






 本文深入分析了Goroutine的原理,包括为何使用Goroutine,G-M-P模型,Goroutine调度流程,如newproc()、runqput()、schedule()、findrunnable()等关键函数,以及Goroutine的抢占机制。文章详细阐述了从Goroutine创建、调度到执行的整个过程,揭示了Go语言高效并发的秘密。
本文深入分析了Goroutine的原理,包括为何使用Goroutine,G-M-P模型,Goroutine调度流程,如newproc()、runqput()、schedule()、findrunnable()等关键函数,以及Goroutine的抢占机制。文章详细阐述了从Goroutine创建、调度到执行的整个过程,揭示了Go语言高效并发的秘密。
Goroutine原理
本文基于golang-v1.16: golang download
文章目录
一个例子
func start(a, b, c int64) {
fmt.Println(a, b, c)
}
func main() {
go start(1, 2, 3)
}
# output:
1 2 3
这个例子中,第6行代码go start()就表示新建了一个Goroutine。Goroutine是Go语言的基本调度单位,可翻译为协程,是比线程更轻量级的调度单位。每个Go程序至少有一个Goroutine(主Goroutine),当程序启动时,它会自动创建。
Go语言中最常见的一个设计模式:不要通过共享内存的方式进行通信,而是应该通过通信的方式共享内存。这也是Go语言有别于其他开发语言的最重要的一点。
为什么要用Goroutine
早期CPU-单进程时代
我们知道,一切的软件都是跑在操作系统上,真正用来干活 (计算) 的是 CPU。早期的操作系统每个程序就是一个进程,进程串行运行,直到一个程序运行完,才能进行下一个进程,我们称之为 “单进程时代”。
串行运行的特点是进程顺序执行,计算机一次只能执行一个任务。显而易见,进程执行I/O时阻塞,会带来大量的CPU时间浪费。
多进程时代
为了减少进程阻塞带来的CPU浪费,操作系统进入了多进程时代,通过CPU调度器对进程进行调度,可以在某个进程阻塞时,让CPU切换到别的进程执行。
但是,调度意味着进程/线程之间的切换。进程拥有太多资源,进程的创建、切换、销毁会占用很长时间。因此,操作系统引入了线程,一个进程可以有多个线程,这些线程共享进程的内存空间,在切换时尽量将属于同一个进程的线程在同一个CPU上执行,就可以减小切换开销。
但即使这样,线程也是比较大的,仍然会有高内存占用和调度时高消耗CPU的问题。
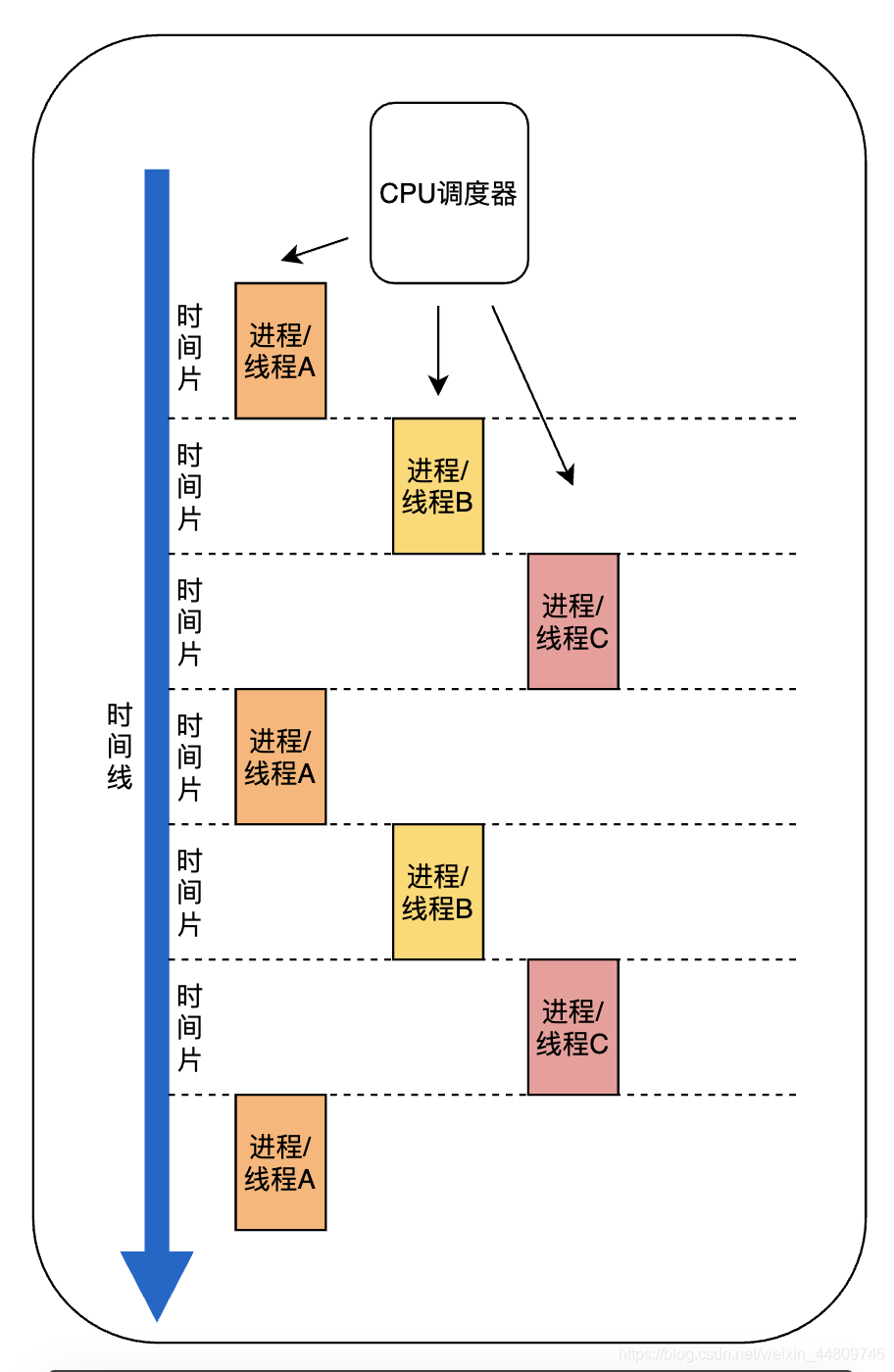
协程
为了更加减轻线程切换的开销,Go语言引入了更轻量级的协程。
Linux中,线程分为“用户态”和“内核态”。Go中将用户态线程叫做协程(co-routine),将内核线程叫做线程(thread),下文中我们统一用“线程”表示内核线程,用“协程”或“Goroutine”表示Go中的用户态线程。在发展过程中,二者从一对一的绑定关系逐渐演化为多对多的调度关系。
这样,操作系统的调度器调度只需要调度线程,而不需要考虑协程;协程的调度就交给了Goroutine的调度器。由于协程在用户态线程即完成切换,不会陷入到内核态,因此协程切换非常的轻量快速,大大减小了切换的开销。
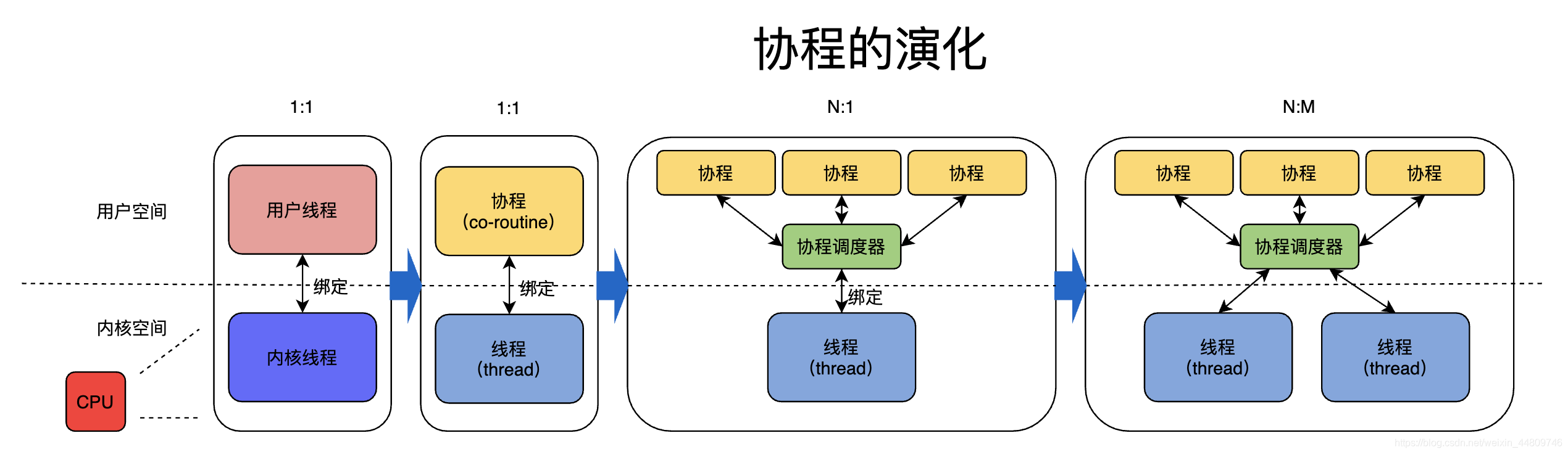
进程、线程、协程的内存占用和切换时间开销比较如表。
| 内存占用 | 切换时间开销 | |
|---|---|---|
| 进程 | MB~GB | 3~5us |
| 线程 | >1M | ~1us |
| 协程 | ~KB, 初始化2KB | ~0.2us |
术语解释
G:Goroutine,指Go语言中的协程,每个Goroutine都可以看作一个任务。
M:工作线程,可以理解为上文的内核态线程,由操作系统调度。每个G都需要运行在一个M上。
P:处理器,可以被看作运行在线程上的本地调度器,是G和M的中间层,用于提供M所需的上下文环境,也会负责调度线程上的等待队列。
调度器:Go语言用于调度Goroutine的整个模型,包括G-M-P模型和其中的整个调度算法。
M0:启动程序后的编号为 0 的主线程,这个 M 对应的实例会在全局变量 runtime.m0 中,不需要在 heap 上分配,M0 负责执行初始化操作和启动第一个 G, 在之后 M0 就和其他的 M 一样了。
G0:每次启动一个 M 都会第一个创建的 goroutine,G0 仅用于负责调度的 G,G0 不指向任何可执行的函数,每个 M 都会有一个自己的 G0。在调度或系统调用时会使用 G0 的栈空间,全局变量的 G0 是 M0 的 G0。
协程调度器的发展
Go语言发展至今已经到了1.16版本,在这个过程中,协程调度器也产生了很大的变化。
- 单线程调度器(0.x)
- 只包含 40 多行代码;
- 程序中只能存在一个活跃线程M,由 G-M 模型组成。M持有一个G的队列,在上一个G执行完或者发生阻塞时,就从队列中取出一个新的G执行。
- 多线程调度器(1.0)
此时Go有一个全局的Goroutine队列和多个工作线程M,每个M需要从队列中取G时,都要先对全局队列加锁,取出G后再解锁。- 允许运行多线程的程序;
- 全局锁导致竞争严重。
- 任务窃取调度器(1.1)
此时Go支持多个工作线程M,并引入了处理器P,P可以持有本地的Goroutine队列,减少了队列加锁的开销。- 引入了处理器 P,构成了目前的 G-M-P 模型;
- 在处理器 P 的基础上实现了基于工作窃取的调度器;
- 在某些情况下,Goroutine 不会让出线程,进而造成饥饿问题;
- 时间过长的垃圾回收(Stop-the-world,STW)会导致程序长时间无法工作;
- 抢占式调度器(1.2 ~)
- 基于协作的抢占式调度器(1.2 ~ 1.13)
在某个Goroutine陷入系统调用/IO阻塞时,可以对其进行抢占,让出工作线程执行别的Goroutine,可保证一部分公平。- 通过编译器在函数调用时插入抢占检查指令,在函数调用时检查当前 Goroutine 是否发起了抢占请求,实现基于协作的抢占式调度;
- Goroutine 可能会因为垃圾回收和循环长时间占用资源导致程序暂停;
- 基于信号的抢占式调度器(1.14 ~)
实现了异步抢占,对于进行长时间计算的Goroutine,也可以进行抢占。- 实现基于信号的真抢占式调度;
- 垃圾回收在扫描栈时会触发抢占调度;
- 抢占的时间点不够多,还不能覆盖全部的边缘情况;
- 基于协作的抢占式调度器(1.2 ~ 1.13)
- 非均匀存储访问调度器(提案)
- 对运行时的各种资源进行分区;
- 实现非常复杂,到今天还没有提上日程;
G-M-P 的关系
Goroutine在v1.1之后采用G-M-P 模型。简单来说,G-M-P 模型如下图。每个P都持有一个runnext和一个本地运行队列runq,runnext表示下一个待运行的G,runq表示待运行的G队列。runnext优先级高于runq。
每个M都绑定了一个P,M需要从P获取下一个运行的G。
调度器将所有的P的指针都保存在一个全局队列allp中;将所有的M的指针都保存在一个全局队列allm中,另外调度器还拥有一个G的全局队列sched.runq,优先级一般低于本地队列p.runq。
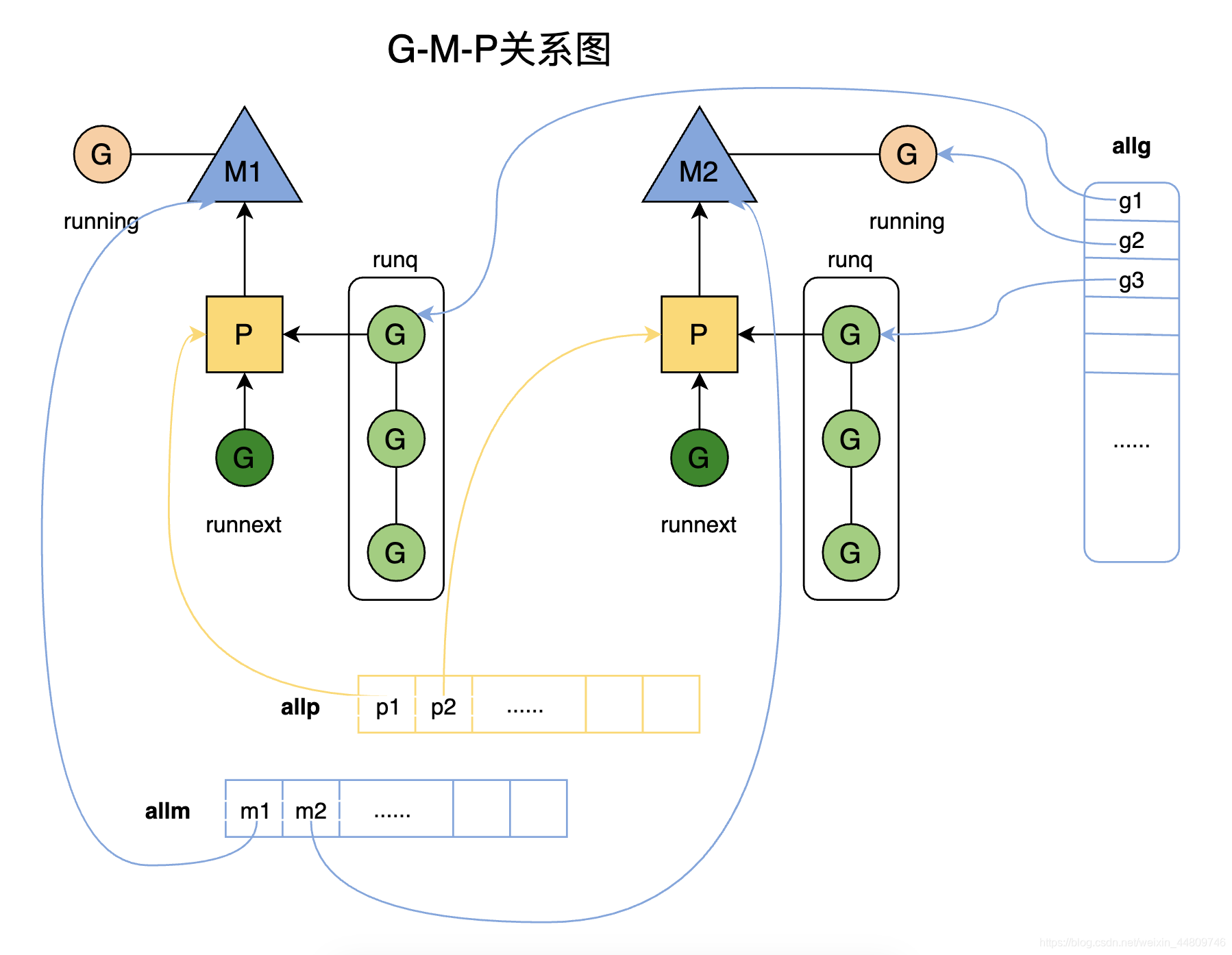
Go调度器的一生
当我们开始运行一个Go函数会发生什么呢?比如文章最开始的代码:
//hello.go
package main
import "fmt"
func start(a, b, c int64) {
fmt.Println(a, b, c)
}
func main() {
go start(1, 2, 3)
}
我们可以简单地把调度器的一生描述为下面的流程图,当我们运行main()函数时,Go调度器开始工作,main()函数结束时,程序执行完成,调度器结束工作。
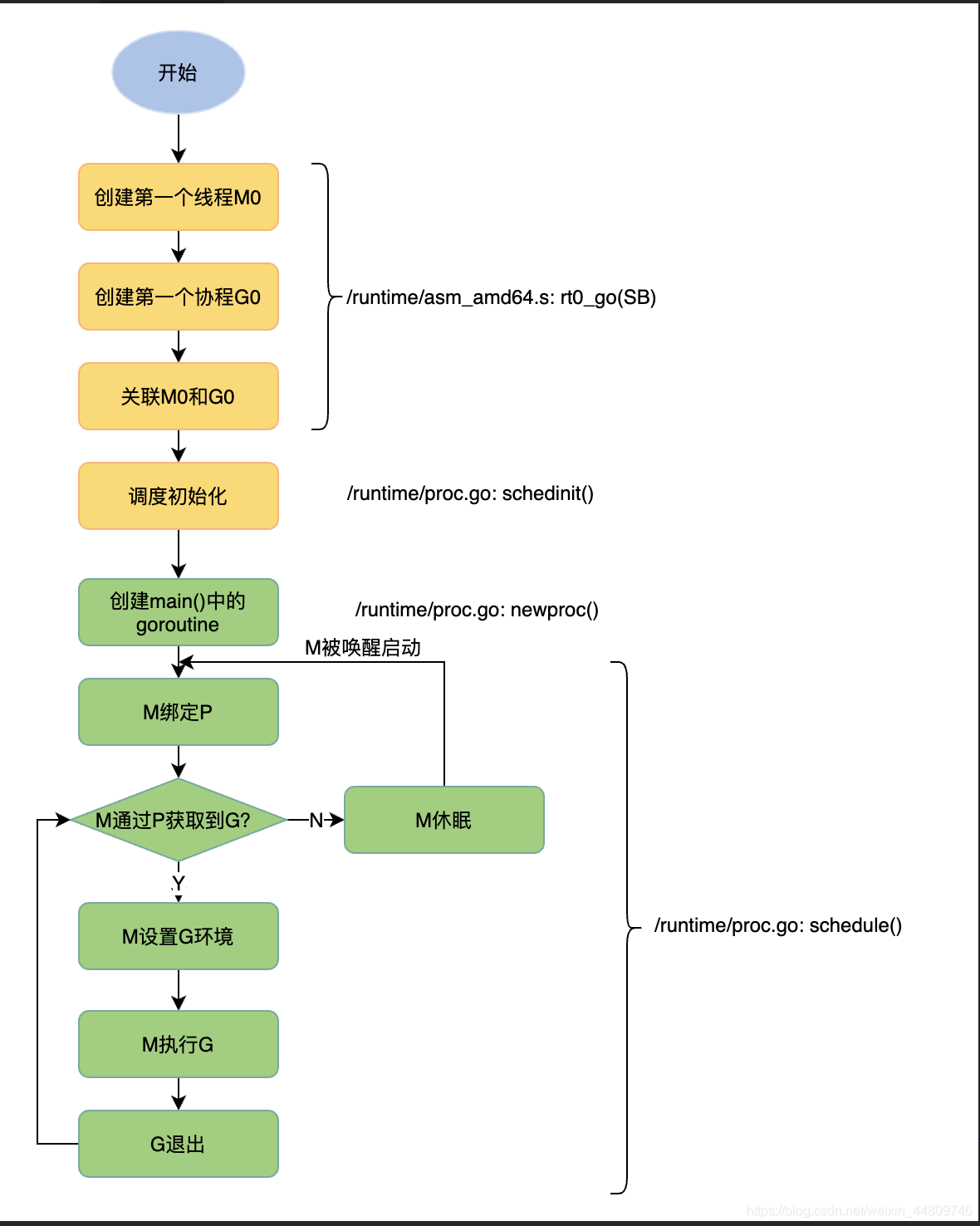
接下来,我们将逐个分析每一步的流程。
准备
我们知道,任何一个由编译型语言所编写的程序在被操作系统加载起来运行时都会顺序经过以下阶段:
- 从磁盘上把可执行程序读入内存;
- 创建进程和主线程;
- 为主线程分配栈空间;
- 把由用户在命令行输入的参数拷贝到主线程的栈;
- 把主线程放入操作系统的运行队列等待被调度执起来运行。
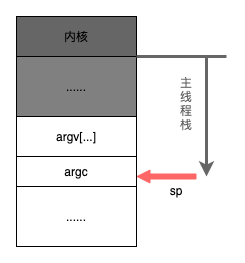
在主线程第一次被调度起来执行第一条指令之前,主线程的函数栈如下图所示,其中sp表示栈顶指针。
程序入口
使用go build编译hello.go,使用gdb调试的info files命令找到程序的入口,对应到runtime/rt0_linux_amd64.s:14
/runtime/rt0_linux_amd64.s:14
// _rt0_amd64 is common startup code for most amd64 systems when using
// internal linking. This is the entry point for the program from the
// kernel for an ordinary -buildmode=exe program. The stack holds the
// number of arguments and the C-style argv.
TEXT _rt0_amd64(SB),NOSPLIT,$-8
MOVQ 0(SP), DI // argc
LEAQ 8(SP), SI // argv
JMP runtime·rt0_go(SB)
前两行指令把操作系统内核传递过来的参数argc和argv数组的地址分别放在DI和SI寄存器中,第三行指令跳转到 rt0_go 去执行。
rt0_go函数完成了go程序启动时的所有初始化工作,包括上图中的创建M0、G0,并将二者关联起来,因此这个函数比较长,也比较繁杂。此处就不展开叙述,有兴趣可以下次分享。
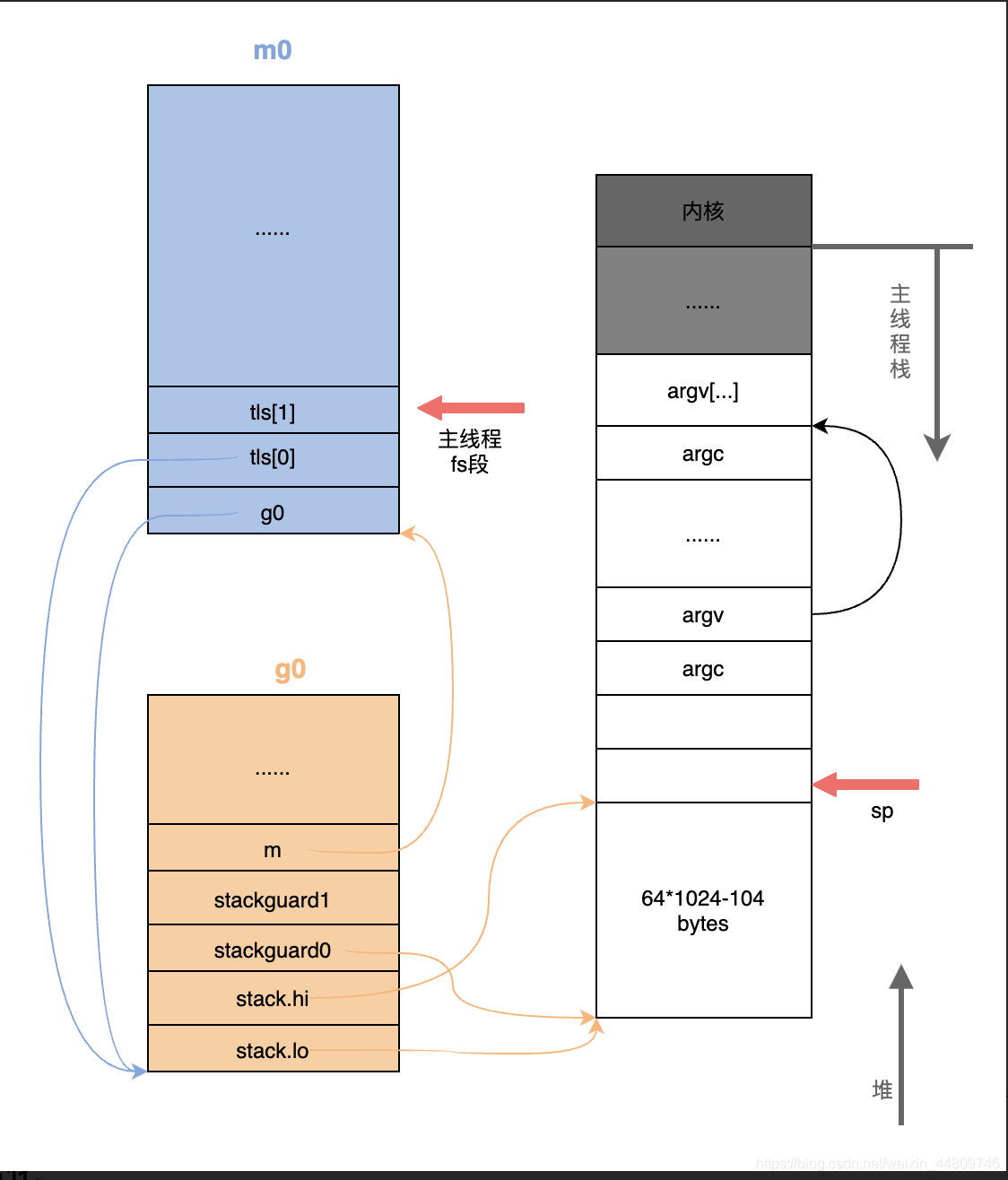
rt0_go函数完成后,内存中的线程栈如下图所示。程序创建了m0和g0,并且m0中有指针m0.g0 -> g0,g0中也有g0.m -> m.
m0中的tls指的是线程本地存储(thread local storage)。从这里还可以看到,保存在主线程m0本地存储m0.tls[0]中的值是g0的地址,也就是说工作线程的私有全局变量其实是一个指向g的指针而不是指向m的指针,目前这个指针指向g0,表示代码正运行在g0栈。
调度器初始化
在上述准备工作做完后,rt0_go函数最后会调用runtime.schedinit()函数,来初始化调度器。
/runtime/asm_amd64.go:220
CALL runtime·schedinit(SB) // 调度器初始化
调度器的初始化主要包括几个方面:
- 获取当前的Goroutine: G0。
在之前的rt0_go函数中,g0的地址已经被设置到了线程本地存储之中,schedinit()通过getg()函数(getg函数是编译器实现的,我们在源代码中是找不到其定义的)从线程本地存储中获取当前正在运行的G。 - 设置工作线程数量上限
- 初始化M0
- 创建一定数量的P,数量一般与内核数相等,并将其都放入全局队列allp中
func schedinit() {
// raceinit must be the first call to race detector.
// In particular, it must be done before mallocinit below calls racemapshadow.
//getg函数在源代码中没有对应的定义,由编译器插入类似下面两行代码
//get_tls(CX)
//MOVQ g(CX), BX; BX存器里面现在放的是当前g结构体对象的地址
_g_ := getg() // _g_ = &g0
......
//设置最多启动10000个操作系统线程,也是最多10000个M
sched.maxmcount = 10000
......
mcommoninit(_g_.m) //初始化m0,因为从前面的代码我们知道g0->m = &m0
......
sched.lastpoll = uint64(nanotime())
procs := ncpu //系统中有多少核,就创建和初始化多少个p结构体对象
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n //如果环境变量指定了GOMAXPROCS,则创建指定数量的p
}
if procresize(procs) != nil {
//创建和初始化全局变量allp
throw("unknown runnable goroutine during bootstrap")
}
......
}
其中,mcommoninit()函数用于初始化m0,它主要的工作包括以下几步:
- 给全局变量sched加锁,因为后面要读写sched中的变量sched.mnext等
- 检查已经创建的工作线程是否超过了数量限制10000,保证并发安全
- 创建用于信号处理的gsignal:从堆上分配一个g结构体对象并设置好栈。gsignal与下文的基于信号的抢占调度有关系,是m的一个成员变量。
- 把m0挂入全局链表allm中
- sched解锁
需要注意的是,在之后的运行中,如果创建了新的工作线程M,程序也会调用mcommoninit()去初始化。
之后,函数会调用procresize()函数创建和初始化全局变量allp,这个函数的主要流程有四步:
- 使用make([]*p, nprocs)初始化全局变量allp,即allp = make([]*p, nprocs)
- 循环创建并初始化nprocs个p结构体对象并依次保存在allp切片之中
- 把m0和allp[0]绑定在一起,即m0.p = allp[0],allp[0].m = m0
- 把除了allp[0]之外的所有p放入到全局变量sched的pidle空闲队列之中
到这里,调度器的初始化就全部完成了。接下来,我们看一下Go是如何创建Goroutine。
Goroutine的调度
Goroutine的调度流程如下图。
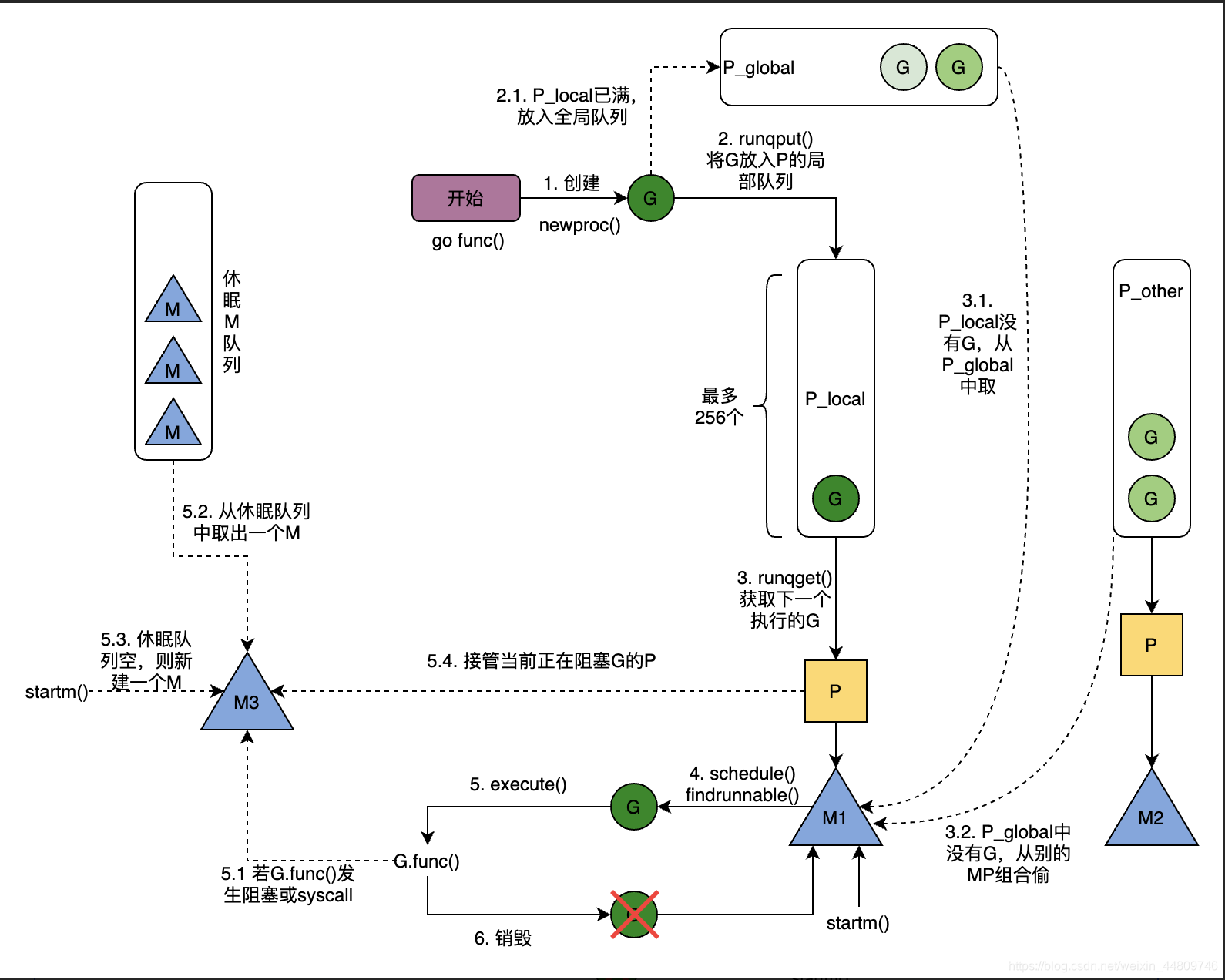
下面介绍一些在调度过程中比较重要的函数。
newproc(): 创建G
在main()中,每个go func()语句都会调用一次newproc()函数来新建一个Goroutine。
newproc()输入参数大小和函数指针,它会获取 Goroutine 以及调用方的程序计数器,然后调用newproc1()函数获取新的 Goroutine 结构体、将其加入处理器的运行队列并在满足条件时调用wakep()唤醒新的处理执行 Goroutine。简单来讲就是五步:
- 准备好当前的Goroutine,Goroutine要调用的函数,newproc()的返回地址
- 切换到G0
- 新建一个G
- 把新建的G放到当前P的本地工作队列中
- 如果M0已启动,就唤醒一个闲置的P
/runtime/proc.go:3959
// Create a new g running fn with siz bytes of arguments.
// Put it on the queue of g's waiting to run.
// The compiler turns a go statement into a call to this.
//
// The stack layout of this call is unusual: it assumes that the
// arguments to pass to fn are on the stack sequentially immediately
// after &fn. Hence, they are logically part of newproc's argument
// frame, even though they don't appear in its signature (and can't
// because their types differ between call sites).
//
// This must be nosplit because this stack layout means there are
// untyped arguments in newproc's argument frame. Stack copies won't
// be able to adjust them and stack splits won't be able to copy them.
/*
params:
siz: fn函数的参数以字节为单位的大小
fn: 函数指针,指向需要新建的goroutine对应的函数,如上面的playWithClose()
*/
func newproc(siz int32, fn *funcval) {
//函数调用参数入栈顺序是从右向左,而且栈是从高地址向低地址增长的
//注意:argp指向fn函数的第一个参数,而不是newproc函数的参数
//参数fn在栈上的地址+8的位置存放的是fn函数的第一个参数
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
gp := getg() //获取正在运行的g,初始化时是m0.g0
//getcallerpc()返回一个地址,也就是调用newproc时由call指令压栈的函数返回地址,
//对于我们现在这个场景来说,pc就是CALL runtime·newproc(SB)指令后面的POPQ AX这条指令的地址
pc := getcallerpc()
//systemstack的作用是切换到g0栈执行作为参数的函数
//如果本身就在g0栈,就什么也不做,直接调用作为参数的函数
systemstack(func() {
newg := newproc1(fn, argp, siz, gp, pc)
_p_ := getg().m.p.ptr() // 获取当前G对应的M对应的P
runqput(_p_, newg, true) // 将新建的G放入当前P的运行队列中
if mainStarted { // mainStarted=true表示主M(M0)已经启动
wakep() // 唤醒闲置的处理器P
}
})
}
这里 systemstack()会让程序从当前G切换到G0再创建新的Goroutine,这是因为普通的Goroutine很多都有no-split标记,表示该Goroutine不支持栈增长;而普通的一个Goroutine只有2KB大小的占空间,无法支持再新建一个Goroutine的内存消耗。G0的栈直接分配在线程栈上,有足够大的空间去新建Goroutine,从而避免栈溢出的问题。
wakep()
由于newproc1()函数很长,我们先来看wakep()函数。
wakep()用于在没有可用的P时,唤醒闲置的P。主要判断两个变量:
- 如果npidle > 0,即当前有空闲的P
- 如果nmspinning == 0,即没有处于spinning状态[见协程盗取章]的M,所有M都在忙
如果以上两个条件都满足,就启动一个M,并将其置为spinning状态。
// Tries to add one more P to execute G's.
// Called when a G is made runnable (newproc, ready).
func wakep() {
if atomic.Load(&sched.npidle) == 0 { // 当前没有空闲的P
return
}
// be conservative about spinning threads
if atomic.Load(&sched.nmspinning) != 0 || !atomic.Cas(&sched.nmspinning, 0, 1) {
return
}
startm(nil, true)
}
wakep()的意义在于负载均衡。我们在G0栈上创建了一个新的G,这个新的G被加入到某个P(P1)的本地队列中。
想象一下这种情况:P1已经在运行,而它的本地队列中还有闲置的G,而同时系统中还有闲置的P(设为P2)。我们已经知道,P的数量跟内核数是一致的,如果我们不唤醒一个新的P(P2),那就相当于P2对应的内核是空闲的,同时P1需要运行多个G,这就导致CPU利用率低下,任务处理速度降低。因此,我们需要进行wakep()操作去均衡。
newproc1()
接下来我们主要分析newproc1()函数。newproc1()是newproc()的核心方法,用于创建一个新的协程G。本函数比较长,可以分段分析。
第一段(如下)主要从堆上分配一个g结构体对象newg,并为这个newg分配一个大小为2048B的栈,并设置好newg的stack成员,然后把newg需要执行的函数的参数从执行newproc()函数的栈(初始化时是g0栈)拷贝到newg的栈,
// runtime/proc.go:3990
// Create a new g running fn with narg bytes of arguments starting
// at argp. callerpc is the address of the go statement that created
// this. The new g is put on the queue of g's waiting to run.
/*
params:
fn: 函数指针,指向新创建G需要执行的函数,即协程入口
argp: 指向fn第一个参数的地址,如playWithClose()中指name的地址
narg: fn函数的参数以字节为单位的大小
callergp: 父协程
callerpc: 返回地址,指调用newproc函数时,由call指令入栈的那个返回地址
*/
func newproc1(fn *funcval, argp *uint8, narg int32, callergp *g, callerpc uintptr) {
//因为已经切换到g0栈,所以无论什么场景都有 _g_ = g0,当然这个g0是指当前工作线程的g0
//对于我们这个场景来说,当前工作线程是主线程,所以这里的g0 = m0.g0
_g_ := getg()
......
// 禁止当前M被抢占,因为可能要保存一些P的相关参数
acquirem() // disable preemption because it can be holding p in a local var
......
_p_ := _g_.m.p.ptr() //初始化时_p_ = g0.m.p,从前面的分析可以知道其实就是allp[0]
newg := gfget(_p_) //从p的本地缓冲里获取一个没有使用的g,初始化时没有,返回nil
if newg == nil {
//new一个g结构体对象,然后从堆上为其分配栈,并设置g的stack成员和两个stackgard成员
newg=malg(_StackMin)
casgstatus(newg, _Gidle, _Gdead) //初始化g的状态为_Gdead
//放入全局变量allgs切片中
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
......
//调整g的栈顶置针,无需关注
totalSize := 4*sys.RegSize+uintptr(siz) +sys.MinFrameSize// extra space in case of reads slightly beyond frame
totalSize += -totalSize&(sys.SpAlign-1) // align to spAlign
sp := newg.stack.hi-totalSize
spArg := sp
......
if narg > 0 {
//把参数从执行newproc函数的栈(初始化时是g0栈)拷贝到新g的栈
memmove(unsafe.Pointer(spArg), unsafe.Pointer(argp), uintptr(narg))
......
}
这段代码执行完后,newg的状态如下。我们只需要关注红色部分,可以看到,程序中多了一个g的结构体对象newg,其stack.hi和stack.lo分别指向了它的栈空间的起止位置。
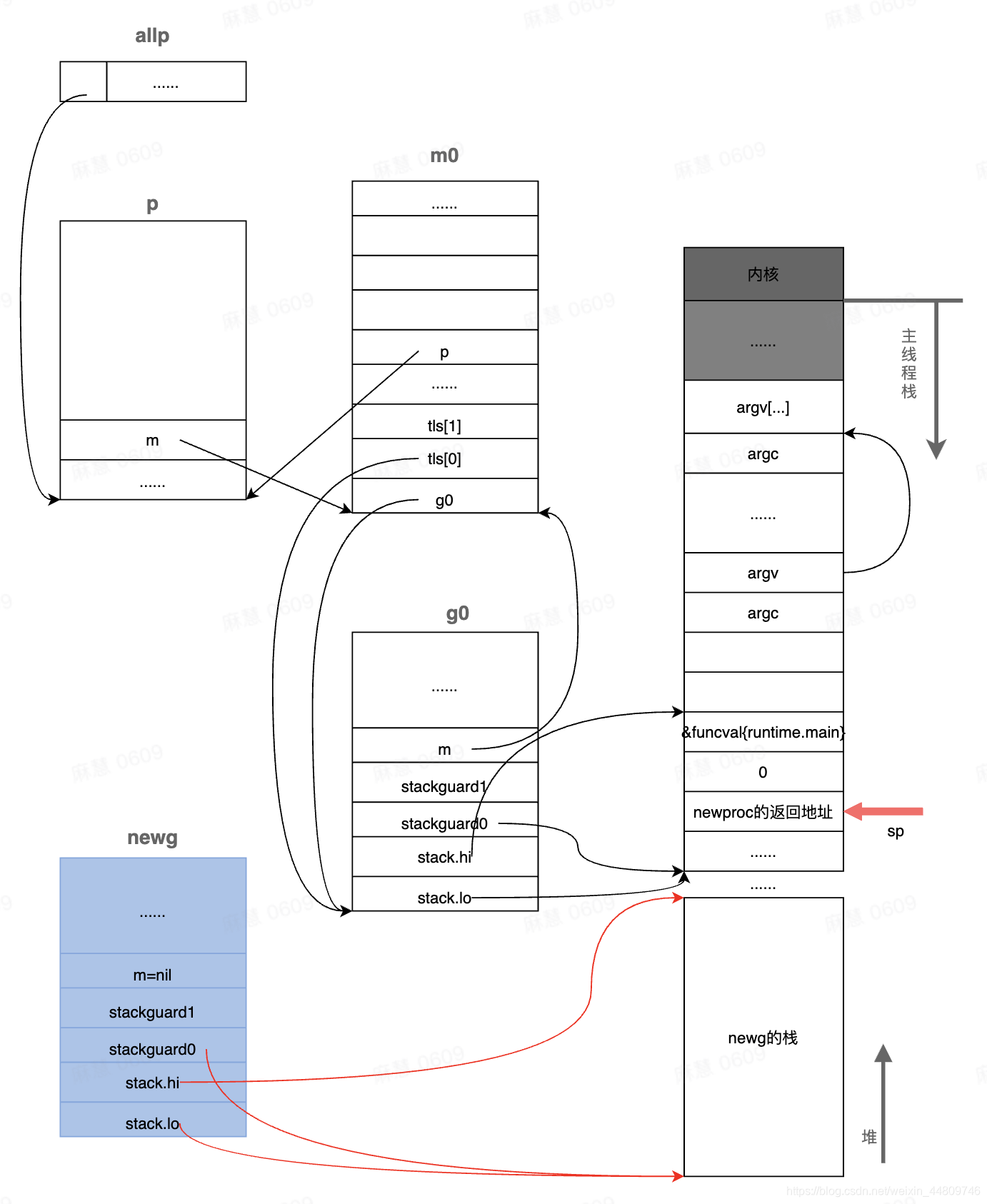
接下来的第二段代码,首先对newg的sched成员初始化,sched成员包含了调度器代码在调度goroutine到CPU运行时所必须的一些信息,其中sched的sp成员表示newg被调度起来运行时应该使用的栈的栈顶,sched的pc成员表示当newg被调度起来运行时从这个地址开始执行指令,然而从上面的代码可以看到,new.sched.pc被设置成了goexit()函数的第二条指令的地址而不是fn.fn,其原因在于gostartcallfn()函数。
这里需要注意的是,只有runtime.main对应的返回地址才是goexit()的下一条指令,而其他函数对应的返回地址都要根据函数中的调用关系确定。
//把newg.sched结构体成员的所有成员设置为0
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
//设置newg的sched成员,调度器需要依靠这些字段才能把goroutine调度到CPU上运行。
newg.sched.sp = sp //newg的栈顶
newg.stktopsp = sp
//newg.sched.pc表示当newg被调度起来运行时从这个地址开始执行指令
//把pc设置成了goexit这个函数偏移1(sys.PCQuantum等于1)的位置,
//至于为什么要这么做需要等到分析完gostartcallfn函数才知道
newg.sched.pc = funcPC(goexit) +sys.PCQuantum// +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg)) // 记录当前这个gobuf对象属于哪个goroutine
gostartcallfn(&newg.sched, fn)//调整sched成员和newg的栈
newg.gopc = callerpc //主要用于traceback
newg.ancestors = saveAncestors(callergp)
//设置newg的startpc为fn.fn,该成员主要用于函数调用栈的traceback和栈收缩
//newg真正从哪里开始执行并不依赖于这个成员,而是sched.pc
newg.startpc = fn.fn
......
//设置g的状态为_Grunnable,表示这个g代表的goroutine可以运行了
casgstatus(newg, _Gdead, _Grunnable)
......
}
gostartcallfn()
gostartcallfn() 函数首先从参数fv中提取出函数地址,然后调用gostartcall() 函数。
// adjust Gobuf as if it executed a call to fn
// and then did an immediate gosave.
func gostartcallfn(gobuf *gobuf, fv *funcval) {
varfnunsafe.Pointer
if fv != nil {
fn = unsafe.Pointer(fv.fn) //fn: gorotine的入口地址,初始化时对应的是runtime.main
} else {
fn = unsafe.Pointer(funcPC(nilfunc))
}
gostartcall(gobuf, fn, unsafe.Pointer(fv))
}
gostartcall()
gostartcall()函数主要有两个作用:
- 调整newg的栈空间,把goexit函数的第二条指令的地址入栈,伪造成goexit函数调用了fn,从而使fn执行完成后执行ret指令时返回到goexit继续执行完成最后的清理工作;
- 重新设置newg.buf.pc 为需要执行的函数的地址,即fn,我们这个场景为runtime.main函数的地址。
// adjust Gobuf as if it executed a call to fn with context ctxt
// and then did an immediate gosave.
func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) {
sp := buf.sp//newg的栈顶,目前newg栈上只有fn函数的参数,sp指向的是fn的第一参数
if sys.RegSize > sys.PtrSize {
sp -= sys.PtrSize
*(*uintptr)(unsafe.Pointer(sp)) =0
}
sp -= sys.PtrSize//为返回地址预留空间,
//这里在伪装fn是被goexit函数调用的,使得fn执行完后返回到goexit继续执行,从而完成清理工作
*(*uintptr)(unsafe.Pointer(sp)) =buf.pc//在栈上放入goexit+1的地址
buf.sp = sp//重新设置newg的栈顶寄存器
//这里才真正让newg的ip寄存器指向fn函数,注意,这里只是在设置newg的一些信息,newg还未执行,
//等到newg被调度起来运行时,调度器会把buf.pc放入cpu的IP寄存器,
//从而使newg得以在cpu上真正的运行起来
buf.pc = uintptr(fn)
buf.ctxt = ctxt
}
为什么要把返回地址设为goexit+1呢?简单来说,是为了统一Goroutine入口函数和普通函数。
我们知道,一般情况下,函数都有调用链。比如,func1()在第4行调用func2(),执行完之后继续执行第四行代码。调用func2()时,我们就需要记录它的返回地址,就是说,fun2()执行完之后的下一行指令地址。
func1() {
......
a = 1 + 2
func2()
b = 2 + a
......
}
但是对于一个Goroutine来说,它的主函数(我们简单的记为g-main())函数由于其函数入口的特殊性,没有这样一个返回地址。
为了统一g-main()函数和别的函数,我们就需要为g-main()设置一个返回地址。一个Goroutine执行结束后,会调用goexit()进行一些清扫工作。我们就可以想象成:goexit()函数一开始先调用g-main(),之后再执行它本来的指令。
因此,我们把goexit第一行指令设置为Goroutine主函数g-main()的返回地址,就能够在汇编层面统一各种函数,它们就可以用相同的方式去执行了。
goexit() {
g-main()
......
}
newproc1()的最后一段代码,主要用于设置缓存相关内容,并将当前的M设置为可被抢占状态。这样,在newproc()中,当wakep()被执行时,会唤醒一个空闲的M,这时空闲的M就可以抢占当前M的协程,开始运行了。
if _p_.goidcache == _p_.goidcacheend {
// Sched.goidgen is the last allocated id,
// this batch must be [sched.goidgen+1, sched.goidgen+GoidCacheBatch].
// At startup sched.goidgen=0, so main goroutine receives goid=1.
_p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch)
_p_.goidcache -= _GoidCacheBatch - 1
_p_.goidcacheend = _p_.goidcache + _GoidCacheBatch
}
newg.goid = int64(_p_.goidcache) // 设置唯一的goid
_p_.goidcache++
if raceenabled {
newg.racectx = racegostart(callerpc)
}
if trace.enabled {
traceGoCreate(newg, newg.startpc)
}
releasem(_g_.m) // 与上文acquirem()对应,将本M设置成可抢占状态。
return newg
}
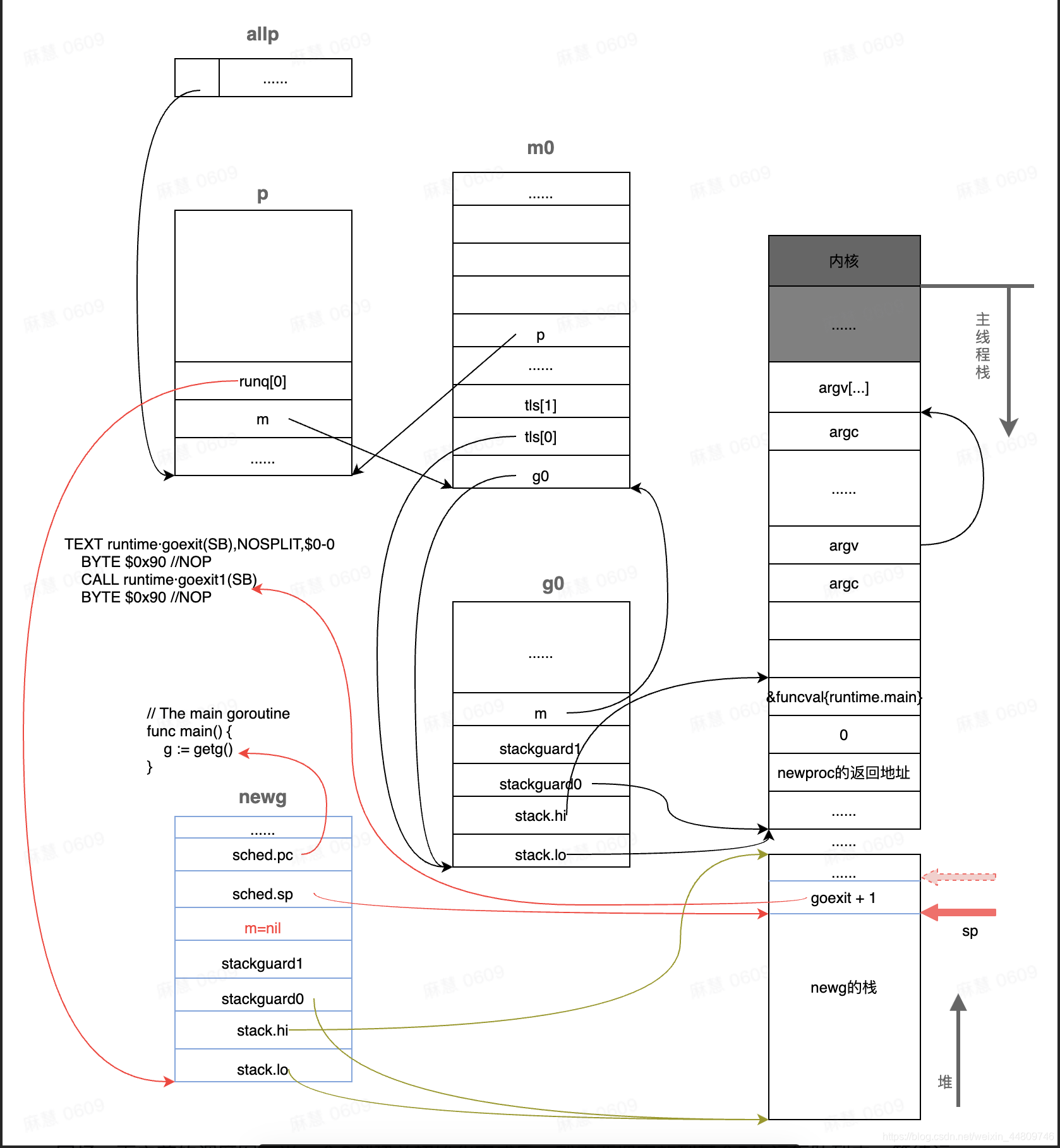
整个调用结束后,newg也就是main goroutine的状态如下,主要包括三部分内容:
- main goroutine对应的newg结构体对象的sched成员已经完成了初始化,图中只显示了pc和sp成员,pc成员指向了runtime.main函数的第一条指令,sp成员指向了newg的栈顶内存单元,该内存单元保存了runtime.main函数执行完成之后的返回地址,也就是runtime.goexit函数的第二条指令,预期runtime.main函数执行完返回之后就会去执行runtime.exit函数的CALL runtime.goexit1(SB)这条指令;
- newg已经放入与当前主线程绑定的p结构体对象的本地运行队列,因为它是第一个真正意义上的goroutine,还没有其它goroutine,所以它被放在了本地运行队列的头部;
- newg的m成员为nil,因为它还没有被调度起来运行,也就没有跟任何m进行绑定。
runqput(): 添加G
回忆一下之前的调度图,当一个G创建并初始化完成后,就需要把它放到某个P的运行队列中,等待运行。runqput()就是用于将准备好的G放入P的调度队列中的。添加G时,分为3步:
- 检查runnext是否为空,如果是,则将G放入next中;否则,执行第二步
- 检查P的本地运行队列runq是否有空位,如果有,则将G加入runq队尾;否则,执行第三步
- 检查全局队列是否有空位,如果有,则将G放入全局队列中;否则,返回第一步,重试整个过程,直到成功加入。
// runtime/proc.go:5734
// runqput tries to put g on the local runnable queue.
// If next is false, runqput adds g to the tail of the runnable queue.
// If next is true, runqput puts g in the _p_.runnext slot.
// If the run queue is full, runnext puts g on the global queue.
// Executed only by the owner P.
func runqput(_p_ *p, gp *g, next bool) {
if randomizeScheduler && next && fastrand() % 2 == 0 {
next = false
}
if next {
//把gp放在_p_.runnext成员里,
//runnext成员中的goroutine会被优先调度起来运行
retryNext:
oldnext := _p_.runnext
if !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
//有其它线程在操作runnext成员,需要重试
goto retryNext
}
if oldnext == 0 { //原本runnext为nil,所以没任何事情可做了,直接返回
return
}
// Kick the old runnext out to the regular run queue.
gp = oldnext.ptr() //原本存放在runnext的gp需要放入runq的尾部
}
retry:
//可能有其它线程正在并发修改runqhead成员,所以需要跟其它线程同步
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumers
t := _p_.runqtail
if t - h < uint32(len(_p_.runq)) { //判断队列是否满了
//队列还没有满,可以放入
_p_.runq[t % uint32(len(_p_.runq))].set(gp)
// store-release, makes it available for consumption
//虽然没有其它线程并发修改这个runqtail,但其它线程会并发读取该值以及p的runq成员
//这里使用StoreRel是为了:
//1,原子写入runqtail
//2,防止编译器和CPU乱序,保证上一行代码对runq的修改发生在修改runqtail之前
//3,可见行屏障,保证当前线程对运行队列的修改对其它线程立马可见
atomic.StoreRel(&_p_.runqtail, t + 1)
return
}
//p的本地运行队列已满,需要放入全局运行队列
if runqputslow(_p_, gp, h, t) {
return
}
// the queue is not full, now the put above must succeed
goto retry
}
这里用到了原子操作atomic.LoadAcq和atomic.StoreRel,是为了保证并发安全。
对于atomic.LoadAcq来说,其语义主要包含如下几条:
- 原子读取,也就是说不管代码运行在哪种平台,保证在读取过程中不会有其它线程对该变量进行写入;
- 位于atomic.LoadAcq之后的代码,对内存的读取和写入必须在atomic.LoadAcq读取完成后才能执行,编译器和CPU都不能打乱这个顺序;
- 当前线程执行atomic.LoadAcq时可以读取到其它线程最近一次通过atomic.CasRel对同一个变量写入的值,与此同时,位于atomic.LoadAcq之后的代码,不管读取哪个内存地址中的值,都可以读取到其它线程中位于atomic.CasRel(对同一个变量操作)之前的代码最近一次对内存的写入。
对于atomic.CasRel来说,其语义主要包含如下几条:- 原子的执行比较并交换的操作;
- 位于atomic.CasRel之前的代码,对内存的读取和写入必须在atomic.CasRel对内存的写入之前完成,编译器和CPU都不能打乱这个顺序;
- 线程执行atomic.CasRel完成后其它线程通过atomic.LoadAcq读取同一个变量可以读到最新的值,与此同时,位于atomic.CasRel之前的代码对内存写入的值,可以被其它线程中位于atomic.LoadAcq(对同一个变量操作)之后的代码读取到。
因为可能有多个线程会并发的修改和读取runqhead,以及需要依靠runqhead的值来读取runq数组的元素,所以需要使用atomic.LoadAcq和atomic.CasRel来保证上述语义。
runqputslow()
runqputslow()用于将一个待运行的G加入全局队列。
runqputslow()首先使用链表batch把从_p_的本地队列中取出的一半和G连接起来,在加锁成功后通过globrunqputbatch()把该链表链入全局运行队列(全局运行队列是使用链表实现的)。
// runtime/proc.go:5772
// Put g and a batch of work from local runnable queue on global queue.
// Executed only by the owner P.
func runqputslow(_p_ *p, gp *g, h, t uint32) bool {
var batch [len(_p_.runq) / 2 + 1]*g //gp加上_p_本地队列的一半
// First, grab a batch from local queue.
n := t - h
n = n / 2
if n != uint32(len(_p_.runq) / 2) {
throw("runqputslow: queue is not full")
}
for i := uint32(0); i < n; i++ { //取出p本地队列的一半
batch[i] = _p_.runq[(h+i) % uint32(len(_p_.runq))].ptr()
}
if !atomic.CasRel(&_p_.runqhead, h, h + n) { // cas-release, commits consume
//如果cas操作失败,说明已经有其它工作线程从_p_的本地运行队列偷走了一些goroutine,所以直接返回
return false
}
batch[n] = gp
if randomizeScheduler {
for i := uint32(1); i <= n; i++ {
j := fastrandn(i + 1)
batch[i], batch[j] = batch[j], batch[i]
}
}
// Link the goroutines.
//全局运行队列是一个链表,这里首先把所有需要放入全局运行队列的g链接起来,
//减少后面对全局链表的锁住时间,从而降低锁冲突
for i := uint32(0); i < n; i++ {
batch[i].schedlink.set(batch[i+1])
}
var q gQueue
q.head.set(batch[0])
q.tail.set(batch[n])
// Now put the batch on global queue.
lock(&sched.lock)
globrunqputbatch(&q, int32(n+1)) // 尽量减小锁粒度,降低锁冲突的概率
unlock(&sched.lock)
return true
}
值得一提的是,runqputslow函数并没有一开始就把全局运行队列锁住,而是等所有的准备工作做完之后才锁住全局运行队列,这是并发编程加锁的基本原则,需要尽量减小锁的粒度,降低锁冲突的概率。
schedule(): 调度G
接下来我们探讨一下Goroutine调度的核心策略。Go通过schedule()方法实现协程调度,主要内容是找到可执行的G并执行。schedule()分三步分别从各运行队列中寻找可运行的goroutine:
- 从全局运行队列sched.runq中寻找goroutine。为了保证调度的公平性,每个工作线程每经过61次调度就需要优先尝试从全局运行队列中找出一个goroutine来运行,这样才能保证位于全局运行队列中的goroutine得到调度的机会。全局运行队列是所有工作线程都可以访问的,所以在访问它之前需要加锁。
- 从工作线程本地运行队列中寻找goroutine。如果不需要或不能从全局运行队列中获取到goroutine则从本地运行队列中获取。
- 从其它工作线程的运行队列中偷取goroutine。如果上一步也没有找到需要运行的goroutine,则调用findrunnable()从其他工作线程的运行队列中偷取goroutine,findrunnable()在偷取之前会再次尝试从全局运行队列和当前线程的本地运行队列中查找需要运行的goroutine。
/runtime/proc.go:3049
// One round of scheduler: find a runnable goroutine and execute it.
// Never returns.
func schedule() {
_g_ := getg() //_g_ = m.g0
// getg()获取到当前的工作线程,对本函数来说,就是G0
......
var gp *g
......
if gp == nil {
// Check the global runnable queue once in a while to ensure fairness.
// Otherwise two goroutines can completely occupy the local runqueue
// by constantly respawning each other.
//为了保证调度的公平性,每个工作线程每进行61次调度就需要优先从全局运行队列中获取goroutine出来运行,
//因为如果只调度本地运行队列中的goroutine,则全局运行队列中的goroutine有可能得不到运行
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock) //所有工作线程都能访问全局运行队列,所以需要加锁
gp = globrunqget(_g_.m.p.ptr(), 1) //从全局运行队列中获取1个goroutine
unlock(&sched.lock)
}
}
if gp == nil {
//从与m关联的p的本地运行队列中获取goroutine
gp, inheritTime = runqget(_g_.m.p.ptr())
if gp != nil && _g_.m.spinning {
throw("schedule: spinning with local work")
}
}
if gp == nil {
//如果从本地运行队列和全局运行队列都没有找到需要运行的goroutine,
//则调用findrunnable函数从其它工作线程的运行队列中偷取,如果偷取不到,则当前工作线程进入睡眠,
//直到获取到需要运行的goroutine之后findrunnable函数才会返回。
gp, inheritTime = findrunnable() // blocks until work is available
}
......
//当前运行的是runtime的代码,函数调用栈使用的是g0的栈空间
//调用execte切换到gp的代码和栈空间去运行
execute(gp, inheritTime)
}
runqget(): 获取G
runqget()是P的成员函数,用于从P的本地工作队列中拿出可运行的G,给M运行。工作线程的本地运行队列分为两部分,一部分是p的runq、runqhead和runqtail这三个成员组成的一个无锁循环队列,该队列最多可包含256个goroutine;另一部分是p的runnext成员,它是一个指向g结构体对象的指针,它最多只包含一个goroutine。
寻找可执行的G时,先检查runnext是否为空,如果不空则优先运行runnext对应的G;否则从循环队列中取G。
// Get g from local runnable queue.
// If inheritTime is true, gp should inherit the remaining time in the
// current time slice. Otherwise, it should start a new time slice.
// Executed only by the owner P.
func runqget(_p_ *p) (gp *g, inheritTime bool) {
// If there's a runnext, it's the next G to run.
//从runnext成员中获取goroutine
for {
//查看runnext成员是否为空,不为空则返回该goroutine
next := _p_.runnext
if next == 0 {
break
}
if _p_.runnext.cas(next, 0) {
return next.ptr(), true
}
}
//从循环队列中获取goroutine
for {
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with other consumers
t := _p_.runqtail
if t == h {
return nil, false
}
gp := _p_.runq[h%uint32(len(_p_.runq))].ptr()
if atomic.CasRel(&_p_.runqhead, h, h+1) { // cas-release, commits consume
return gp, false
}
}
}
其中,cas(a,b)表示CompareAndSwap操作。因为别的工作线程有可能正在访问这两个(runnext和runq)成员,从这里偷取G,因此使用CAS来防止并发错误。
CAS不需要申请锁,可以有效的减少使用锁所带来的开销,但是需要注意在高并发下这是使用cpu资源做交换的。
func CompareAndSwap(p *Type, a Type, b Type) {
if p == a {
p = b
return true
}
return false
}
globrunqget()
globrunqget()用于从全局队列中取出G运行。首先根据全局运行队列中goroutine的数量runqsize计算出该拿多少个goroutine,然后把第一个g结构体对象通过返回值的方式返回给调用函数,其它的则通过runqput()放入当前工作线程的本地运行队列。
// runtime/proc.go:5569
// Try get a batch of G's from the global runnable queue.
// Sched must be locked.
/*
params:
_p_: 与当前工作线程绑定的P
max: 最多可以从全局队列中拿max个G到当前工作线程的本地运行队列中
*/
func globrunqget(_p_ *p, max int32) *g {
if sched.runqsize == 0 { //全局运行队列为空
return nil
}
//根据p的数量平分全局运行队列中的goroutines
// 此处做了负载均衡
n := sched.runqsize/gomaxprocs + 1
if n > sched.runqsize { //上面计算n的方法可能导致n大于全局运行队列中的goroutine数量
n = sched.runqsize
}
if max > 0 && n > max {
n = max //最多取max个goroutine
}
if n > int32(len(_p_.runq))/2 {
n = int32(len(_p_.runq)) / 2 //最多只能取本地队列容量的一半
}
sched.runqsize -= n
//gp直接通过函数返回,其它的goroutines通过runqput放入本地运行队列
gp := sched.runq.pop() //pop从全局运行队列的队列头取
n--
for ; n > 0; n-- {
gp1 := sched.runq.pop() //从全局运行队列中取出一个goroutine
runqput(_p_, gp1, false) //放入本地运行队列
}
return gp
}
从全局队列中取G时,不是只取1个,而是根据P的数量平分全局队列中的G,取多个。这么做的原因可以多方面分析:
从全局队列的角度,这是一种负载均衡,减少CPU时间浪费。全局队列中一共有runqsize个G,想象一种极端情况:所有的P的本地队列中都没有可用的G了,所有的P都到全局队列中获取G,这时候将全局队列中的G平分给P是最佳策略,能够减少CPU的时间浪费。
从P的角度,一次性取多个而不是一个G,可以减少访问全局队列的次数,减少时间开销。想象一种情况:内核中只有一个P,P的本地队列为空,且一直没有新的G进入。如果每次访问全局队列都只取一个G,那就会不断地访问全局队列。而访问全局队列需要加锁、解锁,锁应用是很耗时间的。因此,一次性取尽可能多的G,可以有效地减少时间开销。
可以这么说,globrunqget()函数是在CPU利用率和P访问全局队列之间做了平衡,兼顾双方。
G P M状态转换
G(Goroutine)的一生
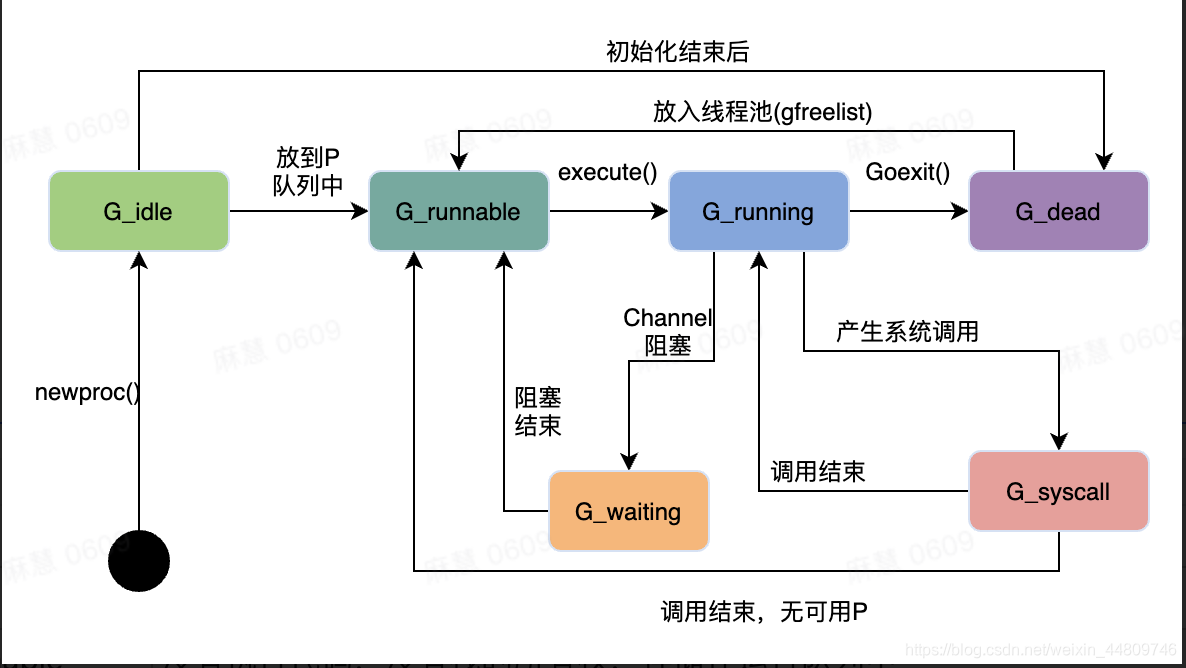
| 状态 | 描述 |
|---|---|
| _Gidle | 刚刚被分配并且还没有被初始化 |
| _Grunnable | 没有执行代码,没有栈的所有权,存储在运行队列中 |
| _Grunning | 可以执行代码,拥有栈的所有权,被赋予了内核线程 M 和处理器 P |
| _Gsyscall | 正在执行系统调用,拥有栈的所有权,没有执行用户代码,被赋予了内核线程 M 但是不在运行队列上 |
| _Gwaiting | 由于运行时而被阻塞,没有执行用户代码并且不在运行队列上,但是可能存在于 Channel 的等待队列上 |
| _Gdead | 没有被使用,没有执行代码,可能有分配的栈 |
| _Gcopystack | 栈正在被拷贝,没有执行代码,不在运行队列上 |
| _Gpreempted | 由于抢占而被阻塞,没有执行用户代码并且不在运行队列上,等待唤醒 |
| _Gscan | GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在 |
P(Process)的一生
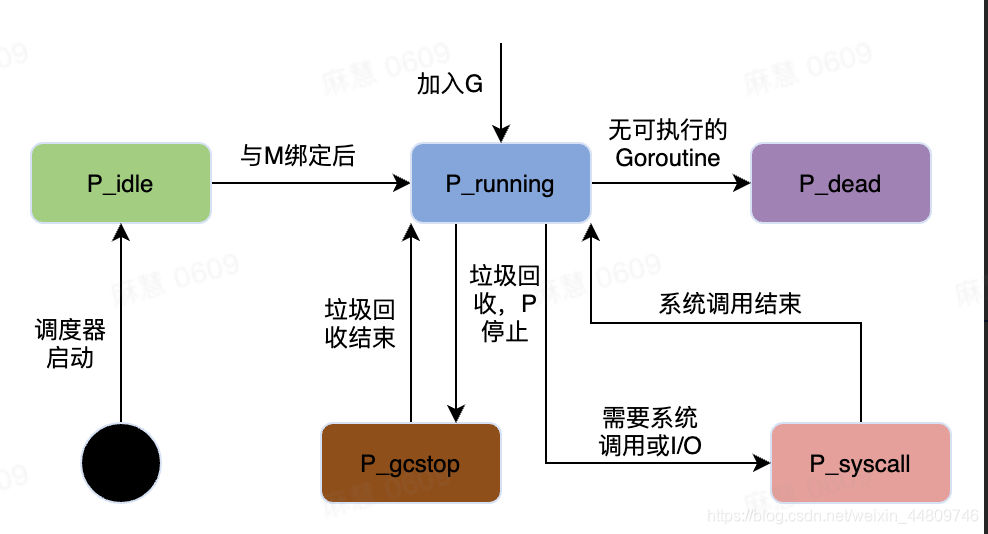
| 状态 | 描述 |
|---|---|
| _Pidle | 处理器没有运行用户代码或者调度器,被空闲队列或者改变其状态的结构持有,运行队列为空 |
| _Prunning | 被线程 M 持有,并且正在执行用户代码或者调度器 |
| _Psyscall | 没有执行用户代码,当前线程陷入系统调用 |
| _Pgcstop | 被线程 M 持有,当前处理器由于垃圾回收被停止 |
| _Pdead | 当前处理器已经不被使用 |
协程盗取
从Goroutine的调度过程中我们可以看到,当P的本地工作队列中没有可运行的G时,程序会执行findrunnable()函数到别的工作进程中盗取G。这就是基于工作窃取的调度器的核心内容。
findrunnable()
findrunnable() 函数负责处理与盗取相关的逻辑,该函数代码很繁杂,因为它还做了与gc和netpoll等相关的事情,为了不影响我们的分析思路,这里我们把不相关的代码删掉了,不过代码还是比较多,但总结起来就一句话:尽力去各个运行队列中寻找goroutine,如果实在找不到则进入睡眠状态。
gc指垃圾回收,会清理内存以便提供给后来的协程使用; netpoll指的是从I/O阻塞队列中恢复已经完成I/O的G,并将其放入全局队列sched.runq中。
函数的主要步骤分top和stop两部分,top部分表示工作窃取的流程,stop部分表示让当前的M进入休眠。
top:
- 检查本地运行队列是否有需要运行的Goroutine,有则返回(有可用G)
- 检查全局队列有无可用Goroutine,有则返回(有可用G)
- 检查别的工作线程M是否都已休眠,是则返回(无可用G)
- 检查是否有很多M都在偷G,是则返回(避免太多CPU消耗,进入stop)
- 随机排列其他M,依次去盗取G,有则返回(有可用G)
stop:
- 保存当前P队列allp的快照
- 给G的全局队列加锁
- 检查G的全局队列中是否有可用的Goroutine,有则返回(有可用G)
- 把当前工作线程M和P解除绑定
- 把P放入空闲队列
- 给G的全局队列解锁
- 休眠之前,再次检查有无可用的Goroutine,有则进入top,再次试图获取可用G
- 进入休眠
// Finds a runnable goroutine to execute.
// Tries to steal from other P's, get g from global queue, poll network.
func findrunnable() (gp *g, inheritTime bool) {
_g_ := getg()
// The conditions here and in handoffp must agree: if
// findrunnable would return a G to run, handoffp must start
// an M.
top:
_p_ := _g_.m.p.ptr()
......
// local runq
//再次看一下本地运行队列是否有需要运行的goroutine
if gp, inheritTime := runqget(_p_); gp != nil {
return gp, inheritTime
}
// global runq
//再看看全局运行队列是否有需要运行的goroutine
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false
}
}
......
// Steal work from other P's.
//如果除了当前工作线程还在运行外,其它工作线程已经处于休眠中,那么也就不用去偷了,肯定没有
procs := uint32(gomaxprocs)
if atomic.Load(&sched.npidle) == procs-1 {
// Either GOMAXPROCS=1 or everybody, except for us, is idle already.
// New work can appear from returning syscall/cgocall, network or timers.
// Neither of that submits to local run queues, so no point in stealing.
goto stop
}
// If number of spinning M's >= number of busy P's, block.
// This is necessary to prevent excessive CPU consumption
// when GOMAXPROCS>>1 but the program parallelism is low.
// 这个判断主要是为了防止因为寻找可运行的goroutine而消耗太多的CPU。
// 因为已经有足够多的工作线程正在寻找可运行的goroutine,让他们去找就好了,自己偷个懒去睡觉
if !_g_.m.spinning && 2*atomic.Load(&sched.nmspinning) >= procs-atomic.Load(&sched.npidle) {
goto stop
}
if !_g_.m.spinning {
//设置m的状态为spinning
_g_.m.spinning = true
//处于spinning状态的m数量加一
atomic.Xadd(&sched.nmspinning, 1)
}
//从其它p的本地运行队列盗取goroutine
for i := 0; i < 4; i++ {
for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() {
if sched.gcwaiting != 0 {
goto top
}
stealRunNextG := i > 2 // first look for ready queues with more than 1 g
if gp := runqsteal(_p_, allp[enum.position()], stealRunNextG); gp != nil {
return gp, false
}
}
}
stop:
......
// Before we drop our P, make a snapshot of the allp slice,
// which can change underfoot once we no longer block
// safe-points. We don't need to snapshot the contents because
// everything up to cap(allp) is immutable.
allpSnapshot := allp
// return P and block
lock(&sched.lock)
......
if sched.runqsize != 0 {
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
return gp, false
}
// 当前工作线程解除与p之间的绑定,准备去休眠
if releasep() != _p_ {
throw("findrunnable: wrong p")
}
//把p放入空闲队列
pidleput(_p_)
unlock(&sched.lock)
// Delicate dance: thread transitions from spinning to non-spinning state,
// potentially concurrently with submission of new goroutines. We must
// drop nmspinning first and then check all per-P queues again (with
// #StoreLoad memory barrier in between). If we do it the other way around,
// another thread can submit a goroutine after we've checked all run queues
// but before we drop nmspinning; as the result nobody will unpark a thread
// to run the goroutine.
// If we discover new work below, we need to restore m.spinning as a signal
// for resetspinning to unpark a new worker thread (because there can be more
// than one starving goroutine). However, if after discovering new work
// we also observe no idle Ps, it is OK to just park the current thread:
// the system is fully loaded so no spinning threads are required.
// Also see "Worker thread parking/unparking" comment at the top of the file.
wasSpinning := _g_.m.spinning
if _g_.m.spinning {
//m即将睡眠,状态不再是spinning
_g_.m.spinning = false
if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 {
throw("findrunnable: negative nmspinning")
}
}
// check all runqueues once again
// 休眠之前再看一下是否有工作要做
for _, _p_ := range allpSnapshot {
if !runqempty(_p_) {
lock(&sched.lock)
_p_ = pidleget()
unlock(&sched.lock)
if _p_ != nil {
acquirep(_p_)
if wasSpinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
goto top
}
break
}
}
......
//休眠
stopm()
goto top
}
findrunnable()里有两个地方设计很巧妙:
第一个是48行,在检查期间,会检查spinning状态的M是否多于忙碌的P的数量,如果是,表示已经有足够多的M在试图偷取别人的G了,那当前的M就不去偷了,跳转到stop。这是因为,只有忙碌状态的P的本地队列中有可以被偷取的G,而当试图偷取别人的G的M > 可被偷取的P时,来再多的前者也只能排队阻塞,这会带来不必要的CPU开销,不如直接去stop;
第二个是64行,定义了一个变量stealRunNextG,这个变量是runqsteal()的入参之一,表示是否偷取runnext中的G。这里取stealRunNextG = i > 2,是为了尽可能均衡地偷取到G。我们先假设是P试图偷取P0/P1/P2/P3的G,且for循环只有四次,意味着如果前三次都只会尝试偷取本地运行队列中的G,而最后一次会尝试偷取P3的本地运行队列和runnext的G。前三次不偷取runnext是因为,假如P2的本地运行队列中没有G,但P2的runnext有G,且P3的本地运行队列中有多个G,这种情况如果在P2时就把P2.runnext偷取完,就不会访问P3,这时候P有1个G,P2没有G,P3有多个G,很明显会导致内核负载不平衡。再考虑第二种情况,如果P0/P1/P2/P3本地运行队列都没有G,而P3.runnext有一个G,此时P3同时还在运行一个G(如果P3没在运行就不会被偷),这时候如果不去偷P3.runnext,就会变成:P:0个,P0/P1/P2:正在运行1个,P3:运行1个+等待1个。显然P和P3不均衡,所以需要去偷1个。
自旋状态
自旋状态,即spinning,工作线程M在从其它工作线程的本地运行队列中盗取goroutine时的状态称为自旋状态。
从上面代码可以看到,当前M在去其它p的运行队列盗取goroutine之前把spinning标志设置成了true,同时增加处于自旋状态的M的数量,而盗取结束之后则把spinning标志还原为false,同时减少处于自旋状态的M的数量,在top代码块的第四步,就需要根据自旋状态的M的数量决定当前M是否进入休眠;对应的,当有空闲P又有goroutine需要运行的时候,这个处于自旋状态的M的数量决定了是否需要唤醒或者创建新的工作线程。
盗取算法
盗取过程findrunnable():59-69用了两个嵌套for循环。内层循环实现了盗取逻辑,从代码可以看出盗取的实质就是遍历allp中的所有p,查看其运行队列是否有goroutine,如果有,则取其一半到当前工作线程的运行队列,然后从findrunnable返回,如果没有则继续遍历下一个p。但这里为了保证公平性,使用stealOrder.start(fastrand()),遍历allp时并不是固定的从allp[0]即第一个p开始,而是从随机位置上的p开始,而且遍历的顺序也随机化了,并不是现在访问了第i个p下一次就访问第i+1个p,而是使用了一种伪随机的方式遍历allp中的每个p,防止每次遍历时使用同样的顺序访问allp中的元素。
随机遍历P的伪代码如下:
offset := uint32(random()) % nprocs
coprime := 随机选取一个小于nprocs且与nprocs互质的数
for i := 0; i < nprocs; i++ {
p := allp[offset]
从p的运行队列偷取goroutine
if 偷取成功 {
break
}
offset += coprime
offset = offset % nprocs
}
举个例子:假设nprocs=8,即一共有8个P。
第一次随机选择offset=6, coprime=3,则对allp的遍历顺序为:6 1 4 7 2 5 0 3
offset=6
(6+3)%8=1
(1+3)%8=4
(4+3)%8=7
(7+3)%8=2
(2+3)%8=5
(5+3)%8=0
(0+3)%8=3
可以证明,不管nprocs是多少,这个算法都可以保证经过nprocs次循环,每个p都可以得到访问。
挑选出盗取的对象p之后,则调用runqsteal盗取p的运行队列中的goroutine。
runqsteal()
runqsteal()实现了如何从p2中偷取一半的G放到_p_的本地工作队列中,第三个参数stealRunNextG表示是否去偷取p2的runnext。
本函数主要有步:
- 检查p2,得知可以偷取的G的个数n,在runqgrab()中,已经将偷取到的G放在了_p_的本地工作线程中
- 如果n=0,就说明没有偷到G;否则,定位到_p_.runq现在真正的末尾,并将最后一个G作为下一个要运行的gp返回
- 如果n>1,就需要检查当前的runq,是否发生溢出,这是为了保证代码的鲁棒性。第16-18行可能出现的场景是:当h和t增长到超过uint32最大值的时候,即Goroutine的个数增长到2^32个。
// Steal half of elements from local runnable queue of p2
// and put onto local runnable queue of p.
// Returns one of the stolen elements (or nil if failed).
func runqsteal(_p_, p2 *p, stealRunNextG bool) *g {
t := _p_.runqtail
n := runqgrab(p2, &_p_.runq, t, stealRunNextG)
if n == 0 {
return nil
}
n--
gp := _p_.runq[(t+n)%uint32(len(_p_.runq))].ptr()
if n == 0 {
return gp
}
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumers
if t-h+n >= uint32(len(_p_.runq)) {
throw("runqsteal: runq overflow")
}
atomic.StoreRel(&_p_.runqtail, t+n) // store-release, makes the item available for consumption
return gp
}
runqgrab()
runqgrab()从_p_中偷取一半的G,从batchHead开始依次放到batch中,并返回偷取的G的个数。stealRunNextG=true表示可以偷取_p_.runnext。偷取的过程如下:
- 判断_p_的本地工作队列有没有G:如果有,则跳到3;如果没有,则尝试偷取_p_的runnext,跳到2;
- 如果能偷到_p_.runnext,则返回,偷到1个;
- 尝试偷取_p_本地工作队列中的一半G,并放到batch中。
// Grabs a batch of goroutines from _p_'s runnable queue into batch.
// Batch is a ring buffer starting at batchHead.
// Returns number of grabbed goroutines.
// Can be executed by any P.
func runqgrab(_p_ *p, batch *[256]guintptr, batchHead uint32, stealRunNextG bool) uint32 {
for {
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with other consumers
t := atomic.LoadAcq(&_p_.runqtail) // load-acquire, synchronize with the producer
n := t - h
n = n - n/2
if n == 0 {
if stealRunNextG {
// Try to steal from _p_.runnext.
if next := _p_.runnext; next != 0 {
if _p_.status == _Prunning {
// Sleep to ensure that _p_ isn't about to run the g
// we are about to steal.
// The important use case here is when the g running
// on _p_ ready()s another g and then almost
// immediately blocks. Instead of stealing runnext
// in this window, back off to give _p_ a chance to
// schedule runnext. This will avoid thrashing gs
// between different Ps.
// A sync chan send/recv takes ~50ns as of time of
// writing, so 3us gives ~50x overshoot.
if GOOS != "windows" {
usleep(3)
} else {
// On windows system timer granularity is
// 1-15ms, which is way too much for this
// optimization. So just yield.
osyield()
}
}
if !_p_.runnext.cas(next, 0) {
continue
}
batch[batchHead%uint32(len(batch))] = next
return 1
}
}
return 0
}
//小细节:按理说队列中的goroutine个数最多就是len(_p_.runq),
//所以n的最大值也就是len(_p_.runq)/2,那为什么需要这个判断呢?
if n > uint32(len(_p_.runq)/2) { // read inconsistent h and t
continue
}
for i := uint32(0); i < n; i++ {
g := _p_.runq[(h+i)%uint32(len(_p_.runq))]
batch[(batchHead+i)%uint32(len(batch))] = g
}
if atomic.CasRel(&_p_.runqhead, h, h+n) { // cas-release, commits consume
return n
}
}
}
在代码中46-48行,代码中n的计算很简单,从计算过程来看n应该是runq队列中goroutine数量的一半,它的最大值不会超过队列容量的一半,但为什么这里的代码却偏偏要去判断n是否大于队列容量的一半呢?这里关键点在于读取runqhead和runqtail是两个操作而非一个原子操作,当我们读取runqhead之后但还未读取runqtail之前,如果有其它线程快速的在增加(这是完全有可能的,其它偷取者从队列中偷取goroutine会增加runqhead,而队列的所有者往队列中添加goroutine会增加runqtail)这两个值,则会导致我们读取出来的runqtail已经远远大于我们之前读取出来放在局部变量h里面的runqhead了,也就是代码注释中所说的h和t已经不一致了,所以这里需要这个if判断来检测异常情况。
Goroutine的抢占
介绍抢占之前,需要先介绍Golang的一个线程sysmon(),这是实现Golang中抢占式调度的重要函数。
sysmon()线程
sysmon()是Golang的监控线程,它在程序一开始就被创建,游离于工作线程之外,不被GMP模型调度。sysmon()主要用于监控Goroutine运行,有三个作用:
- 网络轮询器监控:
- 系统调用syscall监控
- 垃圾回收GC
网络轮询器
在GPM模型中当网络请求导致的运行阻塞时,调度器会让当前阻塞的G放入网络轮询器(NetPoller)中,由网络轮询器处理异步网络系统调用,从而让出 P 执行其它goroutine。当异步网络调用由网络轮询器完成后,再由sysmon监控线程将其切换回来继续执行。
如下图a序列,sysmon监控线程会每隔 20us~10ms 轮询一次,检查当前网络轮询器中的所有 G 距离 runtime.netpoll 被调用是否超过了10ms,如果是说明当前G执行时间太长了,则通过 injectglist() 将其放入 全局运行队列 (对于 sysmon 线程来说,它的执行是完全脱离P运行的,所以不可能被放回本地运行队列。但在 findrunnable() 函数里调用 injectglist() 函数是可以放入P的),等待下一次的继续执行。
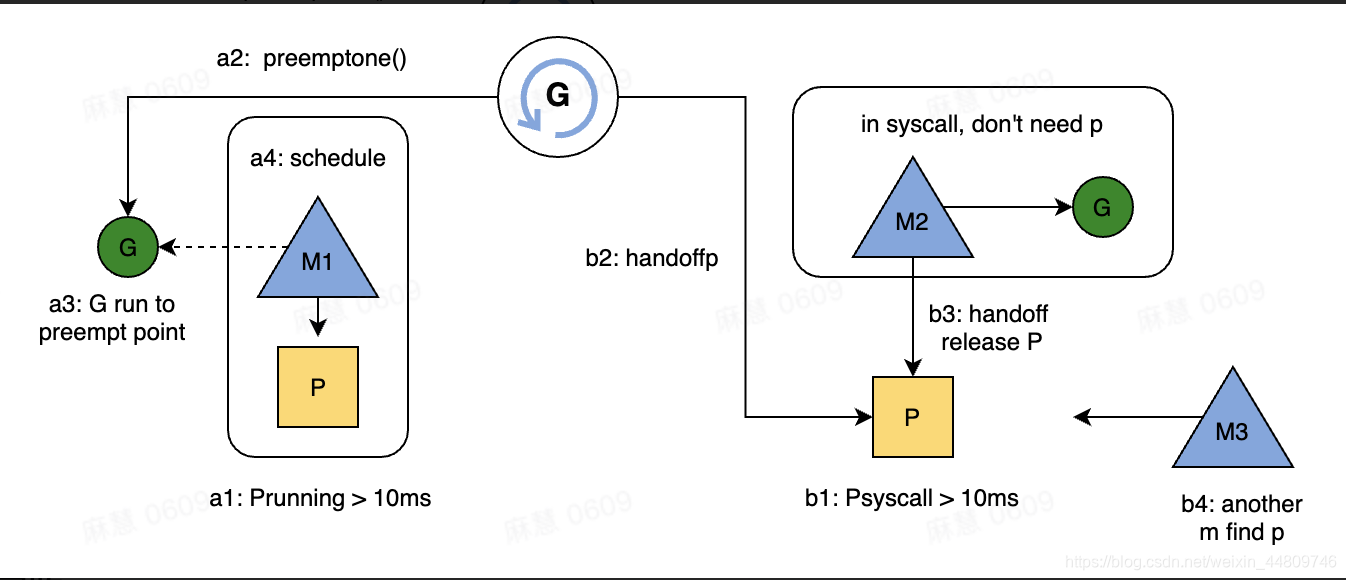
系统调用syscall监控
系统调用监控如下图b序列,如果监测到某个P已经陷入系统调用超过10ms,则发起handoffp,令G和M一起切换出去;之后将P挂到另一个可执行的M上,去执行可运行的G。
不支持在 Docs 外粘贴 block
垃圾回收
如果垃圾回收器超过两分钟没有执行的话,sysmon 监控线程也会强制进行GC。
接下来回到抢占式调度。基于工作窃取的多线程调度器将每一个线程绑定到了独立的CPU上,这些线程会被不同处理器管理,不同的处理器通过工作窃取对任务进行再分配实现任务的平衡,也能提升调度器和 Go 语言程序的整体性能,今天所有的 Go 语言服务都受益于这一改动。
但是,这并不能解决两种问题:
- 如果有一些Goroutine因为一些原因永远不停止,其他Goroutine会无限制等待,造成饥饿;
- 在垃圾回收(GC)时,需要暂停整个程序(Stop-the-world, STW),最长可能需要几分钟时间,导致整个程序无法工作。
因此,1.2版本以后的Go语言调度器引入了基于协作的抢占式调度,用以解决这两个问题。
基于协作的抢占式调度
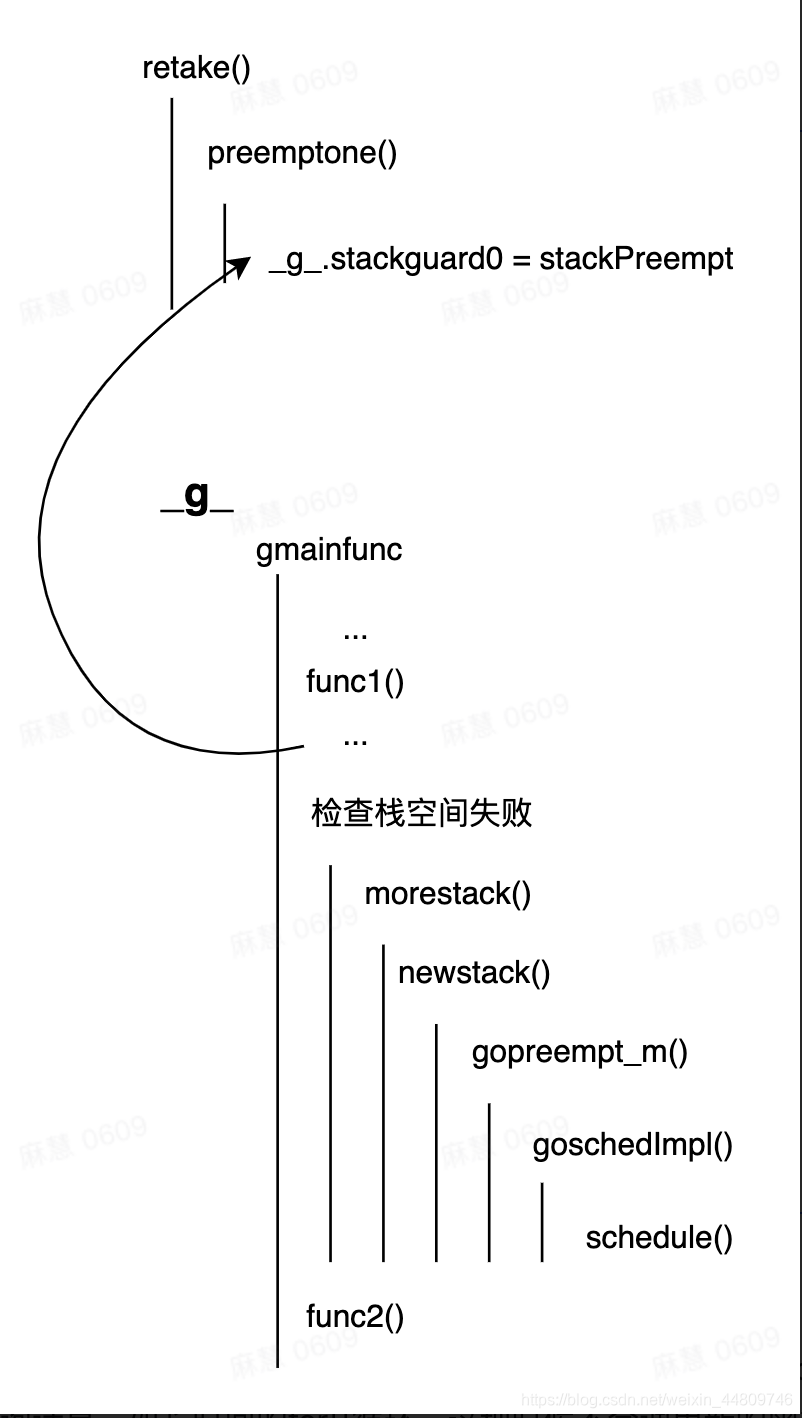
基于协作的抢占式调度主要的思想是,给每个Goroutine一个标志stackguard0,用于标记该Goroutine是否能被抢占。在这个Goroutine调用函数之前,检查标志位,如果可以被抢占,则触发抢占,让出它所在的当前工作线程M。
retake()是抢占前的检测标记逻辑,用于检测当前这个_g_是否满足“可以被抢占”的条件,如果满足,就可以调用preemptone()将这个_g_.stackguard0设置为stackPreempt,表示当前的_g_可以被抢占。
而对于_g_本身来说,在它每次需要进入一个新函数(如图中需要进入func2时)的时候,就会触发栈空间检测,这时发现检查失败,就会调用morestack()去进行抢占。
基于信号的抢占式调度
从上面可以看出,当Goroutine陷入到大量计算或者长时间处于系统调用时,sysmon()都能够扫描到并进行抢占。但是,遇到轮询计算,如长时间的for{}循环,这种时候不会调用新的函数,也就无法进行栈空间检查,也就无法检测stackguard0,从而无法进行抢占。也就是说,基于协作的抢占式调度不能保证“任何时候任何地点(代码段)”的抢占,因此,在1.4版本之后引入了基于信号的抢占式调度。它可以实现异步的抢占。
基于信号的抢占的原理很简单:
4. 注册绑定SIGURG信号及处理方法runtime.doSigPreempt
5. sysmon()间隔性地检测超时的P,并发送信号
6. M收到信号后将正在执行的G休眠
7. M调用schedule()重新进行调度
参考文献
墨记
【幼麟实验室】Golang合辑
go语言设计与实现
goroutine的源码实现
go语言原本
Golang 源码分析 - goroutine
【典藏版】 Golang 调度器 GMP 原理与调度全分析 | Go 技术论坛
我可能并不会使用golang goroutine
golang 异步抢占例子
Golang 抢占调度流程分析
认识Golang中的sysmon监控线程 | 学习笔记
go1.14基于信号的抢占式调度实现原理 – 峰云就她了

















 2220
2220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









