






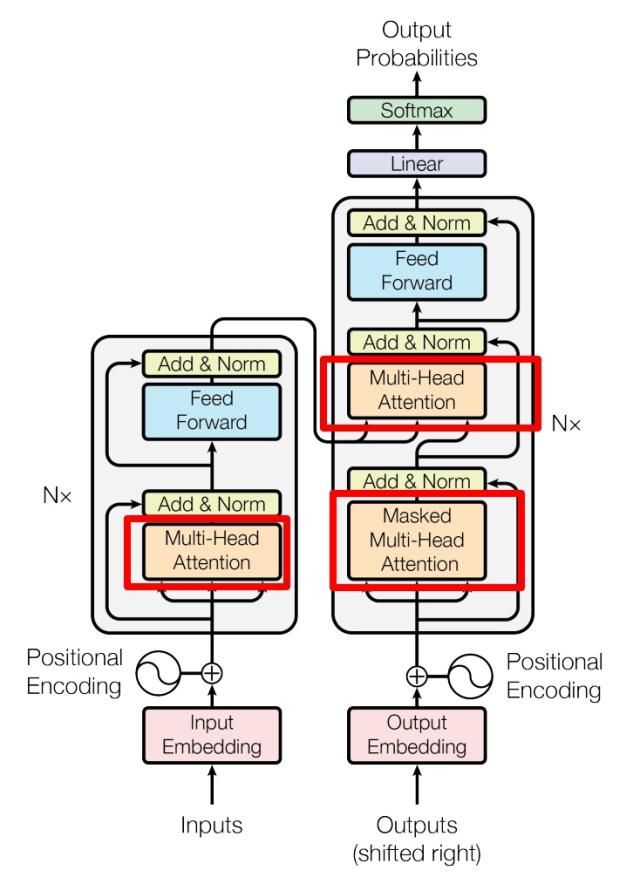
Transformer结构
由encoder和decoder两部分组成
内部结构包括了多头注意力机制,正则化,残差连接。
其整体结构图如下:
开篇一:注意力机制
注意力机制的目的是表示word和word之间关系程度的远近,一般是作为权重项。因此数值不宜过大或过小。
常规注意力系数的计算公式为:阶段1:根据Query和Key计算两者 的相似性或者相关性 ➢ 阶段2:对第一阶段的原始分值进 行归一化处理 ➢ 阶段3:根据权重系数对Value进行 加权求和,得到Attention Value
单头注意力的注意力系数计算常用公式:Q的维度是n*d,其中,n表示单词的数量,d表示每个单词的维度。(使用单词作为表述存在一定的不准确性,也可能是token)而a的作用归一化,将注意力系数n*n做归一化处理。得到的注意力分值是a*V,最终每个单词的维度,仍是n*d.

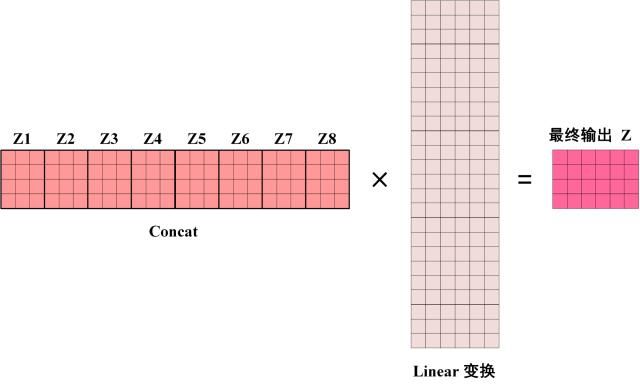
多头注意力计算:对每个head得到的结果做concat计算,之后,通过linear层,将其维度映射到n*d维度。比如,head=8,则concat得到的向量维度是n*(8d),之后通过8d*d的矩阵,得到n*d的输出。
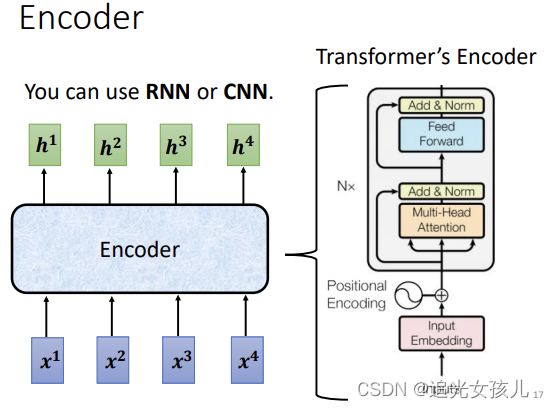
开篇2:encoder的结构
 ——>
——>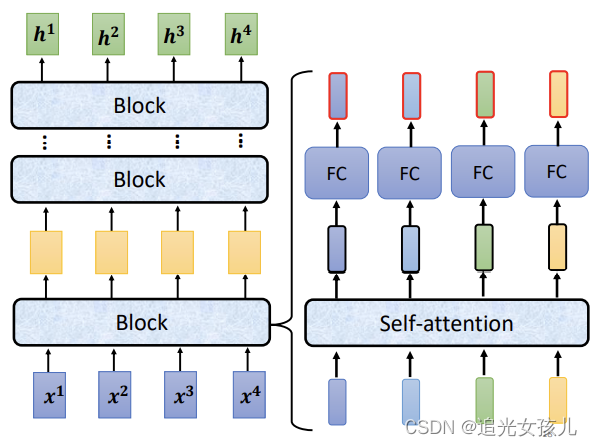 ——>
——>
三幅图连续看过去,对于(1),当我们在使用PLM的一些结构时,可能为了避免参数量多大或者过拟合等情况,会采用CNN、RNN等简单的结构替换Transformer,毕竟,Transformer中有太多linear操作了(在Tinghua课程中,提到线性层的参数量达到整个transformer参数量的70%左右)
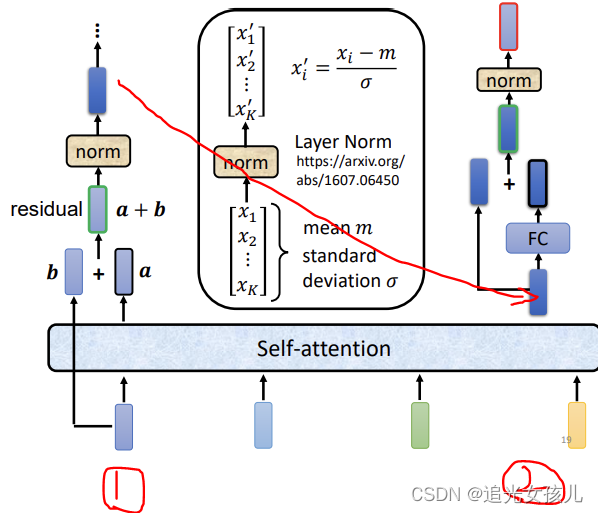
(2)是对encoder部分展开的图,是input->残差连接部分->feed forward之前的部分。
(3)左半部分是采用multi-head,得到attention value a ,和b add之后,通过norm操作,右半部分是feed forward和add-norm部分。
其计算采用的是“dot-product attention”加了一个前缀“scaled”,即引入一个温度因子(temperature) ,中文全称“缩放的点积注意力网络”:
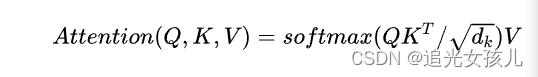
总结一下:在encoder部分,用到linear操作的有:(1)attention中Q/K/V矩阵的获得(2)多头注意力部分,Linear由n*md映射到n*d (3)encoder中的feed forward
开篇3:transformer的初始化和标准化
初始化常用手段:
- 正态分布:
- 均匀分布:
- 结尾正态分布:类似于正态分布,但数值选取范围改变,从[a,b]区间内,选择数据。
标准化常用方法:
- Batch Normalization
- Instance Normalization
- Layer Normalization
其中,(1)的计算流程如下:

















 1468
1468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











