






激活函数:


复合函数就是既有S型函数的性质又有斜坡函数的性质
S型:

非零中心化的σ(x)恒大于0,导致y对w求偏导后的结果恒大于0或小于0,造成只能在一、三象限优化的问题
解决方法:(1)normalization(2)σ(x)+b
斜坡:

复合函数:

σ是sigmoid函数,因为σ是在0~1之间,所以可以把它当作一个不完全开关的门,用来控制信息通过的多少,β是超参数,self是指x作门控制x的信息通过
例如当β=0时,σ(βx)=0.5,表示通过自己信息的一半
β越大,曲线越趋近ReLu的曲线

绿色线是高斯分布的概率密度函数,红色线是高斯分布的累积分布函数
神经网络概述:
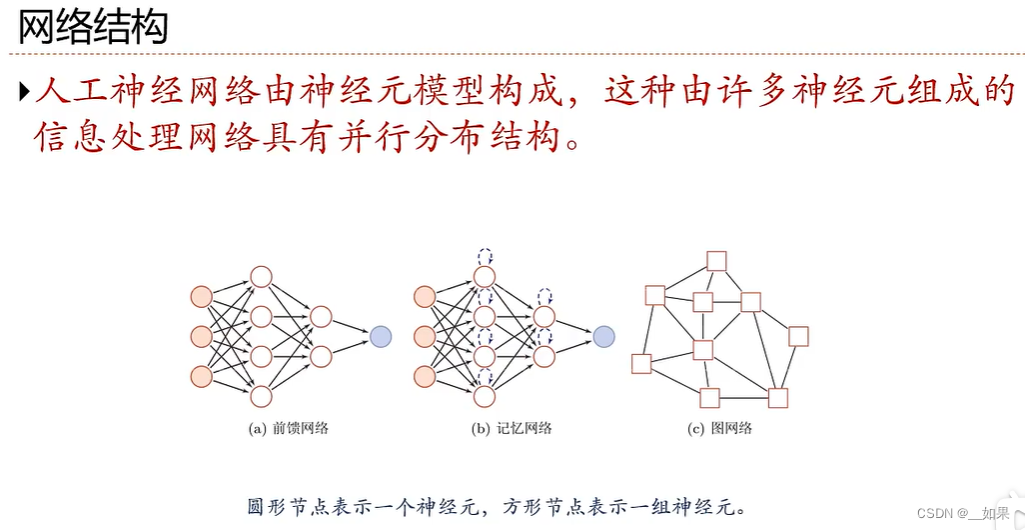

分布式是指一个信息可以分布在多个神经元上
前馈神经网络:




思考:
Q:一个两层的ReLu网络是否可以模拟任何有界闭集函数?
A:可以。万能近似定理表明,一个前馈神经网络如果具有线性输出层,同时至少存在一层具有任何一种“挤压”性质的激活函数的隐藏层,那么只要给予这个网络足够数量的隐藏单元,它就可以以任意的精度来近似任何从一个有限维空间到另一个有限维空间的波莱尔可测函数

前一项为交叉熵损失,后一项为正则化项(Frobenius范数)
计算梯度:

反向传播:


当链式法则的分母为矩阵时,就把它展开成对矩阵每一个元素的求导
计算梯度:

先不考虑正则化项
下面两个式子属于标量对向量求导,比较难展开,因此将其转化成

规避掉这个问题
现将两个式子用链式法则展开:

求第一项的偏导

分母是一个标量,且只与第i维相关,因此其它项都为0,将zi展开,只有前一项与w相关
求第二项的偏导


将原式拆成三项,经矩阵微分可得第 l 次的误差可以由第 l+1 次的误差乘权重矩阵的转置,再乘上激活函数的导数得到,我们把这个过程称为反向传播
求第三项的偏导

得到单位矩阵
最终结果:

思考:
Q:随机初始化w和b时能不能全零初始化?
A:不可以。在逻辑回归中可以,因为

即使将w11和w21初始化为0,dw11和dw21也会因为输入的x1与x2不同而不同
而在神经网络中不行

全零初始化会导致a1和a2、dw13和dw23恒相等,从而使同一隐藏层所有神经元的输出都一致
文章链接:谈谈神经网络权重为什么不能初始化为0 - 知乎 (zhihu.com)
计算图与自动微分:
让程序自动帮我们计算微分

将复合函数 f 中的操作分解成多个算子用作计算图的节点,节点的输入就是其对应的值
在每个节点上计算其偏导数

前向模式与反向模式:

前向模式是指从前往后计算偏导,反向模式是指从后往前计算偏导
用反向模式的原因在于输入的x是向量,而输出的f是标量,用反向模式时链式法则计算过程中保留的中间量会比用前向模式时的中间量要少
静态计算图与动态计算图:

比如我们的输入是一个变长的序列、动态变化的数据、图数据等,需要根据输入动态地调整网络架构
优化问题:
非凸优化问题:
(1)全局最优与局部最优
(2)鞍点
梯度消失问题:















 210
210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









