






2D Human Pose Estimaiton
随着DeepPose的提出,人体姿态估计的方法开始由传统方法转化为深度学习方法,在下面总结的几篇论文,这些论文代表了从 Google 的 DeepPose 开始的 Human Pose Estimation 的演变(这不是一个详尽的列表,而是最好的进展/最 每个会议重要的)。
文章目录
- 2D Human Pose Estimaiton
- DeepPose: Human Pose Estimation via Deep Neural Networks (CVPR’14) [arXiv]
- Efficient Object Localization Using Convolutional Networks (CVPR’15)
- Convolutional Pose Machines (CVPR’16)
- Human Pose Estimation with Iterative Error Feedback (CVPR’16)
- Stacked Hourglass Networks for Human Pose Estimation (ECCV’16)
- Simple Baselines for Human Pose Estimation and Tracking (ECCV’18)
- Deep High-Resolution Representation Learning for Human Pose Estimation [HRNet] (CVPR’19)
-
DeepPose
-
Efficient Object Localization Using Convolutional Networks
-
Convolutional Pose Machines
-
Human Pose Estimation with Iterative Error Feedback
-
Stacked Hourglass Networks for Human Pose Estimation
-
Simple Baselines for Human Pose Estimation and Tracking
-
Deep High-Resolution Representation Learning for Human Pose Estimation
转自: https://nanonets.com/blog/human-pose-estimation-2d-guide/?utm_source=github&utm_medium=social&utm_campaign=pose&utm_content=cbsudux#convnet
DeepPose: Human Pose Estimation via Deep Neural Networks (CVPR’14) [arXiv]
模型由一个AlexNet backend(7层)和一个最终输出
2
k
2k
2k个关节坐标的层组成:
(
x
i
,
y
i
)
∗
2
(x_i,y_i)*2
(xi,yi)∗2 for i in {1,2,…k},k是关节数量。
损失函数采用
L
2
L2
L2 loss
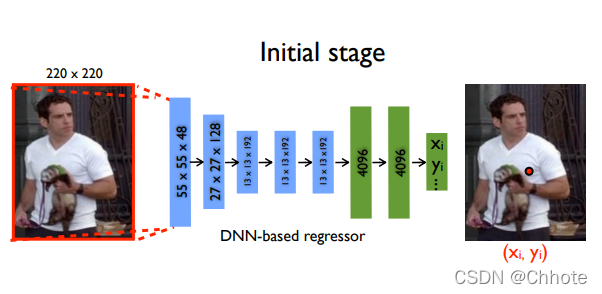
该模型实现的一个有趣想法是使用级联回归器对预测进行细化。 初始粗略姿态被细化并获得更好的估计。 图像在预测关节周围被裁剪并馈送到下一阶段,这样后续的位姿回归器会看到更高分辨率的图像,从而学习更精细尺度的特征,最终导致更高的精度。
数据集:
LSP:Leeds sports dataset (http://sam.johnson.io/research/lsp.html)
FLIC:Frames Labeled In Cinema(https://bensapp.github.io/flic-dataset.html)

Efficient Object Localization Using Convolutional Networks (CVPR’15)
这个方法生成关节点的热图,此方法十分成功,后续的很多研究延续此方法。
模型:
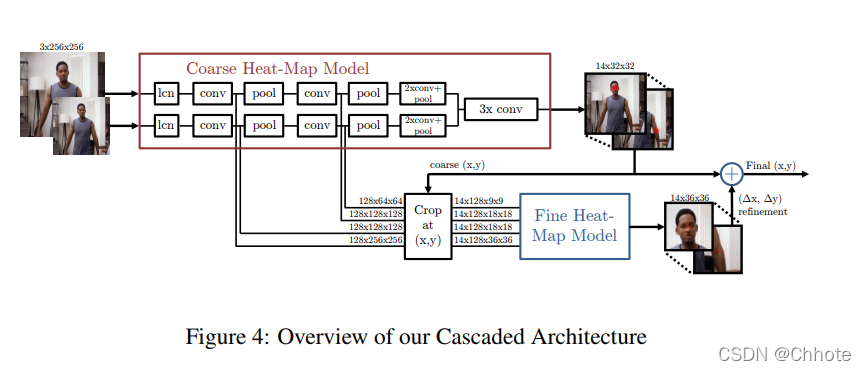
多分辨率 CNN 架构(粗热图模型)用于实现滑动窗口检测器以产生粗热图输出。
本文的主要动机是恢复由于初始模型中的池化而损失的空间精度。 通过使用额外的“姿势细化”ConvNet 来改进粗略热图的定位结果。 然而,与标准级联模型不同,它们重用现有的卷积特征。 这不仅减少了级联中可训练参数的数量,而且还充当了粗略热图模型的正则化器,因为粗略和精细模型是联合训练的。
本质上,该模型包括用于粗略定位的基于热图的部件模型和用于在每个关节的指定 (x,y) 位置对卷积特征进行采样和裁剪的模块,以及用于精细定位的附加卷积模型。
这种方法的一个关键特征是 ConvNet 和图形模型的联合使用。 图形模型学习关节之间的典型空间关系。
损失函数: MSE
然而,本方法缺乏结构建模。 由于身体部位比例、左右对称、相互渗透约束、关节限制(例如肘部不向后弯曲)和物理连接(例如手腕与肘部刚性相关)等原因,二维人体姿势的空间是高度结构化的。 对该结构进行建模应该可以更容易地查明可见的关键点,并可以估计被遮挡的关键点。 接下来的几篇论文以他们自己新颖的方式解决了这个问题。
Convolutional Pose Machines (CVPR’16)
这是一篇有趣的论文,它使用了一种叫做 Pose Machine的东西。 Pose Machine由图像特征计算模块和预测模块组成。 Conventional Pose Machine(CPM)是完全可微的,它的多阶段架构可以端到端训练。 它为学习丰富的隐式空间模型提供了一个顺序预测框架,并且非常适用于人体姿势。
模型:
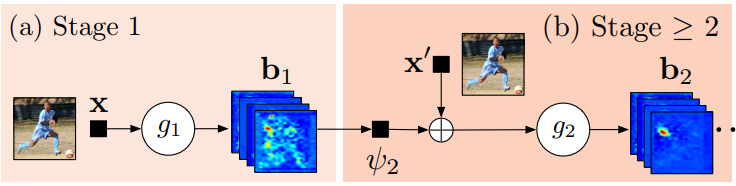
Stage 1 是图像特征计算模块
Stage 2 是预测模块
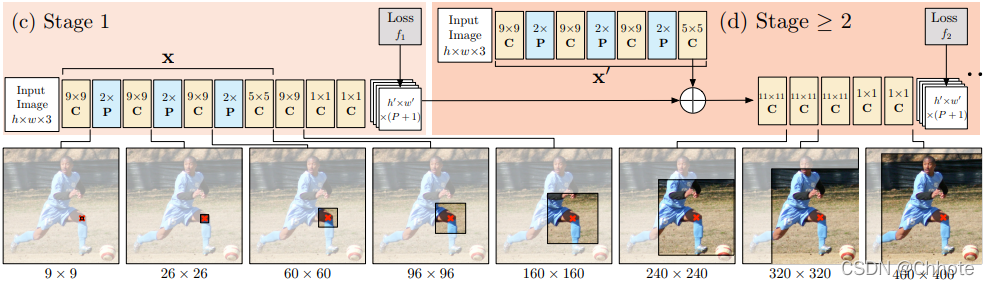
一个 CPM 可以包含 > 2 个阶段,阶段的数量是一个超参数。 (通常 = 3)。 阶段 1 是固定的,阶段 > 2 只是阶段 2 的重复。阶段 2 将热图和图像证据作为输入。 输入热图为下一阶段添加空间上下文。 (已在论文中详细讨论)。
在高层次上,CPM 通过后续阶段细化热图。
论文在每个阶段之后使用中间监督来避免梯度消失的问题,这是深度多阶段网络的常见问题
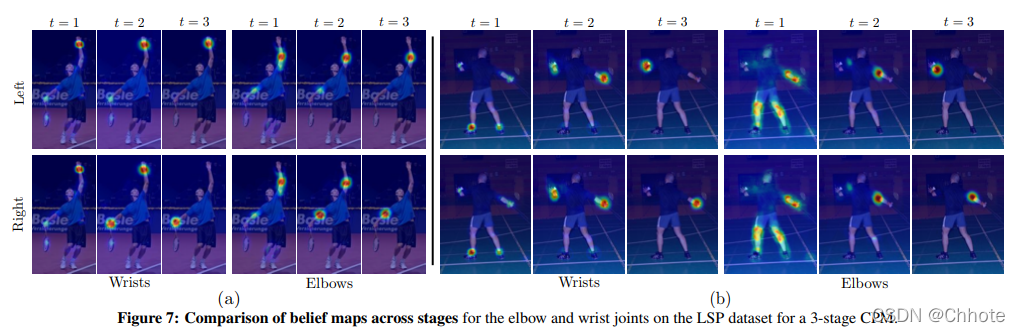
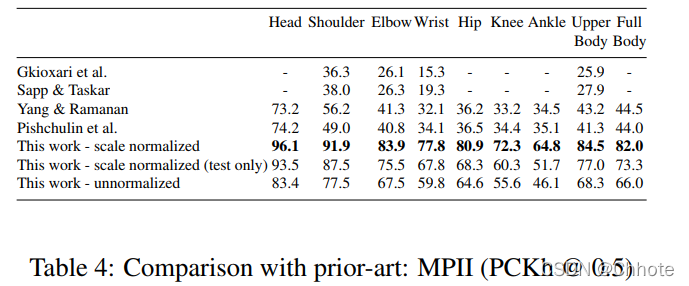
- MPII:PCKh-0.5 得分达到了 87.95%,比最接近的竞争对手高出 6.11%,值得注意的是,在脚踝(最具挑战性的部分)上, PCKh@0.5 得分为 78.28%,这是 比最接近的竞争对手高出 10.76%。
- LSP:模型以 84.32% 达到最先进水平(添加 MPII 训练数据时为 90.5%)。
在MPII, FLIC 和LSP三个数据集上都达到了最先进水平
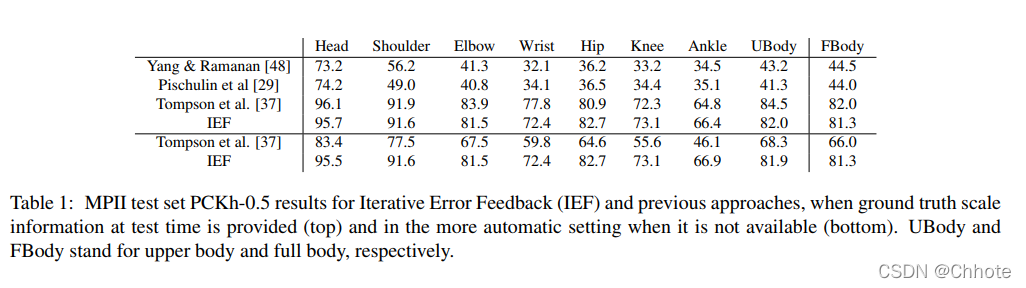
Human Pose Estimation with Iterative Error Feedback (CVPR’16)
这篇文章的工作很简单:预测当前估计中的问题并迭代地纠正它们。
模型不是一次性直接预测输出,而是使用自校正模型,通过反馈错误预测逐步改变初始解决方案,这个过程称为迭代错误反馈 (IEF)。
Model Pipeline: 模型的输入由图像
I
I
I和上一次的输出
y
t
−
1
y_{t-1}
yt−1组成。
Input:
x
t
=
I
⊕
g
(
y
t
−
1
)
x_t=I \oplus g(y_{t-1})
xt=I⊕g(yt−1)
Output:
-
f
(
x
t
)
f(x_t)
f(xt)输出矫正
ε
t
\varepsilon_t
εt,并且这个矫正会加到
y
t
y_t
yt来生成
y
t
+
1
y_{t+1}
yt+1 :
y t + 1 = ε t + y t y_{t+1}=\varepsilon_t+y_t yt+1=εt+yt
ε t = f ( x t ) \varepsilon_t=f(x_t) εt=f(xt) -
g
(
y
t
+
1
)
g(y_{t+1})
g(yt+1)把
y
t
+
1
y_{t+1}
yt+1中的每一个关键点转化成heatmap,以便它们可以堆叠到图像
I
I
I中,从而形成下次迭代的输入。这个过程会持续
T
T
T次直到我们得到一个细化后的
y
t
+
1
y_{t+1}
yt+1,并且输出的关键点坐标已经和真实的坐标差别小于
ε
t
\varepsilon_t
εt。
第二次的输入: x t + 1 = I ⊕ g ( y t − 1 ) x_{t+1}=I\oplus g(y_{t-1}) xt+1=I⊕g(yt−1)
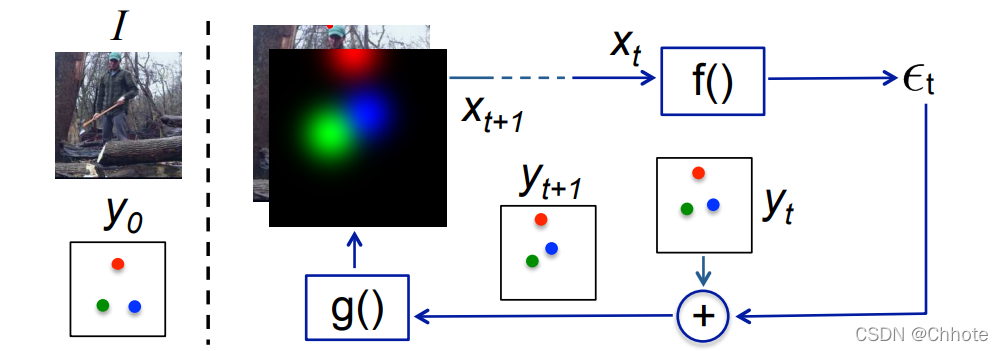
上面中 g ( ) 和 f ( ) g()和f() g()和f()都是可学习的,并且 f ( ) f() f()是CNN
参数 Θ g \Theta_g Θg和 Θ f \Theta_f Θf都是优化以下等式学习得来的:
m i n Θ f , Θ g ∑ t = 1 T h ( ε t , e ( y , y t ) ) min_{\Theta_f,\Theta_g}\begin{matrix} \sum_{t=1}^T h(\varepsilon_t,e(y,y_t)) \end{matrix} minΘf,Θg∑t=1Th(εt,e(y,yt))
下图中展示的就是随着迭代一步步修正的过程

Stacked Hourglass Networks for Human Pose Estimation (ECCV’16)
一篇优雅的论文,介绍了一个很好的新颖性并且效果很好的方法。
这个网络被称为堆叠沙漏网络是因为它由看起来像沙漏的池化层和上采样层的步骤组成。
沙漏设计的动机是需要在每个尺度上捕获信息。 虽然局部证据对于识别面部手等特征至关重要,但最终的姿势估计需要全局信息。 人的方向、四肢的排列以及相邻关节的关系是图像中不同尺度下最容易识别的众多线索之一。(较小的分辨率捕获更高阶的特征和全局信息。)
网络在中间监督的情况下重复进行从下而上、从上而下的处理。
- Bottom-up:从高分辨率到低分辨率
- Top-down:从低分辨率到高分辨率
网络使用跳跃连接来保存每个分辨率的空间信息,并将其传递给上采样,进一步向下采样。
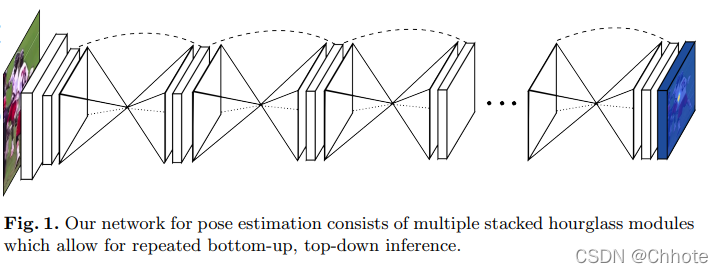
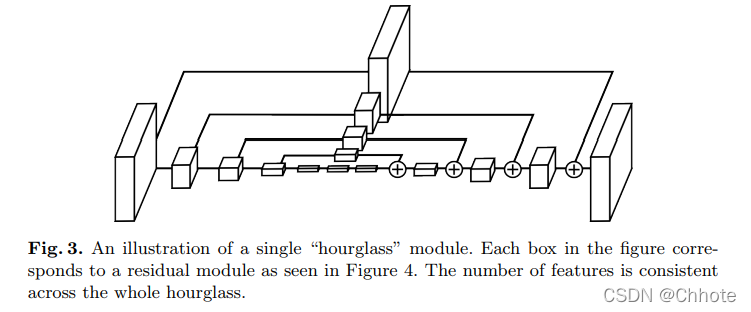
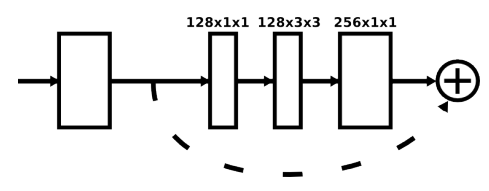
以上的每一个框都是一个残差模块。
中间监督: 中间监督被用于每个沙漏阶段的预测。例如监督堆栈中每个沙漏的预测,而不仅仅是最终的沙漏预测。

沙漏网络获取图像每个维度的消息,这样,全局和局部信息被完全捕获并被网络用来学习预测。
Simple Baselines for Human Pose Estimation and Tracking (ECCV’18)
这篇论文提出的方法是人体姿态估计的的基本方法,这篇文章就是想说明人体姿态估计的方法的最简单的方法,在COCO数据集上达到SOTA,mAP为73.7%。
这个网络的结构十分简单,由一个ResNet+一些反卷积层组成。
沙漏网络中使用上采样来增强特征图分辨率,并且在其他块中放卷积参数,HRNet中用了一种十分简单的方式融合了这些在几个反卷积层中。
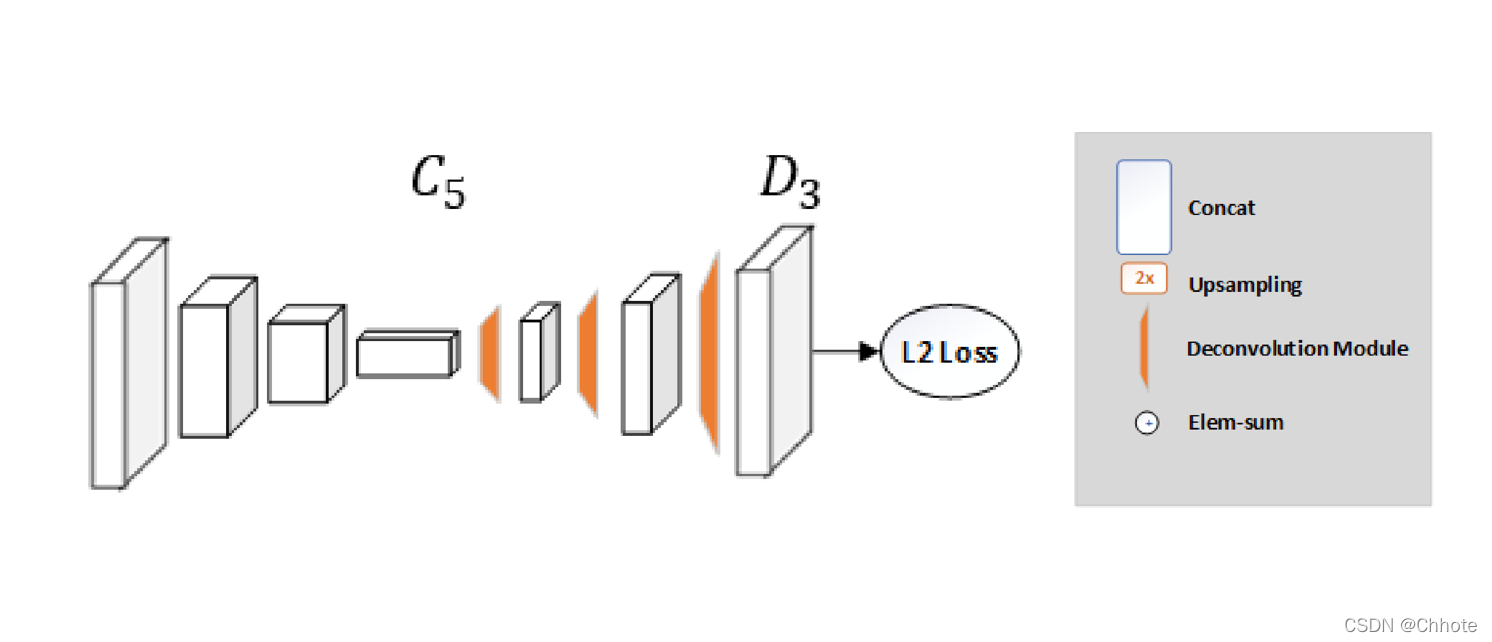
损失函数: MSE:均方误差 (MSE) 用作预测热图和目标热图之间的损失。 关节
k
k
k的目标热图
H
k
H_k
Hk是通过应用以第
k
k
k个关节的地面实况位置为中心的 2D 高斯生成的,std dev = 1 像素。
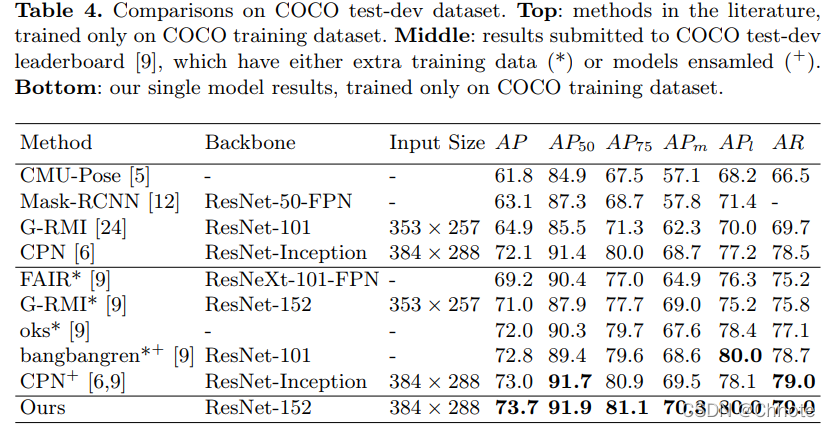
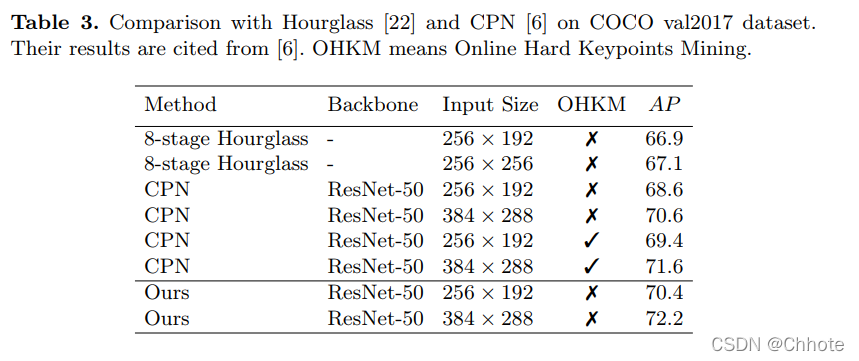
Deep High-Resolution Representation Learning for Human Pose Estimation [HRNet] (CVPR’19)
在关键点检测中,HRNet模型是比现存的所有模型都更加表现优秀的。在COCO上的多人姿态估计是最好的
目前大多数的论文都遵行high——low——high-resolution representation,但是HRNet在整个的处理过程中都使用high-resolution representation。
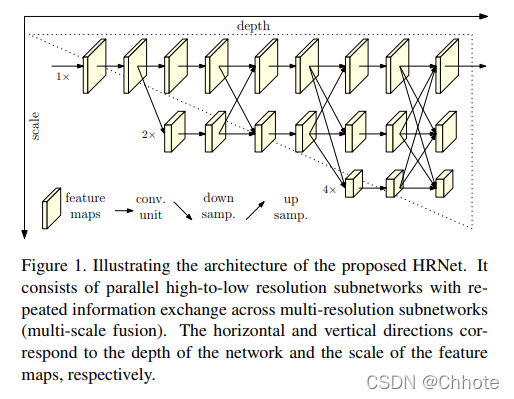
这个结构的第一阶段从一个高分辨率的子网络开始,然后逐渐一个接一个把high-to-low 分辨率的子网加进去组成更多的阶段,然后并行连接多分辨率的子网。
重复的多尺度融合是通过在整个过程中在并行多分辨率子网络中反复交换信息而进行的。
另外一个优点是这个结构没有用中间热图监督,和堆叠沙漏网络不同。
损失函数: MSE
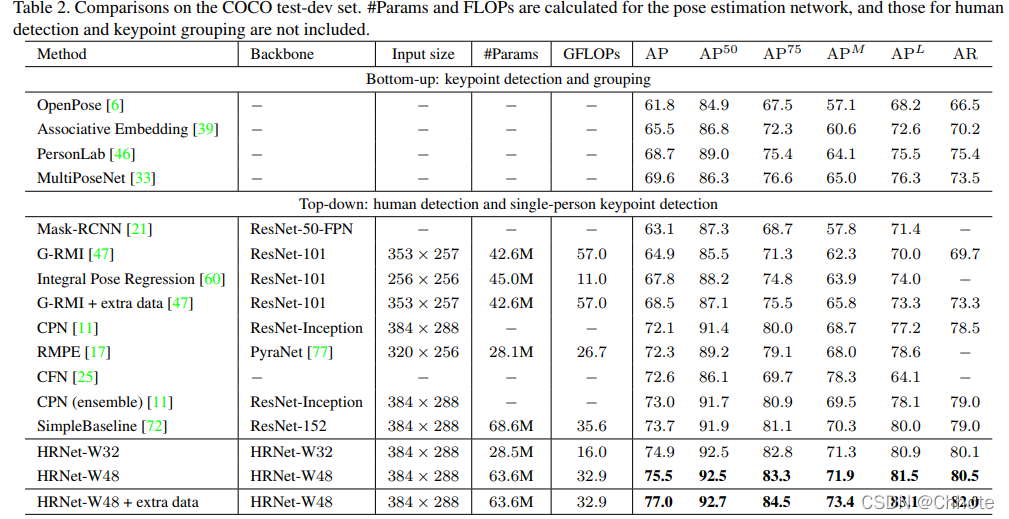
姿态估计一些常用的评价指标:
- Percentage of Correct Parts - PCP
- Percentage of Correct Key-points - PCK
- Percentage of Detected Joints - PDJ
- Object Keypoint Similarity (OKS) based mAP

















 8723
8723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









