






1 前馈神经网络相关知识
前馈神经网络(Feedforward Neural Network)是一种最基本的神经网络模型,也是深度学习的基础。它由多个神经元(节点)和层构成,信息在网络中单向传播,没有循环连接。
想了解前馈神经网络,就要了解以下一些知识:
-
网络结构:前馈神经网络通常由输入层、隐藏层和输出层组成。输入层接收原始数据,隐藏层用于处理中间特征表示,输出层产生最终的预测结果。
-
神经元连接:在前馈神经网络中,每个神经元与前一层的所有神经元相连接,每个连接都有一个权重。这意味着每个神经元都接收前一层所有神经元的输出,并通过权重进行加权计算。
-
权重和偏置:每个连接都有一个权重,表示连接的强度。此外,每个神经元还有一个偏置,用于调整神经元的激活阈值。权重和偏置是网络的可学习参数,通过训练过程进行调整。
-
激活函数:每个神经元的输出通过激活函数进行非线性变换。常见的激活函数包括Sigmoid、ReLU、Tanh等,它们引入非线性性质,使得神经网络能够学习更复杂的函数关系。
-
前向传播:前馈神经网络通过前向传播的方式将输入信号从输入层传递到输出层。在前向传播过程中,每个神经元根据输入信号和权重计算输出,并将其传递到下一层。
-
反向传播:反向传播是训练前馈神经网络的关键算法。它使用损失函数计算模型的预测误差,并将误差信号从输出层向后传播到隐藏层和输入层,以更新权重和偏置。
-
经典的多层前馈神经网络如图所示:
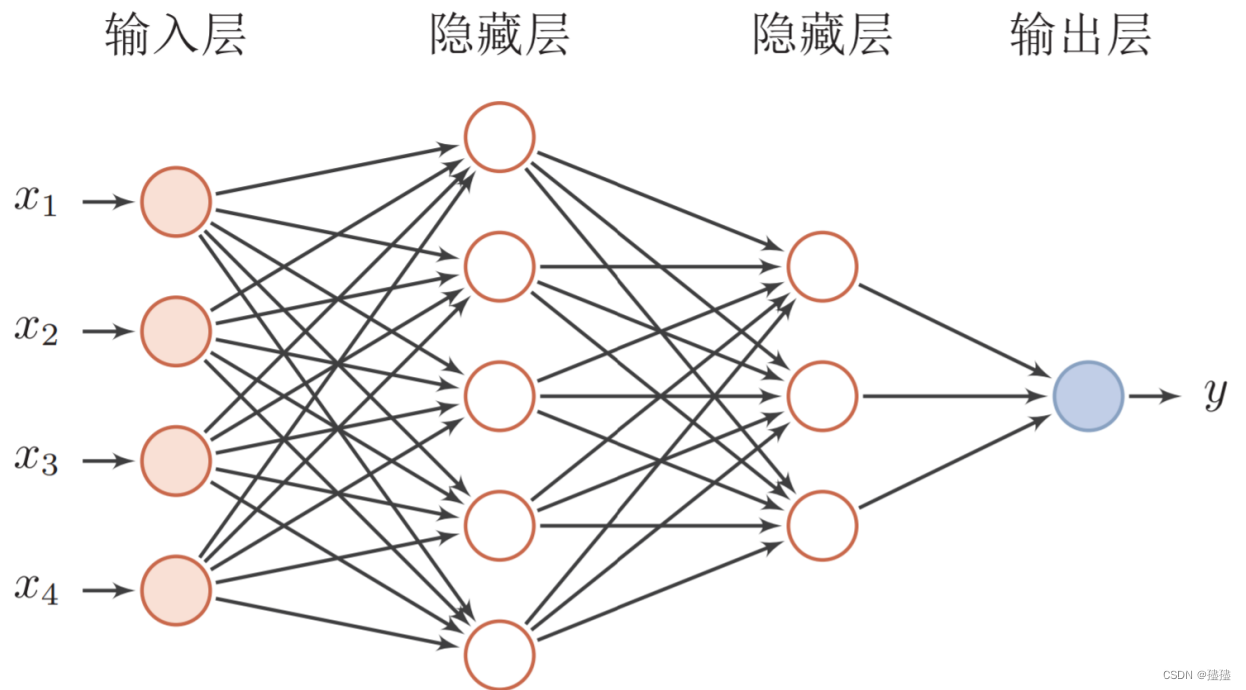
前馈神经网络在图像分类、语音识别、自然语言处理等领域得到广泛应用。它的主要优点是能够处理复杂的非线性关系,并且在数据量足够大的情况下,可以通过反向传播算法进行有效的训练和优化。下面通过对手写数字识别项目进行深入了解
2 数据库的介绍:
本次项目要使用到的是MNIST数据集,该数据集是一个广泛使用的手写数字识别数据集,常用于测试和验证机器学习和深度学习算法的性能。它由60,000个训练样本和10,000个测试样本组成,每个样本都是一个28x28像素的灰度图像。
官网连接为:http://yann.lecun.com/exdb/mnist/

3 代码介绍
(1) 导入必要的库
import tensorflow as tf #tensorflow库是一个广泛使用的深度学习库,提供了各种工具和功能用于构建和训练神经网络模型。
from tensorflow import keras#Keras是一个高级神经网络库,提供了方便的API和工具用于构建和训练神经网络模型
from keras.datasets import mnist #mnist模块包含了MNIST数据集的加载和预处理功能。
from tensorflow.keras import optimizers#优化器在神经网络中用于调整权重和偏置,以最小化损失函数。Keras提供了多种优化器(2) 数据准备
TensorFlow 自带的 MNIST 手写字体数据集,所以可以直接调用mnist.load_data(),即可将数据集下载下来,下面是训练集前5个带有标签的样本图片:

查看样本图片的具体代码:
import matplotlib.pyplot as plt
from keras.datasets import mnist
# Load the MNIST dataset
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Display the first few images with their labels
num_images = 5
for i in range(num_images):
plt.subplot(1, num_images, i + 1)
plt.imshow(x_train[i], cmap='gray')
plt.title(f"Label: {y_train[i]}")
plt.axis('off')
plt.show()(3) 数据处理
1)prepare_mnist_features_and_labels()函数
def prepare_mnist_features_and_labels(x, y):
# 将张量强制转换为dtype新类型
x = tf.cast(x, tf.float32) / 255.0
y = tf.cast(y, tf.int64)
return x, y
这个函数主要是将张量x转化成TensorFlow的32位浮点数(tf.float32),并除以255.0,将张量y转化成TensorFlow的64位整数(tf.int64),主要是为了为后面对图片数据进行处理时进行调用
1) mnist_dataset()函数
def mnist_dataset():
# 从训练集提取60000个数据
(x, y), (x_test, y_test) = mnist.load_data() # 加载MNIST数据集。
# 训练图像存储在x中,训练标签存储在y中,测试图像存储在x_test中,测试标签存储在y_test中。
train_ds = tf.data.Dataset.from_tensor_slices((x, y))
# 训练数据(x, y)创建了一个TensorFlow数据集。它沿着第一个维度对输入张量进行切片,以创建数据集的单个元素。
# 将数据打乱顺序并分成600个batch,每个batch有100个样本。
train_ds = train_ds.map(prepare_mnist_features_and_labels) # 将map_func映射到此数据集的元素
train_ds = train_ds.take(60000).shuffle(60000).batch(100) # 装载60000个数据集打乱后分为600批,每批次的样本数据为100个
# 从测试集提取全部20000个数据,prepare_mnist_features_and_labels,打乱顺序,设置为1个batch
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_ds = test_ds.map(prepare_mnist_features_and_labels)
test_ds = test_ds.take(10000).shuffle(10000).batch(10000)
return train_ds, test_dsfrom_tensor_slices()函数的认识:
from_tensor_slices()方法是tf.data.Dataset类的一个方法,用于从一个或多个张量创建一个TensorFlow数据集。在这种情况下,使用了from_tensor_slices((x, y)),表示从训练数据(x, y)创建一个数据集。具体来说,from_tensor_slices()方法会沿着第一个维度对输入张量进行切片,以创建数据集的单个元素。这意味着,如果x和y是张量,例如x的形状为(n, m),y的形状为(n,),其中n表示样本数量,m表示属性数量,那么数据集将包含n个元素,每个元素由x和y中对应位置的切片组成。
具体例子就是:
转换为:
实际就是将数据和标签一起进行切割,进行切割后数据通过转换对应类型后将60000个训练数据随机打乱,并分为600批,每批包含100个样本数据,及10000个测试数据分为1批次,每个批次包含10000个样本数据
总的来说,上述主要的功能是将加载MNIST数据集,进行预处理步骤,并通过对样本进行批处理和洗牌来准备训练和测试数据集。
(4) 模型建立
定义Model类
我们使用的网络是前馈神经网络,所以我们在搭建层数时,设置了两个隐含层和一个输出层。
def __init__(self):
# tf.Variable类型数据,形状为[28*28, 100],数据类型为tf.float32,初始值为-0.1到0.1的随机数,初始值形状与W1本身形状相同。
self.W1 = tf.Variable(shape=[28 * 28, 100], dtype=tf.float32,
initial_value=tf.random.uniform(shape=[28 * 28, 100],
minval=-0.1, maxval=0.1))
# tf.Variable类型数据,形状为[100],数据类型为tf.float32,初始值为0,初始值形状与b1本身形状相同。
self.b1 = tf.Variable(shape=[100], dtype=tf.float32, initial_value=tf.zeros(100))
# 以上属性说明,第一隐含层有100个神经元,上一层(第0层,输入层)有28*28=784个神经元
# tf.Variable类型数据,形状为[100, 10],数据类型为tf.float32,初始值为-0.1到0.1的随机数,初始值形状与W2本身形状相同。
self.W2 = tf.Variable(shape=[100, 10], dtype=tf.float32,
initial_value=tf.random.uniform(shape=[100, 10],
minval=-0.1, maxval=0.1))
# tf.Variable类型数据,形状为[10],数据类型为tf.float32,初始值为0,初始值形状与b2本身形状相同。
self.b2 = tf.Variable(shape=[10], dtype=tf.float32, initial_value=tf.zeros(10))
# 以上属性说明,输出层有10个神经元,上一层(第一隐含层)有100个神经元
# 由self.W1, self.W2, self.b1, self.b2构成的列表
self.trainable_variables = [self.W1, self.W2, self.b1, self.b2]在__init__方法中,定义了四个tf.Variable类型的变量:W1、b1、W2、b2,它们分别表示第一隐含层的权重、偏置,以及第二层的输出层的权重、偏置。这些变量的形状和初始值都被指定。
其中第0层,即输入层有28 * 28=784个输入神经元,第一层,即隐含层有100个神经元,第二层,也是输出层,它包含10个神经元。
向前传播:
def __call__(self, x):
#输入属性集x进行形状变换,将每个二维样本转化为一维
flat_x = tf.reshape(x, shape=[-1, 28 * 28])
# 将结果其与W1矩阵相乘,加上偏置b1,然后用tanh激活函数处理。
h1 = tf.tanh(tf.matmul(flat_x, self.W1) + self.b1)
# 将结果其与W2矩阵相乘,加上偏置b2,不用激活函数处理。
logists = tf.matmul(h1, self.W2) + self.b2
return logists在__call__方法中,先通过将输入属性集x进行形状变换,将二维样本转化为一维样本。然后,将展平后的一维样本与权重矩阵W1相乘,然后加上偏置b1,最后使用双曲正切(tanh)激活函数处理,最后,将第一隐含层的输出与权重矩阵W2相乘,然后加上偏置b2,得到最终的输出。
上述代码实现了自定义模型类MyModel中的前向传播过程,将输入样本通过第一隐含层和输出层的计算,得到模型的输出结果。
(5) 模型训练
在进行模型训练时得定义相关的函数:
交叉熵损失函数:
def compute_loss(logits, labels):
return tf.reduce_mean(
# 计算逻辑和标签之间的稀疏软最大交叉熵
tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels)
)
调用TensorFlow中的交叉熵损失函数,就是将模型的原始输出和真实标签的差值来计算它们之间的交叉熵损失后,返回平均损失。这个函数主要返回模型的损失函数
准确性函数:
def compute_accuracy(logits, labels):
# 对预测标签logits使用tf.argmax函数(注意维度为1),得到预测结果predictions
predictions = tf.argmax(logits, axis=1)
# 使用tf.equal函数判断预测标签与真实标签是否相同,再计算准确率。
return tf.reduce_mean(tf.cast(tf.equal(predictions, labels), tf.float32))该函数是用于计算模型在给定预测标签和真实标签下的准确率。具体步骤就是先调用tf.argmax函数对预测标签进行计算,取预测最大值,然后调用tf.equal函数判断预测标签与真实标签是否相同,返回一个布尔类型的张量,表示预测是否与真实标签相匹配,并将True会转换为1,False会转换为0,最后使用tf.reduce_mean函数计算张量的平均值,该值就是预测与真实标签相同的比例。
训练批次函数
def train_one_step(model, optimizer, x, y):
# 在梯度带中,调用模型的__call__方法
with tf.GradientTape() as tape:
logists = model(x)
loss = compute_loss(logists, y)
# 预测样本的标签,并调用compute_loss函数计算损失值。
grads = tape.gradient(loss, model.trainable_variables)
# 利用梯度带进行一次随机梯度下降法训练。
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# 调用compute_accuracy函数计算准确性。
accuracy = compute_accuracy(logists, y)
return loss, accuracytrain_one_step() 函数通过使用with tf.GradientTape() as tape::创建一个梯度带,用于记录前向传播过程中涉及的操作和变量,并计算损失值和梯度。然后,利用优化器将梯度应用于模型的可训练变量,进行一次参数更新。最后,计算并返回当前批次数据的损失值和准确性。这样,可以使用该函数迭代地训练模型,不断更新参数以提高模型性能。
训练函数
def train(epoch, model, optimizer, train_ds):
loss = 0.0
accuracy = 0.0
# 遍历数据集(TensorFlow的dataset形式)中的样本,调用train_one_step函数进行训练,
for step, (x, y) in enumerate(train_ds):
loss, accuracy = train_one_step(model, optimizer, x, y)
# 每次取出一个batch,在最后一个batch结束后,输出此刻的epoch, loss, accuracy。
print('epoch', epoch, ': loss', loss.numpy(), '; accuracy', accuracy.numpy())
return loss, accuracytrain 函数通过遍历训练数据集的每个批次,并对每一批次使用 train_one_step 函数进行模型训练,在训练过程中,损失值和准确率会被更新,并在最后一个批次训练结束后输出当前 epoch 的损失值和准确率。该函数的功能主要用于整个训练过程的迭代和监控训练进展。
(6) 模型测试
测试批次函数
def _test_step(model, x, y):
logists = model(x)
# 调用compute_loss函数计算损失值。
loss = compute_loss(logists, y)
# 调用compute_accuracy函数计算准确性。
accuracy = compute_accuracy(logists, y)
return loss, accuracy_test_step 函数主要通过调用模型的前向传播过程获取预测输出,然后使用用compute_loss 函数和 compute_accuracy 函数计算模型在测试样本上的损失值和准确率。该函数用于评估模型在测试集上的性能,并可以通过损失值和准确率指标来衡量模型的表现。
测试函数
def my_test(model, train_ds):
loss = 0.0
accuracy = 0.0
# 遍历数据集(TensorFlow的dataset形式)中的样本,调用test_step函数进行测试,每次取出一个batch,
for step, (x, y) in enumerate(train_ds):
loss, accuracy = _test_step(model, x, y)
# 在最后一个batch结束后,输出此刻的loss, accuracy。(注:本实验中,测试集只有一个batch)
print('<test loss>', loss.numpy(), '; <test accuracy>', accuracy.numpy())
return loss, accuracymy_test 函数通过遍历测试数据集的每个批次,使用 _test_step 函数进行模型测试,并在每个批次结束后更新总体的损失值和准确率。在测试过程中,每个批次的损失值和准确率会被更新,并在最后一个批次测试结束后输出测试集的损失值和准确率。该函数可以用于对模型在测试集上的性能进行评估。
其中本项目的测试数据是10000个样本,批次数为1,即模型在进行测试时,是遍历了整一个测试集后得出的损失值和正确值
4 结果展示

训练的轮数设置为10次,从输出结果可以看出,随着训练的进行,损失值逐渐减小,从初始的 0.22932684 降低到最后的 0.04652228。这说明模型对训练数据的预测逐步接近于实际标签;准确率在训练过程中有所波动,但整体上呈现出稳定的趋势,从初始的 0.96 上升到最后的 0.99,这表明模型对训练数据的分类能力逐渐提高。
测试集的结果用于评估模型在未见过的数据上的性能,模型在测试集上的损失值为 0.081175 和准确率为 0.975。从测试结果来看,模型在测试集上表现良好,具有较低的损失值和较高的准确率。
综合来看,模型在训练过程中逐渐学习并提高了对训练数据的拟合能力,同时在测试集上也展现出良好的泛化能力。这些结果表明模型在解决相应任务上的性能较好,并且随着训练的进行,模型的性能不断得到改善。
5 完整代码
# -*- coding: utf-8 -*-
#导入库
import tensorflow as tf #tensorflow库是一个广泛使用的深度学习库,提供了各种工具和功能用于构建和训练神经网络模型。
from keras.datasets import mnist #Keras是一个高级神经网络库,提供了方便的API和工具用于构建和训练神经网络模型。mnist模块包含了MNIST数据集的加载和预处理功能。
from keras.api.keras import optimizers#优化器在神经网络中用于调整权重和偏置,以最小化损失函数。Keras提供了多种优化器
#定义一个
def mnist_dataset():
# 从训练集提取60000个数据
(x, y), (x_test, y_test) = mnist.load_data() # 加载MNIST数据集。
# 训练图像存储在x中,训练标签存储在y中,测试图像存储在x_test中,测试标签存储在y_test中。
train_ds = tf.data.Dataset.from_tensor_slices((x, y))
# 训练数据(x, y)创建了一个TensorFlow数据集。它沿着第一个维度对输入张量进行切片,以创建数据集的单个元素。
# 将数据打乱顺序并分成600个batch,每个batch有100个样本。
train_ds = train_ds.map(prepare_mnist_features_and_labels) # 将map_func映射到此数据集的元素
train_ds = train_ds.take(60000).shuffle(60000).batch(100) # 装载60000个数据集打乱后分为600批,每批次的样本数据为100个
# 从测试集提取全部20000个数据,prepare_mnist_features_and_labels,打乱顺序,设置为1个batch
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_ds = test_ds.map(prepare_mnist_features_and_labels)
test_ds = test_ds.take(10000).shuffle(10000).batch(10000)
return train_ds, test_ds
def prepare_mnist_features_and_labels(x, y):
# 将张量强制转换为dtype新类型
x = tf.cast(x, tf.float32) / 255.0
y = tf.cast(y, tf.int64)
return x, y
class MyModel:
"""自定义模型类"""
def __init__(self):
# tf.Variable类型数据,形状为[28*28, 100],数据类型为tf.float32,初始值为-0.1到0.1的随机数,初始值形状与W1本身形状相同。
self.W1 = tf.Variable(shape=[28 * 28, 100], dtype=tf.float32,
initial_value=tf.random.uniform(shape=[28 * 28, 100],
minval=-0.1, maxval=0.1))
# tf.Variable类型数据,形状为[100],数据类型为tf.float32,初始值为0,初始值形状与b1本身形状相同。
self.b1 = tf.Variable(shape=[100], dtype=tf.float32, initial_value=tf.zeros(100))
# 以上属性说明,第一隐含层有100个神经元,上一层(第0层,输入层)有28*28=784个神经元
# tf.Variable类型数据,形状为[100, 10],数据类型为tf.float32,初始值为-0.1到0.1的随机数,初始值形状与W2本身形状相同。
self.W2 = tf.Variable(shape=[100, 10], dtype=tf.float32,
initial_value=tf.random.uniform(shape=[100, 10],
minval=-0.1, maxval=0.1))
# tf.Variable类型数据,形状为[10],数据类型为tf.float32,初始值为0,初始值形状与b2本身形状相同。
self.b2 = tf.Variable(shape=[10], dtype=tf.float32, initial_value=tf.zeros(10))
# 以上属性说明,输出层有10个神经元,上一层(第一隐含层)有100个神经元
# 由self.W1, self.W2, self.b1, self.b2构成的列表
self.trainable_variables = [self.W1, self.W2, self.b1, self.b2]
def __call__(self, x):
#输入属性集x进行形状变换,将每个二维样本转化为一维
flat_x = tf.reshape(x, shape=[-1, 28 * 28])
# 将结果其与W1矩阵相乘,加上偏置b1,然后用tanh激活函数处理。
h1 = tf.tanh(tf.matmul(flat_x, self.W1) + self.b1)
# 将结果其与W2矩阵相乘,加上偏置b2,不用激活函数处理。
logists = tf.matmul(h1, self.W2) + self.b2
return logists
@tf.function
def compute_loss(logits, labels):
return tf.reduce_mean(
# 计算逻辑和标签之间的稀疏软最大交叉熵
tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels)
)
@tf.function
def compute_accuracy(logits, labels):
# 对预测标签logits使用tf.argmax函数(注意维度为1),得到预测结果predictions
predictions = tf.argmax(logits, axis=1)
# 使用tf.equal函数判断预测标签与真实标签是否相同,再计算准确率。
return tf.reduce_mean(tf.cast(tf.equal(predictions, labels), tf.float32))
@tf.function
def train_one_step(model, optimizer, x, y):
# 在梯度带中,调用模型的__call__方法
with tf.GradientTape() as tape:
logists = model(x)
loss = compute_loss(logists, y)
# 预测样本的标签,并调用compute_loss函数计算损失值。
grads = tape.gradient(loss, model.trainable_variables)
# 利用梯度带进行一次随机梯度下降法训练。
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# 调用compute_accuracy函数计算准确性。
accuracy = compute_accuracy(logists, y)
return loss, accuracy
@tf.function
def _test_step(model, x, y):
logists = model(x)
# 调用compute_loss函数计算损失值。
loss = compute_loss(logists, y)
# 调用compute_accuracy函数计算准确性。
accuracy = compute_accuracy(logists, y)
return loss, accuracy
def train(epoch, model, optimizer, train_ds):
loss = 0.0
accuracy = 0.0
# 遍历数据集(TensorFlow的dataset形式)中的样本,调用train_one_step函数进行训练,
for step, (x, y) in enumerate(train_ds):
loss, accuracy = train_one_step(model, optimizer, x, y)
# 每次取出一个batch,在最后一个batch结束后,输出此刻的epoch, loss, accuracy。
print('epoch', epoch, ': loss', loss.numpy(), '; accuracy', accuracy.numpy())
return loss, accuracy
def my_test(model, train_ds):
loss = 0.0
accuracy = 0.0
# 遍历数据集(TensorFlow的dataset形式)中的样本,调用test_step函数进行测试,每次取出一个batch,
for step, (x, y) in enumerate(train_ds):
loss, accuracy = _test_step(model, x, y)
# 在最后一个batch结束后,输出此刻的loss, accuracy。(注:本实验中,测试集只有一个batch)
print('<test loss>', loss.numpy(), '; <test accuracy>', accuracy.numpy())
return loss, accuracy
if __name__ == '__main__':
print("start")
model = MyModel() # 实列化自定义模型
optimizer = optimizers.Adam() # 实现Adam算法的优化器
# 调用函数mnist_dataset(),获取数据集train_ds, test_ds。
train_ds, test_ds = mnist_dataset()
# 在5轮中,利用train函数进行训练。
for epoch in range(10):
loss, accuracy = train(epoch, model, optimizer, train_ds)
# 利用test函数进行测试。
loss, accuracy = my_test(model, test_ds)
print("real损失loss: %f ; real准确性accuracy: %f" % (loss.numpy(), accuracy.numpy()))














 1522
1522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









