






01、限流知识概述
流是一种对请求或并发数进行限制的关键技术手段,旨在保障系统的正常运行。当服务资源有限、处理能力有限时,限流可以对调用服务的上游请求进行限制,以防止自身服务因资源耗尽而停止服务。
在限流中,有两个重要的概念需要了解:
- 阈值:指在单位时间内允许的请求量。例如,将 QPS(每秒请求数)限制为500,表示在1秒内最多接受500次请求。通过设置合适的阈值,可以控制系统的负载,避免过多的请求导致系统崩溃或性能下降。
- 拒绝策略:用于处理超过阈值的请求的策略。常见的拒绝策略包括直接拒绝、排队等待等。直接拒绝会立即拒绝超过阈值的请求,而排队等待则将请求放入队列中,按照一定的规则进行处理。选择合适的拒绝策略可以平衡系统的稳定性和用户体验。
通过合理设置阈值和选择适当的拒绝策略,限流技术可以帮助系统应对突发的请求量激增、恶意用户访问或请求频率过高的情况,保障系统的稳定性和可用性。限流方案根据限流范围,可分为 单机限流和分布式限流;其中单机限流依据算法,又可分为 固定窗口、滑动窗口、漏桶和令牌桶限流等常见四种。本文将对上述限流方案进行详细介绍。
优点:
- 平滑流量:漏桶算法可以平滑突发流量,使得输出流量变得更加平稳,避免了流量的突然增大对系统的冲击。
- 简单易实现:漏桶算法的原理简单,实现起来也相对容易。
- 有效防止过载:通过控制流出的流量,漏桶算法可以有效地防止系统过载。
缺点:
- 对突发流量的处理不够灵活:虽然漏桶算法可以平滑突发流量,但是在某些情况下,我们可能希望能够快速处理突发流量。在这种情况下,漏桶算法可能就不够灵活了。
- 无法动态调整流量:漏桶算法的流出速率是固定的,无法根据系统的实际情况动态调整。
- 可能会导致流量浪费:如果输入流量小于漏桶的流出速率,那么漏桶的流出速率就会被浪费。
- 如果输入流量持续大于漏桶的流出速率,那么漏桶会一直满,新的请求会被丢弃,可能会导致服务质量下降。
02漏桶限流
算法介绍
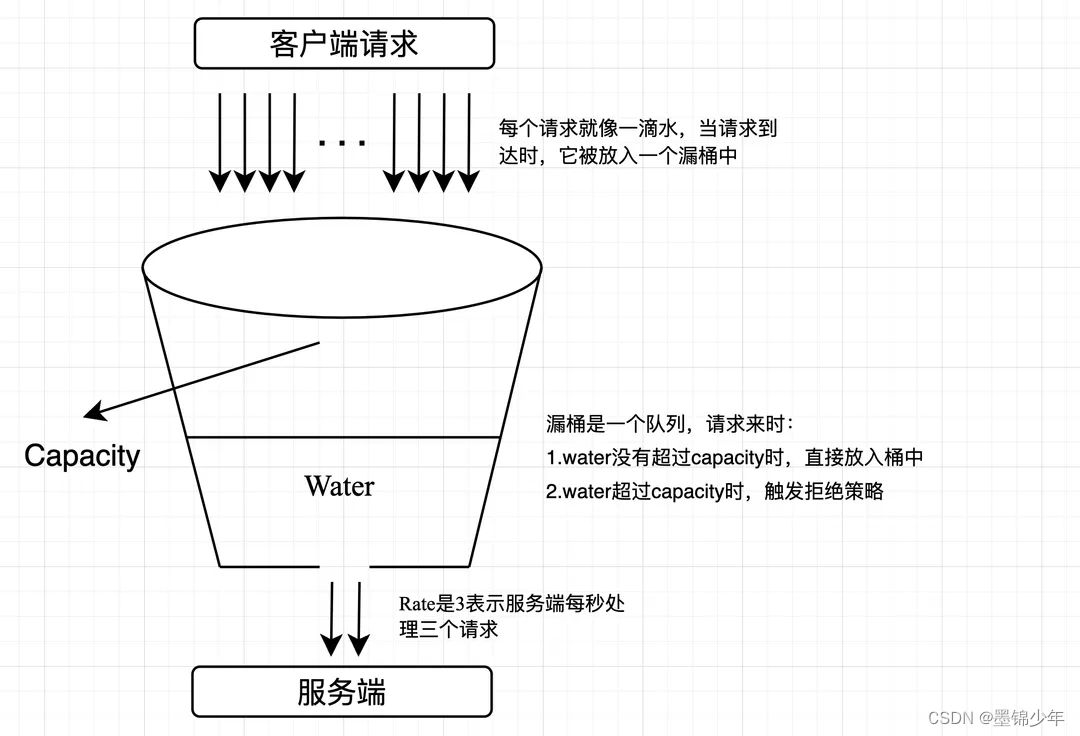
尽管滑动窗口算法可以提供一定的限流效果,但它仍然受限于窗口的大小和时间间隔。在某些情况下,突发流量可能会导致窗口内的请求数超过限制。为了更好地平滑请求的流量,漏桶限流算法可以作为滑动窗口算法的改进。算法的原理很简单:它维护一个固定容量的漏桶,请求以不定的速率流入漏桶,而漏桶以固定的速率流出。如果请求到达时,漏桶已满,则会触发拒绝策略。可以从生产者-消费者模式去理解这个算法,请求充当生产者,每个请求就像一滴水,当请求到达时,它被放入一个队列(漏桶)中。而漏桶则充当消费者,以固定的速率从队列中消费请求,就像从桶底的孔洞中不断漏出水滴。消费的速率等于限流阈值,例如每秒处理2个请求,即500毫秒消费一个请求。漏桶的容量就像队列的容量,当请求堆积超过指定容量时,会触发拒绝策略,即新到达的请求将被丢弃或延迟处理。算法的实现如下:
- 漏桶容量:确定一个固定的漏桶容量,表示漏桶可以存储的最大请求数。
- 漏桶速率:确定一个固定的漏桶速率,表示漏桶每秒可以处理的请求数。
- 请求处理:当请求到达时,生产者将请求放入漏桶中。
- 漏桶流出:漏桶以固定的速率从漏桶中消费请求,并处理这些请求。如果漏桶中有请求,则处理一个请求;如果漏桶为空,则不处理请求。
- 请求丢弃或延迟:如果漏桶已满,即漏桶中的请求数达到了容量上限,新到达的请求将被丢弃或延迟处理。
03 令牌桶限流
算法介绍
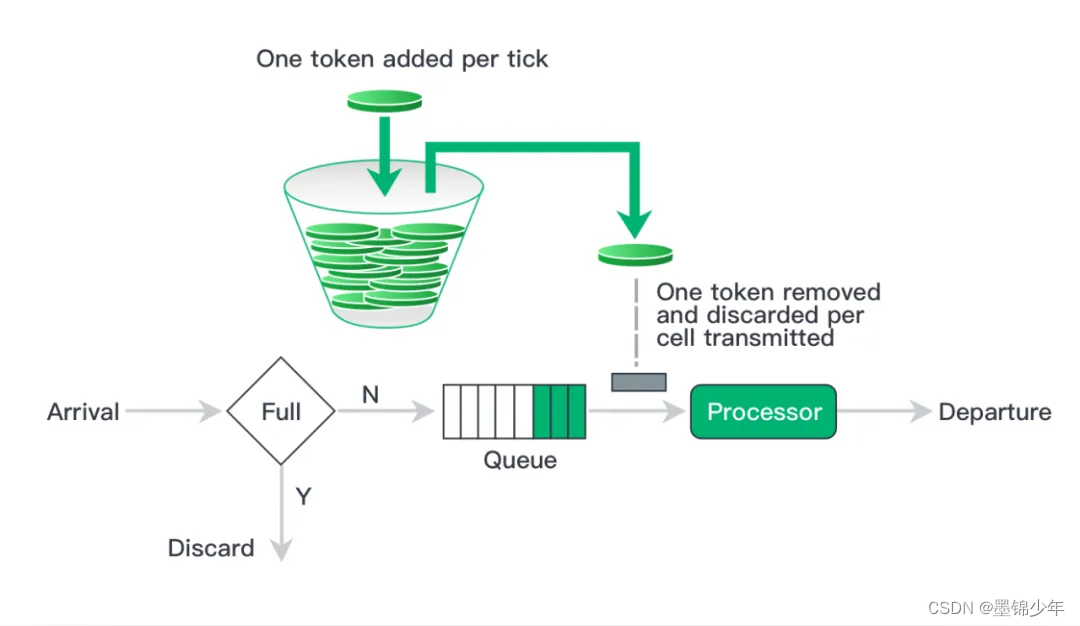
令牌桶算法是实现限流的一种常见思路,用于限制请求的速率。它可以确保系统在高负载情况下仍能提供稳定的服务,并防止突发流量对系统造成过载。最常用的 Google Java 开发工具包 Guava 中的限流工具类 RateLimiter 就是令牌桶的一个实现。令牌桶算法基于一个令牌桶的概念,其中令牌以固定的速率产生,并放入桶中。每个令牌代表一个请求的许可。当请求到达时,需要从令牌桶中获取一个令牌才能通过。如果令牌桶中没有足够的令牌,则请求被限制或丢弃。令牌桶算法的实现步骤如下:
- 初始化一个令牌桶,包括桶的容量和令牌产生的速率。
- 持续以固定速率产生令牌,并放入令牌桶中,直到桶满为止。
- 当请求到达时,尝试从令牌桶中获取一个令牌。
- 如果令牌桶中有足够的令牌,则请求通过,并从令牌桶中移除一个令牌。
- 如果令牌桶中没有足够的令牌,则请求被限制或丢弃。
.4.3 优缺点
优点:
- 平滑流量:令牌桶算法可以平滑突发流量,使得突发流量在一段时间内均匀地分布,避免了流量的突然高峰对系统的冲击。
- 灵活性:令牌桶算法可以通过调整令牌生成速率和桶的大小来灵活地控制流量。
- 允许突发流量:由于令牌桶可以积累一定数量的令牌,因此在流量突然增大时,如果桶中有足够的令牌,可以应对这种突发流量。
缺点:
- 实现复杂:相比于其他一些限流算法(如漏桶算法),令牌桶算法的实现稍微复杂一些,需要维护令牌的生成和消耗。
- 需要精确的时间控制:令牌桶算法需要根据时间来生成令牌,因此需要有精确的时间控制。如果系统的时间控制不精确,可能会影响限流的效果。
- 可能会有资源浪费:如果系统的流量持续低于令牌生成的速率,那么桶中的令牌可能会一直积累,造成资源的浪费。
04分布式限流
单机限流指针对单一服务器的情况,通过限制单台服务器在单位时间内处理的请求数量,防止服务器过载。常见的限流算法上文已介绍,其优点在于实现简单,效率高,效果明显。随着微服务架构的普及,系统的服务通常会部署在多台服务器上,此时就需要分布式限流来保证整个系统的稳定性。接下本文会介绍几种常见的分布式限流技术方案:
4.1 基于中心化的限流方案
通过一个中心化的限流器来控制所有服务器的请求。实现方式:选择一个中心化的组件,例如— Redis。定义限流规则,例如:可以设置每秒钟允许的最大请求数(QPS),并将这个值存储在 Redis 中。对于每个请求,服务器需要先向 Redis 请求令牌。如果获取到令牌,说明请求可以被处理;如果没有获取到令牌,说明请求被限流,可以返回一个错误信息或者稍后重试。
方案实现: 自定义注解
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface MyRedisLimiter {
/**
* 缓存到Redis的key
*/
String key();
/**
* Key的前缀
*/
String prefix() default "limiter:";
/**
* 给定的时间范围 单位(秒)
* 默认1秒 即1秒内超过count次的请求将会被限流
*/
int period() default 1;
/**
* 一定时间内最多访问的次数
*/
int count();
/**
* 限流的维度(用户自定义key 或者 调用方ip)
*/
LimitType limitType() default LimitType.CUSTOMER;
}
String key = getKey(limitAnnotation, limitType);
ImmutableList<String> keys = ImmutableList.of(StringUtils.join(limitAnnotation.prefix(), key));
try {
Number count = limitRedisTemplate.execute(redisScript, keys, limitCount, limitPeriod);
logger.info("try to access, this time count is {} for key: {}", count, key);
if (count != null && count.intValue() <= limitCount) {
return pjp.proceed();
} else {
demote();//降级
return null;
}
} catch (Throwable e) {
if (e instanceof RuntimeException) {
throw new RuntimeException(e.getLocalizedMessage());
}
throw new RuntimeException("服务器出现异常,请稍后再试");
}
加载Lua脚本在切面类中,我们可以通过初始化加载Lua脚本,如下new
加载Lua脚本
在切面类中,我们可以通过初始化加载Lua脚本,如下new ClassPathResource(LIMIT_LUA_PATH)
java复制代码private static final String LIMIT_LUA_PATH = "limit.lua";
private DefaultRedisScript<Number> redisScript;
@PostConstruct
public void init() {
redisScript = new DefaultRedisScript<>();
redisScript.setResultType(Number.class);
ClassPathResource classPathResource = new ClassPathResource(LIMIT_LUA_PATH);
try {
classPathResource.getInputStream();//探测资源是否存在
redisScript.setScriptSource(new ResourceScriptSource(classPathResource));
} catch (IOException e) {
logger.error("未找到文件:{}", LIMIT_LUA_PATH);
}
}
lua脚本代码
local count
count = redis.call('get',KEYS[1])
--不超过最大值,则直接返回
if count and tonumber(count) > tonumber(ARGV[1]) then
return count;
end
--执行计算器自加
count = redis.call('incr',KEYS[1])
if tonumber(count) == 1 then
--从第一次调用开始限流,设置对应key的过期时间
redis.call('expire',KEYS[1],ARGV[2])
end
return count
-
2存在的问题:性能瓶颈:由于所有的请求都需要经过 Redis,因此 Redis 可能成为整个系统的性能瓶颈。为了解决这个问题,可以考虑使用 Redis 集群来提高性能,或者使用更高性能的硬件。单点故障:如果 Redis 出现故障,整个系统的限流功能将受到影响。为了解决这个问题,可以考虑使用 Redis 的主从复制或者哨兵模式来实现高可用。网络带宽:Redis 是一个基于网络通信的内存数据库,因此网络带宽是其性能的一个关键因素。如果网络带宽有限,可能会导致请求的传输速度变慢,从而影响 Redis 的性能。
-
05zookeeper实现
-
用 ZooKeeper 或者 etcd 等分布式协调服务来实现限流。每台服务器都会向分布式协调服务申请令牌,只有获取到令牌的请求才能被处理。基本方案:初始化令牌桶:在 ZooKeeper 中创建一个节点,节点的数据代表令牌的数量。初始时,将数据设置为令牌桶的容量申请令牌:当一个请求到达时,服务器首先向 ZooKeeper 申请一个令牌。这可以通过获取节点的分布式锁,然后将节点的数据减1实现。如果操作成功,说明申请到了令牌,请求可以被处理;如果操作失败,说明令牌已经用完,请求需要被拒绝或者等待释放令牌:当一个请求处理完毕时,服务器需要向 ZooKeeper 释放一个令牌。这可以通过获取节点的分布式锁,然后将节点的数据加1实现补充令牌:可以设置一个定时任务,定期向 ZooKeeper 中的令牌桶补充令牌。补充的频率和数量可以根据系统的负载情况动态调整。
-
zookeeper实现分布式锁:
-
(二)Zookeeper锁的原理
锁分为两种:共享锁(读锁)和排他锁(写锁)
读锁:当有一个线程获取读锁后,其他线程也可以获取读锁,但是在读锁没有完全被释放之前,其他线程不能获取写锁。
写锁:当有一个线程获取写锁后,其他线程就无法获取读锁和写锁了。zookeeper有一种节点类型叫做临时序号节点,它会按序号自增地创建临时节点,这正好可以作为分布式锁的实现工具。
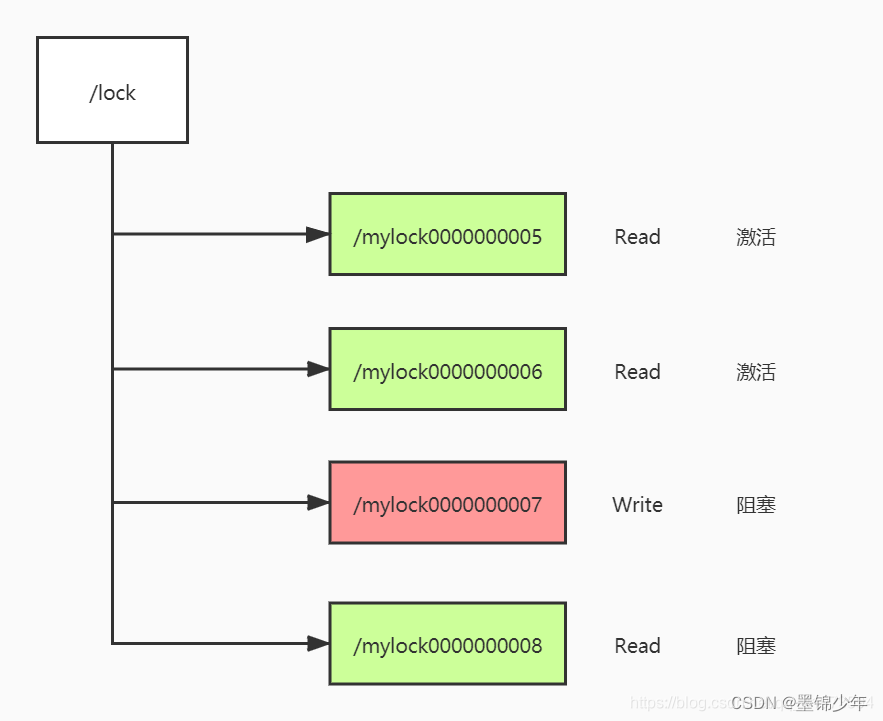
读锁获取原理:
根据资源的id创建临时序号节点:/lock/mylockR0000000005 Read
获取/lock下的所有子节点,判断比他小的节点是否全是读锁,如果是读锁则获取锁成功
如果不是,则阻塞等待,监听自己的前一个节点。
当前面一个节点发生变更时,重新执行第二步操作。写锁获取原理:
根据资源的id创建临时序号节点:/lock/mylockW0000000006 Write
获取 /lock 下所有子节点,判断最小的节点是否为自己,如果是则获锁成功
如果不是,则阻塞等待,监听自己的前一个节点
当前面一个节点发生变更时,重新执行第二步。通过一张图更清晰地看出现象:首先是写锁,因为写锁不是最前面的节点,所以阻塞了,008读锁因为前面并不是所有都是读锁,所以阻塞了。
-
释放锁:
删除对应的临时节点即可,如果服务器宕机了,因为临时节点的原理也不会发生死锁的情况。 -
 4.3.2 存在的问题
4.3.2 存在的问题 -
这个方案的优点是可以实现精确的全局限流,并且可以避免单点故障。但是,这个方案的缺点是实现复杂,且对 ZooKeeper 的性能有较高的要求。如果 ZooKeeper 无法处理大量的令牌申请和释放操作,可能会成为系统的瓶颈。















 1507
1507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









