







注意力机制
想要理解注意力机制,先看一下Encoder RNN(Seq2Seq Model)是怎么一回事。Seq2Seq Model中有一个编码器也就是下面这张图所展示的,比如要将一段英文翻译成中文,编码器就是将每一个词向量
X
i
Xi
Xi进行矩阵变换,变换之后的结果为
h
i
hi
hi,编码器将这些词向量的特征汇聚到最后一个状态
h
m
hm
hm上,也就是说经过
E
n
c
o
d
e
r
Encoder
Encoder 编码器之后,我们得到的只有
h
m
hm
hm ,之前的 h 都会舍去。

我们再来看解码器,它像我们文本生成器一样,把我们刚才得到的信息,逐字逐句的翻译成中文。但是它也有缺陷,如果输入句子太长,那么编码器会忘掉一些特征,导致解码的时候会对应不上。

为了解决遗忘问题,注意力机制在2015年横空出世,我们来看看注意力机制是怎么改进的。
参考我们人类对于遗忘是怎么处理的,如果不重要的事情,我们会忘掉它,那当然没关系,如果事情很重要,我们会额外注意它,然后把这件事记住。
那么电脑怎么衡量一个事情或者是特征重要不重要呢?这里呢,就提出了一个相关性的公式。它是计算
S
o
So
So 与每一个输出
h
i
hi
hi的相关性,那么会得出m个权重
α
\alpha
α .
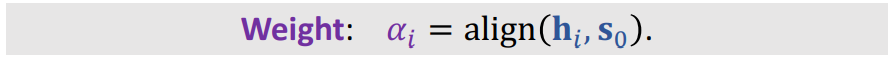

接下来我们看一下每一个权重
α
\alpha
α具体是怎么算的。权重计算的方法有很多,我们只看应用最广泛的 transformer 是怎么计算的。如下图所示,计算权重的步骤总共3步。
1 用两个矩阵分别对 h , So 做线性变换,并分别记为
k
i
k_i
ki ,
q
0
q_0
q0。
2 然后将得到的
k
i
k_i
ki ,
q
0
q_0
q0 相乘
3 将得到的值做softmax,得到
α
i
\alpha_i
αi,总共m个值。

到这里我们的相关性就计算完成了,那么计算出这么多的相关性,我们必须把它使用起来,刚才讲到
s
o
s_o
so 作为解码器的时候会遗忘一些特征,那么这时候如果我们将相关性与特征做一个线性加和,再当作解码器的输入,是不是就不会产生遗忘的问题了。我们将这样的线性相加得出的结果称为Context vector,简称
c
0
c_0
c0,它具体计算公式如下:

接下来我们看解码是怎么回事。
经过刚才的一顿操作我们得到了
s
0
s_0
s0 ,
c
0
c_0
c0 ,那么
s
1
s_1
s1 该怎么计算呢?具体公式如下:


我们得到了新的状态
s
1
s_1
s1,那么怎么得到
c
1
c_1
c1 呢?和刚才得到
c
0
c_0
c0 的思路类似(相关性与
h
i
h_i
hi 的加权平均),那么
c
1
c_1
c1 的值,也得是相关性与
h
i
h_i
hi加权平均,只不过这时候的相关性是
s
1
s_1
s1与
h
i
h_i
hi的相关性,具体公式如下:
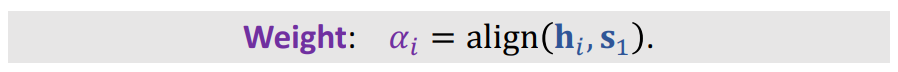
计算完
s
1
s_1
s1与
h
i
h_i
hi的相关性之后,我们就能得出
c
1
c_1
c1 的值了。

同理我们将
s
1
s_1
s1 ,
h
i
h_i
hi ,
x
1
,
x_1^,
x1, ,做一次变换,就能得到
s
2
s_2
s2 ,变换公式如下:
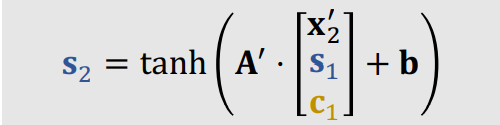
c
2
c_2
c2的值,得是
s
2
s_2
s2与
h
i
h_i
hi 得出的相关性与
h
i
h_i
hi的加权平均。如下图:

同理:

最后计算出所有的值:

权重大的我们用深线表示,也意味着我们只关注那些与我们相关的特征。

以上这就是注意力机制的原理。小白一枚,希望各位大佬指出当中某些不正确的内容。















 1323
1323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









