






docker搭建简单elk日志系统1
docker搭建简单elk日志系统2
docker搭建简单elk日志系统3
docker搭建简单elk日志系统4
如有疑问可以去上面文档找相关内容
1.查看logstash管道配置文件logstash.conf
cd ~/elk/logstash/pipeline/
cat logstash.conf

默认的配置文件输入是beat;
beat表示ELK Stack中的核心组件Beats;
Beats指轻量型数据采集器,是一些列beat的合称;目前官网上的beat有:
Filebeat
用于采集日志和其他数据的轻量型采集器
Metricbeat
轻量型指标数据采集器
Packetbeat
轻量型网络数据采集器
Winlogbeat
轻量型 Windows 事件日志采集器
Auditbeat
轻量型审计数据采集器
Heartbeat
用于运行状态监测的轻量型采集器
那么搭建日志系统所用的beat就是filebeat;关于filebeat连接logstash,在
docker搭建简单elk日志系统4中有相关配置
默认的配置文件输出是stdout;
stdout(标准输出),即默认会将beat发送过来的数据打印到控制台上
2.修改logstash的默认输出
通过filebeat收集的日志传到logstash中,logstash处理后最后要传送到elasticsearch才能让日志持久化到磁盘中,方便后续查看分析;
vim ~/elk/logstash/pipeline/logstash.conf
在output中添加
elasticsearch {
hosts => ["https://192.168.182.128:9200"]
index => "%{[fields][env]}-%{[fields][application]}-%{+YYYY.MM.dd}"
cacert => "/usr/share/logstash/config/certs/http_ca.crt"
user => "elastic"
password => "+4TMJBgOpjdgH+1MJ0nC"
}

logstash.yml相关配置
hosts :elasticsearch的地址;使用https;同logstash.yml中的配置
index:索引,所有存到elasticsearch的数据都需要设置索引([fields][env]和[fields][application]是在filebeat中添加的自定义字段)
cacert:elasticsearch证书;同logstash.yml中的配置
user :elasticsearch账户;同logstash.yml中的配置
password :上面user对应的密码;同logstash.yml中的配置
3.重启logstash
docker restart logstash

4.生成日志供filebeat收集
这里生成了一条错误日志
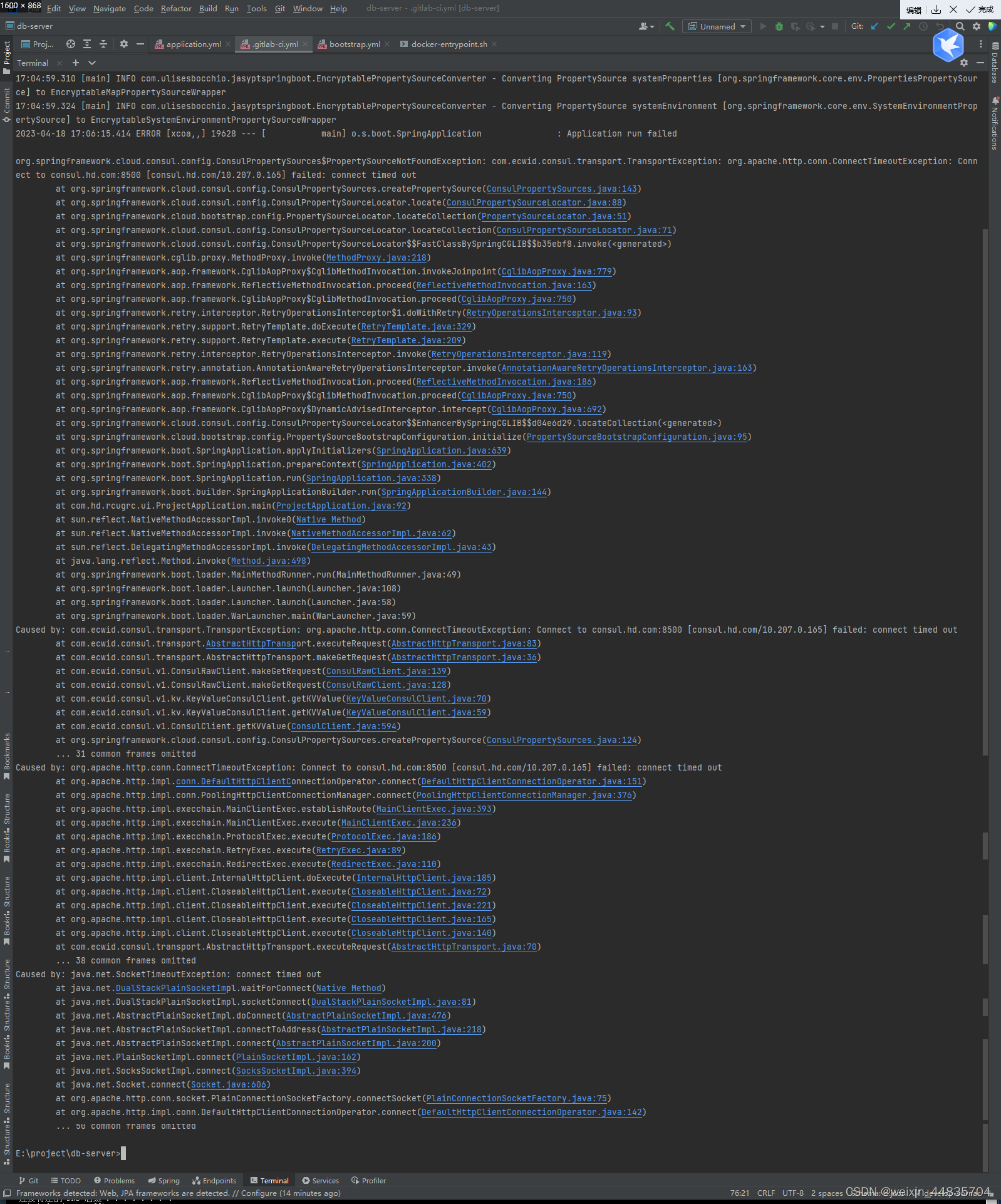
查看logstash日志
docker logs -f --tail 200 logstash

5.登录kibana查看是否生成索引
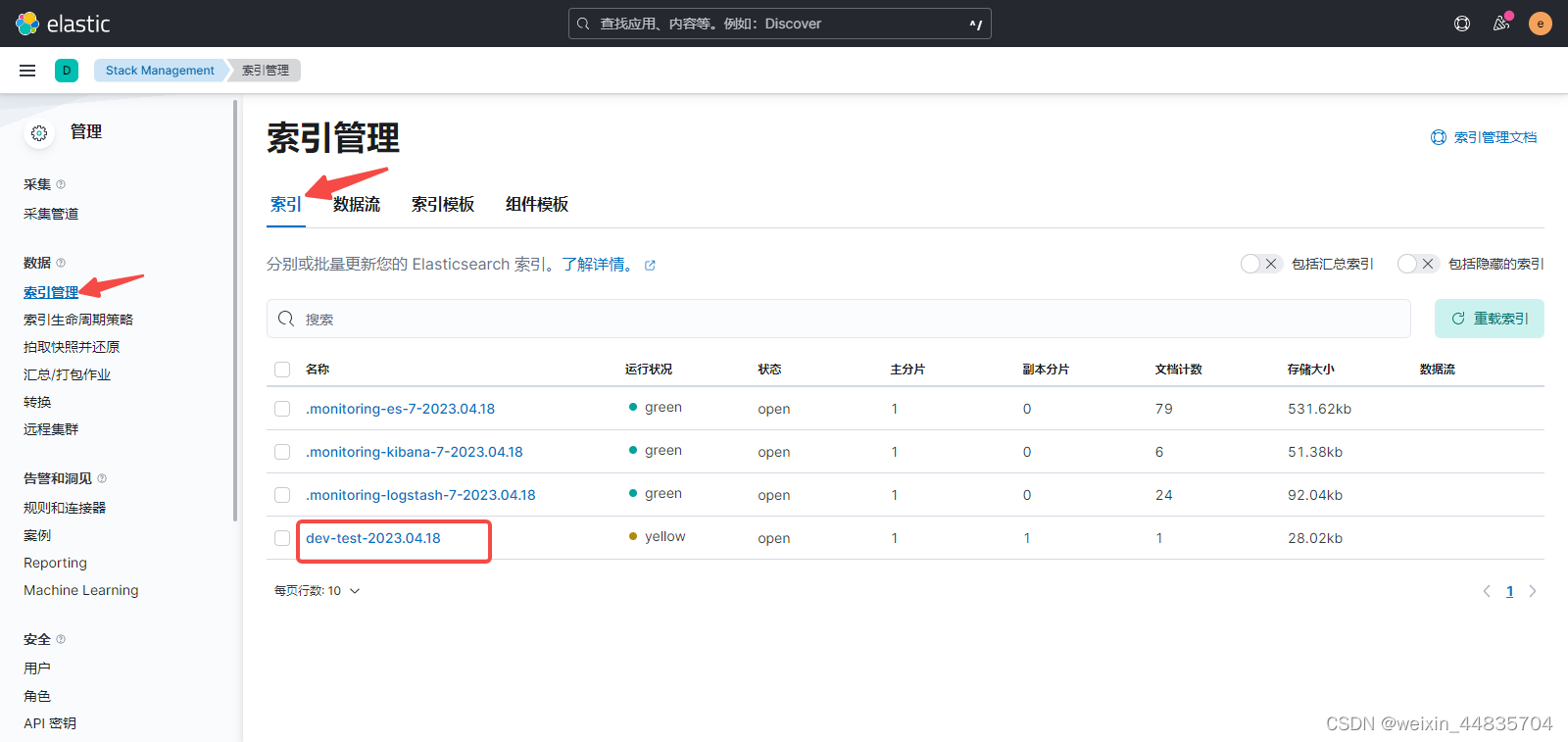
此处生成了一个名为dev-test-2023.04.18的索引;
这个索引由logstash.conf中的index配置生成的
index => "%{[fields][env]}-%{[fields][application]}-%{+YYYY.MM.dd}"
{[fields][env]}和%{[fields][application]}分别表示取json数据中的fileds.env和fileds.application字段;
fileds.env和fileds.application是在filebeat配置中设置的
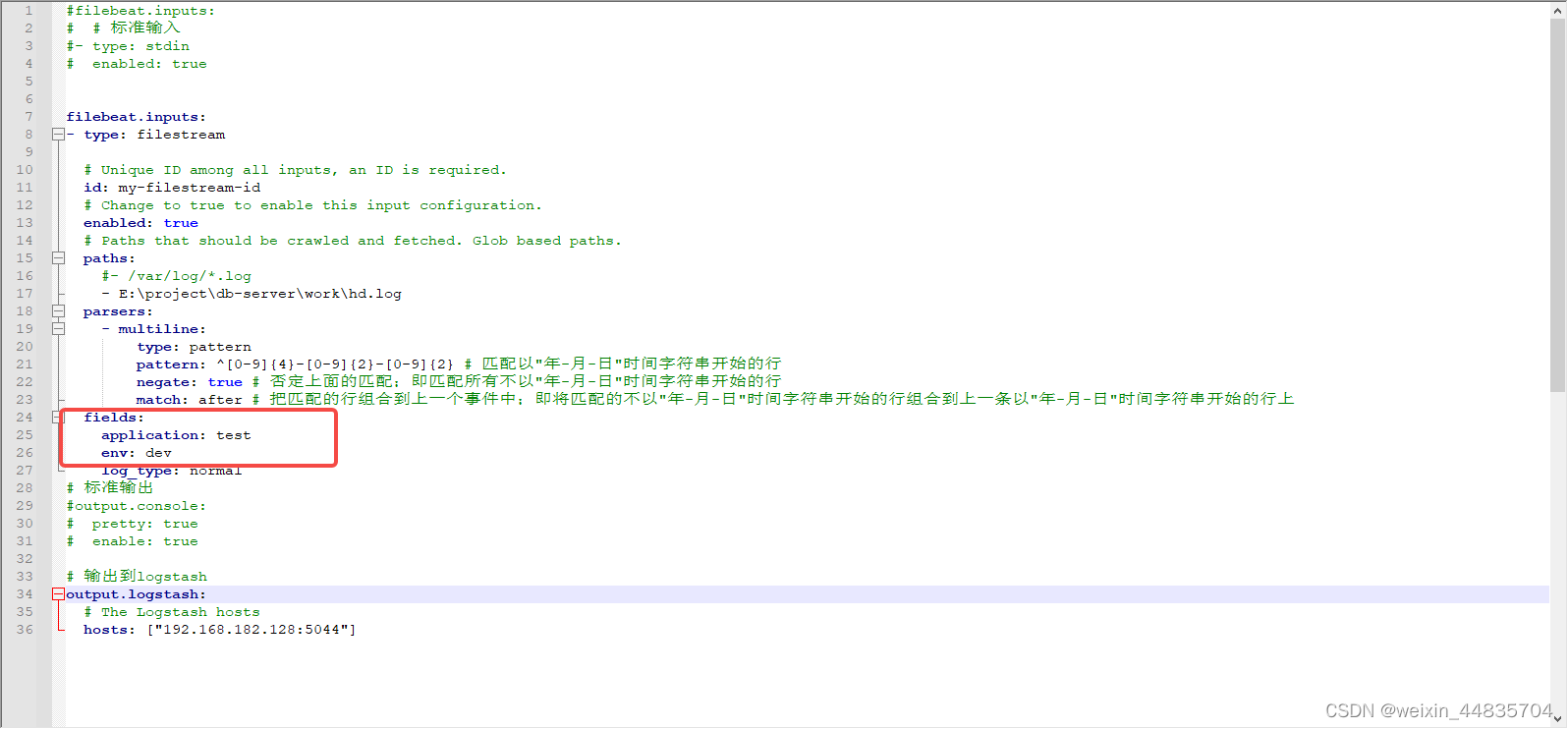
%{+YYYY.MM.dd}表示取当前日期;索引名中动态取当前日期意味着,每天产生的日志对应elasticsearch中都有一个单独的索引
6.在kiban中查看日志
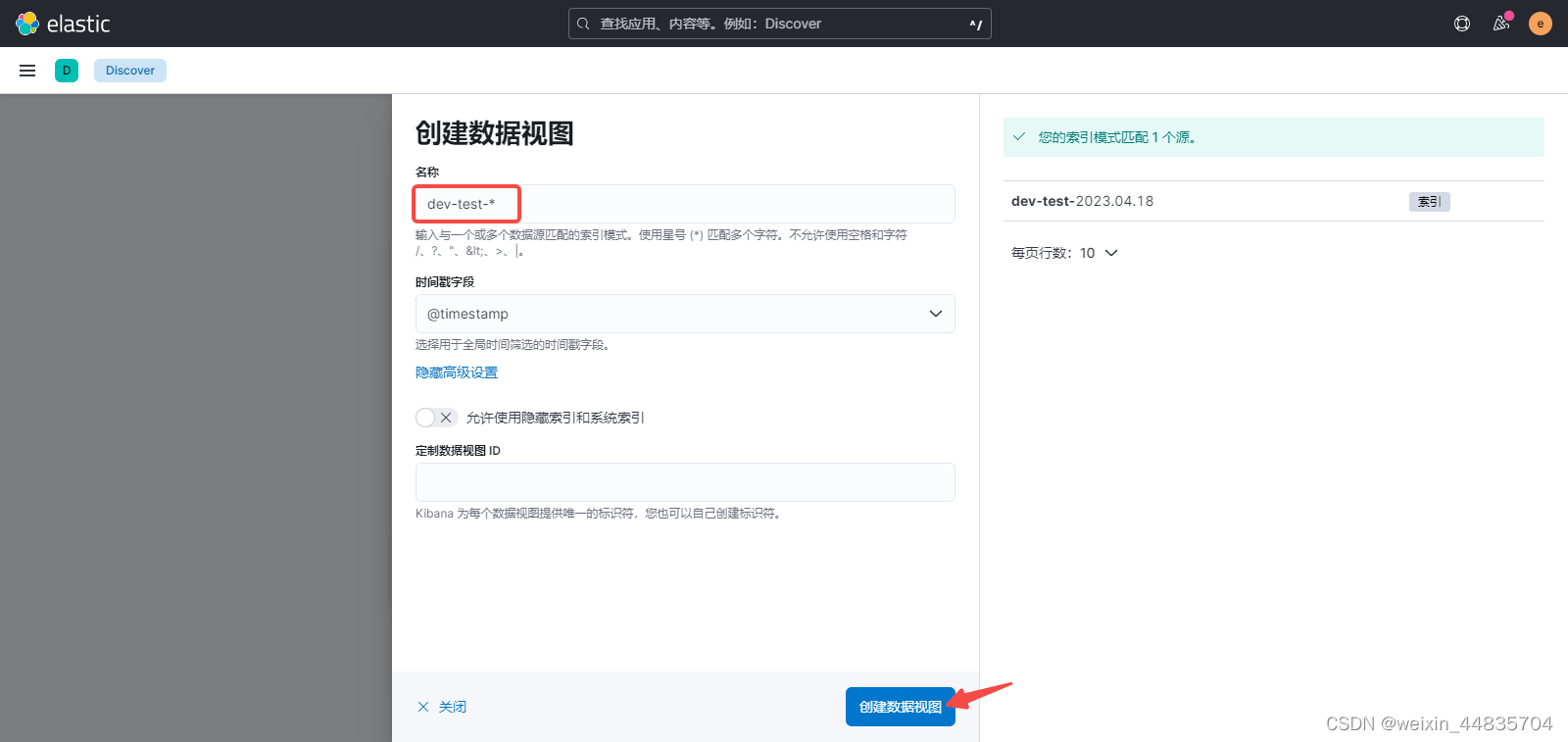
视图名称使用dev-test-*匹配所有以dev-test-开头的索引
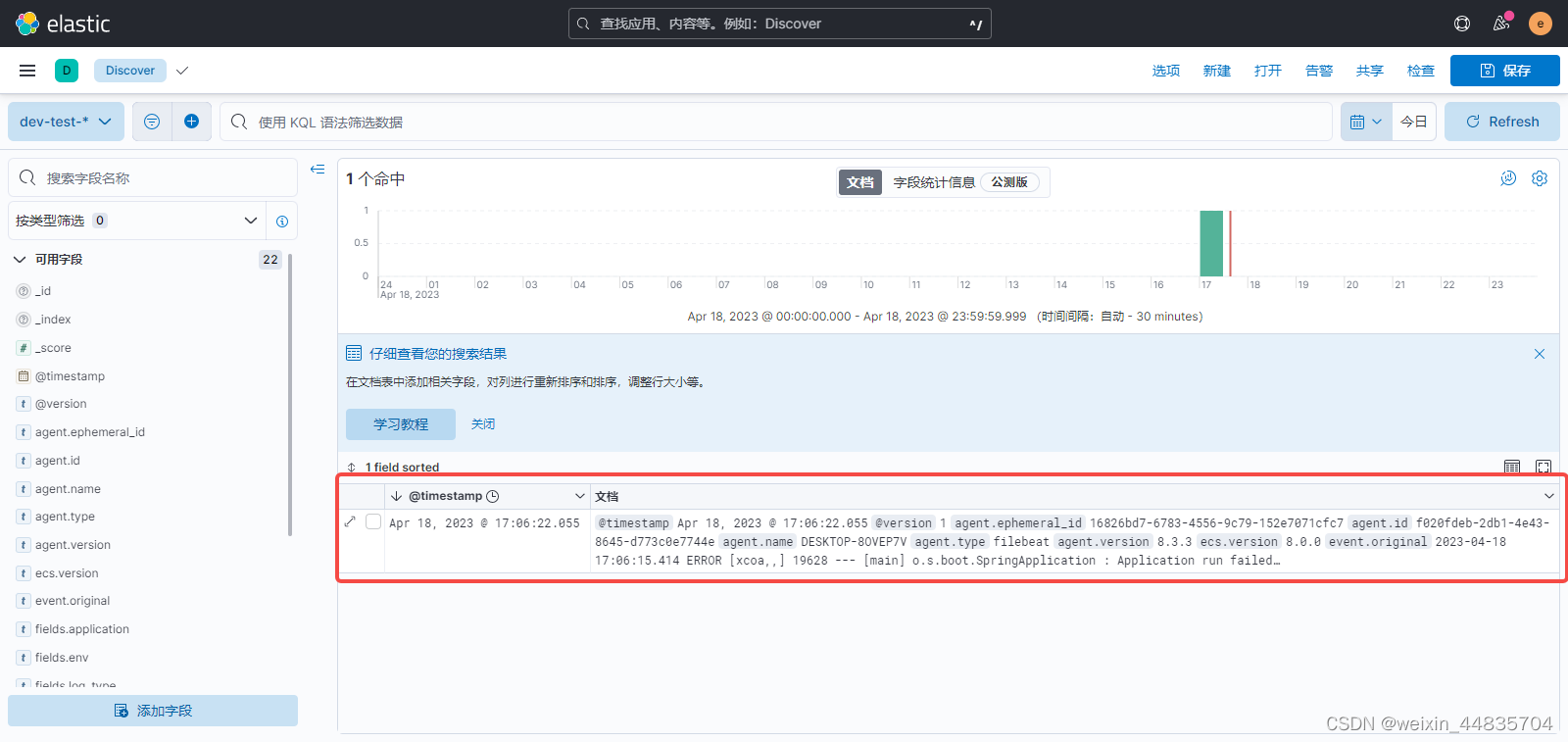
这里的文档就对应产生的一条日志
这个文档里面的字段可能除了日志本身外还有很多我们不关心的字段
可以在左侧过滤出想展示的字段
找到message字段添加
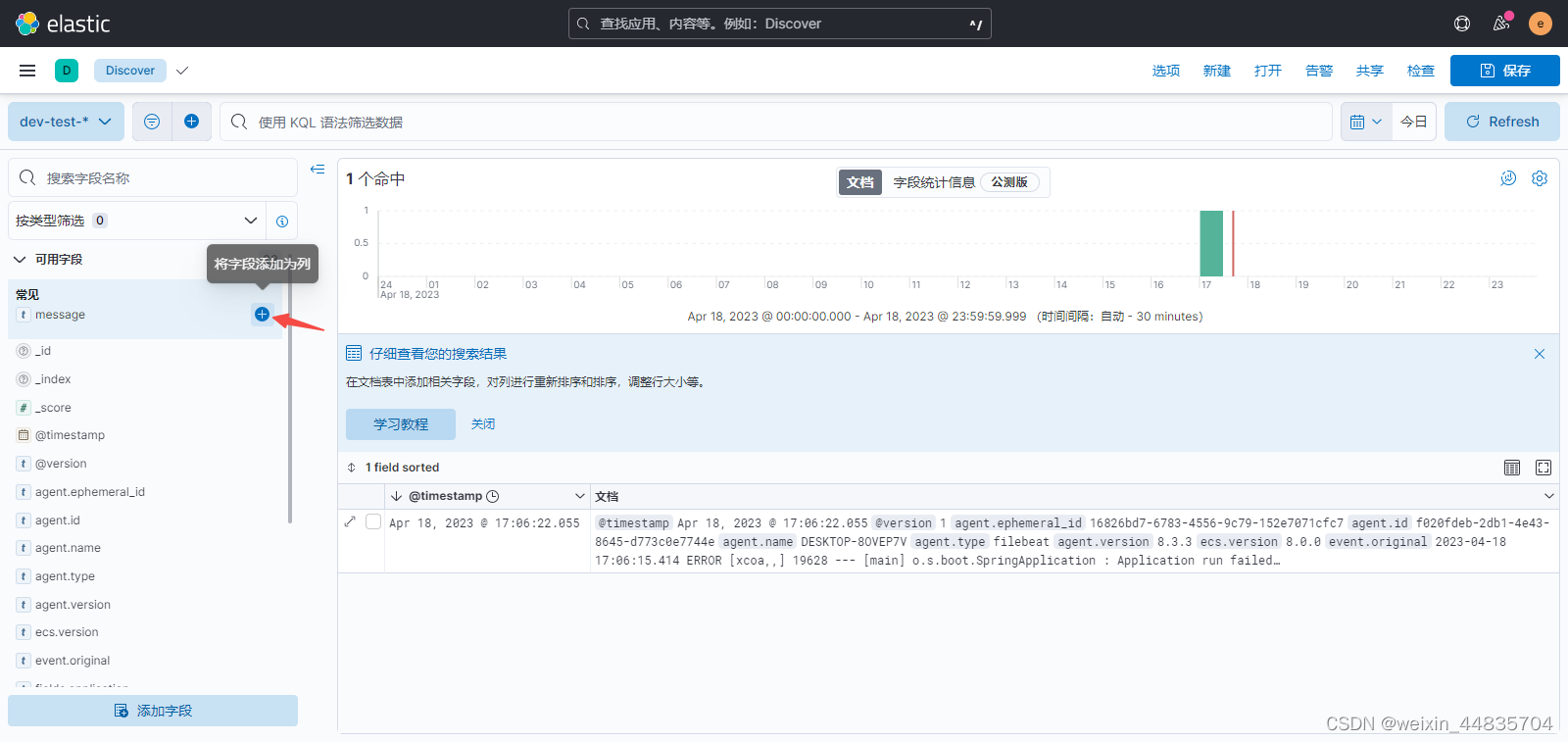
此时展示的内容即为产生的日志
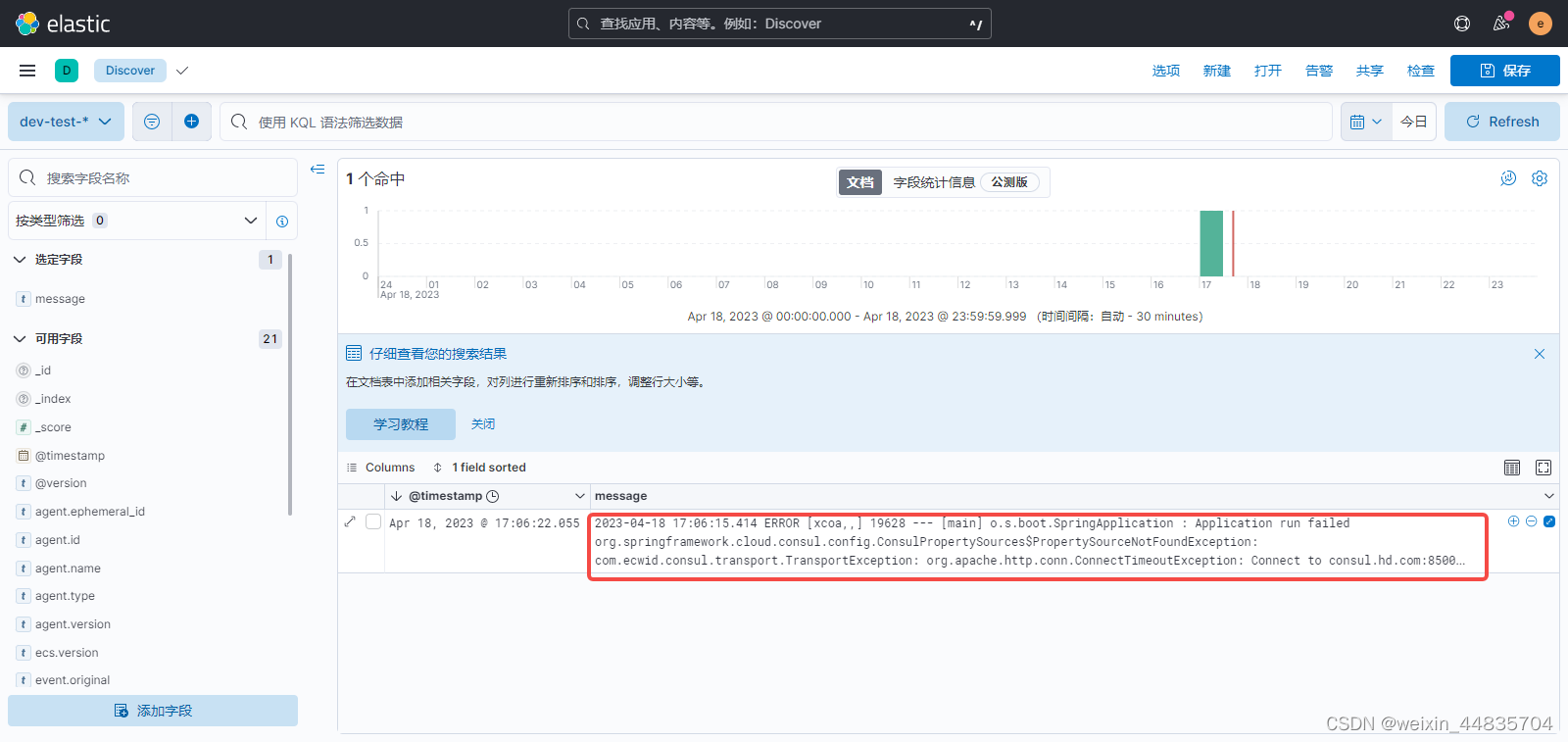
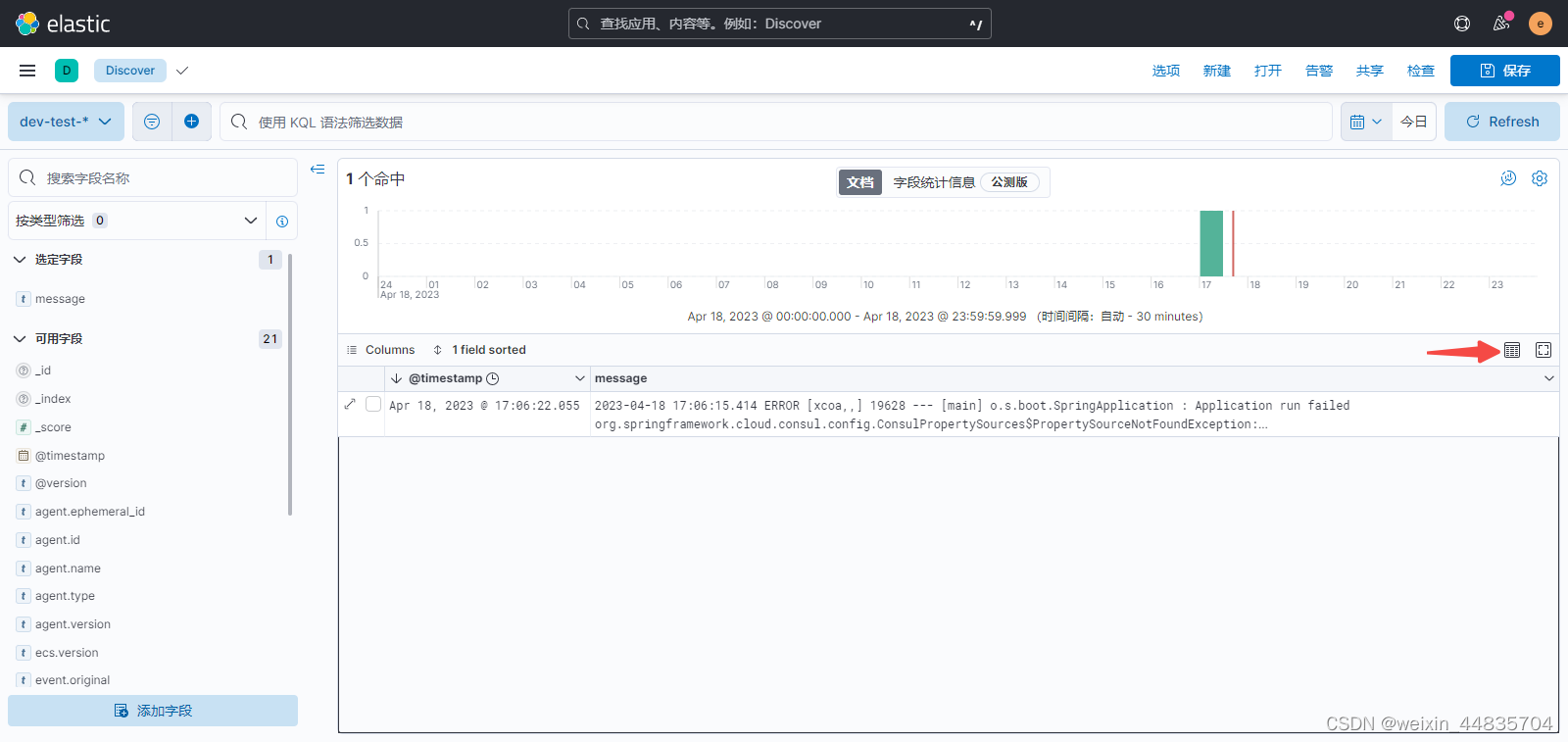
产生的日志是一条错误日志,内容比较多;这里并没有全部展示出来而是折叠了;设置日志行宽度自适应
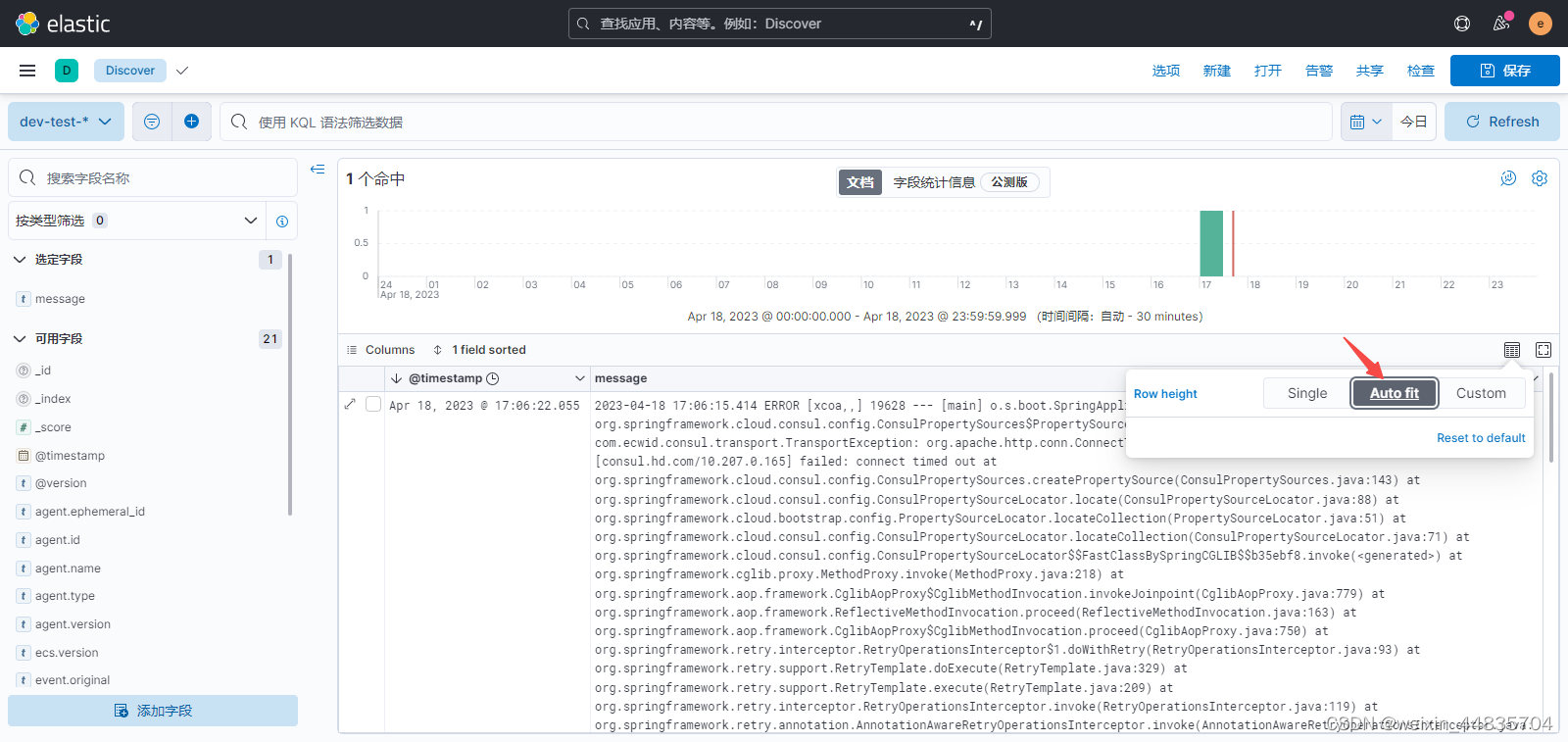

7.logstash.conf输出配置中添加action配置
如果配置action => “create”;则会生成数据流,数据流下面的后备索引才是真正的索引,类似索引的别名;设置数据流主要是方便设置索引的生命周期,日志会不断地产生,但是磁盘确实有限的资源,所以需要给索引设置生命周期,自动删除那些老旧的日志,为新的日志腾出空间;如何设置索引生命周期后面再说
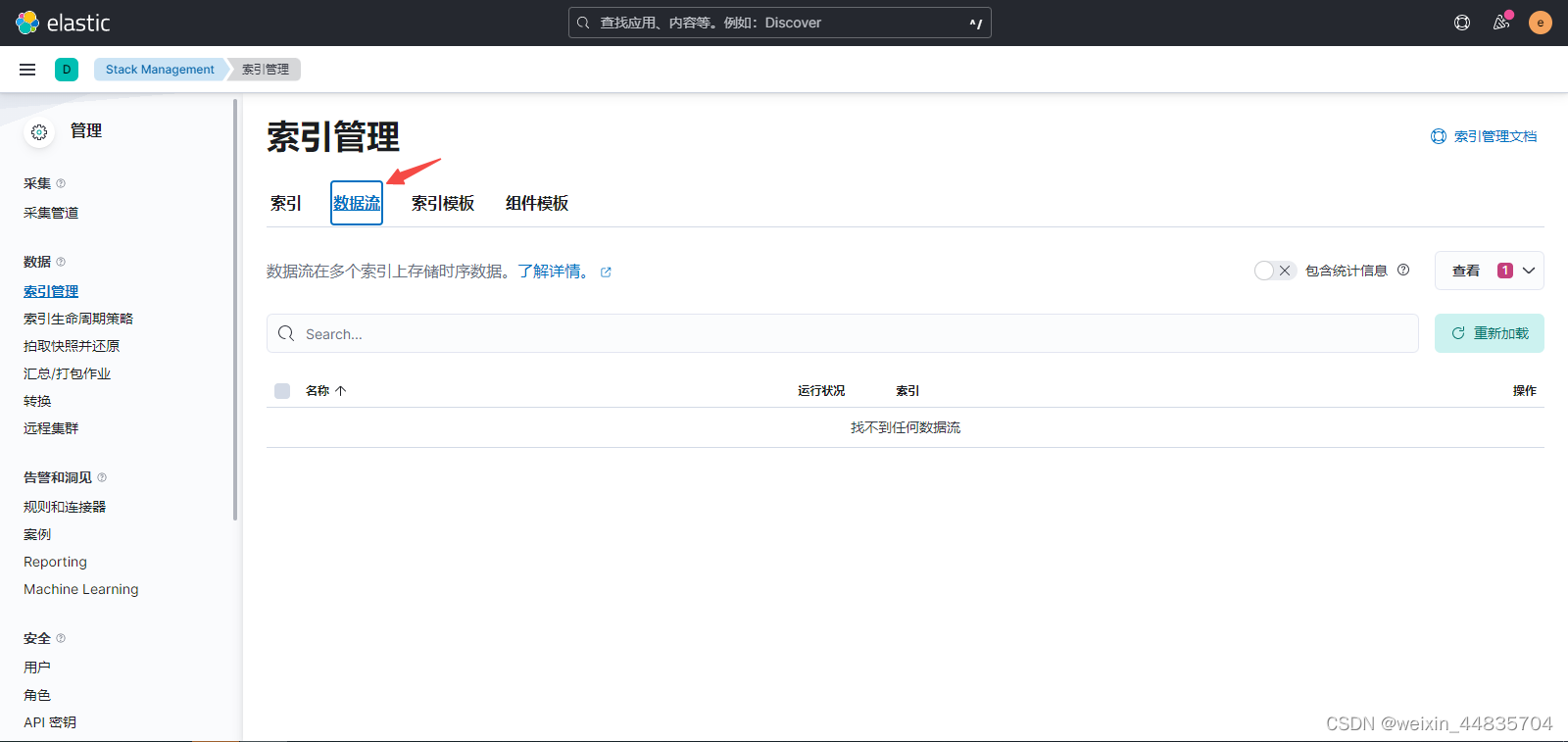
数据流命名格式一般为“logs-应用名-环境“
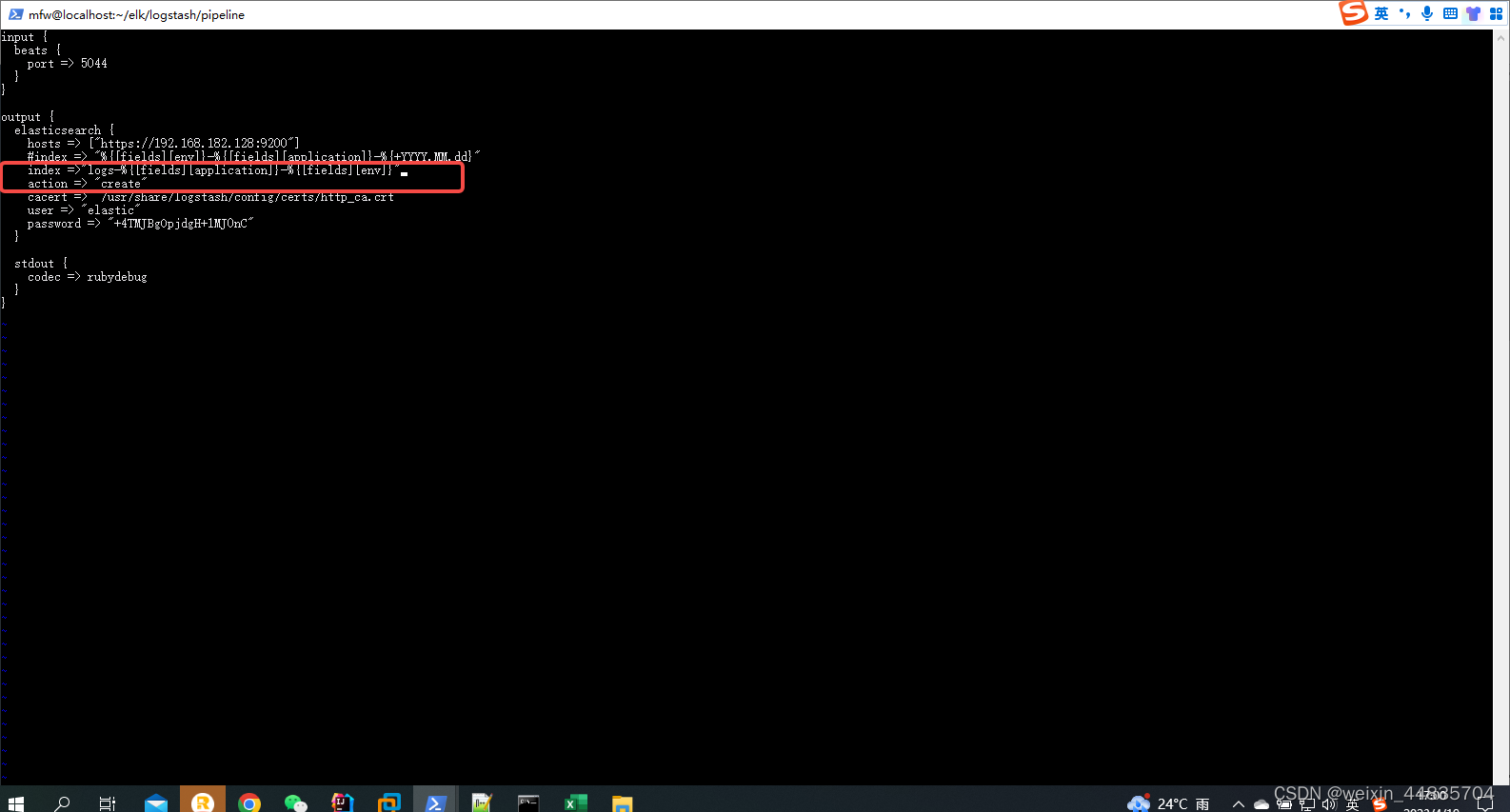
修改配置文件
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["https://192.168.182.128:9200"]
#index => "%{[fields][env]}-%{[fields][application]}-%{+YYYY.MM.dd}"
index =>"logs-%{[fields][application]}-%{[fields][env]}"
action => "create"
cacert => "/usr/share/logstash/config/certs/http_ca.crt"
user => "elastic"
password => "+4TMJBgOpjdgH+1MJ0nC"
}
stdout {
codec => rubydebug
}
}
8.重启logstash,生成新的日志,查看logstash日志
docker restart logstash
docker logs -f logstash
程序日志输出
logstash日志
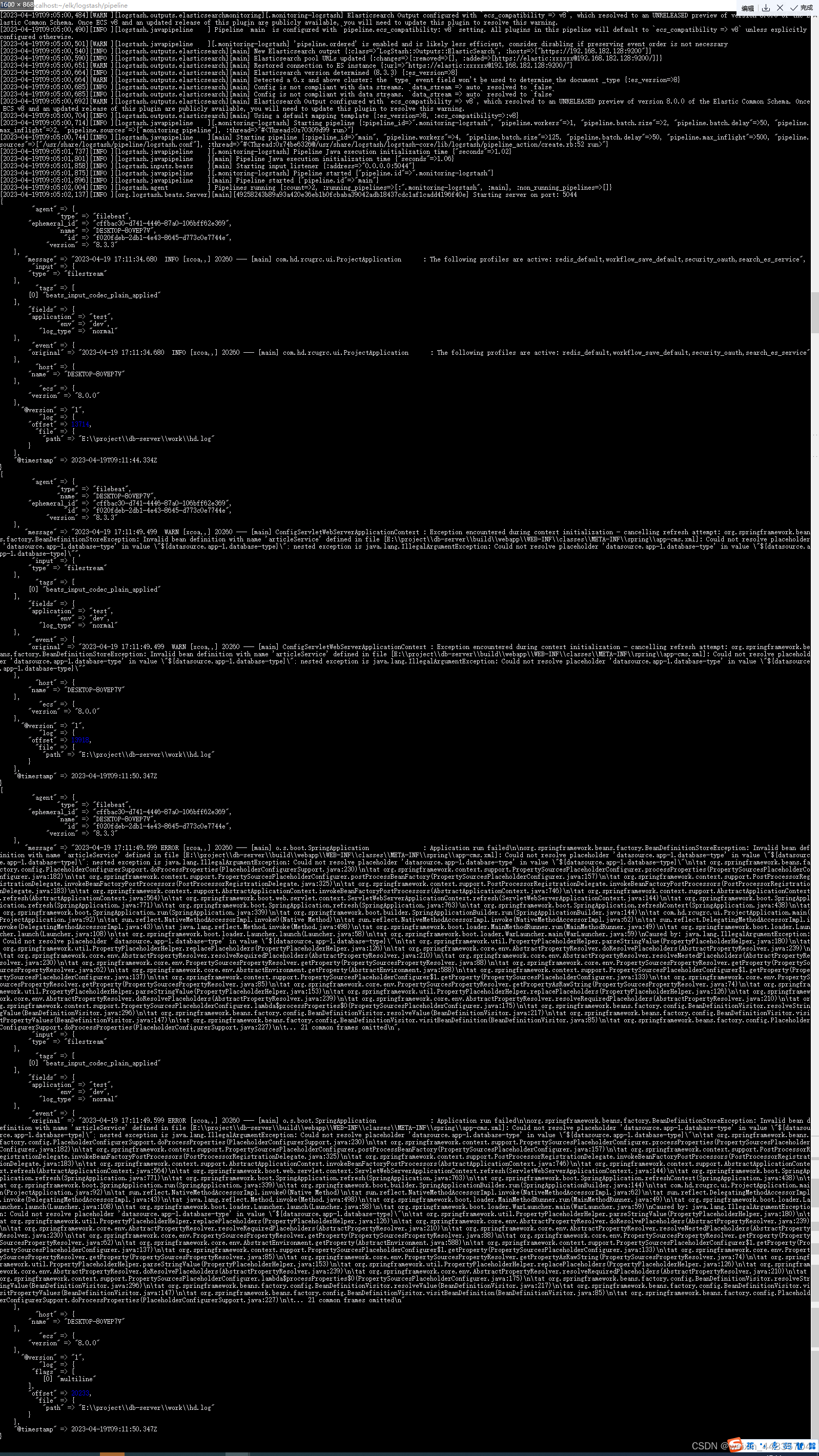
elasticsearch中出现数据流
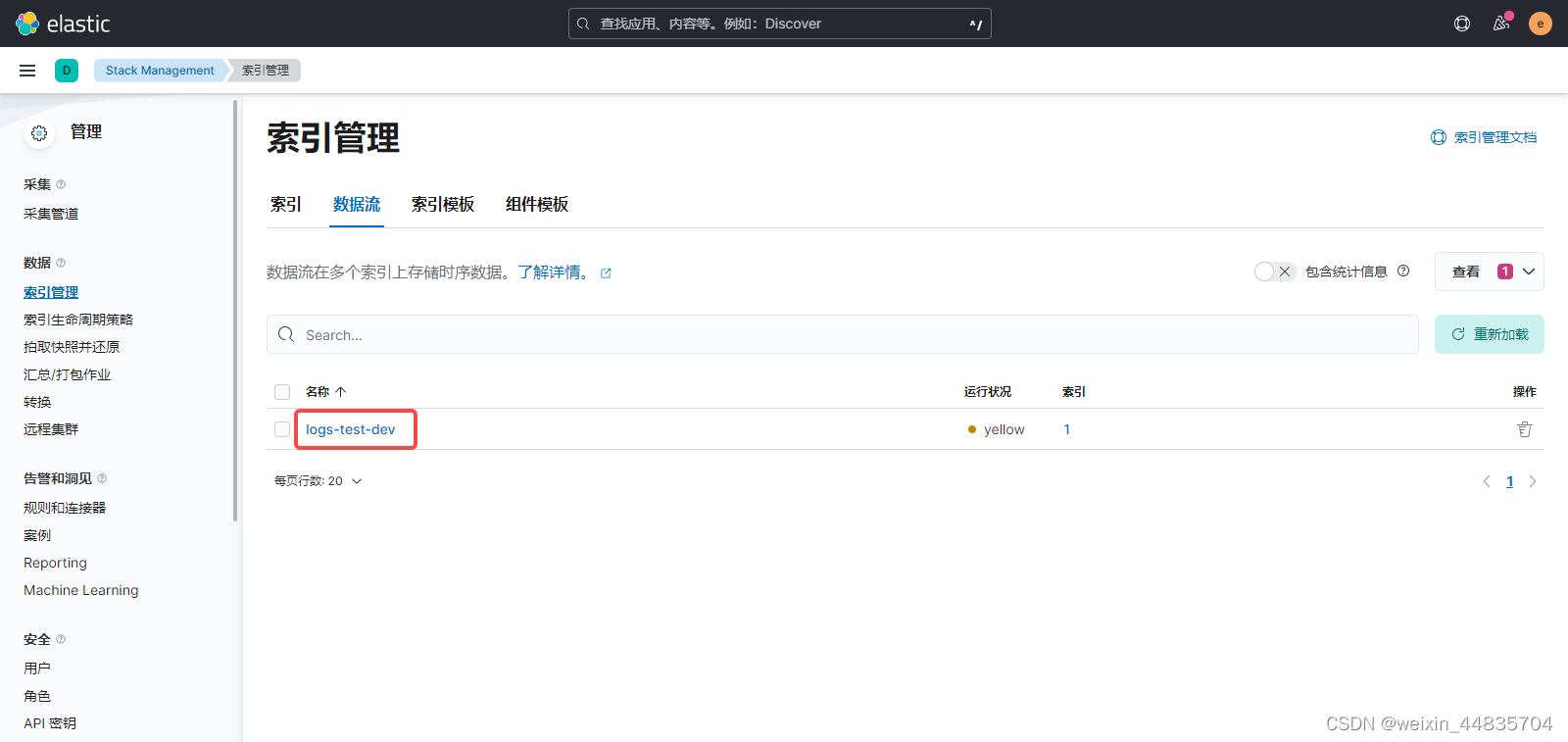
9.按照前面的方法创建数据视图
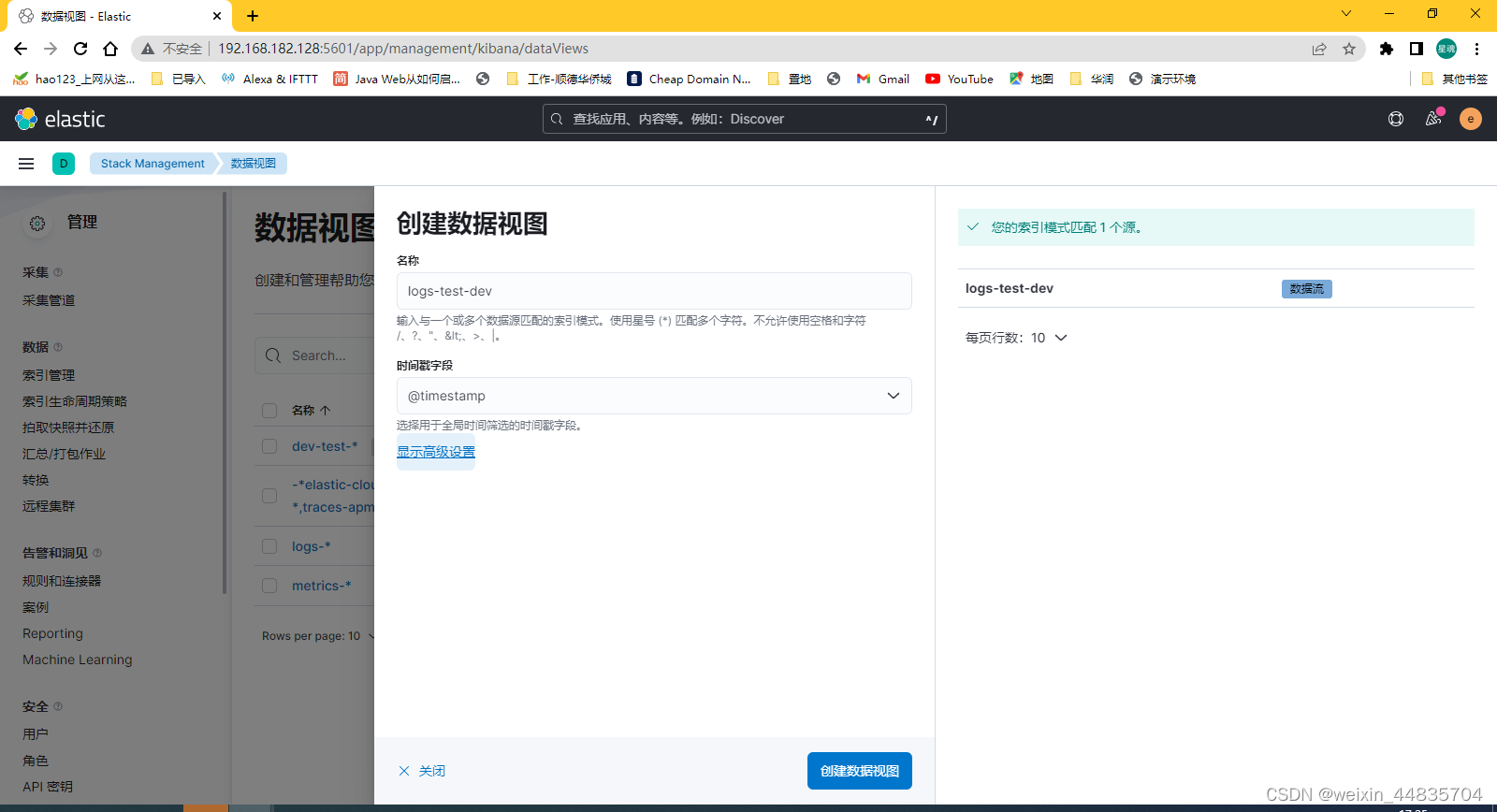
通过Discover查看视图
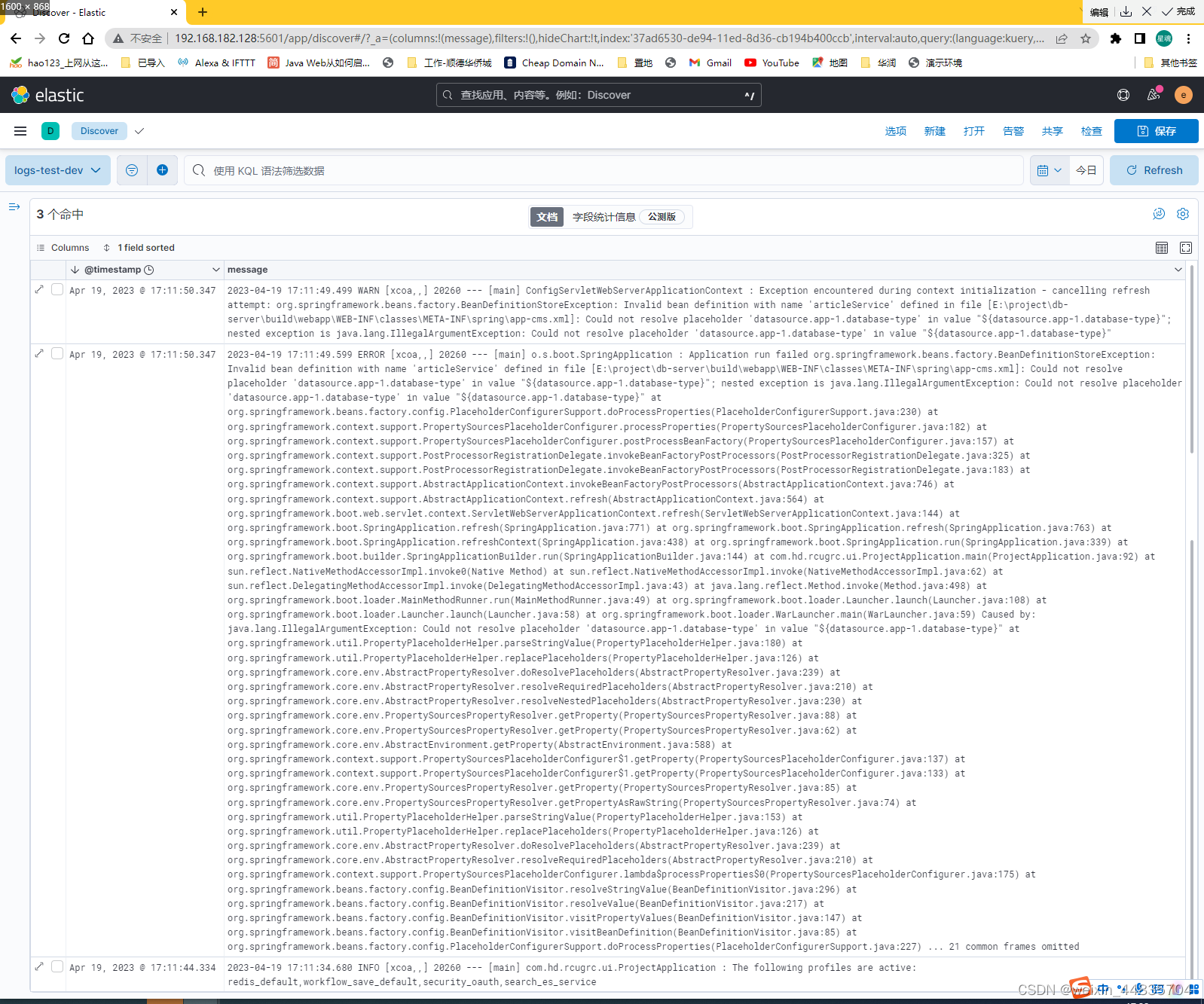
从产生的三条日志来看,发现一个问题:这里默认排序是按@timestamp字段倒序排列的;但是按日志产生的顺序来看最上面两条是正序排列的,而最上面两条日志和第三条日志之间又是倒序排列的
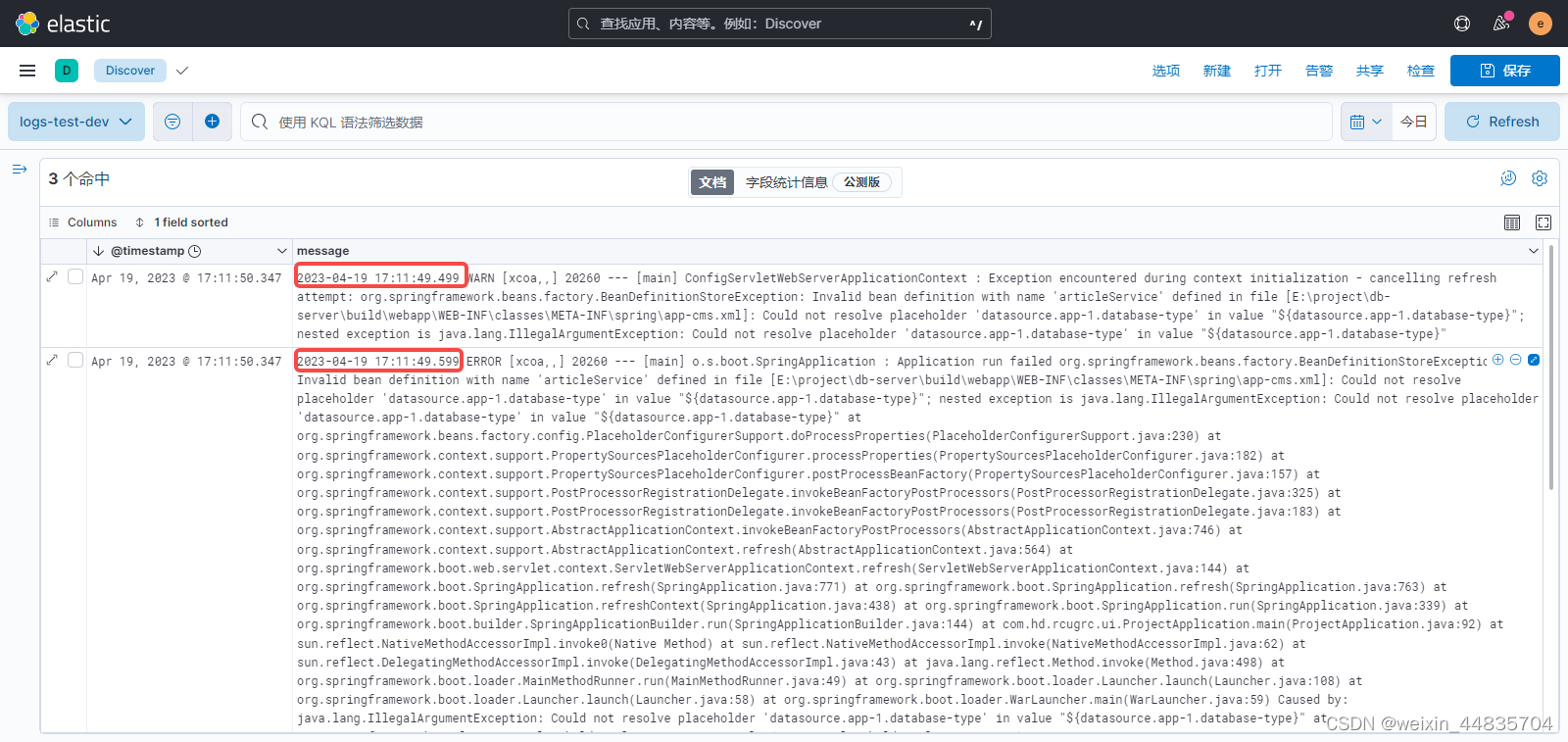
这样日志看起来可能就比较混乱;造成这个现象的原因是:@timestamp字段是filebeat收集日志的时间,但是filebeat收集日志并不是应用产生一条日志就收集一条,而是一批一批收集的,也就是最上面两条日志是同一批次收集的,es并不能区分同一批里面日志的先后顺序;而日志里面的时间才是日志真实产生的时间,@timestamp只是收集日志的时间;
所以要解决的问题就是从日志将日志真实产生时间提取出来,并设置到@timestamp字段中,要从日志中提取时间就需要给将日志进行拆分
10.日志字段拆分
java日志一般有固定格式;我们可以根据格式将每一条日志拆分成固定数量的字段,就像关系型数据库一样
如下面的日志:
2023-04-21 17:09:36.394 ERROR [xcoa,,] 23072 --- [ main] com.zaxxer.hikari.pool.HikariPool : HikariPool-2 - Exception during pool initialization.
2023-04-21 17:09:36.394 =>日志产生时间
ERROR =>日志级别
[xcoa,] =>上下文等信息
23072 => 进程id
[ main] => 线程名
com.zaxxer.hikari.pool.HikariPool =>类名
HikariPool-2 - Exception during pool initialization. =>日志内容
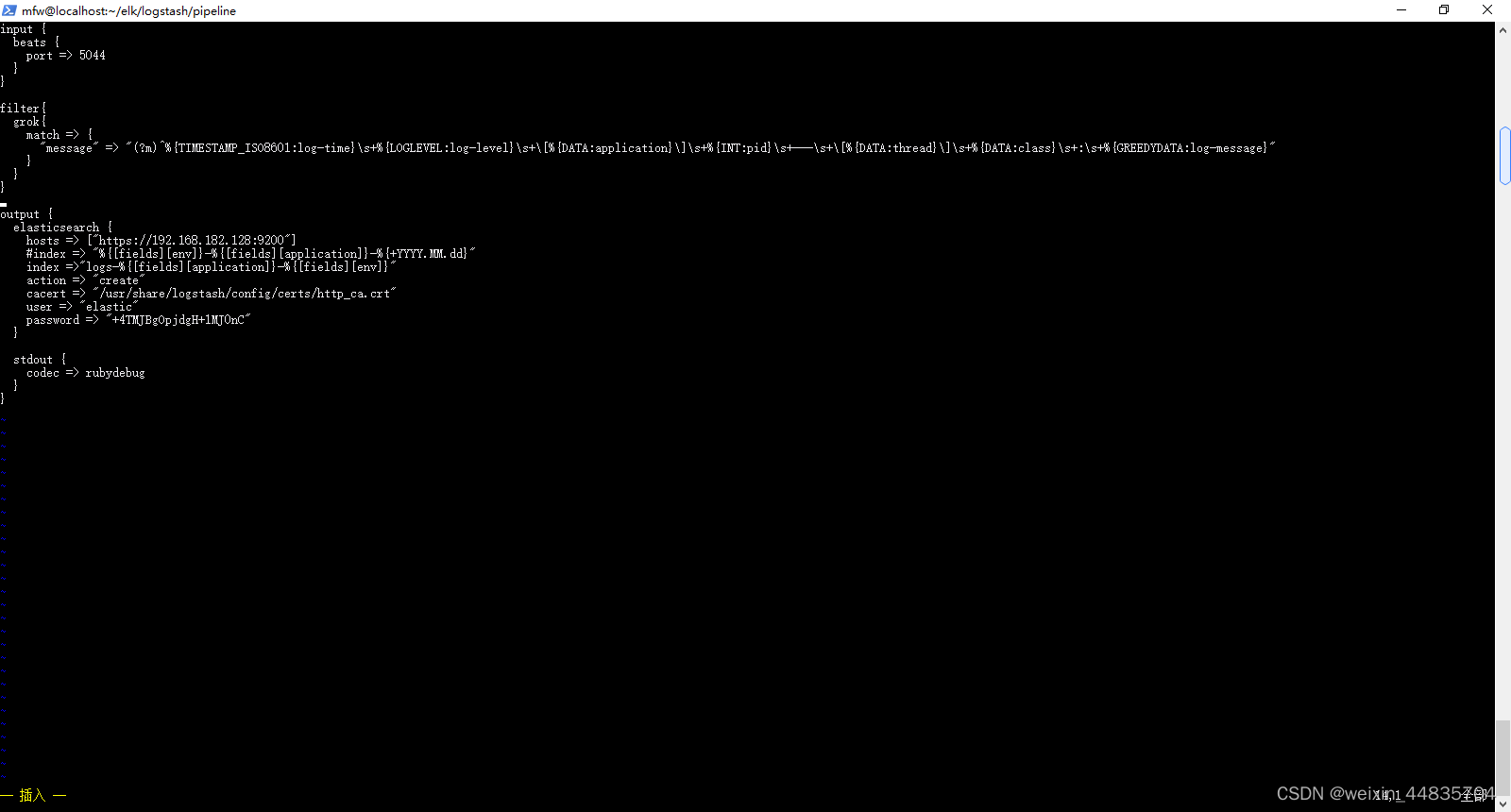
针对这个日志,在logstash中可以根据下面的grok表达式进行匹配:
(?m)^%{TIMESTAMP_ISO8601:log-time}\s+%{LOGLEVEL:log-level}\s+\[%{DATA:application}\]\s+%{INT:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:log-message}
拆分出的各个字段如下:
log-time:日志产生时间
log-level:日志级别
application :上下文等信息
pid:进程id
thread:线程名
class:类名
log-message.:日志内容
对应在logstash配置
input {
beats {
port => 5044
}
}
filter{
grok{
match => {
"message" => "(?m)^%{TIMESTAMP_ISO8601:log-time}\s+%{LOGLEVEL:log-level}\s+\[%{DATA:application}\]\s+%{INT:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:log-message}"
}
}
}
output {
elasticsearch {
hosts => ["https://192.168.182.128:9200"]
#index => "%{[fields][env]}-%{[fields][application]}-%{+YYYY.MM.dd}"
index =>"logs-%{[fields][application]}-%{[fields][env]}"
action => "create"
cacert => "/usr/share/logstash/config/certs/http_ca.crt"
user => "elastic"
password => "+4TMJBgOpjdgH+1MJ0nC"
}
stdout {
codec => rubydebug
}
}
11.日志字段拆分效果测试
重启logstash
docker restart logstash
产生日志
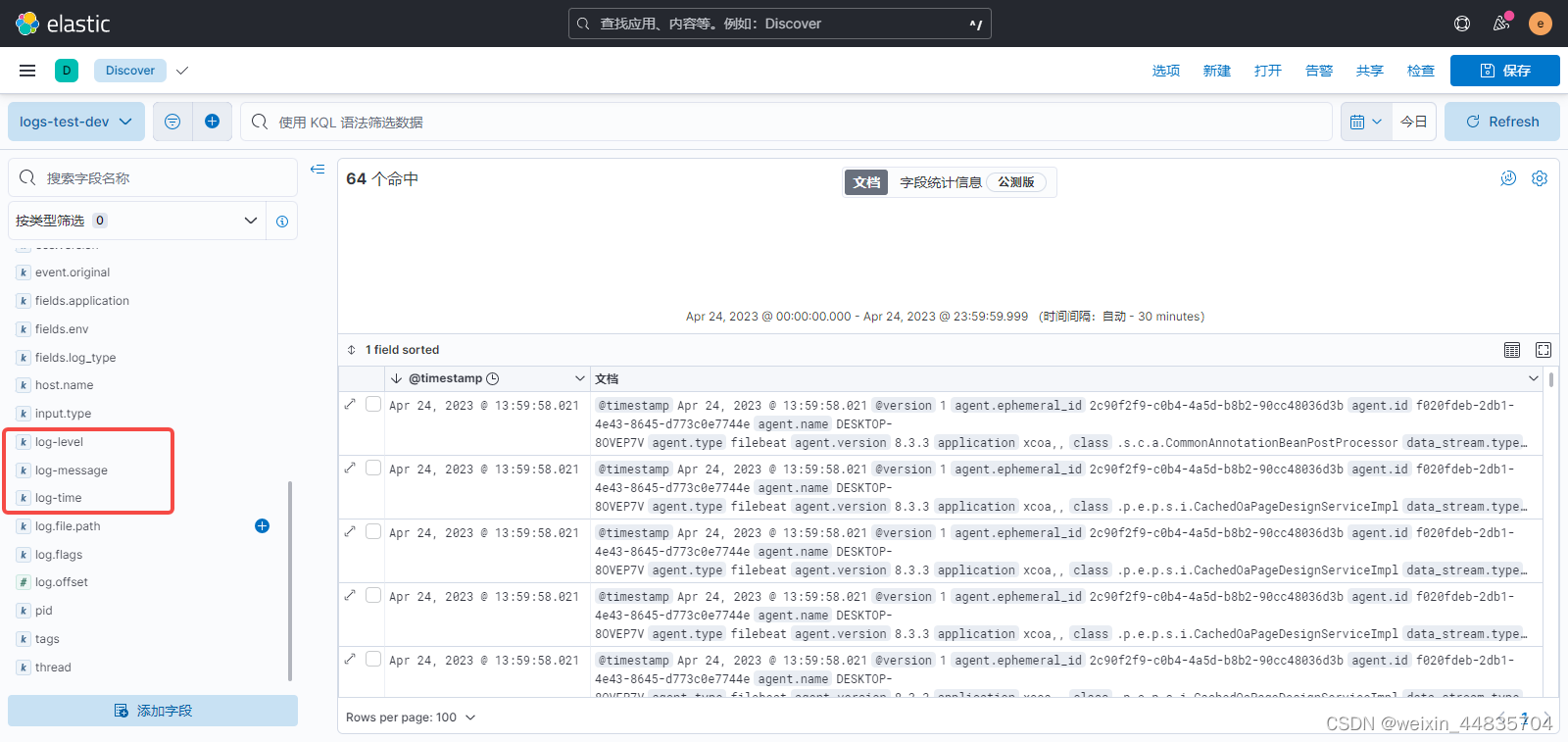
kibana中查看(已经可以在字段列表中看到拆分出来的字段,后续可以用这些字段筛选)
12.日志按产生时间排序
前面已经将日志产生时间拆分出来并放在log-time字段里面
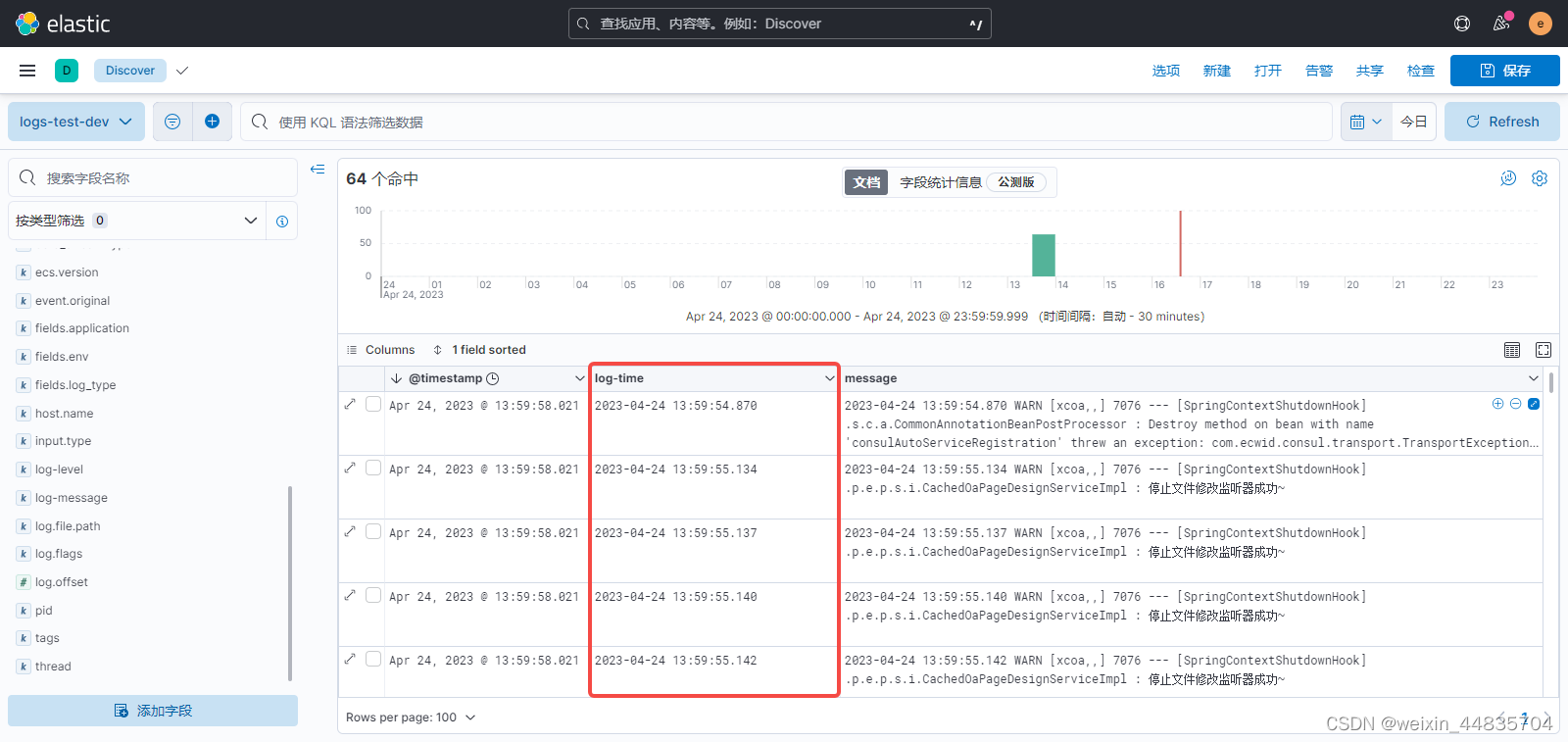
所以需要做的是,用log-time字段的内容覆盖@timestamp就可以了
logstash.conf的filter中加入配置:
date {
match => ["log-time", "yyyy-MM-dd HH:mm:ss.SSS", "ISO8601"] #原字段转换成时间类型
locale => "en"
target => [ "@timestamp" ] #目标字段
timezone => "Asia/Shanghai"
}
这里的配置就是将log-time按格式化转化为时间类型然后覆盖到@timestamp字段
如果想保留原@timestamp,可以将原@timestamp值赋值给新的字段:
下面配置将@timestamp设置给了一个新字段collection_time
ruby {
code => "event.set('collection_time', event.get('@timestamp'))"
}
完整配置为:
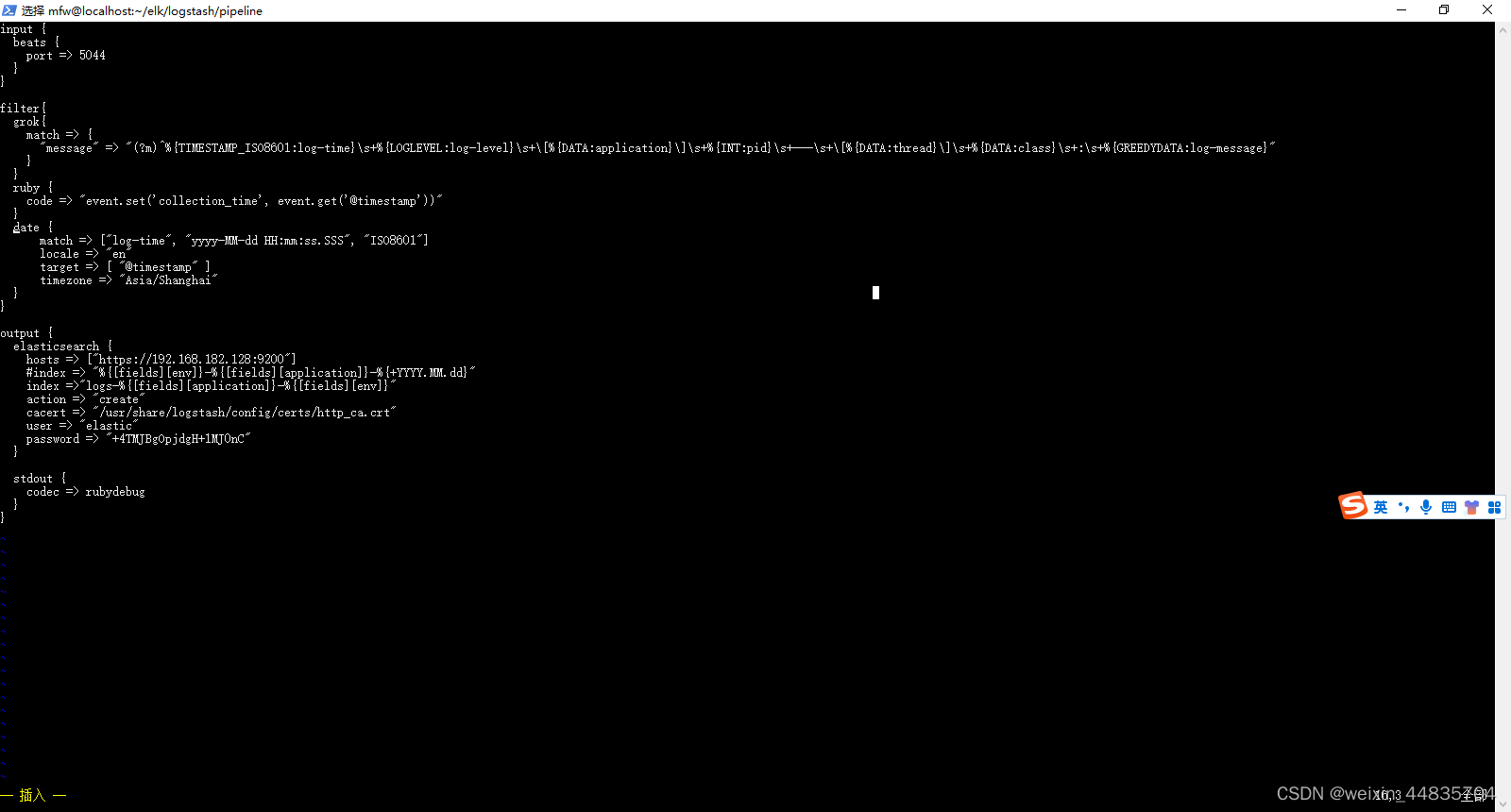
input {
beats {
port => 5044
}
}
filter{
grok{
match => {
"message" => "(?m)^%{TIMESTAMP_ISO8601:log-time}\s+%{LOGLEVEL:log-level}\s+\[%{DATA:application}\]\s+%{INT:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:log-message}"
}
}
ruby {
code => "event.set('collection_time', event.get('@timestamp'))"
}
date {
match => ["log-time", "yyyy-MM-dd HH:mm:ss.SSS", "ISO8601"]
locale => "en"
target => [ "@timestamp" ]
timezone => "Asia/Shanghai"
}
}
output {
elasticsearch {
hosts => ["https://192.168.182.128:9200"]
#index => "%{[fields][env]}-%{[fields][application]}-%{+YYYY.MM.dd}"
index =>"logs-%{[fields][application]}-%{[fields][env]}"
action => "create"
cacert => "/usr/share/logstash/config/certs/http_ca.crt"
user => "elastic"
password => "+4TMJBgOpjdgH+1MJ0nC"
}
stdout {
codec => rubydebug
}
}
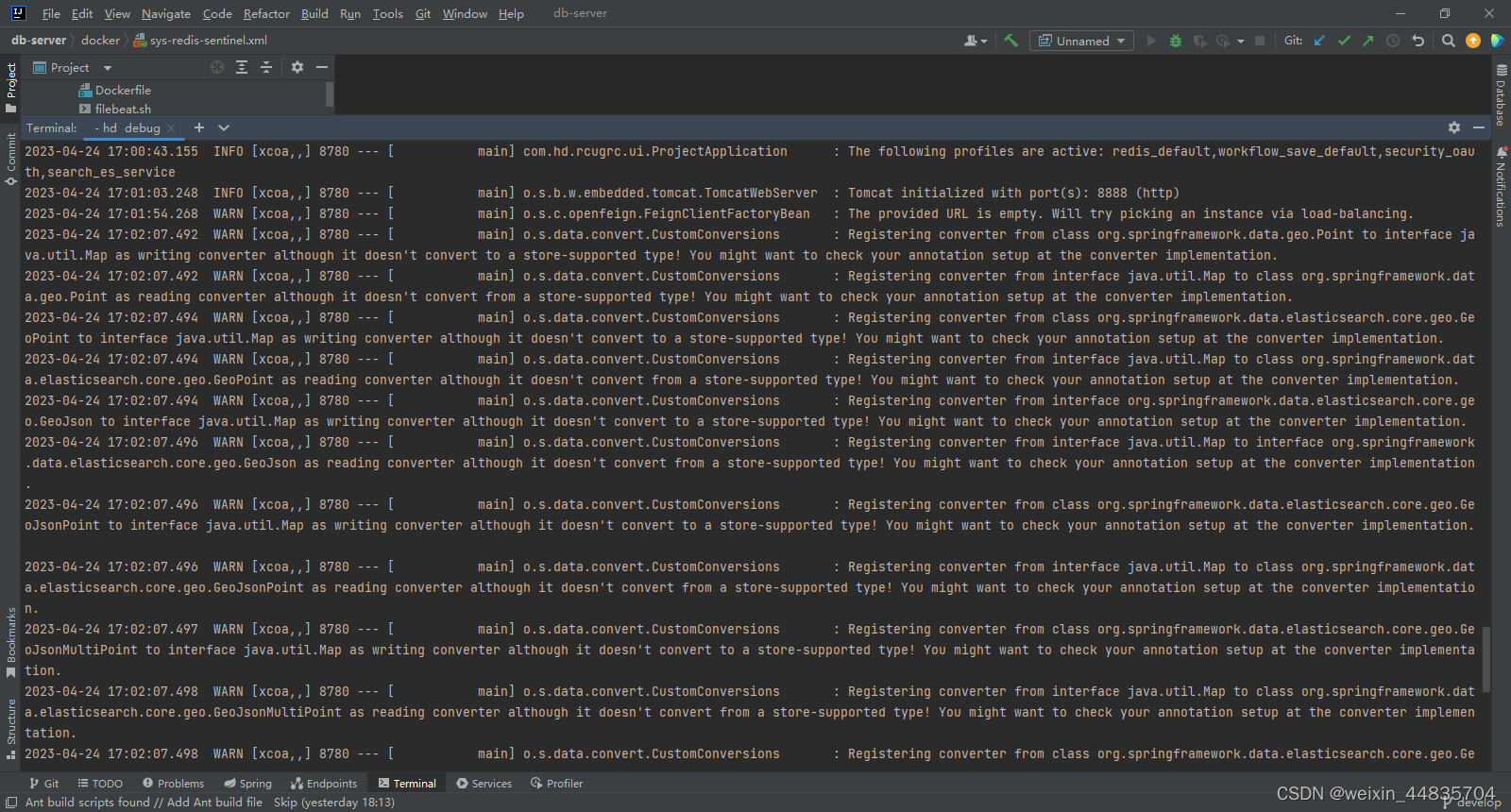
13.效果测试
重启logstash
docker restart logstash

产生日志
kibana中查看新产生的日志:
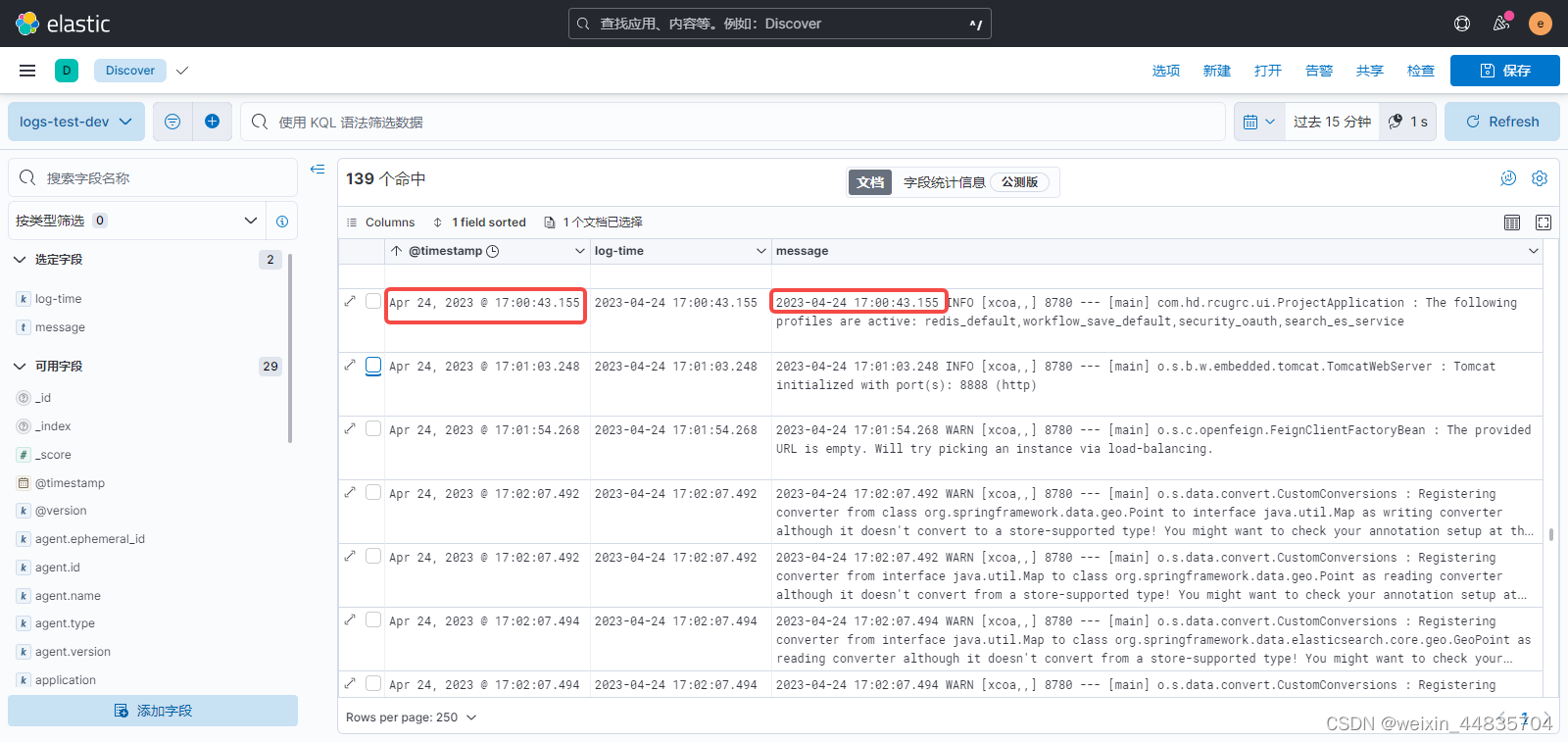
可以看到新产生的日志@timestamp值现在是一致的。使用@timestamp也不会出现日志乱序的问题














 453
453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









