









一:编译器的结构

1,词法分析/扫描
确定单词的类型,语法单词(token)
token:<种别码,属性值>
2,赋值语句的分析树

3,语义分析
(声明语句和语义检查 )
声明语句:

放在符号表(存放标识符的属性信息)中,同时其中还要有字符串表。
语义检查:

4,中间代码生成和编译器后端
中间代码生成:
三地址码:

代码优化
二:语言及其文法

1,基本概念
字母表:有穷符号集合
字符表的运算+串+串上的运算
2,文法的定义
文法的形式化定义


3,语言的定义
推导(将左部替换成右部)和归约(将右部替换成左部) 句型和句子
4,文法的分类
0型文法:无限制文法/短语结构文法
1型文法:上下文有关文法
2型文法:上下文无关文法
3型文法:正则文法(左线性和右线性)
四种文法的关系:
逐级限制

逐级包含

5,CFG(上下文无关文法/二型文法)分析树
分析树是推导的图形化表示
句型的短语:
如果树的深度为二,那么这棵子树边缘称为直接短语(所以直接短语是产生式的右部)
二义性文法:
一个文法可以生成多棵分析树树,则称这个文法是二义性的 (消歧规则)
三:词法分析
1,正则表达式RE(描述正则语言)
2,正则定义(给正则表达式起名字)
3,有穷自动机FA(对一类处理系统建立的数学模型)
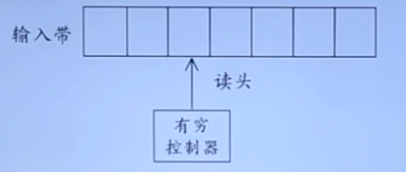


FA接收的语言:

最长匹配原则:(读取多个终端)

4,有穷自动机的分类(正则文法<=>正则表达式<=>FA)确定的(DFA):

例子(转换表和转换图)

不确定的(NFA):
与DFA的两点不同(红色标记)

带有和不带有:

5,从正则表达式到有穷自动机(RE转换成DFA)
RE->NFA->DFA

6,从NFA到DFA的转换方法 (子集构造法算法(不好理解,后面应该仔细学习))


从带Σ-边的NFA到DFA的转换:

7,识别单词的DFA
识别标识符/识别无符号数/识别各进制无符号整数/识别注释/识别Token

总的来说:

词法分析中的错误处理:
单词拼写错误/非法字符->查找字符表对应的某终态字符,没查到->错误恢复策略:恐慌模式(不断删除字符直到发现正确字符)
四:语法分析
1,自顶向下分析概论(从顶部根结点向底部叶节点构建分析树)
文法符号S->词串w
最左推导:总是选择每个句型的最左非终结符替换
最右规约:上面逆过程

自顶向下的语法总是采用最左推导的方式 计算机采用’递归下降分析‘
需要’回溯‘的分析器效率较慢
避免’回溯‘采用‘预测分析’(向前看k个输入符号)
2,文法转换
(不是所有文法都适合自顶向下分析,所以要转换):



消除直接左递归(A->Aα):
(消除左递归会付出代价:引进了一些非终结符和ε_产生式)
间接消除左递归:(使用代入法)
提取左公因子

3,LL(1)文法
s_文法(简单确定文法):

非终结符的后继符号集(FOLLOW(A))
产生式的可选集:

q_文法()

(q_文法不含右部以非终结符打头的产生式)
串首终结符:

LL(1)文法
以上条件确保了:

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









