









数据库系列
前言
MongoDB是当前最流行的数据库之一,属于文档型数据库。
一、为什么选择mongodb数据库?
MongoDB是当前最流行的数据库之一,属于文档型数据库,是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。它同时具备mysql和redis的特点(即持久化安全落盘写和异步不等落盘的快速写),还有很强大的内置分区、多副本和数据变更通知的功能。最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
主要特点:
1、MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
2、你可以在MongoDB记录中设置任何属性的索引 (如:FirstName=“Sameer”,Address=“8 Gandhi Road”)来实现更快的排序。
3、你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
4、Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
5、MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
6、Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
7、Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
8、Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
9、GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
10、MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
11、MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
12、MongoDB安装简单。
二、mongo基本功能
1.mongo安装与重要功能
你可以在mongodb官网下载该安装包,地址为:https://www.mongodb.com/download-center#community。
安装mongo 服务,客户端,备份(backup),恢复(restore)
准备好安装离线包,通过rpm -ivh安装
rpm -ivh mongo/cyrus-sasl-lib-2.1.26-23.el7.x86_64.rpm
rpm -ivh mongo/cyrus-sasl-2.1.26-23.el7.x86_64.rpm
rpm -ivh mongo/cyrus-sasl-gssapi-2.1.26-23.el7.x86_64.rpm
rpm -ivh mongo/cyrus-sasl-plain-2.1.26-23.el7.x86_64.rpm
rpm -ivh mongo/mongodb-database-tools-100.5.1.x86_64.rpm
rpm -ivh mongo/mongodb-org-database-tools-extra-4.4.3-1.el7.x86_64.rpm
rpm -ivh mongo/mongodb-org-server-4.4.3-1.el7.x86_64.rpm
rpm -ivh mongo/mongodb-org-shell-4.4.3-1.el7.x86_64.rpm
systemctl enable mongod; #建立systemctl服务管理
/bin/cp -f mongo/mongod.conf /etc
chmod 0644 /etc/mongod.conf
systemctl start mongod; #启动mongodb
通过rpm -e卸载
rpm -e mongodb-org-server mongodb-org-shell
rpm -e mongodb-database-tools mongodb-org-database-tools-extra cyrus-sasl cyrus-sasl-gssapi cyrus-sasl-plain cyrus-sasl-lib
/bin/rm -rf /var/lib/mongo /etc/mongod.conf.rpmsave /var/log/mongodb
#数据默认存储目录为 /var/lib/mongo
#日志默认存储目录为 /var/log/mongodb/mongod.log
#数据存储大小默认 50G
mongo 单机开启副本集事务,初始化集群
mongo --host 127.0.0.1 --port 27017
use admin
rs.initiate({_id:"rs0",members:[{_id:0,host:"127.0.0.1:27017"},{_id:1,host:"127.0.0.1:27018"}]});
等价于
mongo --eval 'rs.initiate({_id:"rs0",members:[{_id:0,host:"127.0.0.1:27017"},{_id:1,host:"127.0.0.1:27018"}]})';
查看集群状态
rs.status()
查看副本集的配置
rs.conf()
关闭mongod
mongo --shutdown
安装成功后,可以通过mongo client 访问mongo server,端口默认27017,默认是没有用户的。
数据的备份与恢复
备份数据:
无用户数据备份
mongodump -d runoob -o /opt/app_backup/
有用户数据备份
mongodump --authenticationDatabase admin -u admin -p admin -d runoob -o /opt/app_backup/
恢复数据:
无用户数据恢复
mongorestore -d runoob /opt/app_backup/runoob
有用户数据恢复
mongorestore -u admin -p admin --authenticationDatabase admin --drop -d runoob --dir /opt/app_backup/runoob
MongoDB 复制(副本集)
MongoDB复制是将数据同步在多个服务器的过程。复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。复制还允许您从硬件故障和服务中断中恢复数据。
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
创建conf,将mongodb.conf所有路径和port改成实际路径就行
mongo
rs.initiate({
_id : "rs0",
members : [
{_id : 0, host : "192.168.31.223:27000"},
{_id : 1, host : "192.168.31.164:27001"}
]
});

参考:https://blog.csdn.net/weixin_40863968/article/details/126631015
MongoDB的副本集与我们常见的主从有所不同,主从在主机宕机后所有服务将停止,而副本集在主机宕机后,副本会接管主节点成为主节点,不会出现宕机的情况。
mongostat 命令
mongostat是mongodb自带的状态检测工具,在命令行下使用。它会间隔固定时间获取mongodb的当前运行状态,并输出。如果你发现数据库突然变慢或者有其他问题的话,你第一手的操作就考虑采用mongostat来查看mongo的状态。
mongostat
mongostat -u admin -p 123456 --authenticationDatabase admin
参数解析:
inserts/s 每秒插入次数
query/s 每秒查询次数
update/s 每秒更新次数
delete/s 每秒删除次数
getmore/s 每秒执行getmore次数,查看更多的意思,我们每次查询数据时,如果一次数据量比较大,超过了mongodb一次能查询的最大数据量,那么mongodb就回把这次要查询的数据分成几次查询,分别返回
command/s 每秒的命令数,比以上插入、查找、更新、删除的综合还多,还统计了别的命令
dirty WiredTiger存储引擎中dirty 数据占缓存百分比
used WiredTiger存储引擎中引擎使用缓存占百分比
flushes/s 每秒执行fsync将数据写入硬盘的次数, WiredTiger存储引擎中,flushes是指WiredTiger循环创建检查点的时间间隔。每隔一段时间,mongodb就将内存上的数据写入硬盘,如果这个数值比较大的话,会影响性能
vsize 虚拟内存使用量,单位MB
res 物理内存使用量,单位MB
faults /s 每秒访问失败数(只有Linux有),数据被交换出物理内存,放到swap。不要超过100,否则就是机器内存太小,造成频繁swap写入。此时要升级内存或者扩展
res 使用真实内存大小
qr 客户端等待读的长度,队列中的长度
qw 客户端等待写的队列长度
ar 活跃客户执行写操作的数量。
aw 活跃客户等待写的数量
netin mongodb进入的流量包含mongostat本身(单位:bytes)
netout mongodb出去的流量包含mongostat本身
conn 当前连接数
time 时间戳

mongotop命令
mongotop也是mongodb下的一个内置工具,mongotop提供了一个方法,用来跟踪一个MongoDB的实例,查看哪些大量的时间花费在读取和写入数据。 mongotop提供每个集合的水平的统计数据。默认情况下,mongotop返回值的每一秒。
mongotop
mongotop -u admin -p 123456 --authenticationDatabase admin

mongo分片
在Mongodb里面存在另一种集群,就是分片技术,可以满足MongoDB数据量大量增长的需求。
当MongoDB存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
分片重要主要组件:
Shard:用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组个一个replica set承担,防止主机单点故障
Config Server:mongod实例,存储了整个 ClusterMetadata,其中包括 chunk信息。
Query Routers:前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
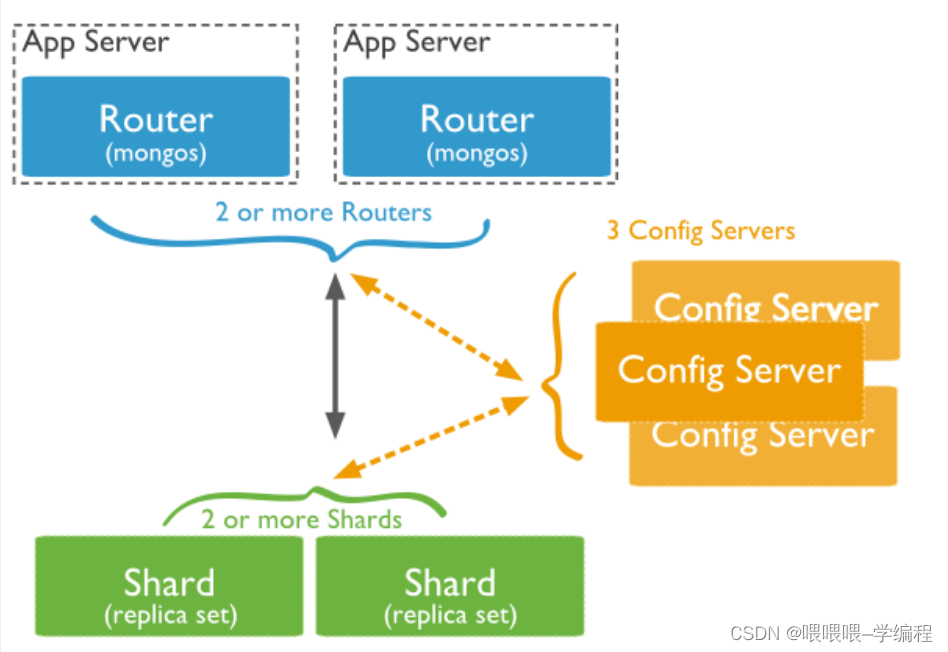
为什么使用分片
a)复制所有的写入操作到主节点
b)延迟的敏感数据会在主节点查询
c)单个副本集限制在12个节点
d)当请求量巨大时会出现内存不足。
e)本地磁盘不足
f)垂直扩展价格昂贵
Shard Server 1:27020
Shard Server 2:27021
Config Server :27100
Route Process:40000
启动Shard Server
mkdir -p /www/mongoDB/shard/s0
mkdir -p /www/mongoDB/shard/s1
mkdir -p /www/mongoDB/shard/log
mongod --port 27020 --dbpath=/www/mongoDB/shard/s0 --logpath=/www/mongoDB/shard/log/s0.log --logappend --fork
mongod --port 27021 -dbpath=/www/mongoDB/shard/s1 --logpath=/www/mongoDB/shard/log/s1.log --logappend --fork
启动Config Server
mkdir -p /www/mongoDB/shard/config
mongod --port 27100 --dbpath=/www/mongoDB/shard/config --logpath=/www/mongoDB/shard/log/config.log --logappend --fork
启动Route Process
mongos --port 40000 --configdb localhost:27100 --fork --logpath=/www/mongoDB/shard/log/route.log --chunkSize 500
配置Sharding即添加Shard节点
mongo admin --port 40000
db.runCommand({ addshard:"localhost:27020" })
db.runCommand({ addshard:"localhost:27021" })
db.runCommand({ enablesharding:"test" }) #设置分片存储的数据库
db.runCommand({ shardcollection: 'test.user', key: {name: 1}})
2.mongo的CRUD基本用法
创建数据库,默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中
use databse
查看数据库
show dbs
插入数据库
db.databse.insert({"name":"菜鸟教程"})
删除数据库
use database
db.dropDatabase()
创建runoob集合类似于表
db.createCollection("runoob")
show tables==show collections
创建固定集合mycol,整个集合空间大小 6142800 B, 文档最大个数为10000 个。
db.createCollection("mycol", { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
删除集合
use
db.runoob.drop()
插入文档
db.runoob.insert({title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '菜鸟教程',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100,
date: 1667232000
})
查找表中所有文档
db.runoob.find()
查找数组中元素匹配
查下数组中每个doc中id为123且name为234的情况,其中id与name必须是同一个数组元素
db.runoob.find({"tags":{$elemMatch: {"id": "123", "name": "234"}}})
查下数组中doc中id为123且name为234的情况,其中id与name不一定是同一个数组元素
db.runoob.find({"tags.id":"123","tags.name":"234"})
更新文档
db.runoob.insert({
title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '菜鸟教程',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})
删除文档
db.runoob.remove({'title':'MongoDB 教程'})
或者删除文档
db.runoob.deleteOne({"_id":"123456"})
db.runoob.deleteMany({"dt":{$lt:1669913240}})
db.runoob.deleteMany({})
db.runoob.deleteMany({$or: [{"by":"菜鸟教程"}, {title":"MongoDB 教程"}]})
查找文档(有些关键字可以查找其他文档比如gt,lt,or,and等)
#且查找
db.runoob.find({"by":"菜鸟教程", "title":"MongoDB 教程"}).pretty()
#或查找
db.runoob.find({$or: [{"by":"菜鸟教程"}, {title":"MongoDB 教程"}]}).pretty()
#多条件查找
db.runoob.find({"likes": {$gt:50}, $or: [{"by": "菜鸟教程"},{"title": "MongoDB 教程"}]}).pretty()
#多条件查找 发生时间100<ht<300内
db.runoob.find({"ht":{$gt:1668471207,$lt:1668478207}})
#查找,限制前100条的查找
db.runoob.find().limit(100)
#查找,限制为200条,其中前100条跳过
db.runoob.find().limit(200).skip(100)
#排序查找,其中1为升序排列,而 -1 是用于降序排列。
db.runoob.find().sort({"by":1})
方法distinct()对数据进行去重
查找时间>1671008764,不同的
db.runoob.distinct("name",{'dt':{$gt:1671008764}})
统计文档数
db.runoob.countDocuments({"dt":{$gt:1671033600,$lt:1671465600}})
db.runoob.count({"dt":{$gt:1671033600,$lt:1671465600}})
统计文档总数,无条件查询
db.runoob.estimatedDocumentCount()
统计大于ISO Date的文档
db.runoob.find({dt:{$gt:new Date('2022-11-21T10:29:14.089Z')}})
创建索引
db.runoob.createIndex({"title":1})
db.runoob.createIndex({"title":1,"description":-1})
聚合操作,聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。
计算每个作者所写的文章数,每次+1
db.runoob.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
聚合操作,查找时间在[1667232000,1667923200]范围内,统计url为"http://www.runoob.com",每小时的数据量
其中:subtract表示减法,mod表示取余,用时间减去整数的余数,即可得到整数
db.getCollection('runoob').aggregate(
{"$match":{"date": {'$gte':1667232000,'$lt':1667923200}},"url":"http://www.runoob.com"}},
{"$group": {
"_id": { "$subtract": ["$date",{ "$mod": ["$date",3600]}]},
"total": {'$sum': 1}
}}
)
参考:https://www.cnblogs.com/chuijingjing/p/16465404.html
聚合操作,查找时间在[1667232000,1667923200]范围内,_id以起始时间为基准开始统计,每3600为区间,统计url为"http://www.runoob.com",的数据量,输出_id、数量以及修正后的时间点,以datetime升降序进行排序输出
其中:subtract表示减法,mod表示取余,用时间减去整数的余数,即可得到整数
db.getCollection('runoob').aggregate(
{"$match":{"date": {'$gte':1667232000,'$lt':1667923200},"url":"http://www.runoob.com"}}
,{"$group": {
"_id": { "$subtract": [
{ "$subtract": [ "$date", 1667232000] },
{ "$mod": [{ "$subtract": [ "$date", 1667232000 ] },3600]}
]},
"total": {'$sum': 1}
}}
,{"$project": {
"_id": 1,
"count":1,
'datetime': {'$add': [1667232000, '$_id']}
}}
,{"$sort": {
'datetime': 1
}}
)
结果类似如下:
{ "_id" : 565200, "count" : 2, "datetime" : 1667797200 }
{ "_id" : 583200, "count" : 1, "datetime" : 1667815200 }
聚合操作,将runoob中tags中的数据拆分成多条数据
db.getCollection('runoob').aggregate([{$unwind:"$tags"}])
聚合统计,将runoob中files数据分成多条数据并查看文件类型为1或者2的数据总数
db.getCollection('runoob').aggregate(
[
{"$unwind":"$files"},
{"$match":{$or: [{"files.type": 1},{"files.type": 2}]}},
{"$group": {
"_id": "",
"total": {'$sum': 1}
}}
])
统计某段时间内总文档数
db.runoob.aggregate(
[
{ $match: {"dt":{$gt:1671008765,$lt:1671008926}}},
{ $group: { _id: null, count: { $sum: 1 } } }
]
)
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
$match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
$limit:用来限制MongoDB聚合管道返回的文档数。
$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
$group:将集合中的文档分组,可用于统计结果。
$sort:将输入文档排序后输出。
$geoNear:输出接近某一地理位置的有序文档。
展示title,author等字段
db.article.aggregate({ $project : {title : 1 ,author : 1 }});
db.article.aggregate({ $project : {_id : 0 ,title : 1 ,author : 1 }});
用于获取分数大于70小于或等于90记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理
db.articles.aggregate( [{ $match : { score : { $gt : 70, $lte : 90 } } },{ $group: { _id: null, count: { $sum: 1 } }}] );
前五个文档被"过滤"掉
db.article.aggregate({ $skip : 5 });
三、mongo高级功能
MongoDB GridFS
GridFS 用于存储和恢复那些超过16M(BSON文件限制)的文件(如:图片、音频、视频等)。
GridFS 也是文件存储的一种方式,但是它是存储在MonoDB的集合中。
GridFS 可以更好的存储大于16M的文件。
GridFS 会将大文件对象分割成多个小的chunk(文件片段),一般为256k/个,每个chunk将作为MongoDB的一个文档(document)被存储在chunks集合中。
GridFS 用两个集合来存储一个文件:fs.files与fs.chunks。
每个文件的实际内容被存在chunks(二进制数据)中,和文件有关的meta数据(filename,content_type,还有用户自定义的属性)将会被存在files集合中。
上传于下载mps文件
mongofiles -d gridfs put song.mp3 #上传mp3
mongofiles -d gridfs get song.mp3 #下载mp3
mongo
db.fs.files.find()
db.fs.chunks.find({files_id:ObjectId('534a811bf8b4aa4d33fdf94d')})

MongoDB 正则表达式
正则表达式是使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。
许多程序设计语言都支持利用正则表达式进行字符串操作。
MongoDB 使用 $regex 操作符来设置匹配字符串的正则表达式。
db.runoob.find({description:{$regex:"Nosql"}}) #正则表达式查找包含Nosql字符串的描述
db.runoob.find({post_text:{$regex:"Nosql",$options:"$i"}}) #且不区分大小写
引用式关系
引用式关系是设计数据库时经常用到的方法,这种方法把用户数据文档和用户地址数据文档分开,通过引用文档的 id 字段来建立关系。
#第一次查询用户地址的对象id(ObjectId),第二次通过查询的id获取用户的详细地址信息
var result = db.users.findOne({"name":"Tom Benzamin"},{"address_ids":1})
var addresses = db.address.find({"_id":{"$in":result["address_ids"]}})
MongoDB 覆盖索引查询
#第一次查询用户地址的对象id(ObjectId),第二次通过查询的id获取用户的详细地址信息
var result = db.users.findOne({"name":"Tom Benzamin"},{"address_ids":1})
var addresses = db.address.find({"_id":{"$in":result["address_ids"]}})
覆盖查询是以下的查询:a)所有的查询字段是索引的一部分 b)所有的查询返回字段在同一个索引中
#创建索引
db.users.createIndex({gender:1,user_name:1})
db.users.ensureIndex({gender:1,user_name:1}) #5.0版本后被移除
注意:当创建用户开启授权以后,就会出现创建索引阻塞的问题,解决办法如下:
openssl rand -base64 756 > /etc/mongod_keyfile;chmod 400 /etc/mongod_keyfile;chown mongod /etc/mongod_keyfile
//mongod.conf中security配置节添加keyFile选项
security:
keyFile: /etc/mongod_keyfile
db.users.find({gender:"M"},{user_name:1,_id:0})
对于上述查询,MongoDB的不会去数据库文件中查找。相反,它会从索引中提取数据,这是非常快速的数据查询。由于我们的索引中不包括 _id 字段,_id在查询中会默认返回,我们可以在MongoDB的查询结果集中排除它。
MongoDB 索引查询分析
MongoDB 查询分析可以确保我们所建立的索引是否有效,是查询语句性能分析的重要工具。
MongoDB 查询分析常用函数有:explain() 和 hint()。
mongodb提供db.collection.explain()、cursort.explain()及explain命令获取查询计划及查询计划统计信息。
利用explain命令,我们可以很好的观察系统如何使用索引来加快检索,同时可以做针对性的性能优化。
现版本explain有三种模式,分别是:queryPlanner、executionStats、allPlansExecution
//explain分析
db.users.find({"dt":{$gt:1671008765,$lt:1671008926},"number":200}).explain("executionStats")
db.users.find({"type":200}).explain("executionStats")
db.users.find({"type":100}).explain("executionStats")
db.users.explain().aggregate({ $project:{type : 1 }});
//强制索引
db.users.find({"dt":{$gt:1671008765},"name":{$regex:"沪"}}).hint({dt:-1,"name":1}).explain("executionStats")
主要参考3个返回项,nReturned、totalKeysExamined、totalDocsExamined,分别表明该条查询返回的条目、索引扫描条目、文档扫描条目。这些都是直观地影响到executionTimeMillis,咱们须要扫描的越少速度越快。
对于一个查询,咱们最理想的状态是:nReturned=totalKeysExamined=totalDocsExamined
explain中关注的是COLLSCAN、IXSCAN、keysExamined、docsExamined 等关键字,keysExamined 和 docsExamined 越大代表没有建索引或者索引的区分度不高。
1、COLLSCAN:代表该查询进行了全表扫描;
2、IXSCAN:代表进行了索引扫描;
3、keysExamined:代表索引扫描条目;
4、docsExamined:代表文档扫描条目。
5、nReturned:获胜计划(winning plan)完整的查询执行数据
6、executionTimeMillis:查询条件匹配到的文档数量
MongoDB官方提供的分析命令,详情请参见:
通过MongoDB自身提供的命令db.stats()和db.$collection_name.stats()分析。
db.stats()
db.collection.stats()
db.collection.storageSize()
db.collection.totalIndexSize()
db.collection.totalSize()
MongoDB 固定集合
MongoDB 固定集合(Capped Collections)是性能出色且有着固定大小的集合,对于大小固定,我们可以想象其就像一个环形队列,当集合空间用完后,再插入的元素就会覆盖最初始的头部的元素!
属性
属性1:对固定集合进行插入速度极快
属性2:按照插入顺序的查询输出速度极快
属性3:能够在插入最新数据时,淘汰最早的数据
用法
用法1:储存日志信息
用法2:缓存一些少量的文档
#我们通过createCollection来创建一个固定集合,且capped选项设置为true:
db.createCollection("cappedLogCollection",{capped:true,size:10000})
#还可以指定文档个数,加上max:1000属性:
db.createCollection("cappedLogCollection",{capped:true,size:10000,max:1000})
#判断集合是否为固定集合:
db.cappedLogCollection.isCapped()
#如果需要将已存在的集合转换为固定集合可以使用以下命令:
db.runCommand({"convertToCapped":"mycoll",size:10000})
#固定集合文档按照插入顺序储存的,默认情况下查询就是按照插入顺序返回的,也可以按照$natural调整返回顺序
db.cappedLogCollection.find().sort({$natural:-1})
MongoDB 原子操作
mongodb提供了许多原子操作,比如文档的保存,修改,删除等,都是原子操作。
所谓原子操作就是要么这个文档保存到Mongodb,要么没有保存到Mongodb,不会出现查询到的文档没有保存完整的情况。
MongoDB ObjectId
ObjectId 是一个12字节 BSON 类型数据,有以下格式:
前4个字节表示时间戳
接下来的3个字节是机器标识码
紧接的两个字节由进程id组成(PID)
最后三个字节是随机数。
MongoDB中存储的文档必须有一个"_id"键。这个键的值可以是任何类型的,默认是个ObjectId对象。
在一个集合里面,每个文档都有唯一的"_id"值,来确保集合里面每个文档都能被唯一标识。
MongoDB采用ObjectId,而不是其他比较常规的做法(比如自动增加的主键)的主要原因,因为在多个 服务器上同步自动增加主键值既费力还费时。
newObjectId = ObjectId()
ObjectId("5349b4ddd2781d08c09890f4").getTimestamp()
new ObjectId().str
MongoDB 全文检索
全文检索对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。
全文检索要用到”
t
e
x
t
“判断符,而想要进行数据的查询则使用”
text“判断符,而想要进行数据的查询则使用”
text“判断符,而想要进行数据的查询则使用”search“运算符
db.posts.createIndex({post_text:"text"}) #创建索引
db.posts.find({$text:{$search:"runoob"}}) #查询
db.posts.getIndexes() #获取索引
db.posts.dropIndex("post_text_text") #删除索引
Map Reduce
Map-Reduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。
略,后面补上
基于地理位置查询
支持4种查询:geoIntersects geoWithin near nearSphere
GeoJSON对象类型:Point,LineString,Polygon,MultiPoint,MultiLineString,MultiPolygon,GeometryCollection
经度范围[ -180,180]
纬度范围[ -90,90]
< field >: { type: < GeoJSON type> , coordinates: < coordinates > }
Polygon:闭合线至少有四个坐标对,并指定与第一个和最后一个坐标相同的位置。
MongoDB提供地理空间索引类型以支持地理空间查询。只支持2维坐标
遵循格式:
location: { type: “Point”, coordinates: [ 0, 0] }
db.collection.createIndex( { location field : “2dsphere” } )
参考:https://www.fengjinwei.com/blog-1217144.html
基于圆形查询
use places
db.places.insertMany( [
{
name: "Central Park 1",
location: { type: "Point", coordinates: [ 1, 1 ] },
category: "Parks"
},
{
name: "Sara D. Roosevelt Park 1",
location: { type: "Point", coordinates: [ 2, 2 ] },
category: "Parks"
},
{
name: "Polo Grounds 1",
location: { type: "Point", coordinates: [ 3, 3 ] },
category: "Stadiums"
}
] )
创建索引
db.places.createIndex( { location: "2dsphere" } )
基于圆形查询:
//100000为m,1609m对应1mile,地球半径3963.2mile,转换为弧度
db.places.find( {location: { $geoWithin: { $centerSphere: [ [ 1, 1 ], (100000/1609)/3963.2 ] } }} )
基于点的区域查找
db.places.find({
location:
{ $near:{
$geometry: { type: "Point", coordinates: [ 1, 1 ] },
$minDistance: 0,
$maxDistance: 1
}
}
})
基于多边形查询,注意首点、尾点一定要重合,不然会报错
db.places.find({
location:
{$geoWithin:
{
$geometry:{type:"Polygon",coordinates:[[[0,2],[2,2],[2,0],[0,0],[0,2]]]}
}
}
})
基于点,判断是否在多边形区域内部还是外部,前提是已经存在区域
db.places.find({
polygons:
{
$geoIntersects:{
$geometry:{ "type" : "Point","coordinates" : [1.1,1.1] }}
}
});
基于矩形查询
db.places.find( {
location: { $geoWithin: { $box: [ [ 0, 0 ], [ 2, 2] ] } }
} )
模糊查找
use test
db.test.find()
{ "_id" : "3CEA2E755178", "topic" : "监控机场" }
{ "_id" : "4CEA2E755179", "topic" : "监控机场" }
//两种方式模糊查找
db.test.find({_id:{$regex:"3CEA2"}})
{ "_id" : "3CEA2E755178", "topic" : "监控机场" }
db.test.find({_id:/3CEA2E7/})
{ "_id" : "3CEA2E755178", "topic" : "监控机场" }
//不区分大小写
db.test.find({"_id":{"$regex":"3ce", "$options": "-i"}})
{ "_id" : "3CEA2E755178", "topic" : "监控机场" }
//首尾不填,中间未知填*,*表示0次(含)以上
db.test.find({_id:/A2E75*17/}) == db.test.find({_id:/A2E755*17/})
{ "_id" : "3CEA2E755178", "topic" : "监控机场" }
{ "_id" : "4CEA2E755179", "topic" : "监控机场" }
db.test.find({_id:{$regex:"A2E75*17"}})
{ "_id" : "3CEA2E755178", "topic" : "监控机场" }
{ "_id" : "4CEA2E755179", "topic" : "监控机场" }
//首尾不填,中间重复5+,+表示1次(含)以上
rs0:PRIMARY> db.test.find({_id:/5+/})
{ "_id" : "3CEA2E755178", "topic" : "监控机场" }
{ "_id" : "4CEA2E755179", "topic" : "监控机场" }
//首尾不填,中间未知填?,?表示0次或1次,但是db.test.find({_id:/EA?/}) 不支持
db.test.find({_id:{$regex:"EA?"}})
db.test.find({_id:{$regex:"EA?2E"}})
{ "_id" : "3CEA2E755178", "topic" : "监控机场" }
{ "_id" : "4CEA2E755179", "topic" : "监控机场" }
三、mongo 常见问题解决
问题1:安装配置完成后尝试启动mongod进程,出现了“Process: **ExecStart=/usr/bin/mongod $OPTIONS (code=exited, status=14)”错误。经过一番探索,发现这是文件权限问题,用户mongod没有对必需文件的写权限,导致数据库服务不能启动。
sudo chown -R mongod:mongod /var/lib/mongo
sudo chown -R mongod:mongod /var/log/mongodb
sudo chown mongod:mongod /tmp/.sock
重启mongod
问题2:创建用户名开启授权后,创建索引会阻塞
解决办法:启用一下mongodb成员之间的keyfile认证
1,生成随机的keyfile文件
openssl rand -base64 756 > /etc/mongod_keyfile;chmod 400 /etc/mongod_keyfile;chown mongod /etc/mongod_keyfile
2,mongod.conf中security配置节添加keyFile选项
security:
keyFile: /etc/mongod_keyfile
问题3:关于mongodb占用内存过大的问题
未设置cacheSizeGB的情况下:系统内存与默认内存 两者取较大的来使用
系统内存,会使用到(系统内存-1GB)/2。
默认内存:使用256MB(老版本是1G,后来为了照顾小机器下调了)
主要是看storage.wiredTiger.engineConfig.cacheSizeGB,这个参数设置的是wiredTiger引擎可以使用内存的大小,
mongo在3.2的版本之前,默认引擎是MMAP,3.2版本之后,默认的是wiredTiger,因为我们的版本是4.4.2,所以就不从引擎区别上去深究了。
wiredTiger在插入的时候内存一直控制在限制之内。但在做查询或者做删除的时候,wiredTiger是限制不了内存的,内存还会上涨。
mongo的机制有点无赖,只向操作系统要内存,而不会管理内存,比较依赖系统自身的内存淘汰算法,所以我们经常能看到内存占用过高的表现。
如果集合数据量大,而索引设置的不对,也会造成内存占用超高,因为结果集都被扔到了内存。
问题4:如何判断mongo内存占用情况
通过db.serverStatus().wiredTiger.cache可以来判断内存的使用情况
重点关注五个指标:
db.serverStatus().wiredTiger.cache['maximum bytes configured']
db.serverStatus().wiredTiger.cache['bytes currently in the cache']
db.serverStatus().wiredTiger.cache['tracked dirty bytes in the cache']
db.serverStatus().wiredTiger.cache['pages written from cache']
db.serverStatus().wiredTiger.cache['pages read into cache']
rs0:PRIMARY> db.serverStatus().wiredTiger.cache['maximum bytes configured'] 16246636544
rs0:PRIMARY> db.serverStatus().wiredTiger.cache['bytes currently in the cache']
978992763
rs0:PRIMARY> db.serverStatus().wiredTiger.cache['tracked dirty bytes in the cache'] 1307942
rs0:PRIMARY> db.serverStatus().wiredTiger.cache['pages written from cache'] 243141
rs0:PRIMARY> db.serverStatus().wiredTiger.cache['pages read into> cache'] 10920
使用情况:
use test
db.stats(1073741824)
rs0:PRIMARY> db.stats(1073741824)
{
"db" : "vtollgate",
"collections" : 2,
"views" : 0,
"objects" : 1463204,
"avgObjSize" : 342.00221226841916,
"dataSize" : 0.466051516123116,
"storageSize" : 0.09939193725585938,
"indexes" : 4,
"indexSize" : 0.14574432373046875,
"totalSize" : 0.24513626098632812,
"scaleFactor" : 1073741824,
"fsUsedSize" : 31.342559814453125,
"fsTotalSize" : 497.94922256469727,
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1671367446, 1),
"signature" : {
"hash" : BinData(0,"P9PmqISHpTKaid+BKl/yx7ye3k8="),
"keyId" : NumberLong("7176641827628384260")
}
},
"operationTime" : Timestamp(1671367446, 1)
}
查看单表占用
db.test.stats(1073741824)
问题5:如何设置mongodb的缓存
方法一:
修改配置文件mongod.conf
添加内容如下
storage:
dbPath: /data/db
journal:
enabled: true #启用journal日志,false为关闭 注意:这里应该是4个空格。
engine: wiredTiger #指定存储引擎 注意:这里应该是2个空格。
wiredTiger: 注意:这里应该是2个空格。
engineConfig: #存储引擎的配置 注意:这里应该是4个空格。
cacheSizeGB: 4 #来指定mongodb使用内存的多少-8G 注意:这里应该是6个空格。
方法二:
直接登mongo修改
db.adminCommand( { "setParameter": 1, "wiredTigerEngineRuntimeConfig": "cache_size=1G"})
db.serverStatus().wiredTiger.cache['maximum bytes configured']/1024/1024/1024
问题6:如何检测mongo状态
db.serverStatus()
总结
本文主要讲解了mongodb的linux服务器上的安装,基本功能,使用,后面文章会讲解c++来实现mongo的crud功能。
老铁:如果觉得海不错,别忘了随手点赞转发+关注哦!
















 890
890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











