坐标获取目标的特征信息,然后将信息存储、学习,在目标图像上找到符合的特征信息,确定目标位置。
1)目的是从一张图片中可以识别出多个不同种类的物体
2)并且用一个框将每个物体框出来并得到坐标,也可以要得到物体的尺寸,包含5个信息:物体的中心位置(x,y),物体的长和宽(h,w),以及物体的种类置信度分数(score)
yolo-应用场景
yolo系列是目标领域知名度最高的算法,其凭借出色的实时检测性能在不同的领域均有广泛应用。目前,yolo共有6个版本,yolo v1-v5和yolo vx。
yolo的预测是基于整个图片的,并且它会一次性输出所有检测到的目标信息,包括类别和位置。就好像捕鱼,yolo会将整张网撒下去,将所有的鱼都捞起来。
1) 医疗领域,胃镜息肉检测、药品表面缺陷检测、CT医疗图像检测
2) 安防领域,是否佩戴安全帽检测、行人检测、人员识别、明火检测
3) 交通领域,车辆检测、交通标志识别、交通信号灯检测,交通状况监控
4) 农业领域,病虫害检测、成熟度检测、生育期识别
yolo-简单网络结构
输入端:
Mosaic数据增强(随机裁剪拼接)
自适应锚框计算(反复更新标注框和预测框的差值)
自适应图片缩放(统一模型训练的图像宽高)
Backbone(主干网络):
Focus结构(将图像切片、卷积得到需要的特征图)
CSP结构(采样、特征获取和组合)用于提高准确率
Neck(特征层):

输出端:
Bounding box损失函数(计算交并比)
nms非极大值抑制(解决遮挡问题)
二 模型训练
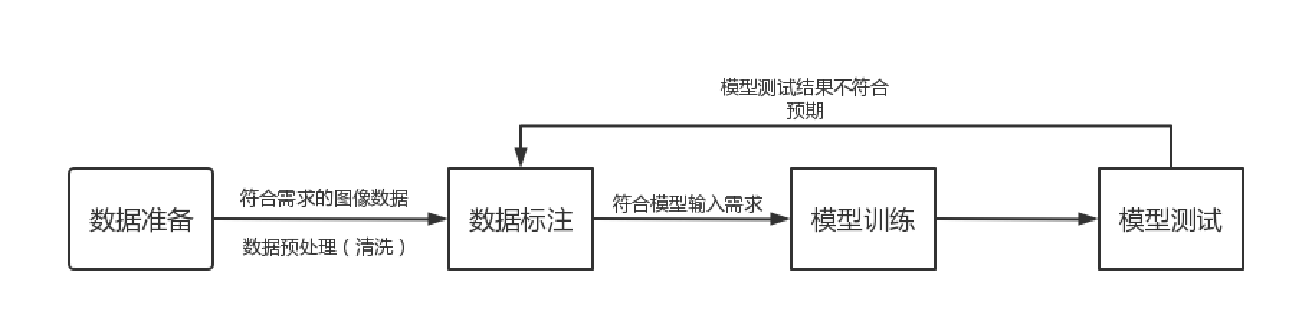
三 训练注意事项
1、数据准备阶段
数据的多种多样(不重复)
图像清晰
目标准确(图像中有目标)并且目标不宜过大或者过小
2、数据标注阶段
标注框刚好框住目标
标注信息准确(标注信息一般用英文和数字)
选取的信息简单明了(特征单一)
3、模型训练阶段
标准信息、格式和训练输入是否一致(不一致进行转化)
训练的轮数输入大小(影响到最终结果和时间)
超参数的设置
4、模型测试阶段
正负样本检测
测试数据的多样和量多
训练常用超参数
*超参数 *:
- 定义关于模型的更高层次的概念,如复杂性或学习能力。
- 不能直接从标准模型培训过程中的数据中学习,需要预先定义。
- 可以通过设置不同的值,训练不同的模型和选择更好的测试值来决定
常用超参数:
1.学习率:是指在优化算法中更新网络权重的幅度大小,也叫做步长
2.权重初始化:第一种是采用均匀分布的方法初始化各层网络的权重,自己从头开始训练网络模型.
第二种是采用该模型之前已经训练好的权重作为训练的初始值
3.优化器:通过什么算法去优化网络模型的参数,常用的优化器就是梯度下降
4.批次大小:每一次训练神经网络送入模型的样本数,在卷积神经网络中,大批次通常可使网络更快收敛,
但由于内存资源的限制,批次过大可能会导致内存不够用或程序内核崩溃
5.迭代次数:指整个训练集输入到神经网络进行训练的次数
6.激活函数:激活函数是给神经网络加入一些非线性因素,使得网络可以更好地解决较为复杂的问题。
类似于人类大脑中基于神经元的模型,激活函数最终决定了要发射给下一个神经元的内容















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









