







1.FT
相当于有若干台电脑在执行相同的事情,只要能保证它们的状态完全一致,就可以达到可靠性的要求。
只要备份服务器的状态在任意时间必须与主服务器几乎相同,从而在主服务器宕机后可以快速接管。
GFS提供的只是存储的容错,
有两种做法:
- State Transfer, replicating the state ,即发送整个状态,包括内存状态、CPU寄存器等,适用于多核机器
- Replicated State Machine, the state-machine approach,只需要发送一些会引起分歧的操作即可,不适用于单核机器。
状态机方法有相对低的带宽需求,因此可以运行主和备份服务器分布在更广的物理区域。
异步事件、输入、输出必须发送log entries
Primary发送给backup的数据大致包含三种:指令号(从开机以来执行的第几个指令),指令类型(type),数据(data)
-
如果Primary对client的请求处理完毕后就马上输出,然后传送给backup,那么可能在传给backup的时刻,Primary死机,那么backup不会收到该请求。而该请求又发给了client,那么client就会误判服务器的状态。为了避免此现象,要对输出设定一定规则。
输出规则:延缓Primary VM的输出,是为了确保backup接收到了相同的请求(并不一定处理完请求,只需收到即可),从而在Primary宕机后可以恢复到一致的状态。
如果Primary最后一条指令为输出指令,输出完后挂掉,那么backup最后也会执行到这样的
可能会有重复输出现象,但这种现象无法避免,需要应用判断是否为重复的数据。如果使用TCP协议,那么该协议本身可以提供这种检测重复的功能。 -
为避免脑裂问题;出现网络分区错误时,Primary和backup不能通信,但二者都可以和client通信,此时二者都会认为对方挂掉了,因此想要go live。
在共享存储上执行原子的test-and-set操作(类似锁操作),只有成功的才会允许go live -
为Primary比backup快很多,导致接管时需要较长时间处理缓存的事件,同时避免backup执行比Primary快
设立了backup buffer,只有其中有log时,才会执行。
(1)如果log buffer为空,则backup buffer等待;当primary的log buffer为满时,也需要等待。近似于流控制机制。
(2)为防止primary VM和backup VM之间的lag time过大,在发送log entries时需要检测当前lag,如果过大时则减慢primary VM执行,通过反馈缓慢确定适当的CPU限制。 -
bounce buffers
有网络数据包到来时,会通过DMA将其复制到内存中,而相关软件还在执行,复制完成后DMA发送中断。
而为了精确知道这个时刻,当有数据到来时,FT首先会将其复制到bounce buffers中,当复制完毕后,VMM(Virtual Machine Monitor)会中断虚拟机的执行, 再将其复制到虚拟机内存后,记录当前时刻,再恢复Primary的执行。将该记录发送给backup,backup’s FT的在相同指令处中断,复制数据到backup的内存中。如此,数据将会出现在相同时刻。
发送特殊的control entries
hypervisor是虚拟机系统的一部分,FT是hypervisor的一部分
2.Raft
1. 概述
假设有两个主机,客户端再与主机通信时,如果需要和两个主机同时通信阻止脑裂问题,那么就丧失了容错性。而只要求和一个主机通信即可,那么在发生网络partition错误时,就会导致不一致的问题。FT使用的共享存储是一个办法,但仍具有单点故障问题。因此,有了多数投票算法。
在一个具有
2
∗
f
+
1
2*f+1
2∗f+1的集群中,最多可以容忍
f
f
f台故障。
需要注意的是,这里的多数是指相对于原来数量,而不是故障后剩余的数量。
多数投票算法的核心思想是:任何决定都需要多数服务器同意,那么任何相邻的决定覆盖范围中肯定至少有一台服务器是重叠的。
一般服务器数量为奇数,这样即使发生network partition将服务器划分为两部分,那么必定有一部分多,一部分少,虽然这两部分都可能会有一个Leader(原Leader位于少部分的那块,多的部分新选出一个Leader),那么client向少部分的Leader发送的请求,因为无法获得大多数的存储,因此永远不会提交。只有多部分服务器的请求会被提交。
如果network partition修复,那么由于多部分服务器的新Leader用于更高的Term,其会作为整体的Leader。
整体系统架构如下图所示,在上层有应用,当client请求到来时,上层应用通过Start接口(参数为command,返回值为Term,index等)通知下层Raft,当底层Raft确认多数服务器都复制log后,使用ApplyCh通知上层应用。之后应用返回给client对应请求的响应。
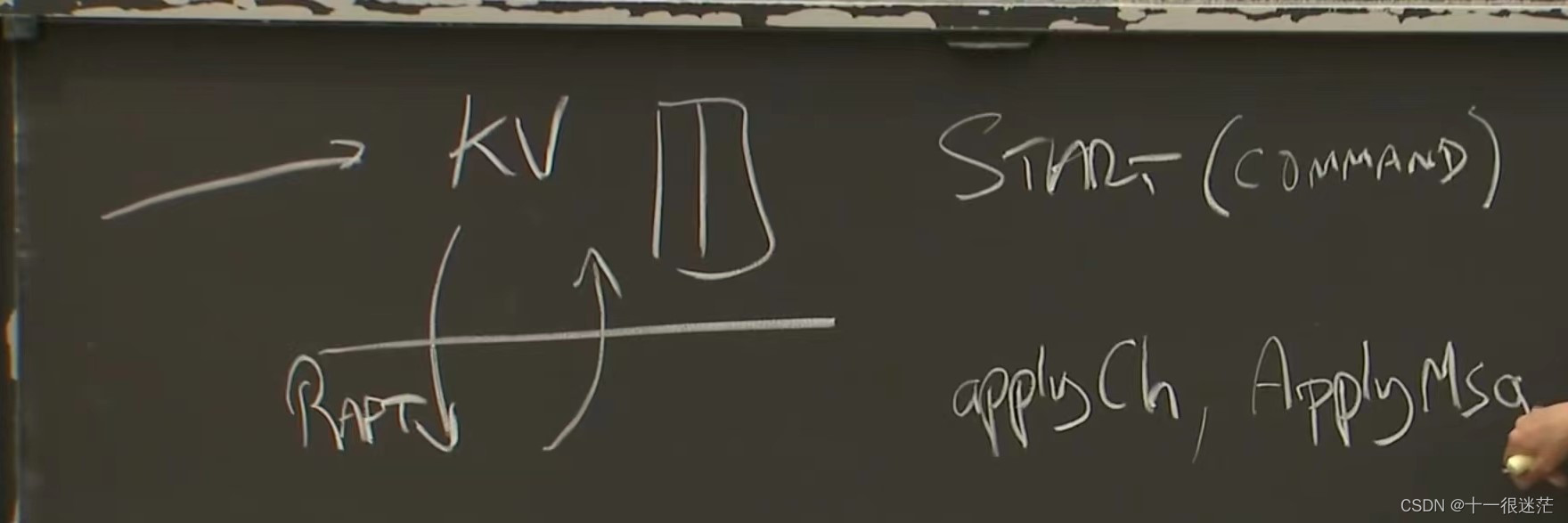
2. 介绍
Replicated state machine计算相同状态的相同副本,典型由 a replicated log实现。每个server都存储包含一系列命令的log,为了保证log中的命令具有相同的顺序,需要使用Consensus Module来管理(即使用一致性算法)。
Raft是一致算法用来管理复制的log,
解耦(分离了一致性算法的关键元素,如领导者选举、日志复制、安全性和成员变化)及状态空间压缩。
首要目标是可理解性。
- Strong leader:log entries只能从leader流向其他服务器。
- Leader election:使用随机计时器来选举leader
- Membership changes:新的联合共识方法,其中两个不同配置的大多数在转换期间重叠。
安全性:不会产生错误的结果。
可利用性:具有完整的功能,只要大多数服务器可操作,能彼此通信,能和client通信
在一般情况下,只要大多数集群响应了一轮远程过程调用,命令就可以完成;少数慢速服务器不需要影响整体系统性能
Paxos选择single-decree subset作为其基础,造成其不透明性。
2.1总体流程
首先选举一个Leader,Leader接收clients上的log entries,复制到其他servers上,并且指定了执行该log entries的时间。(Leader故障或断开连接后,会选取一个新的Leader)
任何时刻服务器处于三种状态之一:leader, follower, or candidate。正常运行时,只有一个为leader,其于为follower。Leader处理所有clients上的请求。(如果client联系了一个follower,follower会将其重定向到leader)。candidate是选取leader时的状态。
将时间划分为任意长度的Terms,并使用整数标识。每个Terms都会开始一个election,选出一个leader,然后开始正常执行。如果无法成功选出一个leader(出现平票情况),则该Terms结束并立即开始一个新的Terms。不同服务器可能在不同时刻观测到Terms的过渡,有些情况下一个服务器察觉不到election甚至整个Term。
为此,每个server存储了current term number,在服务器交流时会交换此信息。因此,可以清楚过时的数据。server发送请求时也会附带current term,如果服务器接收到带有过期term的请求,它将拒绝该请求。
2.1.1 Leader election
使用心跳机制触发Leader election
如果长时间没有收到leader的心跳信息(AppendEntries RPCs,但没有任何log entries),会增加其存储的current term并变为candidate状态,并行的向所有server发送RequestVote RPCs。
每个server至多为一个candidate投票,按照先到先得的原则。server投完票后,也会增加其term。
两个重要时间:
(1)election timeout:为了避免无限重复的分裂投票情况,使用randomized election timeouts方法(一开始就使用)(每个选举阶段,candidate会重新选取其timeouts)。需要注意,server投票后,会重新开始election timeout的计时。
(2)heartbeat timeout:选出Leader后,其会发送Append Entries(周期发送,heartbeat timeout),server收到后都会重新开始election timeout计时。
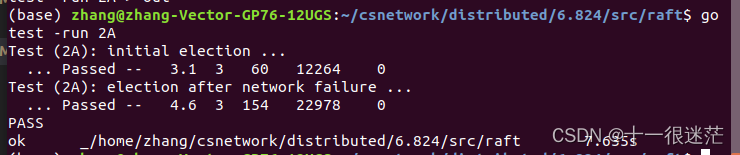
1. 实验部分 lab 2A
此处需要注意的点是:
- 选举Leader后,各服务器维护的votedFor变量已经设置了,当前Leader宕机时,开始新的选举,此时如果简单的按照下图所示情况,那么无法选举新的Leader。感觉下面的条件更适合初始化的时候使用。

注意论文中的描述是:在任一Term内,每个服务器最多将投票给一个候选人。因为其他服务器变成Candidate时,相当于开始新的Term,因此其他服务器可以通过判断Term与currentTerm的关系决定是否进行新的投票。 - 随机化选取election timeout时,要注意尽可能分散开,例如:每50ms执行一次对election timeout的检查,那么election timeout的选取如下
rand.Intn(10)*50 + 200
- 正如实验强调的部分,发送
RequestVote时,不能直接将rf.currentTer复制给arg.Term,如下所图所示。这是因为外面的rf.currentTerm很可能在过程中改变,这样会造成意外的行为。

- 确定投票时才重启election timeout,而非收到
RequestVote请求时。如果在一个较差的网络环境中,各服务器可能有不同的log记录,如果收到请求就重启计时器,那么具有过时log的服务器将和具有最新log的服务器有相等机会开启选举,那么很可能其被选取为Leader(可能这个过时log的服务器随没有最新的log,但log比其还低的服务器仍有很多,它们可能将票投给该服务器)。而如果确定投票时才重启,那么具有最新的log不会被过时的服务器中断,更可能胜出。
2. 实验部分 lab 2B
bug记录:
- 如果简单的按照Term的比较方式的话,可能出现的情况为:发送了network partition错误,原Leader位于服务器多的一方,服务器少的一方不断变为Candidates,不断增加 currentTerm,如果此时修复网络,那么服务器少的一方因为其currentTerm最大,当前变为Candidates时发送RequestVote,原Leader会变为Followers,需要重新选取Leader。
此时必须加入日志的限制,防止服务器少的一方变为新Leader。注意,投票时的规则是,拥有旧的log的服务器给新的log投票。千万不能写反(自己犯过这个错误)。
原先方式如下:

上述会导致log长的服务器会获得投票,必须要加上在Term相等情况下的限制

- 一方面是每次选举成为新的Leader时,都需要重新对nextIndex和matchIndex初始化。

- 在发送AppendEntries后,不能直接使用len(rf.log)来更新matchIndex或nextIndex,这是因为在发送或等待AppendEntries过程中,很有可能rf.log已经改变(来了新的start请求)。

在发送AppendEntries时,要把nextIndex到len(rf.log)之间的数据一次性发送,这样只要log匹配上了,就可以在一次发送完毕,减少发送AppendEntries的次数。
- 性能优化;之前对nextIndex的更新是如果AppendEntries失败,那么就递减nextIndex,最简单的方式是每次递减1,但这样的问题是比较慢,需要发送很多RPC请求才能匹配上。
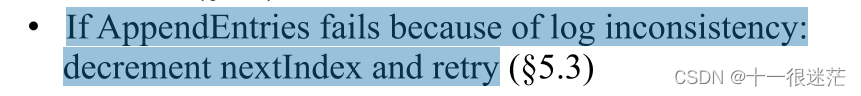
正如论文中所述的那样,为了加快匹配进度,需要在AppendEntries的响应中添加额外信息ConflictIndex和ConflictTerm。
(1)如果PrevLogIndex处的PrevLogTerm不匹配,那么将ConflictTerm = log[prevLogIndex].Term,ConflictIndex设置为ConflictTerm对应的第一个索引。此时出现两种情况:
a)在Leader中,如果rf.log出现了ConflictTerm,那么可以将nextIndex设置为Leader中rf.log的ConflictTerm对应下的最后一个索引的位置 + 1
b)如果没有ConflictTerm,则简单将nextIndex = ConflictIndex,这样就能将ConflictTerm对应的log全部取代
因为我们是严格按Term顺序存储log,就Term而言其是有序序列,那么上述找到某一个Term的第一个元素和最后一个元素,可以使用二分查找来实现。
(2)服务器的PrevLogIndex处还没有log,将ConflictIndex = len(rf.log),ConflictTerm = -1,直接从服务器存储log处开始匹配
最终的效果如下所示:时间上确实有提升
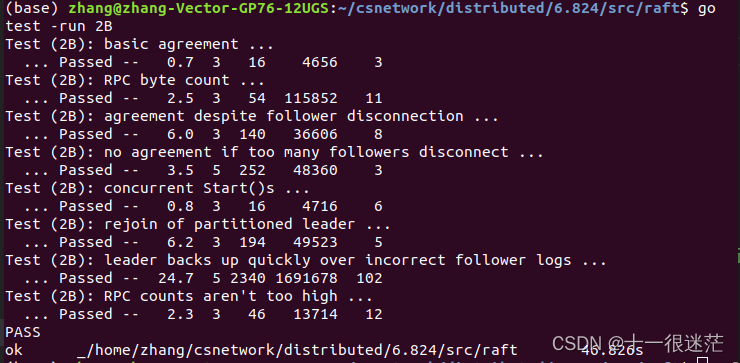
3. 关于Log replication进一步理解(Fig 8)
假设发送网络分区错误,服务器0位于少部分的服务器区。如果Leader2在term为1时,假设其commit为5,新收到请求一个请求为
C
6
C_6
C6,此时server0重新接入连接。server2重新当选为Leader,此时term可能变为4,其会复制其log到server0中,但commit最大为5,因为
C
6
C_6
C6的Term与当前不匹配无法提交。即使可以保证
C
6
C_6
C6被复制大多数服务器上,因为可能其他服务器具有更新的term项假设为
C
7
C_7
C7但没有
C
6
C_6
C6,其具有当选为新的Leader的可能,一旦其当选,会将
C
6
C_6
C6覆盖掉,即论文中图c到图d的情况。
如果Leader2收到一个新请求
C
8
C_8
C8,如果
C
8
C_8
C8成功复制到大多数服务器中的话,可以提交
C
8
C_8
C8,那么
C
6
C_6
C6就可以被提交。这是因为之后只有具有
C
8
C_8
C8的服务器可以被选举为Leader(其前面也必有
C
6
C_6
C6,因此可以提交),对应原论文Fig 8中图e的情况,这就是Log Matching规则。
上面的情况,实际上论文中有描述,但读的时候可能就一笔带过,实际上这个细节对理解系统的运行很重要。

4.读请求
这也是后续第八节为什么在新的Term开始处理读请求时,领导者需要先提交一个no-op条目才能知道哪些条目被提交
2.1.2 Log replication
每个client请求会包含一个命令
每个entry包含:Term号,实际命令,entry index
如果由故障发生,Leader会无限期的重复AppendEntries请求,即使在回复client后,直到所有followers存储所有log entries;
一旦创建日志条目的Leader将其复制到大多数服务器上,日志条目就被提交。并且意味着,在Leader’s log中该log index之前的条目也被提交。
(1)Leader将跟踪最高的committed index,并将其添加到之后的AppendEntries请求中,以便其他服务器知晓。一旦follower知道某个log entry被提交,它将在本地执行该条目。
如果follower没有在其日志中找到具有相同log index和Term的条目,那么它将拒绝新的条目。
(2)在Raft中,leader通过强制follower的日志复制leader的日志来处理不一致问题。
leader为每个follower维护了一个nextIndex,标识leader发送给该follower的下一个条目。刚开始,所有的nextIndex初始化为leader日志中最后一个索引之后的索引,请求失败后递减nextIndex重新请求。
优化上述过程:当follower拒绝时,其会在回复中包含冲突条目的term,及在该term下存储的第一个index。
2.1.3 Safety
限制被选举为leader的服务器(确保之前提交的条目都在该服务器的log内)
RequestVote包含了candidate’s log的信息,如果投票人自己的日志比candidate的更新,投票人就会拒绝投票
只有leader的当前Term的条目能够通过计数复制品的方式提交。
2.1.4 Log compaction
使用Snapshotting方法,当前整个系统状态被写入到snapshot中,并存储下来,清空快照对应的log条目和之前的快照。
snapshot中的元数据:
last included index、
last included term(快照中包含的最后log条目的索引和term)。
保存上述两个,是为了应对AppendEntries consistency check
latest configuration(last included index对应的)
当leader已经丢弃了需要发送给follower的下一个日志条目时,leader必须给落后较多的follower发自己的快照。
客户端为每个命令分配唯一的序列号。如果leader在提交日志条目后崩溃,防止新的leader重试该命令,导致它被第二次执行。
只读请求不要写入log,Raft通过让每个leader在任期开始时在日志中提交一个空白的无操作条目来保证Leader具有所有已提交的条目。leader必须在处理只读请求之前检查它是否已经被罢免
2.1.5 Persistent
持久化currentTerm,需要保证一个Term至多有一个Leader
持久化votedFor,是为了防止重复投票。(如果没有持久化,当前Term下已经投过票,系统重启后会重新投票)
为什么不需要持久化lastApplied? 因为不需要保存系统状态,重启后需要会重新应用log中存储的这些条目。
2.1.5.1 实验部分 lab 2C
此部分实验比较简单,按照示例实现函数后,插入到改变的地方即可。(如果你真这么想就天真了)
但最好多测试几次,这样才能测试出来bug。可能需要你在数千行的日志中找bug(典型是8000多行,够酸爽)
- 实验中一直发现会出现莫名其妙的投票,即拥有新日志的投给旧日志的,一直以为是选举那里出了问题,最后排查发现是未完全删除之前的日志导致的(如果日志冲突,则删除该日志之后的所有元素),原先代码如下图,下面的问题是在删除过程中,
len(rf.Log)也一直在改变,导致删除不完全(排查了一天,查看的打印输出得到达2万行了,血泪教训),这样在选举时判断最新的日志的rf.Log(len(rf.Log)).Term,则很有可能是使用过时的数据,从而导致错误的投票。

最终经过二十余次的运行,都可用正常通过
2.1.6 Log compaction
一直存储Log,会消耗过多的存储空间,并且重启后恢复起来也非常慢,Leader可以每隔一段时间或者Log存储超过一定限度,就保存一个快照,记录一个LogIndex,然后将之前的Log丢弃。
这里有一个问题就是:其他的Server不一定可以跟的上Leader的进度,也就是说可能有的Server的Log还未到LogIndex,就宕机了,因为此时Leader将LogIndex之前的丢弃了,因此就无法使得该Server的日志和Leader保持一致。
为解决上述问题,引入了一个新的RPC调用InstallSnapshot,如果Server的Log还未到LogIndex,则直接发送当前的快照即可。
3 限制
为达到持久化的目的,每次操作后都写入硬盘(更好的方式是积攒一批,类似于fsync和write的关系)
快照的设计对小系统是有用的,更好的方式是仅仅存储最近改变的部分
如果包含副本的数据中心和客户端的彼此相距较远时,使用Raft不太合适;Paxos没有Leader(需要发送更多消息协调),任何副本都可以start an agreement,即任何服务器都可以在任何时候有效地充当领导者;因此,客户端可以在本地数据中心与副本进行通信,而不必与远程数据中心的领导者进行通信。
客户端的请求失败时,会重新发送请求,因此必须防范重复成功的请求。
3.1 与VM FT相关性
VMware-FT的test-and-set server存在单点故障问题,可以将该服务使用Raft实现。
4.相关资源
可视化Raft的网址 http://thesecretlivesofdata.com/raft/#election














 468
468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









