







引言
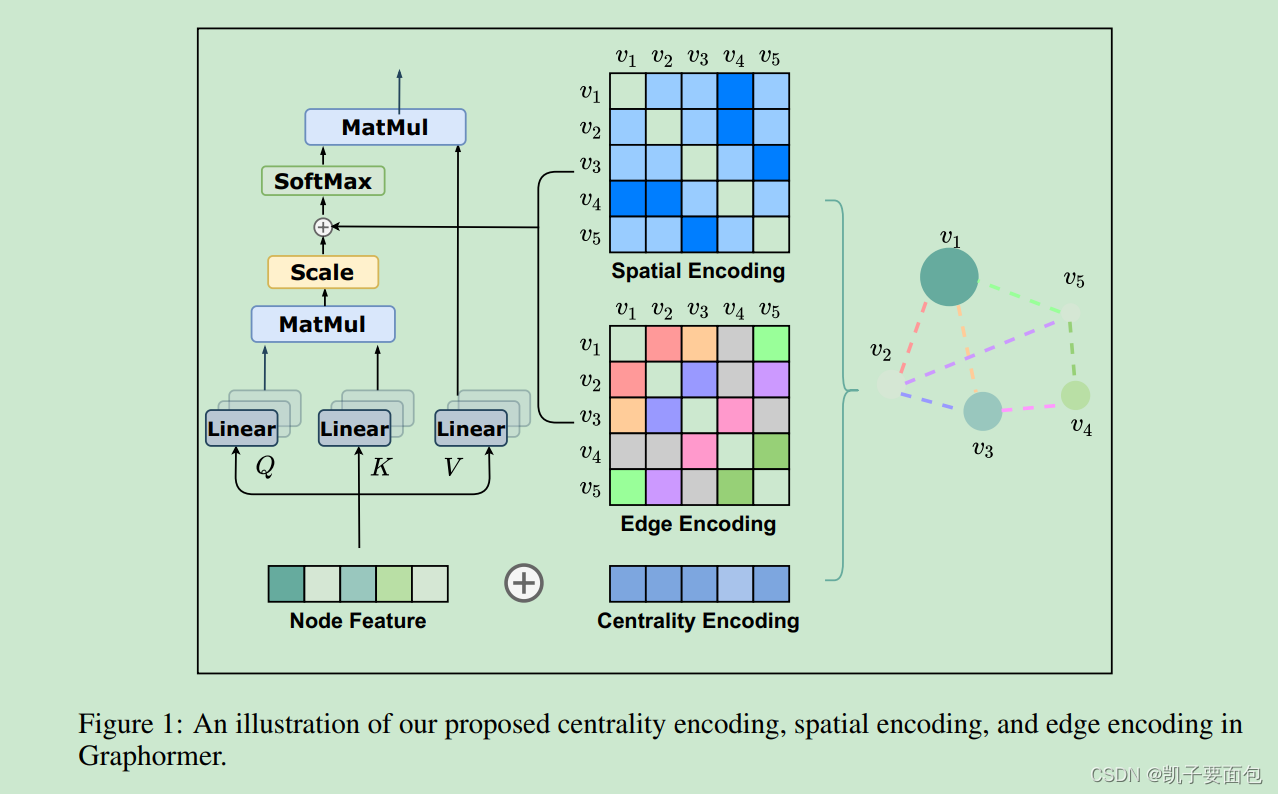
论文提出 Graphormer 对“图数据结构”进行表征学习,Graphormer 是基于标准 Transformer 模型结构, 通过加入 Centrality Encoding、Spatial Encoding 、Edge Encoding 技术编码图结构信息, Centrality Encoding 主要用于编码节点的重要度信息, Spatial Encoding 主要用于编码节点位置结构信息。模型示意图如下:
Graph Neural Network
给定一个图对象 G = ( V , E ) G=(V, E) G=(V,E), V = { v 1 , v 2 , . . . , v n } V=\{v_1, v_2, ..., v_n\} V={v1,v2,...,vn} 表示节点集合, x i x_i xi 表示特定节点对应的特征向量,GNN网络的目标是学习节点的向量表征、与图对象的向量表征。
对节点的表征学习遵从 AGGREGATE-COMBINE 模式,用
h
i
l
h_i^l
hil 表示节点
i
i
i 第
l
l
l 次迭代对应的特征向量,并且
h
i
0
=
x
i
h_i^0 = x_i
hi0=xi,则:
a
i
l
=
A
G
G
R
E
G
A
T
E
(
{
h
j
(
l
−
1
)
,
j
∈
N
(
v
i
)
}
)
h
i
l
=
C
O
M
B
I
N
E
(
h
i
(
l
−
1
)
,
a
i
l
)
a_i^l = AGGREGATE(\{h_j^{(l-1)}, j\in N(v_i)\}) \newline h_i^l = COMBINE(h_i^{(l-1)}, a_i^l)
ail=AGGREGATE({hj(l−1),j∈N(vi)})hil=COMBINE(hi(l−1),ail)
N ( v i ) N(v_i) N(vi) 表示节点 i i i 的邻居节点集合, a i l a_i^l ail 实质是从邻居节点中抽取信息,而 $h_i^l $ 对邻居节点信息与自身特征信息进行融合。
为了得到图对象整体的表征,可以在最后一次迭代
L
L
L 中,对所有节点的表征向量进行聚合,
h
G
=
R
E
A
D
O
U
T
(
{
h
i
L
,
i
∈
G
}
)
h_G=READOUT(\{h_i^L, i \in G\})
hG=READOUT({hiL,i∈G}), 得到的
h
G
h_G
hG 就可以作为图表征向量。
Transformer
Transformer 的核心是注意力机制,单一头注意力机制计算如下, :
H
l
−
1
=
[
h
1
l
−
1
,
h
2
l
−
2
,
.
.
.
,
h
n
l
−
1
]
Q
=
H
l
−
1
W
Q
,
K
=
H
l
−
1
W
K
,
V
=
H
l
−
1
W
V
A
=
Q
T
K
/
d
k
H
l
=
A
V
H^{l-1} = [h_1^{l-1}, h_2^{l-2}, ..., h_n^{l-1}]\newline Q=H^{l-1}W_Q, K=H^{l-1}W_K, V=H^{l-1}W_V \newline A=Q^TK/\sqrt{d_k} \newline H^l=AV
Hl−1=[h1l−1,h2l−2,...,hnl−1]Q=Hl−1WQ,K=Hl−1WK,V=Hl−1WVA=QTK/dkHl=AV
Graphormer
标准 Transformer 依赖隐向量的相似度来决定注意力强度,但在图数据结构中,仅利用节点的特征向量是不够的,还需高效的利用图结构信息。
Centrality Encoding
Centrality Encoding 用于度量图节点的重要程度,图中不同节点应该具有不同的重要程度,将节点的重要度信息注入到 Transformer 中,有助于模型对图数据的理解。在具体实现上,主要根据节点的 “度” 信息来决定节点的重要程度,在有向图中,每个节点有“入度” 与 “出度”两个值,Graphormer 会赋予每个节点两个度向量,并将度向量与特征向量加在一起作为输入:
h
i
0
=
x
i
+
z
d
e
g
r
e
e
(
v
i
)
−
+
z
d
e
g
r
e
e
(
v
i
)
+
h_i^0 = x_i + z^-_{degree_{(v_i)}} + z^+_{degree_{(v_i)}}
hi0=xi+zdegree(vi)−+zdegree(vi)+
z
+
z^+
z+ 与
z
−
z^-
z− 是可学习的 Embedding 矩阵, 对于无向图,
z
+
z^+
z+ 与
z
−
z^-
z− 可以合并为一个可学习矩阵 。
Spatial Encoding
标准 Transformer 是为文本数据建模而设计的,在处理文本序列时,通过绝对位置编码或者相对位置编码,注入位置信息,而图数据结构并非典型的序列数据,那么应采用何种位置编码信息来表示节点的位置呢?论文采取了相对位置编码的思想,将节点
v
i
v_i
vi 与
v
j
v_j
vj 之间的最短路径距离作为位置信息,如果两节点是可连通的,则取值为最短路径长度,否则取-1或者其它特殊值。针对每一位置值,Graphormer 初始化一个可学习标量与之对应,并将位置信息加入到注意力矩阵
A
A
A中:
A
i
j
=
Q
T
K
d
+
b
f
(
v
i
,
v
j
)
A_{ij} = \frac{Q^TK}{\sqrt d} + b_{f(v_i, v_j)}
Aij=dQTK+bf(vi,vj)
偏置项
b
f
(
v
i
,
v
j
)
b_{f(v_i, v_j)}
bf(vi,vj) 表示的就是两节点的位置信息。
Edge Encoding
如果边对象集合包含有意义的特征向量信息,将这部分信息注入到模型,将有利于表征学习,论文指出传统的 Edge Encoding 有两种方式,一种是将相关联的边特征向量加总到节点特征向量上,另一种将边向量加入到 AGREEGATE-COMBINE的AGREEGATE阶段。
Graphormer 提出了一种全新的 Edge Encoding,对于任意可连通的节点对 ( v i , v j ) (v_i, v_j) (vi,vj) 与最短路径 s p i j = { e 1 , e 2 , . . . , e n } sp_{ij} = \{e_1, e_2, ..., e_n\} spij={e1,e2,...,en}, 两节点的边特征信息融合为 c i j = 1 N ∑ i = 1 N x e n ( w n E ) T c_{ij} = \frac{1}{N}\sum_{i=1}^Nx_{e^n}(w_n^E)^T cij=N1i=1∑Nxen(wnE)T, 其中 x e n x_{e^n} xen 是最短路径中某一条边对应的特征向量, w E w^E wE 是一个可学习的Embedding 矩阵。最终将 c i j c_{ij} cij 加总到注意力矩阵 A i j A_{ij} Aij。
A
i
j
=
Q
T
K
d
+
b
f
(
v
i
,
v
j
)
+
c
i
j
A_{ij} = \frac{Q^TK}{\sqrt d} + b_{f(v_i, v_j)} + c_{ij}
Aij=dQTK+bf(vi,vj)+cij
Implementation Details of Graphormer
将 Layer Normalization 应用在MHA 与 FFN 之前。
H
l
′
=
M
H
A
(
L
N
(
H
l
−
1
)
)
+
H
l
−
1
H
l
=
F
F
N
(
L
N
(
H
l
′
)
+
H
l
′
H^{l'} = MHA(LN(H^{l-1})) + H^{l-1} \newline H^{l} = FFN(LN(H^{l'}) + H^{l'}
Hl′=MHA(LN(Hl−1))+Hl−1Hl=FFN(LN(Hl′)+Hl′
添加 Special Node 融合图 G G G 的信息,与 READOUT函数功能类似:
- 在 Graphormer 中, 用 [VNode] 表示 Special Node。
- [VNode] 与图 G G G 的任意一节点直接连接。
- 在 AGGREGATE-COMBINE 阶段, [VNode] 的表征学习与普通阶段一致,在READOUT阶段,直接采取最后一层的[VNode] 的表征学习作为 h G h_G hG。
- 由于 [VNode] 与其它节点的连接是虚拟的,并且最短距离为1,为了区别实际连接距离为1的节点对关系,在 Spatial Encoding 中,对 b f ( v i , [ V N o d e ] ) b_{f(v_i, [VNode])} bf(vi,[VNode]) 设置为一个特殊独立的可学习标量值。
实验
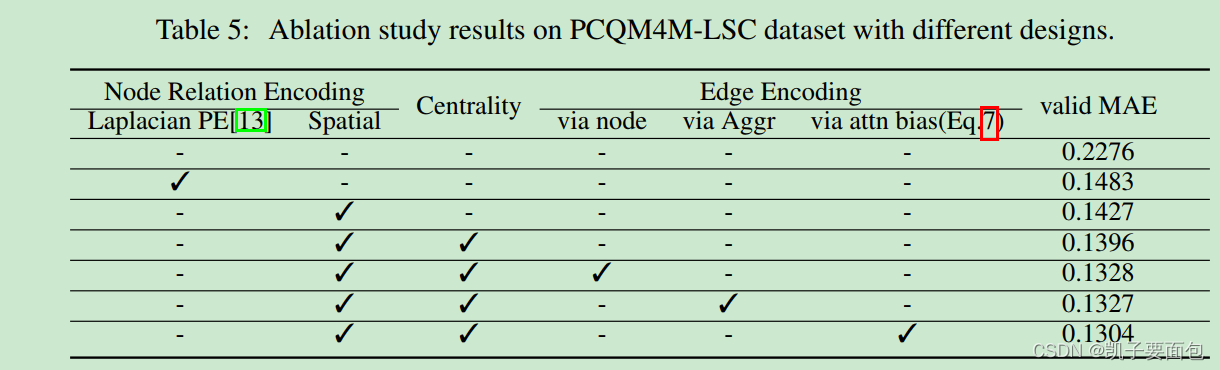
对比第二行与第三行,说明 Spatial Encoding 比 Laplacian PE 更有效,并且对比基线效果,Spatial Encoding 的作用十分明显。 对比第三行与第四行,说明 Centrality Encoding 有助于效果提升。对比最后三行,Edge Encoding 中的 via node 与 via Aggr 分别对应传统的两种融合边特征信息的两种方式, via attn bias 是论文提出的方式,最终结果表明 via attn bias 略优于前两种方式。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









