






1.写程序需要先梳理思路,甚至可以画出逻辑流程图,一步一步划分为细的步骤:
例如本次的数据提取:涉及到两个文件一个txt的文件夹和一个CSV文件,那么就可以梳理思路就是,读取txt文件,读取csv文件,分类数据,新建类别文件夹保存文件.
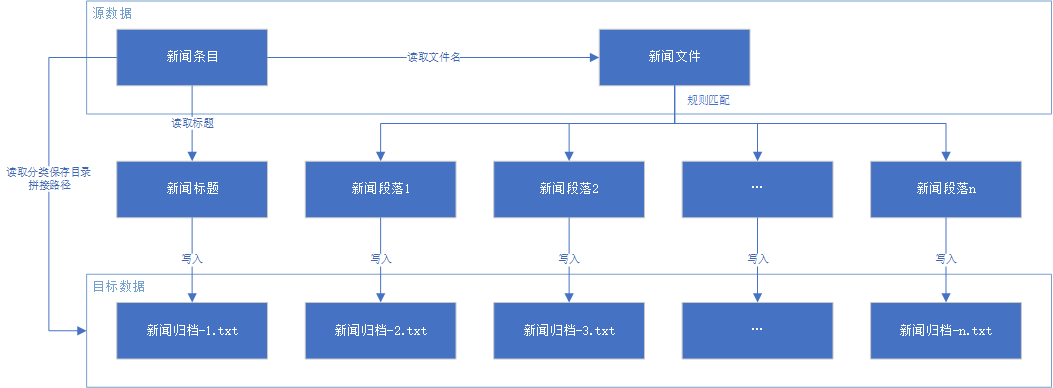
image.png
注意:确定要实现哪些小的功能,一个函数def就实现一个小功能
2.注意标明编码
#!/usr/bin/python
申明l这是个python脚本,要用python解释器来运行,有时候解释器路径不对,
换成通用的:#!/usr/bin/env python 即可
---------------------------
# -*- coding: utf-8 -*-
用来指定文件编码为utf-8的
3.读文件 with open('路径', 'r') as f 和f = open()的区别:
参考:https://blog.csdn.net/a1496785/article/details/83011974
with open("test.txt","r") as file:
for line in file.readlines():
print line
用with语句的好处,就是到达语句末尾时,会自动关闭文件,即便出现异常。
file = open("test.txt","r")
for line in file.readlines():
print line
file.close()
这样直接打开文件,如果出现异常,如读取过程中文件不存在或异常,则直接出现错误,close方法无法执行,文件无法关闭
4.读取文件常用的三种方法 :read()和readline() ,readlines()的区别?
参考:https://blog.csdn.net/weixin_42168614/article/details/88292146
- read([size])方法:从文件当前位置起读取size个字节,若无参数size,则表示读取至文件结束为止,它范围为字符串对象.
- readline()方法:从字面意思可以看出,该方法每次读出一行内容,所以,读取时占用内存小,比较适合大文件,该方法返回一个字符串对象。
- readlines()方法:读取整个文件所有行,每行保存为一个字符串,可以用空列表保存在一个列表(list)变量中,该列表可以由Python的for in 结果进行处理,每行作为一个元素,但读取大文件会比较占内存。
f = open('1.txt', 'r') #以读方式打开文件
result = list()
for line in f.readlines(): #依次读取每行
line = line.strip() #去掉每行头尾空白
if not len(line) or len(line) < 4: #判断是否是空行或注释行
continue #是的话,跳过不处理
result.append(line) #保存
# result.sort() #排序结果
print(result)
f.close()
5.路径问题,
得注意的是:在Windows系统中,在文件路径中使用反斜杠(\)而不是斜杠(/)。
路径一般写成读写放在开头为全局变量,可以作为参数向函数传参
- python中 STR.strip() 的用法:
参考:https://www.cnblogs.com/kaishirenshi/p/8610892.html
- str.strip()就是把字符串(str)的头和尾的空格,以及位于头尾的\n \t之类给删掉。
- 字符串str还有另外两种类似的方法lstrip()和rstrip()。第一个是只删头,第二个是只删尾巴。
7.split():拆分字符串.
参考:https://blog.csdn.net/qq_24407657/article/details/80265217
通过指定分隔符对字符串进行切片,并返回分割后的字符串作为元素的列表(list)
语法:str.split(str="",num=string.count(str))[n]
分割两次,取第一个分片(序号为0)
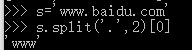
image.png
8.读取csv文件:
with open( 'd:file.csv', 'r', encoding= 'utf-8') as csvFile: #以只读方式打开"file.csv"文件并返回文件对象"csvFile"
reader =csv.reader(csvFile) #只上传第一个参数"csvFile",剩下两个采用缺省设定
for row in reader:
print (str(row)) #输出"reader"中的每行数据
9,















 4377
4377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









