







\G是垂直显示;
1. 体系架构
MySQL实例在系统上的表现就是一个进程(多线程)
(1)多个配置文件中有相同参数,以哪个为准?
MySQL以读取到的最后一个配置文件中的参数为准。
InnoDB存储引擎是多线程模型;
后台线程的主要作用是负责刷新内存池中的数据,并写回脏页
1.1 Master thread
1.2 IO thread
innodb_read_io_threads和innodb_write_io_threads在ubuntu20.04下默认仍分别为4个线程。
处理AIO(Async)请求
read threads负责预读功能
write threads负责写回脏页
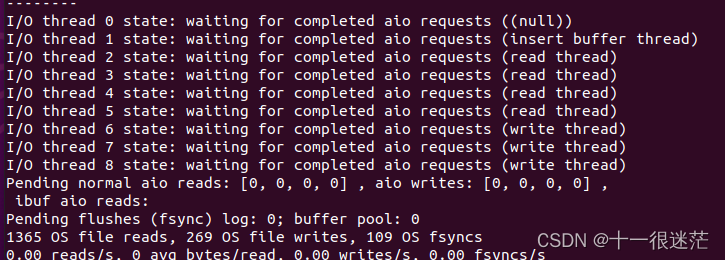
目前执行来看,与书中展示的还是有所区别的。
1.3 Purge thread
事务提交后,回收undo log
1.4 Page Cleaner thread
专门刷新脏页。
将 redo log buffer 中的日志,调用 write 写到文件系统的 page cache 中,然后调用 fsync 持久化到硬盘;
2. 存储引擎内存
2.1 缓存池
支持多个缓存池实例。每个页根据哈希值平均分配到各个缓存池实例中。
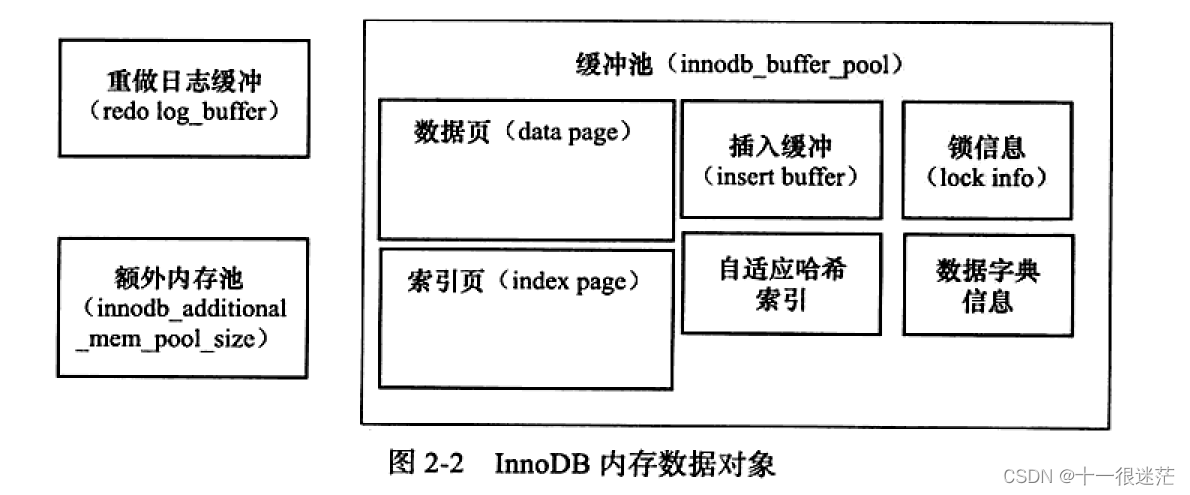
(1)缓存的管理是采用LRU算法,缓存中页的大小默认为16KB。Database pages表示LRU链表中页的数量
-
做了一些优化,在链表中额外维护了一个
midpoint的位置,每次新读取到的页,不是插入到链表头部,而是midpoint处(并非真正的中点,可以自行设定,默认是5/8位置处)。 -
innodb_old_blocks_time表示页读取到mid位置后需要等待多久才会被加入到LRU链表头部。
这是为了避免缓存污染,防止在表的扫描操作中将热点数据驱逐。
(2)缓存中的空闲的页由Free链表维护。初始时,页都放在Free链表中。
(3)自适应哈希索引、Insert Buffer等不需要LRU来管理,因此也不在LRU链表中
(4)页压缩管理;对于非16KB的页,由unzip_LRU链表进行管理,其对不同大小的页(1/2/4/8KB)分别进行管理,类似空闲链表的做法。
例如,需要4KB大小的页
- 先检查4KB的
unzip_LRU链表是否有空闲页 - 若有,则直接使用
- 否则,检查8KB的
unzip_LRU链表,若能够得到空闲页,分成2个4KB的页,存放到4KB的unzip_LRU链表; - 若不能得到空闲页,从
LRU链表中申请一个16KB的页,分成1个8KB的页、2个4KB的页,分别存放到对应的unzip_LRU链表;
从上述分配规则来看,unzip_LRU链表管理的页实际上也都在LRU链表中。
(5)Flush链表维护脏页。脏页即存在于LRU列表中,也存在于Flush列表中。
2.2 redo缓存
首先将redo log放入这个缓冲区中。
将redo log缓存中的内容刷新到磁盘的redo log文件中的三种情况:
- master线程每隔一秒;
- 每个事务提交时;(如果
innodb_flush_log_at_trx_commit设置为1,也会把其他事务的 redo log 刷新到磁盘) - 当redo log缓存剩余空间小于1/2时;(后台线程负责,这里只是调用了 write 写到操作系统的缓存中)
从redo缓存往磁盘写回时,按512字节(一个扇区大小)为单位,可以保证写入必成功(可认为是原子操作),不需要doublewrite
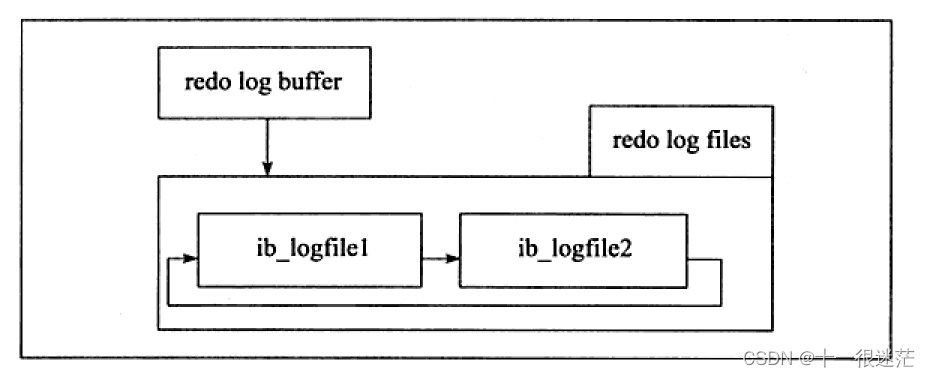
2.3 额外的内存池
维护内存池本身的数据结构的内存是从额外的内存池中进行申请的,例如LRU等信息。
在申请很大的InnoDB缓冲池时,也应考虑相应增加该值。
3. Checkpoint技术
(1)Sharp Checkpoint发生在数据库关闭时,将所有脏页都刷新回磁盘。
(2)Fuzzy Checkpoint发生在数据库运行时,只刷新一部分脏页。
- master线程每隔一段时间从脏页链表中刷新一定比例的页
- 需要保证LRU链表中有差不多100个空闲页可供使用,若不满足,会将LRU尾端的页移除,如果移除的为脏页,需要进行Checkpoint
- 重做日志不可用时,强制刷新回一些页。因为重做日志文件是循环使用的,需要保证还有空间存放redo log,若无空间,需要产生Checkpoint(从上图中可以看出,循环利用的特性)。从
Flush链表中刷新 - 脏页数量太多
4. Master Thread
下述的 io_capacity 代表主机的 IO 能力,最好设置为磁盘的 IOPS
4.1 active_task
每秒一次的操作包括:
- 日志缓存刷新到磁盘,即使事务没有提交(调用fsync操作)
- 如果前1s内发生的IO数量小于阈值
5% * io_capacity,合并5% * io_capacity个插入缓存 如果脏页占比是否超过max_dirty_pages_pct(当前为75%),至多刷新100个缓存池中的脏页(Page Cleaner Thread进行)- 如果没有用户活动,切换到
background loop
4.2 background loop
background loop中进行
- 删除无用的undo页
- 合并
io_capacity插入缓存 - 如果不是空闲,返回主循环;
否则,不断刷出100个页直到小于阈值max_dirty_pages_pct- 挂起,等待事件发生,返回主循环。
4.3 idle_task
每10秒执行一次的操作包括:
过去10s的IO数量若小于io_capacity,刷新io_capacity脏页到磁盘- 合并
5% * io_capacity个插入缓存 - 刷新日志缓冲到磁盘
- 删除无用的undo页
当前脏页占比大于70%,刷新io_capacity脏页到磁盘,否则,刷新10% * io_capacity脏页到磁盘
上述中,刷新脏页到磁盘的操作分离到一个单独的线程Page Cleaner Thread中进行
5. 关键特性
5.1 插入缓存
聚集索引一般情况下是顺序插入的,即顺序IO,例如,很大情况下,主键是自增的列,不需要用户指定;而对辅助索引,就要涉及到随机读写了。
使用 Insert Buffer需要满足两个条件:
- 索引是Secondary index(即物理磁盘上记录不是按照该索引顺序存放的)
- 索引不是唯一的
先判断插入的Secondary index页是否在缓存池中,若在,直接插入;否则,插入Insert Buffer中。
(1)要求索引不唯一。因为,插入到Insert Buffer中时,不会检查索引的唯一性。若要检查的话,又要涉及到随机读写了。
(2)其内部实现为一棵全局B+树(对所有表的插入缓存进行维护),存放在共享表空间中。

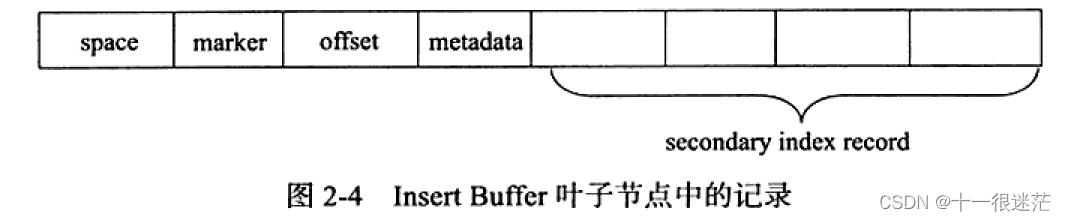
space是表的ID。
offset是页的偏移量。
(3)插入缓存中,除了B+树结构,还有额外的特殊的页:Insert Buffer Bitmap 标记每个Secondary index页的可用空间,及是否有索引缓存在Insert Buffer中
-
存储位置:在每个ibd文件中,每个Extent中的第二个页(每256MB,即16384个页)是一个Insert Buffer Bitmap页。
而每个Insert Buffer Bitmap页,可以管理16384个辅助索引页 -
主要目的:从上述Insert Buffer的节点中可以看出,这些缓存数据都是针对某个页来说的,因此需要保证合并时不会出现空页或者页分裂的情况。
Bitmap页 主要是为了保证合并插入缓存时有足够的空间,不发生页分裂情况。
当在Insert Buffer中缓存记录时,会修改相应Bitmap的信息。
(4)合并Insert Buffer的时机:
- Secondary index页读到缓冲池时;例如,用户线程选择辅助索引进行数据查询时,需要检查Insert Buffer Bitmap,是否有缓存在Insert Buffer
- Insert Buffer Bitmap追踪到该Secondary index页已没有足够的可用空间时,强制读取辅助索引页,进行合并。
- Master Thread,随机选取一个页
若进行merge时,要进行merge的表已经被删除,则直接丢弃相应的Insert Buffer的记录
(5) Change Buffer中缓存了删除操作,不在二级索引中真正执行。那么删除操作时,返回给客户端的影响行数怎么算出来的呢?
实际上会读取聚簇索引,也可能读取二级索引。注意:InnoDB 的删除逻辑是先删聚簇索引, 再删除二级索引(标记删除)。
5.1.1 注意事项
(1)更新删除操作时,如果需要先读后写,那么就不需要 Change Buffer;
(2)数据写入 Change Buffer 中时,也会记录 redo log,那么如果 redo log 文件设置的太小,必须不断做 Checkpoint,涉及到 Change Buffer 中的 redo log 时就会触发 merge 操作,进一步增加脏页数量,使得 Change Buffer 的优化也失效;
5.2 两次写
处理部分写失效问题
对缓存池脏页写回磁盘时
- 通过
memcpy函数复制到内存中的doublewrite buffer - 分成两次,每次1MB顺序写入共享表空间的物理磁盘上
doublewrite;调用这两次write后马上调用fsync函数,同步磁盘。(此步为顺序IO) - 完成
doublewrite页的写入后,再将doublewrite buffer中页写入各个表空间文件中。
操作系统在将页写回磁盘过程中发生崩溃后,恢复时,可以在doublewrite中找到该页的副本。
5.3 自适应哈希索引(AHI)
针对各索引页建立哈希表,并且是通过缓冲池的B+树页构造,不需要对整个表建立索引,会自动根据访问频率和模式为某些热点页建立哈希索引。
要求页的连续访问模式必须是一样的。访问模式是指查询的条件一样。
以该模式访问100次
页通过该模式访问了N次
5.4 异步IO
InnoDB都采用异步IO的方式处理磁盘请求。
同步:每进行一次IO操作,需要等待此次操作结束后才能继续。
发送全部的IO请求后,再等待。而非发出一次,等待完成后,再发送另一次。
可以进行IO merge操作














 1605
1605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









